
基于语义网络的分层DHT*
2016-09-09 03:34严华云
湖州职业技术学院学报 2016年1期
严 华 云
(湖州师范学院 信息工程学院, 浙江 湖州 313000)
基于语义网络的分层DHT*
严 华 云
(湖州师范学院信息工程学院, 浙江湖州313000)
针对Chord结构并未考虑用户查询偏好的问题,提出了一种基于语义网络的分层DHT以解决该问题。在该分层DHT中,节点和关键词按语义关系组织,节点选择自己感兴趣的区域加入,每个区域选一个稳定节点作为超级节点,节点间按语义关系组织,各个区域按2-Chord结构组织。在此基础上提出了相应的路由算法,该算法先检查关键词是否归本地区域管理,否则转发给上层超级节点去处理,如此递归转发查询直至返回查询结果。实验发现,用户的查询关键词较偏好本地区域时,分层DHT较2-Chord的路由效率得到了一定提升,这种效果随着偏好度的增大越发明显。
语义网络;分层DHT;对等网;Chord
分布式哈希表作为一种结构化对等网,在诸多领域有广泛的应用,如文件共享、分布式计算、数据发布等。Chord[1](P149-160)是DHT的一种典型代表。DHT中Chord是一种高效且易实现的结构化对等网。针对Chord结构,研究者提出了多种改进以提高路由效率:
一种是单层Chord变体结构:如F-Chord[2]〗(P89-98)采用斐波那契序列作为finger序列的跨距;2-Chord[3](P72-79)是一种对称双向Chord,它维持Chord 的finger表的奇数项,将偶数项对折到反方向上,这样路由表大小虽然不变,但提高了路由效率;Base-k Chord[4](P643-657)的finger表采用k基序列,通过增加finger表长度来提高路由效率;本文作者结合Base-k Chord和2-Chord提出了双向Base-k