
电机状态异常数据检测算法研究*
2016-09-08 05:41杨全纬唐向红任甲举
组合机床与自动化加工技术 2016年8期
杨全纬,唐向红,郑 阳,任甲举
(贵州大学 现代制造技术教育部重点实验室,贵阳 550003)
电机状态异常数据检测算法研究*
杨全纬,唐向红,郑阳,任甲举
(贵州大学 现代制造技术教育部重点实验室,贵阳 550003)
针对电动机状态监测中异常数据检测存在的准确度低和测量值不精确等问题,文章提出一种基于区间数的不确定数据流异常检测算法。在该算法中,首先引入区间数的方法描述电动机状态监测中测量信号的不确定性,再利用区间数的位置关系对当前窗口的不确定数据进行剪枝,去除大多数正常的数据,最后根据距离值重新排列当前窗口的数据,收缩数据点的K-最近邻对象的查询范围。实验结果表明,该方法具有较高的检测精度和较低的计算复杂度,并能很好的运用到电动机状态监测中的异常数据检测。
电动机电流;不确定数据流;滑动窗口;K-距离;异常数据检测
0 引言
目前,电机状态检测的采集信号主要是利用传感器将包含故障特征的信号转换成数字仪器可直接测量的电气信号[1]。其特征不仅是数据到达速度极快、规模庞大[2-3],而且在实际系统中由于测试对象失效、测试仪器自身误差[4]和高磁场干扰等问题引起了其具有不确定性,并且它已逐渐成为影响测试信息可信性和系统可靠性的主要因素之一[5]。因此,面向电机状态检测系统中不确定数据流分析与挖掘技术的研究,对克服数据的不准确性和保证更高的检测精度具有非常重要的意义。
在不确定数据挖掘的研究领域中,异常点检测是其重要的研究内容之一,同时是数据挖掘处理过程的第1步[6]。一方面它对检测到的异常数据进行分析,能获取许多重要的信息[7];另一方面它对剔除的正常数据进行分析,可以得到更为准确的分析结果[8]。迄今为止,研究人员关于不确定数据异常点检测的研究还很少。其中,Aggarwal和Yu[9]提出基于遍历子空间和密度估计的不确定数据离群点检测算法。该算法对不确定数据对象在一个密集区域出现的概率使用平概率进行量化,再设定特定阈值判定离群点,避免了在处理多维不确定数据过程中对不是离群点的对象进行误判。文献[10]提出基于距离的不确定离群点检测的算法,该算法虽减少了检测次数,提高了效率,但在非均匀数据集的检测过程中精度不高,并只适合概率数据流的异常检测。姜元凯等人[11]提出基于密度的不确定数据离群检测算法。该算法采用R2-tree结构,虽能有效降低了时间复杂度,但未考虑数据属性级的不确定性且不适合流数据的异常检测。文献[12]研究了数据对象及其可能实例都具有不确定性,提出每个对象均由一些可能实例组成,再利用概率密度函数描述每个可能实例。同时假设具有相似属性的不确定数据往往会有相似的可能实例。文献[13]提出基于属性级的不确定数据的异常点检测算法。该算法首先定义了数据属性级的不确定性的异常点,再通过动态规划的方法,减少计算代价和存储空间,最后采用基于SM-tree(statistics M-tree)的查询方法,进一步提高查询效率,但该算法的用户参数不易设定。此外,上述算法对于数据不确定性均假定其概率密度[8-11]或概率分布函数[12-13]是已知的。然而,在大多实际应用中,获得数据完整的概率密度函数或概率分布函数是很难的。为此,采用区间数的方法科学而直观地表示不确定性数据,提出一种基于此方法的不确定数据流异常检测算法,并且能有效地解决在电机状态监测系统中对不确定数据流的异常数据检测。该算法采用滑动窗口分割数据流,并利用区间数的位置关系[14]进行剪枝,剔除一部分干净的数据;另外根据窗口内所有数据与首数据点的距离值大小进行排序,优化数据查询范围;最后基于K-近邻的检测方法对余下的数据进行异常检测。
1 区间数相关定义
定义1:(区间数及其中点和半径)[14]若给定AL、AR∈R,且AR≥AL,则集合A=[AL,AR]{u|AL≤u≤AR}可表示为一个区间数,其中:AL为其下界,AR为其上界。若令αA=(AR-AL)/2,mA=(AR+AL)/2,则有:AL=mA-αA,AR=mA+αA,并称mA为区间数A的中点,αA(αA≥0)是区间数A的半径。故区间数A又可表示为[mA-αA,mA+αA]。当上下界相等时,其可表示为一个确定数据。
定义2:(区间数之间的距离)[14]若给定两区间数P=[mP-αP,mP+αP],O=[mO-αO,mO+αO],其中mP,mO,αP,αO∈R,则区间数P和O的距离可表示为D=[Dmin,Dmax](具体计算过程见文献[14]),其中:
