
基于粗糙集的汽油机失火故障神经网络诊断*
2016-08-24 09:28:40宫唤春徐胜云薛冰吴冬冬
汽车工程师 2016年4期
宫唤春 徐胜云 薛冰 吴冬冬
(燕京理工学院)
内燃机失火现象会造成内燃机动力性下降、燃油经济性恶化及排气污染加重等后果。由于内燃机在使用过程中随着技术状况的下降,失火现象出现概率增大,因此对在用内燃机的失火故障及时诊断并排除对内燃机的节能和减少排气污染有着十分重要的意义。文章以时代超人发动机为例,设置了不同失火故障模式,分别测试了内燃机有失火故障工况和无故障工况排气中HC,CO2,O2浓度及对应的内燃机工况参数,以试验数据为基础,采用粗糙集进行了属性简化[1],建立了基于径向基函数神经网络[2]的内燃机失火故障与排气中CO2,O2及输出转矩之间关系的诊断模型,将训练好的模型应用于内燃机失火故障的诊断,结果表明,此模型能够正确诊断内燃机失火故障,同时简化了神经网络的输入。
1 基于粗糙集的内燃机失火故障诊断方法
内燃机废气排放成分体积分数变化与内燃机失火故障之间的关系模型研究比较成熟,主要采用了专家系统、神经网络及模糊数学[3]等理论方法,但是这些研究缺乏对测试样本集进行系统的分析,大容量测试样本中很可能存在冗余的条件属性和不相容的样本数据,这些对神经网络的精度及泛化能力都会产生影响,会出现网络训练难以收敛和训练精度较低等问题。