Chord[5](P371-375,该结构有意思的是当基数K为奇数时其路由效率没有改变,而基数K为偶数时能有效提高路由效率;作者还针对双向Chord虽然可以双向查找,但其正反两个方向的finger跨距相等,在双向查询中潜在重合可能较多,从而提出了非对称双向Base-k Chord[6](P71-79以提高路由效率。
另一种是分层Chord变体结构:在对等网络中,随着规模的增长,弱节点(指计算能力差, 或动态变化剧烈的节点)严重地制约了DHT网络的性能。为了克服该问题, 研究者提出一些层次DHT网络, 在这种结构中选择稳定的高性能节点作为超级节点, 在超级节点之间构建的上层DHT网络,其维护代价和查找跳数相对于单层的DHT网络更小, 且能有效应对DHT网络中的churn问题(指节点频繁地加入或离开对P2P 网络性能造成的严重影响)。文献[7]是一种分层DHT变体典型结构。
总之,现有各种Chord有如下不足:单层Chord变体(包括Chord、F-Chord、Base-k Chord等)中由于存在弱节点,严重弱化了DHT网络的性能,如网络的稳定性;分层Chord变体选择稳定的高性能节点作为超级节点, 在超级节点之间构建成上层DHT网络,这虽然解决了稳定问题,但并没有考虑各节点的浏览偏好,即节点并非均匀浏览各种资源。
针对现有各种Chord存在的不足,本文主要做了如下工作:提出了一种基于2-Chord的分层语义DHT结构,以弥补现有分层DHT没有考虑节点的浏览偏好问题;通过实验,将本文方法与2-Chord进行性能比较。实验结果表明:与现有方法相比,本文提出的分层语义DHT结构的路由效率得到了提升,随着用户查询本地关键词比率的变大,这种效果更明显。
一、相关工作
本文提出的分层语义DHT基于2-Chord[3](P72-79,因此下面先介绍2-Chord。
2-Chord结构是在Chord的基础上进行的改进,它将Chord的finger表改为了对称的双向finger表,即保留标准Chord finger表的奇数项,删除偶数项,并将奇数项对折到反方向上。