Dmax=|mp-mo|+αp+αo
(1)
这里通过引入相关系数λ[15],{λ∈R|0≤λ≤1},将上述两个不确定数据的距离极值组合,则这两个不确定数据之间的距离平方和D(P,O)2,可表示为:
通过相关系数λ不仅将距离度量与算法结合起来,而且能够表示两个不确定性数据之间各种情况下的距离值。如果λ为0,则可表示两个不确定数据之间的区间距离的最大值,此时两不确定数据最远;如果λ为1,则可表示两个不确定数据之间的区间距离的最小值,此时不确定数据最近。
定义3:(区间数P的K-距离(K-distance(P))在不确定数据集合G中,对于正整数K,区间数P的第K距离可记作K-distance(P)。如果存在某个区间数对象O与区间数P之间的距离可记作D(P,O),并满足以下的条件:
(1)至少存在K个区间数对象O′,∈G,使D(P,O′)≤D(P,O);
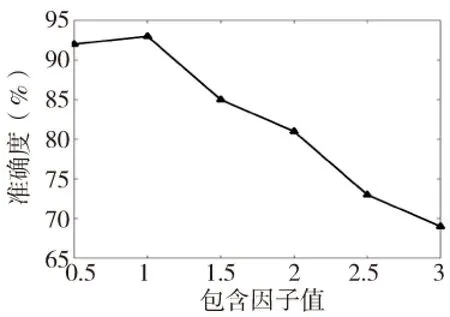
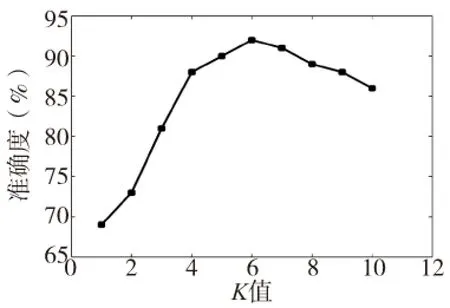
(2)至多存在K-1个区间数对象O′,∈G,使D(P,O′) 那么认为K-distance(P)= D(P,O)。 定义4 :(区间数P的K-距离邻域)给定区间数P的K-distance(P),则所有与区间数P之间的距离不超过K-distance(P)的对象集合称为区间数P的K-距离邻域,记作:Nk(P)。 在这一部分中,首先说明了不确定性数据流的区间表示方法,然后提出了基于滑动窗口和区间数的位置关系的剪枝方法,最后根据区间数距离排序的方法优化了数据查询,并阐述了基于k-近邻的不确定数据流异常检测算法及其实现。 2.1不确定数据流 2.2基于滑动窗口和区间数位置关系的剪枝方法 在不确定数据流DS中,异常数据是明显偏离其他对象的数据,并只占少部分且多为离散的,绝大多数数据为正常数据。为此如果能够寻找一种方法在不确定数据流中快速地去除一部分正常的数据,再对留下的可能为异常数据的数据进行检测,则能在整个不确定数据的检测过程中节省大量的时间。 在实际的电机设备运行诊断过程中测量值常与时间有关。如:在“电流—时间”关系中,电流I值是随时间t变化的,是无限的、有序的、快速变化的、不精确的,在其数据流模型中,由于数据规模极大且到达速度和顺序都无法控制,这将不允许数据全部存储后再处理。为了能处理其数据流中到达速度不同的数据,采用基于滑动时间窗口的处理方法。另外,在电机诊断系统中,很多采集信号为电流或电压,根据采集的谐波信号计算在其正常工作情况下它的有效值,用符号X效表示。再根据电机设备的特性合理获取基于有效值的一个阈值,用符号E表示,E=[X效-X1,X效+X2]。如果信号值的区间数P值处于E范围内,则采集的数据点为正常,否则数据点可能为异常数据。鉴于此,先通过对电流的测量值进行不确定性处理,再基于滑动时间窗口将不确定数据流划分成段以为后续工作做好准备,最后根据区间数的位置关系判断在工作情况中其电流的区间数I值是否处于区间数E范围内,若在某些特殊情况的出现时,其电流的区间数I值超过或相交于这个区域,那么这时其有可能为异常点。 2.3基于K-近邻的异常检测方法及其优化 要判断不确定数据流中经剪枝而留下的不确定数据是否为异常数据,这里采用不确定数据的邻近性度量,并且在实际应用中这很容易实现。在接下来的K-近邻距离的检测过程中仅需计算每个不确定数据与其它不确定数据之间的距离,得到不确定数据点的K-距离,最后用该不确定数据点到其K-最近邻的距离值便可表示离群度量,表达其是否远离大多数的正常点。 从这个计算过程中可以看出,在整个不确定数据的检测过程中每个不确定数据都将依次计算与其它不确定数据之间的距离值,这样会明显的增加整个检测过程的时间复杂度。为此通过空间换时间的方法对这个过程进行优化。首先,对于经剪枝过程而剩下的可能为异常的不确定数据,利用开辟内存空间保存这些不确定数据,用符号L1表示,在需要用到的时候直接提取,优化对象查询;然后,对于当前滑动时间窗口的所有不确定数据,通过计算滑动窗口中所有不确定数据点与首数据点之间的距离值,依据其大小采用冒泡法进行排序,再开辟内存空间L2保存记录,在需要的时候则直接从内存空间中提取。这样做可以在计算某个不确定数据k-近邻过程中,搜索其k-最近邻的对象时,仅需从L1中提取,再在L2中以其为中心有规律地扩散搜索数据对象,这样会大幅度地缩小其计算对象的查询范围,从而减少计算时间。 