
基于近邻传播聚类的电力通信告警分析方法
2016-09-09 02:51李星南陈文伟
电子设计工程 2016年16期
林 斌,曾 瑛,李星南,陈文伟,罗 云
(1.广东电网电力调度控制中心 广东 广州 510600;2.四川创立信息科技有限责任公司 四川 成都610093)
基于近邻传播聚类的电力通信告警分析方法
林 斌1,曾 瑛1,李星南1,陈文伟2,罗 云2
(1.广东电网电力调度控制中心 广东 广州 510600;2.四川创立信息科技有限责任公司 四川 成都610093)
在电力通信告警相关性分析中,往往需要将原始告警数据库转化为事务型数据库,针对传统均匀滑动时间窗口提取告警事务效率低的问题,文中提出一种基于近邻传播聚类的滑动时间窗口法,通过将近邻传播聚类算法应用于告警数据预处理过程中,将原始告警数据转化成能够用于滑动时间窗口法处理的若干时间段。实验证明,基于近邻传播聚类的滑动时间窗口法具有更高的事务提取效率,解决了固定时间段划分方法的不合理性,有利于告警相关性分析,在告警事务提取中具有更广泛的应用前景。
告警事务;关联分析;近邻传播聚类;时间窗口;滑动步长
滑动时间窗口法解决了原始告警数据中的时间非同步性,将告警数据库转化为告警事务数据库,并且滑动步长的设置能够完全将全部的告警信息转化为告警事务。滑动时间窗口法的设计对告警事务提取至关重要,目前已有的滑动时间窗口法大部分是均匀时间窗口法[5],即设定固定的窗口宽度和滑动步长,其值大部分由实验和经验值所得。这种方法简单易行,然而电力系统中故障可能随时发生,因此告警序列具有突发性,告警序列中可能有很长时间里没有告警发生,假如采取固定时间窗口和滑动步长进行告警事务的提取将会出现大量的空告警事务,这样不仅导致提取事务效率低,且耗费一定的时间和空间资源。文献[6]提出了一种基于双约束滑动时间窗来提取告警事务的方法,该方法将时间段划分为多个子时间段,各子时间段段内差异最小和段间差异最大,因此提高了提取事务的效率,然而该方法的计算量较大,并且需要事先指定划分的时间段数目,但告警序列具有数据量大、分布不确定等特点,因此确定时间段的数目比较困难。
文中设计了一种基于近邻传播聚类的滑动时间窗口法,主要思想是根据近邻传播聚类算法将告警序列划分成若干相对集中而独立的子告警时间段,然后对时间段设定合适的窗口宽度和滑动步长,以提高告警事务提取效率,该方法无需事先确定划分时间段的数目,划分时间段效率高且稳定性好。变化的窗口宽度和滑动步长根据告警的实际情况设定,具有更好的灵活性,时间和空间资源利用率较高。
1 问题描述
数据挖掘中的聚类算法是一种有效的数据分析方法,其目的是把大量的数据对象分成若干类,使得每个类中的数据之间最大程度地相似,而不同类中的数据对象最大程度地不同。告警序列是按时间顺序采集的,时间间隔小的告警数据间的关联性较大,因此,找出发生时间密集的告警子序列对提取告警事务有很大的影响,利用聚类的方法可以解决这一问题:将告警序列划分成若干时间段,同一时间段中的告警数据彼此相似,与其他时间段中的告警数据差别较大,说明同一时间段内的告警数据间的相关性较大,然后利用滑动时间窗口法将每个时间段的告警数据转化成告警事务。
在提取告警事务的过程中,滑动时间窗口法需要设置一定的时间窗口,同一时间窗口发生的告警认为是同时发生的,每个窗口的所有告警看作一个告警事务,即将告警数据库转化为事务数据库;在同一窗口内连续出现的告警可以记为同一告警,以消除告警冗余,因为同一个告警有可能被互联的网络设备同时检测到。
定义1滑动时间窗。令告警事件集为E,告警序列为V,一般情况下V是时间递增序列V=(e1,t1),(e2,t2),…,(en,tn),ei∈E,Tb≤ti≤Te,i=1,…,n,Tb为告警序列的起始时间,Te为结束时间,子序列Vw={w,tb,te}称为告警序列V的一个时间窗口,其中称为窗口宽度,记为W。