设J(i)表示N个节点的环中finger表在正、反方向上的第i+1个指针的跨距。
对于front方向和back方向上的finger序列的跨距都为:
J(i)=22i,其中i=0,1,… , [log2N/2] 。
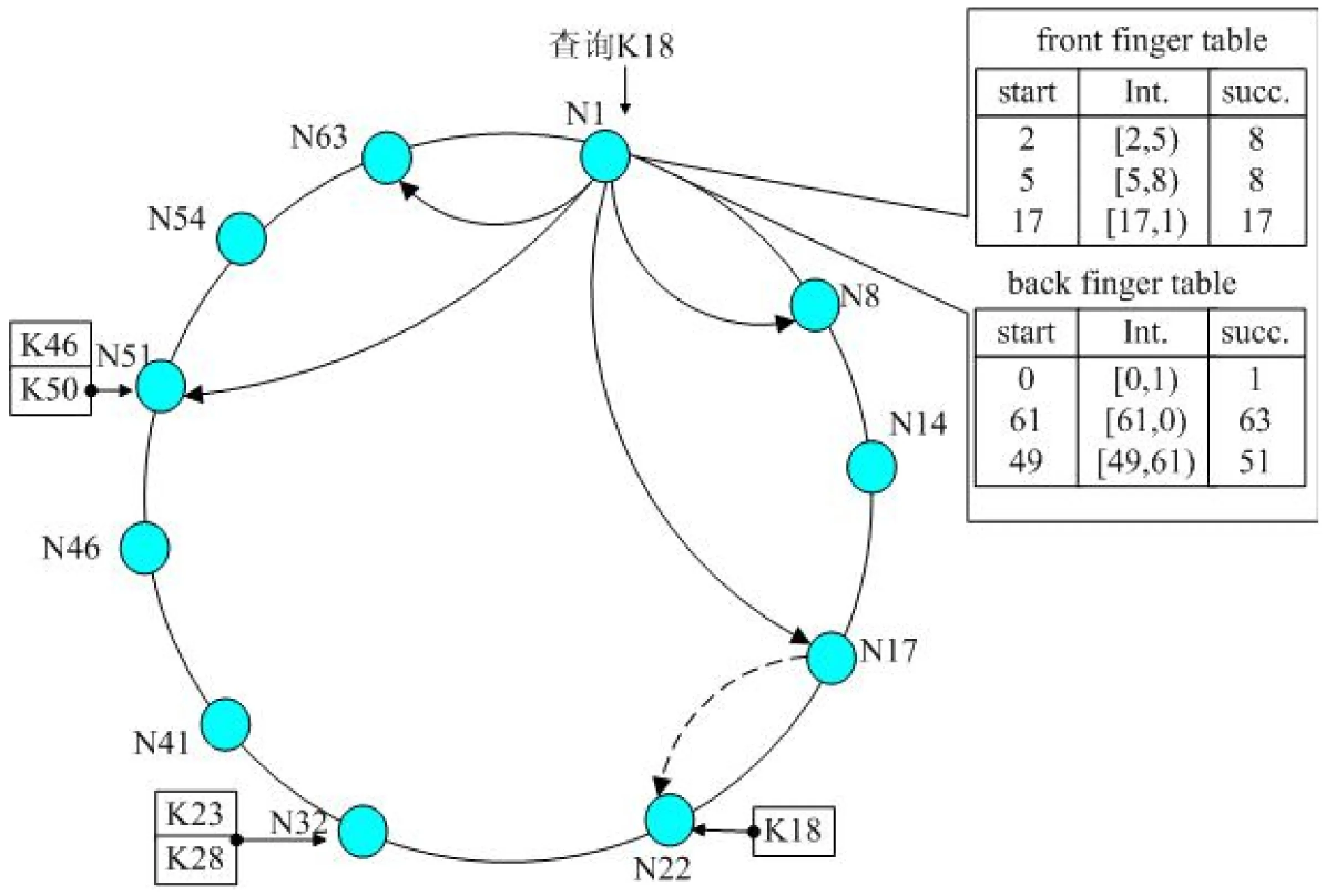
图1 2-Chord 结构及节点1的finger表及查询
图1是一个节点空间为64(即N=64)的2-Chord环。从该图可以看出其finger序列在两个方向上是对称的,其finger表大小和标准Chord的相等,但2-Chord可以双向查询,即查询时在当前节点的2个finger表中选择离目标节点离距离最近的节点进行路由。文献[3]中理论分析得出2-Chord相对于标准的Chord提高了路由效率,文献[6]中用实验得出了相同的结果。
二、基于语义的分层DHT
由于用户在DHT中查询时,查询关键词并非均匀分布,每个用户查询时有其偏好。本文引入了语义网络(Semantic Networks),将语义相近的关键词组织到一起,以使用户查询关键词时效率更高。语义网络常常被用作知识表示的一种形式,它是一个有向图,这个图的顶点(节点)代表概念,而边则用于表示这些概念之间的语义关系[8](P187-195)。图2是语义网络的一个例子,其中下层节点和其相连的上层节点间的关系是泛化联系 (用于表示一种类节点与更抽象的类节点之间的联系,简称AKO)。在语义网络中节点间的关系还有实体联系(用于表示类节点与所属实例节点之间的联系,简称ISA),聚集联系(用于表示某一个个体与其组成成分之间的联系)和属性联系(用于表示个体、属性及其取值之间的联系)。
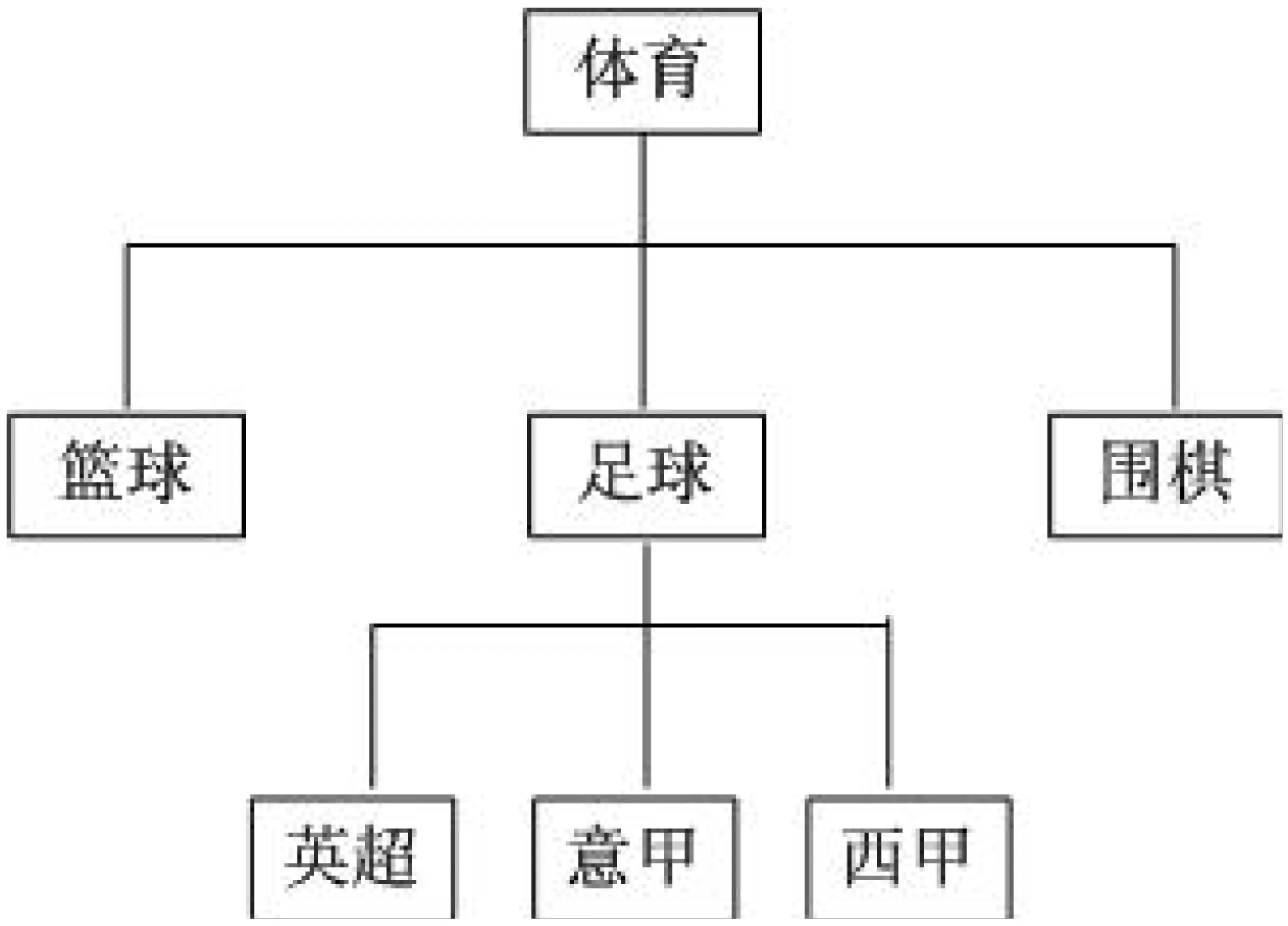
图2 语义网络的一个例子
(一)基于语义的分层DHT结构