2.4算法描述 针对电机检测系统中传感器所采集的不确定数据流,我们根据滑动时间窗口中不确定数据流的有效值和利用K-近邻距离对其进行在线检测。在整个检测过程中,不确定数据流流入时间窗口后,首先对这些不确定数据进行剪枝,去除一部分正常的数据,再对留下的不确定数据采用基于k-近邻的方法进行最后的异常检测。算法描述如下: 算法:不确定数据流异常检测的UIDSWK算法 输入:不确定数据流DS,流数据的有效值T效,正整数K,滑动时间窗口的宽度d 输出:不确定数据流中异常点的数据集合 ①初始化系统的各个内存空间; ②扫描不确定数据流并存储当前时间窗口中的不确定数据直到当前窗口满; ③对当前窗口的不确定数据进行剪枝,并去除在E范围内的不确定数据; ④将窗口中可能的异常数据存到存储空间L1中; ⑤计算窗口中所有数据点与首数据点的距离,再利用冒泡法依据距离大小排序,并保存记录; ⑥调用L1中的数据,计算当前时间窗口内可能为异常数据的K-距离以及Nk(P),并将其按从大到小的距离来排序; ⑦依次判断L1中每个不确定数据的K-近邻对象所属类别,确定真正异常数据并输出; ⑧在时间轴上将窗口滑向下一个单元; ⑨重复第2步至第7步,直到检测完所有的不确定数据。 在整个算法的计算过程中,首先要计算出每个不确定数据点的区间数与E的位置关系进行剪枝,以此为依据来判断其是否为可能的异常点。从这个过程中可以看出整个剪枝过程的时间复杂度,给定数据量为N的不确定数据流,其时间的计算复杂度为O(4N);接着在计算数据点排序过程中的时间复杂度为O(NlogN);最后要计算L1中的对象K-近邻,其时间复杂度要远低于O(KNlogN)。因此,整个计算过程的时间复杂度要低于O(4N+ 2KNlogK)。 在以下的内容中,首先分析了相关系数、包含因子、K值和滑动时间窗口的宽度等参数对本文算法UIDSWK的检测精确度和效率的影响,然后对该算法的检测精度和效率进行评估以及与RLOF[11]和ODA[9]算法的比较,最后用人工合成的模拟数据进一步验证该算法的必要性和可行性。在实验中测试所用的数据分为真实数据和模拟数据两种。并且实验均在一台PC机上完成,实验硬件环境如下:CPU是InterPentiumG630,2.7GHZ,2G的内存。软件环境如下:操作系统为Windows7,编程的语言使用C++,开发环境为MicrosoftVisualStudio2010。 对不确定数据流中异常点的结果评估,采用离群点检测算法有效性的评估标准[9,11],检测准确度所采用表达式如下: 如果检测准确率值越趋近于1,则说明该算法有较好的检测结果。在实验中使用的真实数据集为领域内公认的数据集KDDCUP1999[9],即网络入侵检测数据集,其有多达7×107个网络连接记录,每条记录包含41个特征(如:持续时间、传输字节数、登陆次数等),并且其可分为5大类。从中选取2×104条连接记录,每条记录选取5个连续的数值型属性作为不确定数据的值部分。然后生成(0,μσ2)的高斯白噪声作为不确定数据流的标准差信息,其中μ是噪声因子(通过改变μ的值获取数据所具有不确定性程度的大小),σ2是数据的方差。最后将选取的数据集记录的输入顺序模拟成数据流的到达顺序,顺序号记为对应的时标,采用在线的处理方式对其进行检测。 3.1相关参数λ对UIDSWK算法的影响 在不确定性异常检测算法UIDSWK中,相关参数是采用用户输入的方式,且0≤λ≤1。通过不同的λ取值对UIDSWK算法在真实数据中进行异常数据检测,设定包含因子η取值是1,K值取值是6,滑动时间窗口宽度d是0.1,同时选取真实数据中的每120条记录进行检测,运行20次的检测准确度与相关参数值之间曲线如图1所示。 图1 检测准确度随相关参数λ变化曲线 从图1可看出,相关参数λ对UIDSWK算法的检测准确度有一定的影响。在相关参数λ值从0变化到1过程中,仅当取值为0.7~1时,对UIDSWK算法的准确度有较坏的影响,由此看出区间距离取各不确定数据之间距离的最小值,因而准确度较小,而在其他情况下准确度基本相似。因此选取相关参数λ的值时,推荐从0~0.7内取值较为合适。 3.2包含因子η对UIDSWK算法的影响 由文献[14]可知,如果数据偏离其统计均值3倍标准,那么分布在其区间的概率是99.7%,而不确定性数据流中各个数据的范围大小是由包含因子η决定的,因此η取值范围为0~3。为了进一步验证其对UIDSWK算法的检测准确度影响,在实验中选取不同的包含因子值进行对不确定数据流的异常数据检测。其中相关系数λ取值为0.7、正整数K为6和窗口宽度d为0.1,检测准确度与包含因子值之间曲线如图2所示。 