粗糙集由Pawlak Z于1982年提出,它建立在分类机制基础上,将分类理解为特定空间上的等价关系,而等价关系构成了对该空间的划分,将知识理解为对数据的划分,每一被划分的集合称为概念,它的主要特点是具有很强的数据定性分析能力,可直接对不完整性和不确定性的数据进行分析处理,提取有用属性,简化知识表达式。文章在实验研究内燃机失火故障与废气排放中HC,CO2,O2气体体积分数值、内燃机转速、转矩之间关系的基础上,采用粗糙集理论[4]对各种参数进行分析,剔除冗余数据,建立了内燃机失火故障神经网络诊断模型。
1.1 内燃机失火故障试验
文章以时代超人发动机为研究对象,通过对点火系统设置不同故障,造成内燃机出现不同程度的失火现象,测试不同程度的失火故障排气中HC,CO2,O2浓度值和内燃机转速与转矩。用白金触点烧蚀较严重的分电器来模拟部分失火故障,使一个缸断火来模拟一个缸失火故障。为了提高RBF网络学习训练后模型的泛化能力,在台架试验中,分别进行了内燃机工作转速范围(800~2 600 r/min)内不同转速和不同负荷(节气门开度40%~100%)工况在无故障、有部分失火故障及一个缸断火故障时内燃机废气排放特性试验,表1示出时代超人发动机部分试验数据,作为训练样本用于网络训练。
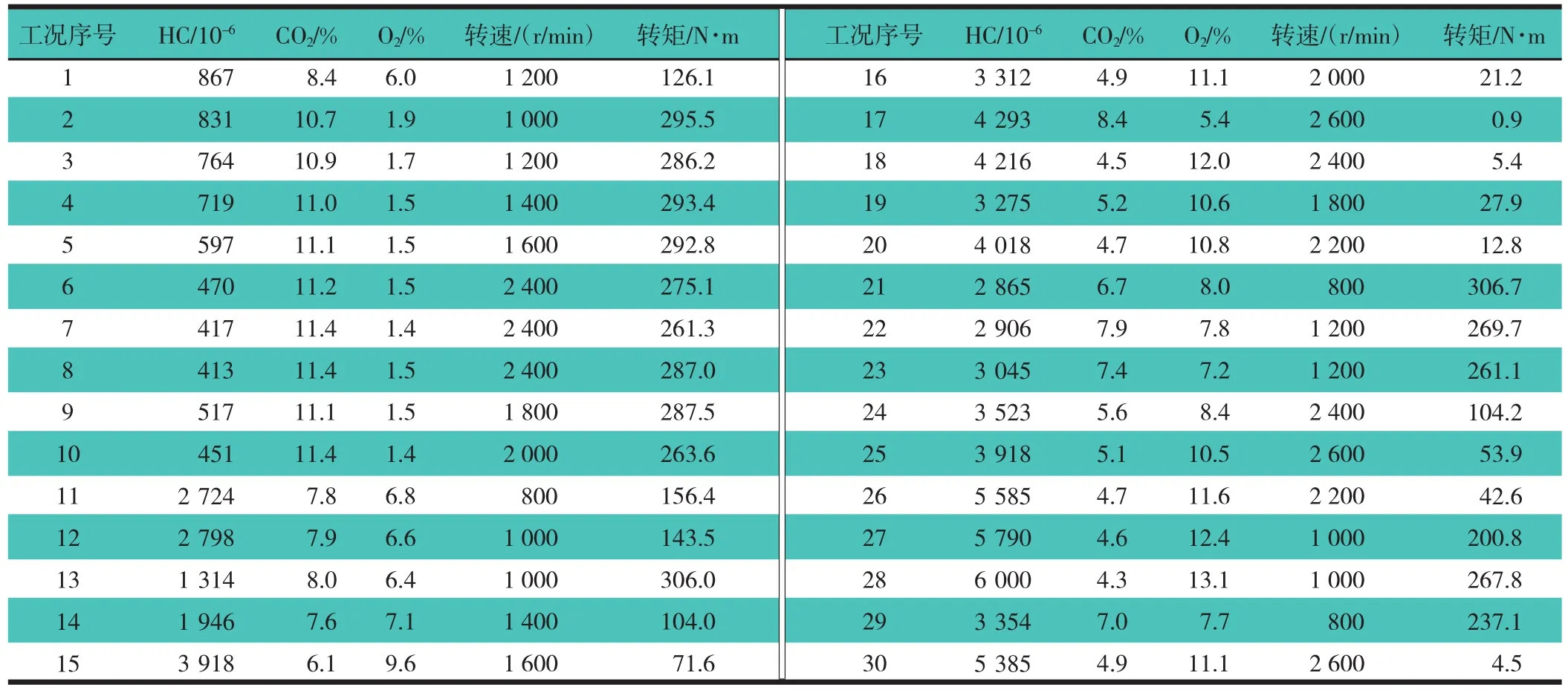
表1 时代超人发动机工况参数和废气排放浓度值
1.2 基于粗糙集的内燃机废气排放和工况参数属性约简