本文提出了一种基于语义网络的分层DHT结构,其结构如图3所示:
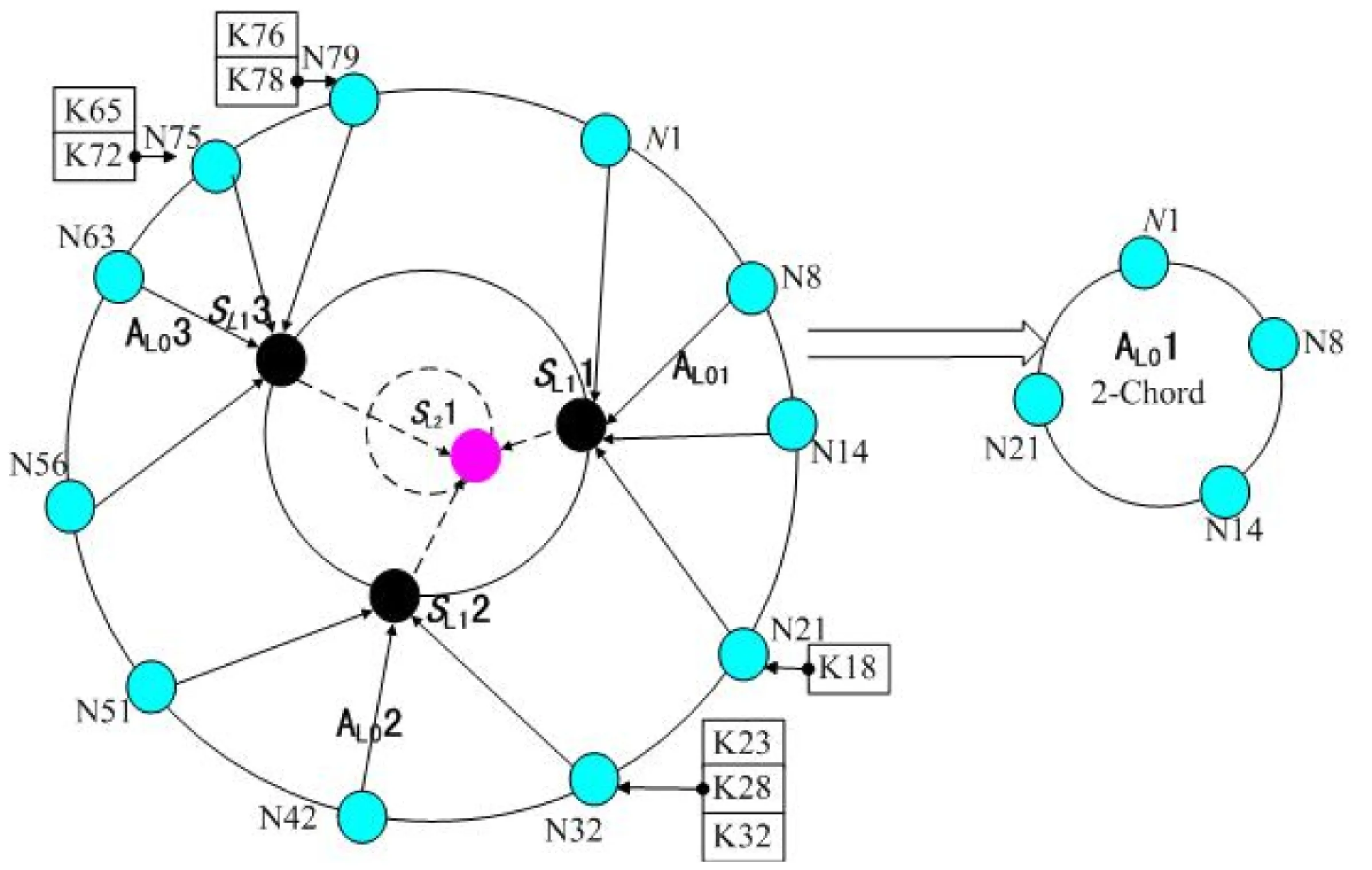
图3 基于语义网络的分层DHT (其中每一个子区域Ai以2-Chord结构组织)
图3中节点分为两类:一类是一般节点,如N1,N8,N14,N32等;另一类是超级节点,如SL11,SL12,SL13等。在该结构中,将有共同查询偏好的节点组织到同一个语义区域,即节点加入时根据自己的偏好选择相应的语义区域AL0i加入,在每一个语义区域中选稳定和计算能力强的节点担任超级节点SL1j;类似的,如果需要将这些超级节点按语义进行分区组织,并在该区中选择稳定和计算能力强的节点成为更上层的超级节点SL2j;如此类推,可以形成更上层的超级节点SL3j,SL4j,…。在该结构中,各语义区域A采用2-Chord结构组织,最上层超级节点S间也采用2-Chord结构加以组织。假设该分层DHT中共有K层,则各层按从上到下的层数分别记为:LK-1,LK-2,…,L1,L0,在语义网络中各层的语义词记为S.Li,节点加入其中后其标识ID为:Hash(S.LK1)|| Hash(S.LK-2)||…|| Hash(S.L1)|| Hash(S.L0),对于其中的Hash(S.Li),当i≥1时Hash(S.Li)表示对i层的语义词S.Li进行散列后的值,当i=0时S.L0用节点的MAC来表示,Hash(S.L0)表示计算节点的MAC值散列后的值。
(二)Finger表结构
在本文提出的基于语义的分层DHT中,节点的finger表由两部分组成:一是其所在层的基于2-Chord结构的双向finger表,另一个就是指向其超级节点的finger;对于某超级节点是由其下层节点选出来的,则该超级节点还包含其下层的双向finger表。