图2 检测准确度随包含因子值η变化曲线 从图2可看出,包含因子η对UIDSWK算法的检测准确度有较明显的影响,当η取值从0.5增加到1时,算法的准确度值较高且变化不大,接着随着η的增大,其值呈迅速下降趋势。因此,在检测过程中推荐包含因子的值选取为0.5~1比较合适。 3.3整参数K值对UIDSWK算法的影响 关于K值对算法的影响,实验选取了不同K值,设定的相关系数λ、包含因子η、正整数K和窗口宽度d保持一致,实验的结果如图3所示。 图3 不同K值时检测的准确度 根据图3可知,在K值从1变化到10过程中,仅当K取值为4~8时,对UIDSWK算法检测准确度值比较高,随着K值增加,其准确度也逐渐增加,但是当K值达到一定程度后,准确度又会呈下降趋势。在K<4时,算法的准确率比较低,但其值随着K值增加而迅速上升,当K>8时,K值对准确度有较坏的影响,准确度会逐渐下降。其原因是因为在K值比较小的时候,不确定数据P的K-近邻的对象数据量很少,很容易误判这些数据中的正常数据为异常数据;随着K值的增加,不确定数据P的K-近邻的对象数据量也会迅速增加,这时判断这些数据中的异常点会比较容易,但当K值增加到一定程度之后,算法会将某些异常数据误判为正常的数据,因此其准确率又会逐渐下降。 3.4滑动时间窗口宽度d对UIDSWK算法的影响 考虑到不同滑动时间窗口宽度d对UIDSWK算法执行时间的影响。实验数据和检测的其它各个参数的选择均相同,实验的结果如图4所示。 图4 不同滑动窗口宽度算法的执行时间 从图4可以看出,对于同一不确定数据流而言,随时间窗口的宽度变大,整个算法的执行时间会迅速增加。这是因为随时间窗口的宽度变大,在每个时间窗口段中需要处理的不确定数据量会随之增多,因此这样导致了整个算法的计算时间的增加。 3.5针对真实数据检验不同算法的优劣 为了分析UIDSWK算法的优劣,通过与ODA和RLOF两种不同算法的比较得以验证。其中ODA算法是采用类似区间的不确定数据异常点检测。RLOF算法是基于密度的不确定数据异常点检测。虽然这两种算法的检测过程不在数据流中,但是可以采用基于时间窗缓冲区的处理方法,然后与本文算法进行比较。 首先,对UIDSWRK算法进行执行效率的性能测试。实验结果表明,在相同数据量的情况下各种算法的所执行时间如图5所示。 图5 不同算法之间执行时间的比较 从图5可以得出,ODA算法所用的时间最多,UIDSWK算法是所用时间最少的。ODA算法是最耗时,这是因为该算法为基于密度的检测算法,绝大部分计算时间都用在计算数据密度上,所以执行时间很高。而RLOF算法要比ODA算法优越,这是因为RLOF算法构建R2-tree树优化了数据查询,虽然这样会增加内存空间消耗,但是从时间的角度来看,可以为整个算法过程节约大量的时间。与这两个算法相比较,UIDSWK算法优化了K-近邻方法的数据查询,并且采用剪枝方法,去除了大多数正常的数据,因此减少了用在绝大部分的正常数据上面的计算时间,从而使其时间复杂度要低于其它两个算法。 为了说明UIDSWK算法的准确度优劣,采用在不同噪声因子μ值和不同算法的情况下进行试验,实验所得的结果如图6所示。 图6 不同算法不同噪声因子值μ检测准确率对比 从图6可看出,三种检测算法的准确度随噪声因子μ的增加呈不断下降的趋势。这是因为随噪声因子μ的增大,数据的不确定性程度变大,因而不确定性数据间的距离变大,因此准确度值也随之变小。同时可以看出 ,在这三种检测算法中,UIDSWK算法的准确度高于其它两种算法,这是因为在其剪枝过程中剔除了部分的干净数据,而留下的数据多为全局异常,在进行K-近邻检测过程中误判可能性较小。 3.6模拟的实验数据的实验 为了进一步验证算法的可行性,假设电机检测系统中要检测的某一电流信号,其表达式如下: (2) 从式(2)可以看出要检测的电流信号的周期为0.02s,频率为50Hz,给此信号施加一个冲击信号m(t),即为原始的信号产生的异常点。m(t)信号是均值为0,方差为3的高斯函数,此时电流信号的数据流变化的关系式如下: Y(t)=I(t)+m(t) (3) 然后在电流属性上继续叠加均值为0,方差为μσ2的高斯白噪声,通过调节μ值来对比本文提出的UIDSWK算法和其它两种算法在模拟实验数据的异常检测的准确度性能。根据前4节所做的关于各参数值大小对于检测结果的影响,设定相关系数λ取值为0.7,包含因子η值为1,K值为6,滑动时间窗口宽度d值为0.1。实验的结果如图7所示。 