定义2滑动步长。假设告警序列当前窗口的起始和结束时间分别为Ti和Tj,设置滑动步长为s,则新窗口的起始和结束时间分别为Ti+s和Tj+s。
定义3告警情景发生的最大间隔和最小间隔。假设一个递增的告警序列为(C,t1),(C,t2),(D,t3),(D,t4),其中时间点t1<t2<t3<t4,对于告警情景CD来说,t4-t1为最大间隔;t3-t2为最小间隔。
SAP系统技术的引进和发展,成为了企业之间竞争和迈向国际化的重要手段。SAP系统以其卓越的技术设计,极大地满足了现代资源管理发展的需要。我们在应用此技术的同时也要对它的不足改进,完善企业资源管理系统。
2 基于近邻传播聚类的滑动时间窗口法
告警时间序列是一组分布不均匀的离散数据点,相关性强的数据总是比较频繁的出现在同一时间段内,如果将这些在时间上相似性比较大的时间段找出来,然后分别设定不同的窗口宽度和滑动步长,就可以有效地提高事务型数据库的生成效率和关联规则的挖掘效率。近邻传播聚类是以找到数据对象中最优的类代表点的集合为目标,每个集合中各个数据点之间彼此相似性较高,在告警序列划分时间段中具有较高的稳定性和自适应性。
2.1近邻传播聚类算法
算法开始将告警时间序列中发生告警的时间点转化为二维的样本点,然后计算样本点之间的相似度作为该算法的输入,输出的聚类结果为多个相对集中的子时间序列及所划分子时间序列中告警事件的聚类中心。在告警序列上进行聚类分析,每个数据对象均为告警信息,通过传递每个数据对象之间的吸引度和归属度,形成的每一个类为一个相关性较大的时间段。
在本文中,根据近邻传播聚类算法[8]的思想,将所有样本点看作潜在的聚类中心,使得聚类结果不受初始聚类中心选择的影响,具有更高的鲁棒性。该算法充分利用吸引度信息和归属度信息交替更新的过程,传递的信息以相似度矩阵为基础。具体信息传播过程如图1所示,实线传递归属度信息a (i,k),虚线传递吸引度信息r(i,k)。
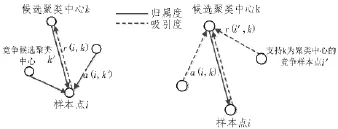
图1 信息传播过程
吸引度信息r(i,k)为从点xi发送到候选聚类中心xk的信息,表示xk作为xi的类代表点的适合程度,反映了xk适合作为xi聚类中心积累的相似度证据。归属度信息a(i,k)为从候选聚类中心xk发送到点xk的信息,表示xi选择xk作为类代表点的合适程度,反映了xi选择xk作为聚类中心积累的相似度证据。信息传播在迭代过程中将吸引度信息和归属度信息进行组合来决策出最终的聚类中心及其每个类代表点下所有的样本点,即计算所有样本点的r(i,k)和a(i,k)之和,从而确定xi是否为聚类中心,然后根据相似度将非聚类中心的点分配给最近的聚类中心。吸引度矩阵和相似度矩阵更新公式如下:

其中s(i,k)表示数据点xk和xi的相似度,距离越小相似度越高,在告警时间序列中,每个告警事务是若干告警项集合,在时间轴上具有强烈的相关性。
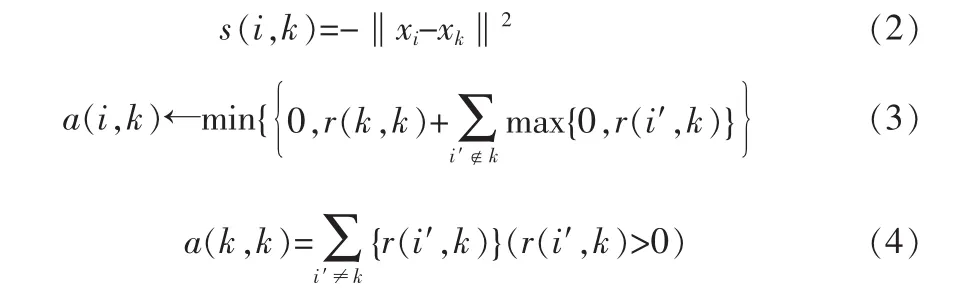
式(3)为归属度矩阵更新公式,式(4)表示xk为其他点聚类中心的可能性,由其他所有样本点发送到xk的非负吸引度相加得到。算法中将s(k,k)的值设定为参考值,记为P值,表示开始时每个告警事件样本点成为聚类中心的可能性相同,P值越大说明该点成为聚类中心的概率高。实验证明,P值的大小和样本点最终的聚类数目相关,P值越高,聚类个数就越多,一般情况下我们选取所有相似度的均值作为值,可以得到中等数目的聚类个数。为了避免算法过程出现振荡,引入阻尼因子dam,每一次的迭代过程,吸引度和归属度矩阵的更新结果就是当前值和上一次的结果加权而得,公式如下:
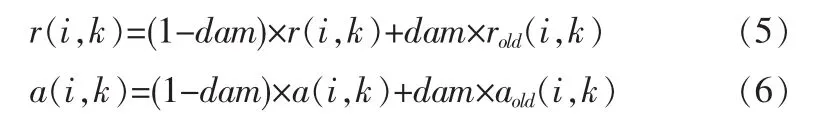