对于一个处于Li层的某(超级)节点,其由于该节点的标识为:Hash(S.LK-1)|| Hash(S.LK-2)||…|| Hash(S.L1)|| Hash(S.L0),则取其Li层的散列值(Hash(S.Li))进行组织该层的finger表 。
设某语义层Li中有N个节点,将这N个节点组成一个2-Chord环,设J(j)表示节点的finger表在正、反方向上的第j+1个finger项的跨距。
对于front方向和back方向上的finger序列的跨距都为:
J(j)=22j其中i=0,1,… , [log2N/2] 。
因此对于某节点m,其finger表为:
m.Hash(S.Li)±J(j)=m.Hash(S.Li)±22j
其中j=0,1,… ,[log2N/2] ,m.Hash(S.Li)表示节点m的标识ID的第Li层的散列值 Hash(S.Li)。
(三)路由
分层DHT的路由查询算法如算法1所示。
算法1n.search(key)(分层DHT的路由算法)
(1)根据查询词及其所属语义网络计算散列值:
key.Hash(S.LK-1)|| Hash(S.LK-2)||…|| Hash(S.L1)|| Hash(key) ;
(2)获取节点n的散列值:
n.Hash(S.LK-1)|| Hash(S.LK-2)||…|| Hash(S.L1)|| Hash(MAC);
(3)i=1;
(4)如果n.Hash (Li)!=key.Hash(Li);
(5) returnS.Li.search(key) ;//S.Li表示从节点n上溯到Li层的超级节点;
(6)i=i+1, 转4;
(7)否则,在Li-1层按2-Chord算法路由, returnS.Li.search(key) ;
//S.Li是节点n上溯到Li-1层的超级节点 。
路由查询时,先看查询词是否在本地区域,如不在,则将查询发送到其超级节点;当该超级节点接收到该请求后,看查询词是否为其所在区域的某一个超级节点所管辖,如该查询不在该超级节点区域管辖范围内,则继续向上层的超级节点转发该查询请求,直到找到某一层的某超级节点管辖该查询,则由该超级节点将该查询请求转发到其所辖的管理该关键词的节点上,如此这般,就能得到路由查询结果。