图7 不同算法不同噪声因子值μ检测准确率对比 从图7可知,在噪声因子较小时,这三种检测算法的准确度相差不大,随着噪声因子值增大而不断下降。但是在同等噪声水平的干扰下, UIDSWK算法的准确度优于其它两种算法,这是因为其使用的剪枝方法去除了大多数正常的数据,对于剩下的数据的检测误判可能性小,故其准确度较高。 鉴于不确定数据流的异常检测是一个非常重要的研究领域,具有广泛的应用前景。本文提出了一种用到电机监测控制系统中的不确定数据流的异常数据检测算法。该算法首先利用区间数和标准差来表示不确定性数据;然后利用基于滑动窗口和区间数位置关系的剪枝方法,剔除了当前滑动窗口中的大多数正常的数据;最后优化了计算K-近邻距离的对象查询。实验结果表明,相比其它两种算法在不确定数据流上UIDSWK算法的检测准确度和效率均有优势。下一步工作,将继续优化与完善UIDSWK算法,并且充分考虑更加复杂的不确定数据流情况下的异常检测。 [1] 安国庆. 异步电动机早期故障特征检测技术的研究[D].天津:河北工业大学,2013. [2] Babcock B, Babu S, Datar M, etal. Models and issues in data stream systems[C]. Symposium on Principles of Database Systems,2002:1-16. [3] 张晨,金澈清,周傲英.一种不确定数据流聚类算法[J]. 软件学报, 2010, 21(9):2173-2182. [4] 黄美发,景晖,匡兵,等.基于拟蒙特卡罗方法的测量不确定度评定[J].仪器仪表学报,2009,30(1):120-125. [5] 周帆,李树全,肖春静,等. 不确定数据Top-k查询算法[J]. 电子测量与仪器学报,2010,24(7):650-657. [6] 苏卫星,朱云龙,胡琨元,等.基于模型的过程工业时间序列异常值检测方法[J].仪器仪表学报,2012,33(9):2080-2087. [7] 周大镯,刘月芬,马文秀.时间序列异常检测[J].计算机工程与应用,2008,44(35):145-147. [8] Lozano E, Acufia E. Parallel algorithms for distance-based and density-based outliers[C]. International Conference on Data Mining, 2005:767-776. [9] Aggarwal C C, Yu P S.Outlier detection with uncertain data[C].Siam International Conference on Data Mining,2008:483-493. [10] Hao Y,Wang B,Gang X,etal.Distance-Based Outlier Detection on Uncertain Data[J].Journal of Computer Research and Development, 2009,1(3):293-298. [11] 姜元凯,郑洪源,丁秋林.一种基于密度的不确定数据离群点检测算法[J].计算机科学,2015,42(4):172-176. [12] Jiang B,Pei J.Outlier detection on uncertain data:Objects,instances, and inferences[J].Proceedings of the 2011 IEEE 27thInternational Conference on Data Engineering,2011,6791(4):422-433. [13] Cao Keyan, Wang Guoren,Han Donghong,et al.An algorithm for outlier detection on uncertain data stream[C]//LNCS 7808: Proceedings of the 15th Asia-Pacific Web Conference Heidelberg: Springer,2013:449-460. [14] 彭宇,罗清华,彭喜元.UIDK-means:多维不确定性测量数据聚类算法[J].