内燃机失火故障与废气排放和工况参数关系可表述成粗糙集中的信息系统 T=(U,A,C,D),其中 U 表示为对象的集合,也称为论域,A为属性值集合,C为条件属性集合,D为决策属性集合[5]。在内燃机失火故障诊断中U表示为表1中试验测试获得的全部数据;A是由C和D共同组成的集合可表示为A=C∪D;C={a,b,c,d,e},其中 a,b,c,d,e 分别表示表 1 中 HC,CO2,O2的体积分数、转速及转矩;D={f},是决策属性集;f={0,1,2},其中0表示无故障工况,1表示发动机有失火故障,2表示发动机有一缸断火。
采用RS理论前,需对各样本属性值进行量化处理,即将表1中的数据转化为规范的粗糙集中的数据表达形式,便于分析数据并进行属性约简。对连续量的量化处理首先要设定条件属性量化区间,目前对连续量的量化处理方法很多,如等距离法[6]和模糊聚类法等[7]。文章采用等距离法,该方法简单易用,基本算法如下:1)设定区间分类数目,文章中内燃机失火故障状况分为3种情况,即无故障工况、有失火故障工况和有一缸断火工况,所以区间分类数取为3;2)对每一个条件属性值区间进行等分处理,把相邻的两类边界属性值的均值作为该2类的分界值;如:表1中HC的体积百分数在[413,6 000]之间,将该区间3等份作为分界值,其它的条件属性值同样按照上述方法进行区间量化处理。按照此算法对表1数据区间化,区间化后的条件属性量化区间,如表2所示。
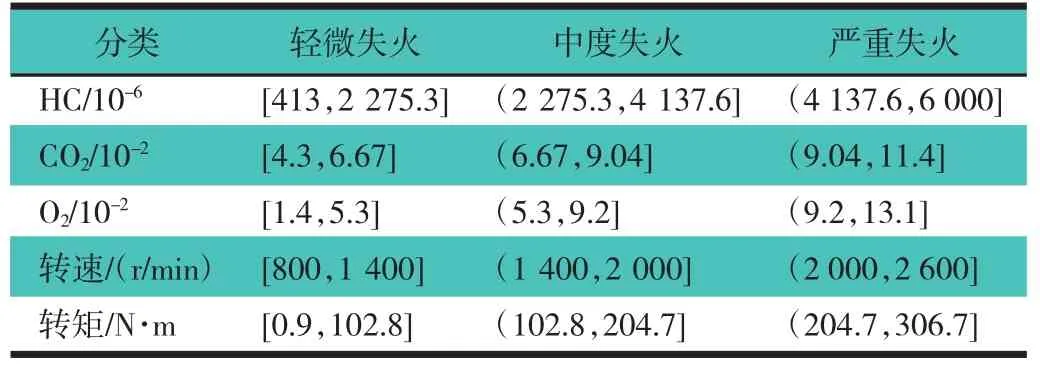
表2 废气排放数值条件属性量化区间
根据表2的量化区间将表1中数据化简到量化区间内,化简后的数据,如表3所示。