三、实验模拟
实验中采用的模拟器为PeerSim,本节的仿真以2-Chord为基准,不失一般性。实验中假设分层DHT的层数为2层,并假设分层DHT的语义区域数为10。下面对分层DHT与2-Chord进行了全面的比较。
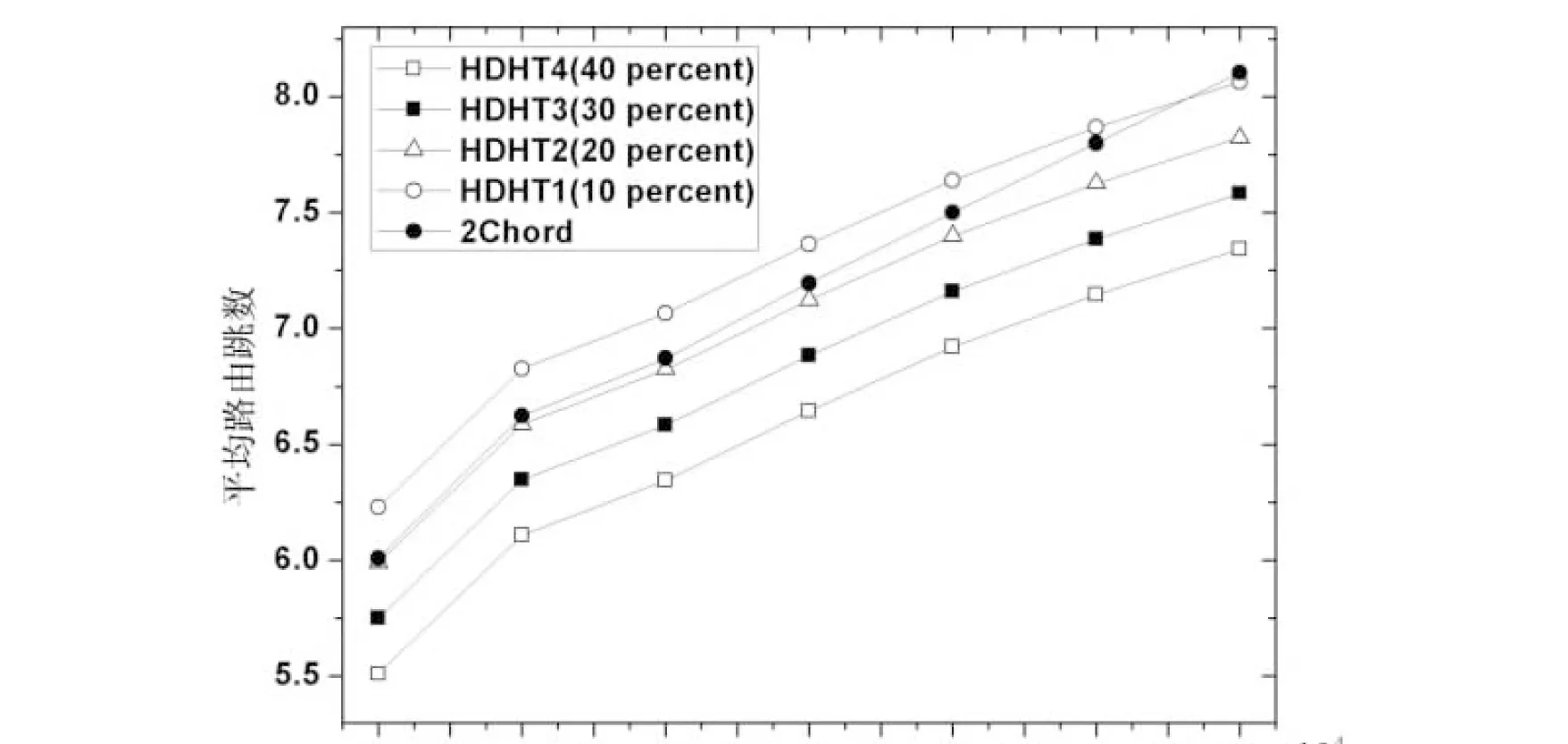
图4 平均路由跳数与节点数的关系
本节将分层DHT和2-Chord进行了实验比较,实验中每个节点管理100个关键词,即使关键词均匀分布在各个节点上,实验结果如图4所示。图4中,2Chord表示的是在2-Chord结构中的实验结果,HDHT表示的是本文提出的方法的结果。具体的,HDHT1表示的是查询关键词有10 %在其所处的子区域的情况,HDHT2表示的是查询关键词有20 %在其所处的子区域的情况,其它情况依此类推。从图中实验结果可知:
HDHT1大部分的平均路由跳数都比2-Chord的大,即其路由效率不如2-Chord高。这是因为HDHT1的查询关键词处于本地子区域的比例和均匀分布查询时的相等,而查询非本地子区域时需要经过上层超级节点的中转,因此其路由效率更低些。
HDHT2、HDHT3和HDHT4的平均路由跳数都比2-Chord的小,即其路由效率比2-Chord高;并且随着本地查询比例的增加其路由效率变得更高。这是因为HDHT2、HDHT3和HDHT4的查询关键词处于本地子区域的比例比均匀分布查询时的大,而在本地区域查询其路由范围变小,因此其路由效率更高些。并且随着本地查询的比例增加,其所需平均路由跳数变小,从而进一步提高了其路由效率;极限情况是所有查询都在本地区域进行,这样所有查询都不需要经过其上层超级节点的中转,从而每一个查询时的节点范围由2-Chord的所有节点变为了HDHT的部分节点,这样必然会大幅提高路由效率。