仪器仪表学报,2011,32(6):1201-1207. [15] Habich D,Volk P B,Dittmann R,et al.Error-aware density-based clustering of imprecise measurement values[C].The 23nd IEEE Int’l Conf. on Data Mining,2007:471-476. [16] 罗清华,彭宇,彭喜元.一种多维不确定性数据流聚类算法[J].仪器仪表学报,2013,34(6):1330-1338. (编辑李秀敏) The Outlier Data Detection Algorithm in the Control System of Motor YANG Quan-wei,TANG Xiang-hong,ZHENG Yang,REN Jia-ju (Key Laboratory of Advanced Manufacturing Technology, Ministry of Education, Guizhou University, Guiyang 550003, China) Aiming at the inaccuracy of outlier data and measured data in the control system of motor, an outlier detection algorithm based on interval data was proposed in uncertain data stream. In this algorithm, firstly, the interval data introduced was used to express the inaccuracy of measured signal; Then all the data in the sliding windows was pruned by the position between two interval data, to dislodge most of the normal data; Finally, the current window data based on their distance with the first data was reordered, to reduce query data ink-close distance. Experiment results showed that the algorithm not only possessed better clustering precision with low computing complexity but also applied to outlier data detection in the motor monitoring system well. motor current; uncertain data stream; sliding window;K-close distance; date detection 1001-2265(2016)08-0034-05 10.13462/j.cnki.mmtamt.2016.08.010 2015-08-23; 2015-08-28 国家科技支撑计划(2012BAF12B14);贵州省重大科技专项(黔科合重大专项字(2012)6018);贵州省科学技术基金项目(黔科合J字[2011]2196号);贵州省工业攻关项目(黔科合GY字(2013)3020) 杨全纬(1989—),男,湖北荆门人,贵州大学硕士研究生,研究方向为先进制造技术、自动控制,(E-mail)825537796@qq.com;通讯作者:唐向红(1979—),男,湖南永州人,贵州大学副教授、硕士生导师,研究方向为实时数据库系统、数据挖掘,(E-mail)txhwuhan@163.com。 TH39;TG506 A2 UIDSWK异常检测方法
3 实验结果分析






4 结束语
猜你喜欢
保健医苑(2022年5期)2022-06-10
成都信息工程大学学报(2021年6期)2021-02-12
汽车维修与保养(2020年10期)2021-01-22
汽车维修与保养(2020年11期)2020-06-09
计算机应用(2020年5期)2020-06-07
中南大学学报(自然科学版)(2018年7期)2018-08-08
天津诗人(2017年2期)2017-03-16
中国交通信息化(2016年5期)2016-06-06
中小企业管理与科技·中旬刊(2014年10期)2015-02-03