其中,dam∈[0,1),主要用来调节算法的收敛速度和稳定性。rold(i,k)和aold(i,k)为上一次r(i,k)和a(i,k)的迭代结果。直到发生迭代次数超过开始输入的最大值或者聚类中心在若干次连续的迭代过程中不发生改变的情况,算法终止。
2.2时间窗口宽度和滑动步长
时间窗口w大小决定了事务数据库中的每个事务的大小,影响关联规则的时间粒度,间接决定了最大频繁项集的长度,跟关联规则挖掘的效率有极大的关系。滑动步长的大小跟相邻事务间的区别粒度有关,步长越小,则相邻事务间的区别性不大,步长越长,则事务间的关联性较差,在满足滑动步长小于窗口宽度的条件下,选择合适的窗口宽度和滑动步长要根据电力通信网的实际网络情况而定。窗口宽度越小,越不容易发现有价值的关联规则,窗口宽度越大,其包含有价值的关联规则的同时也包含了大量的噪音,导致挖掘出来的关联规则数目庞大,一般情况下,典型的窗口宽度为5秒到600秒,常用的窗口宽度集为{5 s,10 s,30 s,60 s,120 s,300 s,600 s}。具体设置应该根据网络中发生告警的具体情况而定,随着电力通信网网络管理性能的提高,告警传输时延呈下降趋势,窗口宽度应该相应的减小;另一方面,当网络的规模增长使得告警的传播路径延长,窗口宽度应该相应的增大。
滑动步长跟提取事务的时间效率有关,滑动步长越长,提取事务所需时间相对较少,当s>w时,在提取告警事务的过程中会漏掉部分告警信息;s=w时,无法体现出告警事务间的相关性;s<w时,能够将告警序列完整地转化为事务型数据库。一般情况下,滑动步长小于时间窗口的一半。对于告警时间序列较长时,推荐滑动步长为窗口宽度的十分之一,常用其取值范围为[1,w/4],以保证相邻窗口有足够的重叠。
在以上的条件限制下,在反复的实验总结中选择合适的窗口宽度和滑动步长,窗口宽度w的取值范围为公式(7),在实际情况中根据具体的告警场景设置。

△w为时间段的宽度,Pmax为时间段内不同情景最大间隔的最大值。滑动步长的取值范围为

其中Qmax为时间段内不同场景最小间隔的最小值。
3 仿真及结果分析
仿真验证采取广东电力通信网中的告警样本,告警预处理后截取其中的部分样本,首先对原始告警数据进行清洗,然后提取告警级别、告警时间、告警名称、告警对象来表示告警事件,采用基于近邻传播聚类的滑动时间窗口法和均匀滑动时间窗口法分别处理时间长为50 s、100 s、200 s和300 s的告警序列,得到的告警事务数目如图2所示。
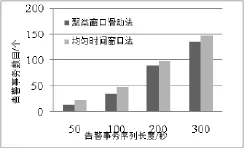
图2 采用两种方法对同一告警序列提取的事务数之比
对同一告警时间序列处理,本文采用的方法提取的事务数目相对来说有所减少,能够有效降低噪声数据对关联规则挖掘的影响,有利于关联规则挖掘。然后比较了基于近邻传播聚类的滑动时间窗口法和均匀滑动时间窗口法在提取告警事务时的效率,从图2得到50 s、100 s、200 s和300 s的告警序列中采用均匀时间窗口法分别提取的告警事务数23、48、98和148,对比采用本文聚类窗口滑动法提取相同数目的事务数所需时间,得到图3所示结果。

图3 采用两种不同方法提取告警事务的效率比较
从图3中可以明显看到,文中提出的基于聚类的窗口滑动法的提取效率高于均匀滑动时间窗口法,因为该算法通过聚类形成的多个告警子序列将没有告警发生的时间段过滤,从而节省了时间资源[11]。从实验结果可以得到,合理的划分时间段数目对提高提取告警事务效率至关重要。文献[6]中提出的基于双约束滑动时间窗口法的主要内容为首先随机的选择k个时间点,每个时间点初始地代表了一个时间段的中心,对剩余的每个告警事件,根据其与初始的k个时间点之间的距离,将它赋值给最近的时间段,然后重新计算每个时间段的中心,这个过程不断重复,直到准则函数收敛,定义准则函数为
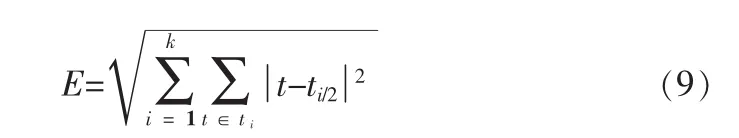