假设本模型中网络的节点数为 N,并且模型中分成了 M 个语义区域,因此每个语义区域平均有 N/M 个节点。同时假设查询时本地查询的比率为R(即偏好度)。根据文献[3]的推导和文献[6]的实验,在2-Chord中路由平均跳数大约为 log2N/2。本文模型中的本地路由平均跳数为:log2N/M/2 ,在L1层路由需要的跳数为 ,于是可得到本文模型在实验中的路由平均跳数(APL)为:
Rlog2N/M/2+(1-R)(log2M/2+log2N/M/2)=log2N/M/2+(1-R)log2M/2
上式中等号左边的第一项表示在本地路由情况,第二项表示查询不在本地路由的情况,在表达式中可以看出其APL随着R的增大而变小,即随着查询更偏好本地而使APL值更小,这意味着提高了路由效率。对于多层的情况有类似的推导。极端情况是R=1时,查询只需要在本地区域进行路由,这样缩小了查询范围,显然APL会减少。
四、结 论
本文在2-Chord的基础上,考虑到用户对查询的偏好问题,提出了一种基于语义的DHT结构(HDHT),其中每个子区域(按语义关系分区)按2-Chord的方式组织,每个区域有一个节点被选为超级节点,超级节点间也可按语义关系组织成区域并按2-Chord结构方式组织。从实验结果可知,HDHT的平均路由跳数得到了较大的降低;特别随着用户查询的偏好更关注于其所在的本地区域时,HDHT的平均路由跳数得到了更大的降低。本文提出的结构路由效率也比2-Chord要高。
[1] STOICA I, MORRIS R, LIBEN·NOWELL D,et al.Chord: A Scalable Peer-to-peer Lookup Service Protocol for Internet Applica tions[J]. IEEE/ACM Transactions on Networking,2003(4).
[2] CORDASCO G, GARGANO L, NEGRO A, et al.F-Chord:Improved Uniform Routing on Chord[J]. Networks,2008(4).
[3] CORDASCO G, SALA A. 2-Chord Halved[A].Proceedings of the 2nd International Workshop on Hot Topics in Peer-to-peer Sys tems. San Diego, California,USA,2005.
[4] CHIOLA G, CORDASCO G, GARGANO L, et al.Optimizing the Finger Table in Chord-like DHTs[J]. Concurrency and Computa tion: Practice and experience, April 2008(6).
[5] YAN H Y,GUAN J H,JIANG Y L.Symmetrical bidirectional Base-k Chord and Its Interesting Character[A]. The 5th International Conference on Semantics, Knowledge and Grid,Zhuhai,2009.
[6] 严华云,关佶红,詹卫华,等.非对称双向Base-k Chord [J].电信科学,2010(10).
[8] JASON J.JUNG: An Empirical Study on Optimizing Query Transformation on Semantic Peer-to-peer Networks[J]. Journal of Intel ligent and Fuzzy Systems,2010(3).
A Hierarchical DHT Based on Semantic Networks
YAN Hua-yun
(School of Information Engineering, Huzhou Teachers College, Huzhou313000, China)
Aiming at Chord structure and considering the preferential problems of user query, a hierarchy DHT based on semantic network is proposed to resolve the issue. In this hierarchical DHT, nodes and keywords are organized according to semantic relations, nodes select the areas that are interesting to join in, a stable node of each area is selected as a super node, the organizations are done between nodes according to semantic relationships, and each area is organized according to 2-Chord structure. On this basis, the corresponding routing algorithm is put forward, first, this algorithm checks if keywords belong to this region management, otherwise forward to the upper super-peer to deal with, do this recursive forwarding check, until returning to query results. It was found that, when a user's query keywords prefer local zone, the routing efficiency of hierarchical DHT has some improvement compared with 2-Chord, this effect becomes increasingly obvious with increasing preference.
semantic networks; hierarchical Distribute Hash Table; Peer-to-Peer; Chord
2015-07-29
本文系2015年度湖州师范学院出国访学项目的研究成果之一。
严华云(1972-) ,男,重庆万州人,副教授,博士,主要从事对等计算和信息检索研究。
G712
A
1672-2388(2016)01-0001-05
猜你喜欢
军事文摘(2020年18期)2020-10-27
开放教育研究(2020年2期)2020-03-31
铁道通信信号(2020年9期)2020-02-06
太原学院学报(自然科学版)(2019年3期)2019-09-23
太原科技大学学报(2019年3期)2019-08-05
网络安全和信息化(2018年3期)2018-11-07
动漫星空(兴趣百科)(2018年4期)2018-10-26
中学生数理化·八年级物理人教版(2017年3期)2017-11-09
中国社会历史评论(2016年2期)2016-06-27
现代语文(2016年21期)2016-05-25