其中:ti/2表示时间段ti的中间点,E表示所有时间点的均方误差和,E越小,说明该划分的效果越好。t是每个时间段中的时间点。准则E试图使生成的结果每个时间段尽可能地紧凑和独立[12]。此算法尝试找出使平方误差函数值最小的k个时间段划分,当划分的时间段是密集的,而时间段彼此之间区别明显时,划分的效果较好,根据式(9)计算得到,基于双约束滑动时间窗口法和基于聚类滑动时间窗口法的均方误差和分别是20.3028和20.2055,因此本文算法划分的效果更好,更适合运用在告警序列划分中。
综上所述,和基于双约束滑动时间窗口法相比,基于近邻传播聚类滑动时间窗口法有以下优势:划分的时间段的数目不需要提前知道,能够自动生成合理的划分时间段数目;划分相同的时间段数目误差平方和更低;算法稳定性好,参考值P不变则聚类结果不变。
4 结束语
告警序列一般分布不均匀,突发性强,因此在将其转化为事务型数据库进行关联规则挖掘时,提取效率是首要考虑的因素。本文提出的基于近邻传播聚类的告警事务提取方法利用近邻传播聚类算法将告警时间序列聚类成多个相似度较高的时间段,然后分别设置不同的窗口宽度和滑动步长进行告警事务的提取。实验结果证明,与均匀滑动时间窗口法相比,本文算法提取告警事务效率较高,与基于双约束滑动时间窗口法相比,无需事先输入划分时间段数目能够自动生成合理的时间段数目。近邻传播聚类在大数据分析中应用比较广泛,电力通信网是大型异构通信网络,其产生的告警数据巨大,具有典型的大数据特征,利用大数据技术将该算法分布式处理能够为电力通信网中告警预处理带来新的发展契机。
[1]CHEN Chao,LI Tong-yanTongyan L.Study of alarm association rules mining based on matrixmapping[C]//Electronics,Communications and Control(ICECC),2011 International Conference on.IEEE,2011:2861-2864.
[2]Wu Y,Du S,Luo W.Mining alarm database of telecommunication network for alarmassociation rules[C]//Dependable Computing,2005.Proceedings.11th Pacific Rim International Symposium on.IEEE,2005:281-286.
[3]Leng X,Li X.Alarm fuzzy association rules parallel miningin multi-domain distributed communicationnetwork[C]//Communication Technology(ICCT),2012 IEEE 14th International Conference on.IEEE,2012:501-506.
[4]Wang Y,Li G,Xu Y,et al.An algorithm for mining of association rules for the information communication network alarms based on swarm intelligence[J].Mathematical Problems in Engineering,2014:1-14.
[5]Van Vaerenbergh S,Via J.Santamana I.Nonlinear system identification using a new sliding-window kernel RLS algorithm[J]Journal of Communications,2007,2(3):1-7.
[6]李彤岩,李兴明.基于双约束滑动时间窗口的告警预处理方法研究[J].计算机应用研究,2013(2):582-584.
[7]肖宇,于剑.基于近邻传播算法的半监督聚类[J].软件学报,2008(11):2803-2813.
[8]Frey B J,Dueck D.Clustering by passing messages between data points[J].science,2007,315(5814):972-976.
[9]Givoni I E,Frey B J.A binary variable model for affinity pro-pagation[J].Neural Computation,2009,21(6):1589-1600.
[10]Sahu N,Thakur G S.Document clustering using message passing between data points[C]//CommunicationSystems and Network Technologies(CSNT),2013 International Conference on.IEEE,2013:591-596.
[11]李刚.基于SOA的Web GIS系统框架设计分析[J].陕西电力,2011(2):38-41.
[12]赵志伟,陈学有,潘琼.采用特征值法和Prony法相结合的PSS自适应控制[J].陕西电力,2012(6):49-52,62.
【相关参考文献链接】
[1]肖寅,姜兴龙,龚文斌,等.基于大数据处理的ETL框架的研究与设计[J].2016,24(2):21-24.
[2]沈琦,陈博.基于大数据处理的ETL框架的研究与设计[J]. 2016,24(2):25-27.
[3]姜慧霖.基于层次聚类的案例检索策略 [J].2014,22(17): 158-161.
[4]李全鑫,魏海平.基于聚类分类法的信息过滤技术研究[J]. 2014,22(20):14-16.
[5]燕国云,侯大志.基于灰色聚类的通信链路效能分析[J]. 2015,23(2):181-183.
[6]吕海燕,张杰,王丽娜.基于聚类分析的微博用户标签自动生成[J].2015,23(7):67-69.
[7]邓森林,陈卫东.基于遗传模拟退火的K-means聚类方法[J]. 2014,22(6):54-56.
[8]刘念杰,秦会斌.基于电力线载波通信的智能调光系统设计[J].2014,22(8):149-152.
[9]刘俊材.物联网环境下电力传输线路安全监控系统体系架构研究[J].2014,22(16):155-158.
[10]罗志华,熊兴中,袁文林.基于电力载波通信的智能家居远程控制技术研究[J].2015,23(6):153-155.
[11]李晓迎,孙友伟,姚秋莎基于电力线物联网通信协议的设计[J].2015,23(20):82-85.
[12]张卫华.基于矩阵的apriori算法的改进[J].2015,23(13): 52-54.
An analysis method of power communication alarm information based on affinity propagation clustering
LIN Bin1,ZENG Ying1,LI Xing-nan1,CHEN Wen-wei2,LUO Yun2
(1.Power dispatch and control Center of Guangdong Power Grid Corporation,Guangzhou 510600,China;2.Sichuan Enrising Information Techonlogy Co.Ltd,Chengdu 610093,China)
In power communication alarm correlationanalysis,the original alarm database needs to be transformed into a transactional database.Traditional sliding time window has low efficiency on extracting alarm transactions,so sliding time window method based on propagation clustering is proposed.With this method,affinity propagation clustering is applied to alarm pretreatment,the alarm sequence would be considered to a series of data objects which is turned into some segments with higher similarity.The performance testing of the algorithm indicates that this method has higher extract efficiency,which solves the irrationality of fixed time window.The method is helpful for alarm correlation analysis and has a wider application prospect for extracting alarm transactions.
alarm transactions;correlation analysis;affinity propagation clustering;time window;sliding step
TN914
A
1674-6236(2016)16-0142-04
2015-08-26稿件编号:201508134
北京市自然科学基金项目(4142049)
林 斌(1969—),男,广东揭阳人,高级工程师。研究方向:电力系统通信网运维和管理。
猜你喜欢
中国交通信息化(2022年10期)2022-11-17
成都信息工程大学学报(2021年5期)2021-12-30
今日农业(2020年13期)2020-08-24
中国惯性技术学报(2020年2期)2020-07-24
河南水利年鉴(2020年0期)2020-06-09
成都信息工程大学学报(2019年2期)2019-08-28
华中师范大学学报(自然科学版)(2017年6期)2017-12-26
意林(2017年8期)2017-05-02
北京航空航天大学学报(2016年12期)2016-02-27
医学研究杂志(2015年5期)2015-06-10