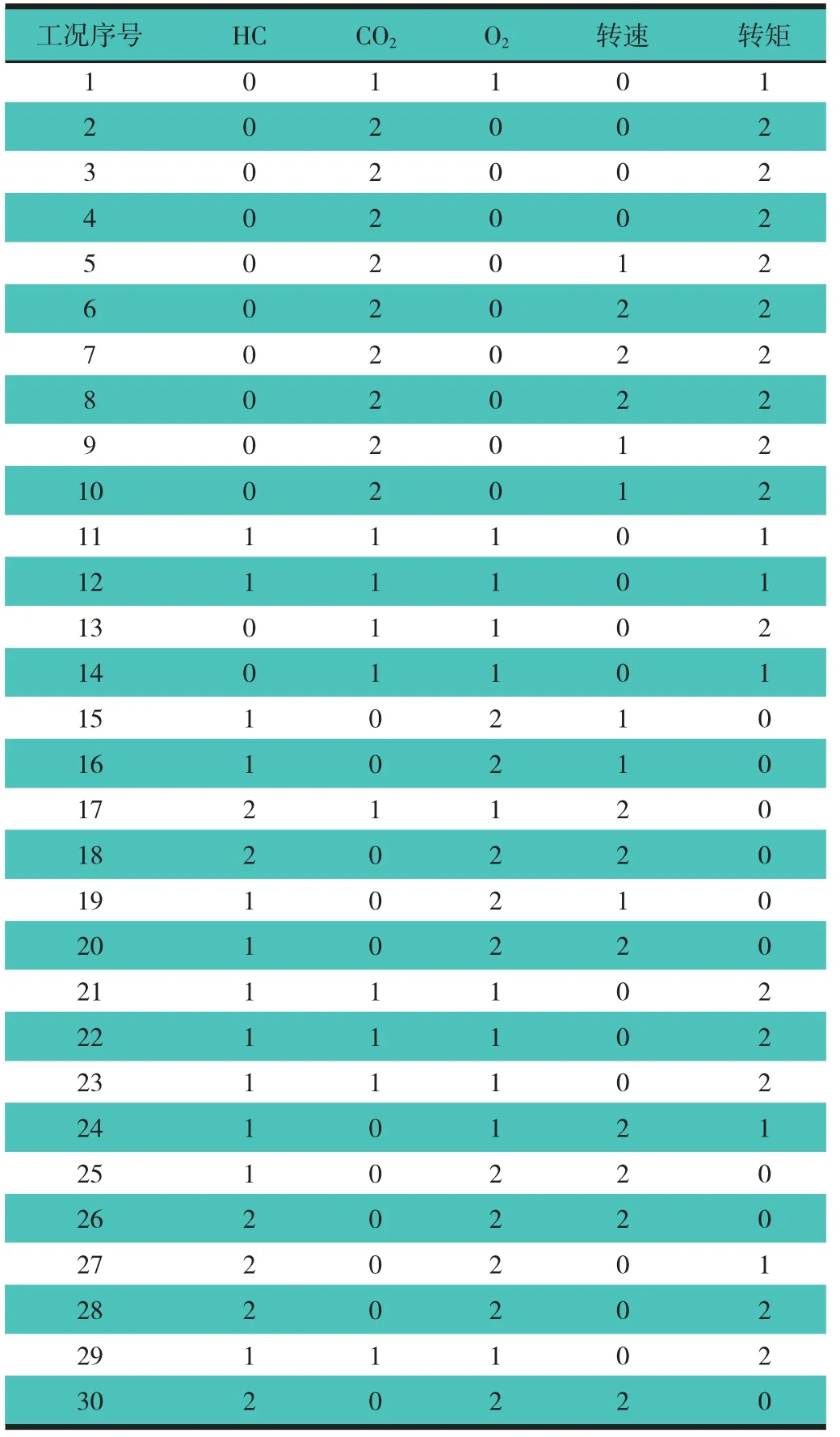
表3 时代超人发动机工况参数和废气排放浓度归一化数值
知识属性约简[8],就是在保持知识库分类能力不变的条件下,删除其中不相关或不重要的知识,在保持决策表决策属性和条件属性之间的依赖关系不发生变化的前提下对决策表进行约简。按照RS理论的约简方法,对表3的知识表达进行属性和规则约简,过程如下:1)合并重复的样本:如表 3 中工况 2,3,4,6,7,8,9,10 等条件属性和决策属性完全相同,则可以去掉重复的冗余属性值,减少规则数目。将表3工况1~30中重复的规则删除后剩下18条规则,表4示出约简后的属性规则表。2)属性约简:属性规则的约简是计算每条规则的核和简化,消去每一个属性规则的不必要条件属性值,它不是整体上的简化属性,而是针对每一个属性规则,去掉表达该规则的冗余属性值,约简后的属性规则具有与约简前的属性规则相同的功能。3)再次合并属性约简后重复的样本。4)决策规则的简化:删除每条规则中不必要的条件属性值,得到简化的规则。表5示出经过属性约简后的数据决策表,此时剩下3个条件属性,9条规则,与约简前相比,属性规则得到了优化。由此可知,在内燃机失火故障诊断中影响最大的因素是废气CO2和O2的体积分数和输出转矩,而HC和转速的影响较小,在粗糙集属性规则中可以约简掉这2个属性规则而不会改变粗糙集属性。
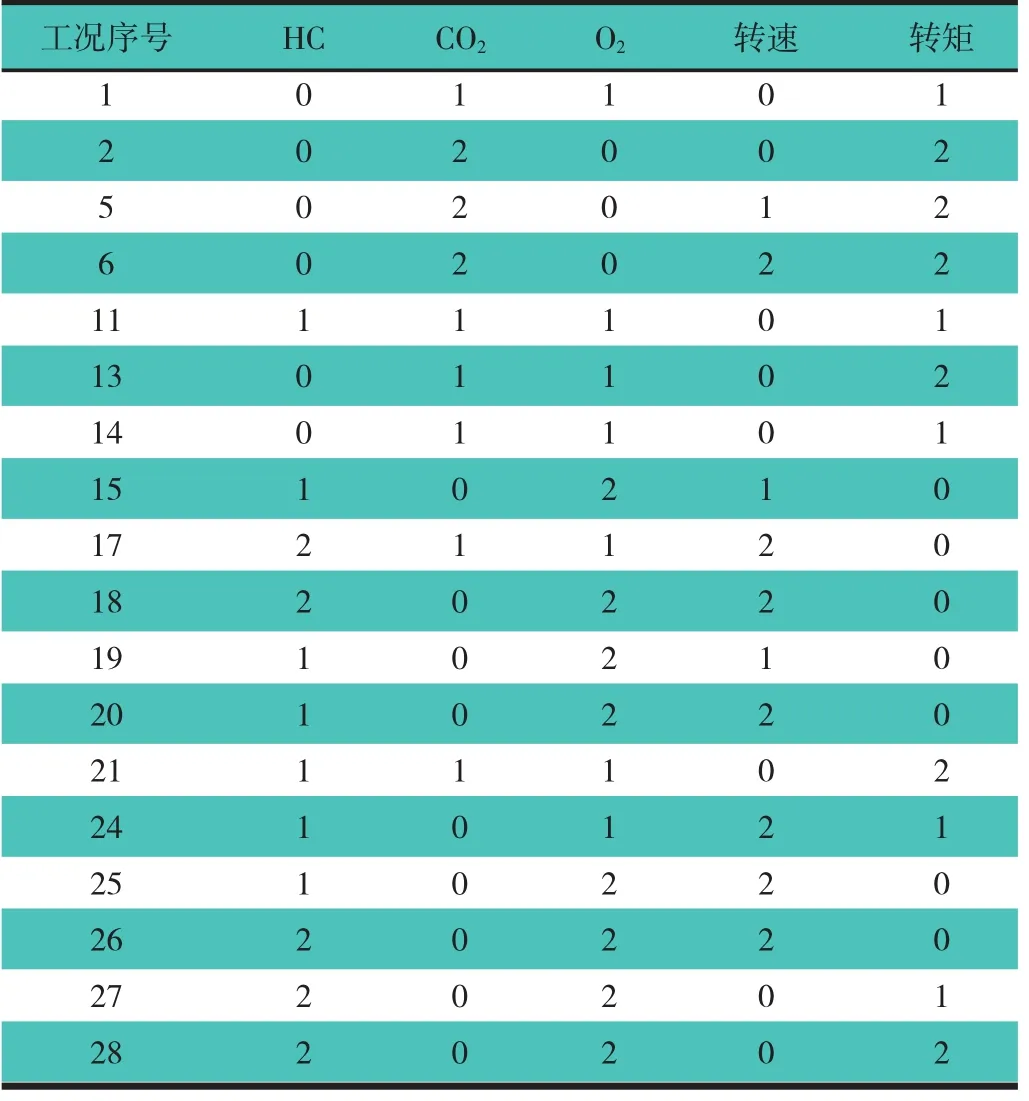
表4 各参数合并重复规则后的属性规则表
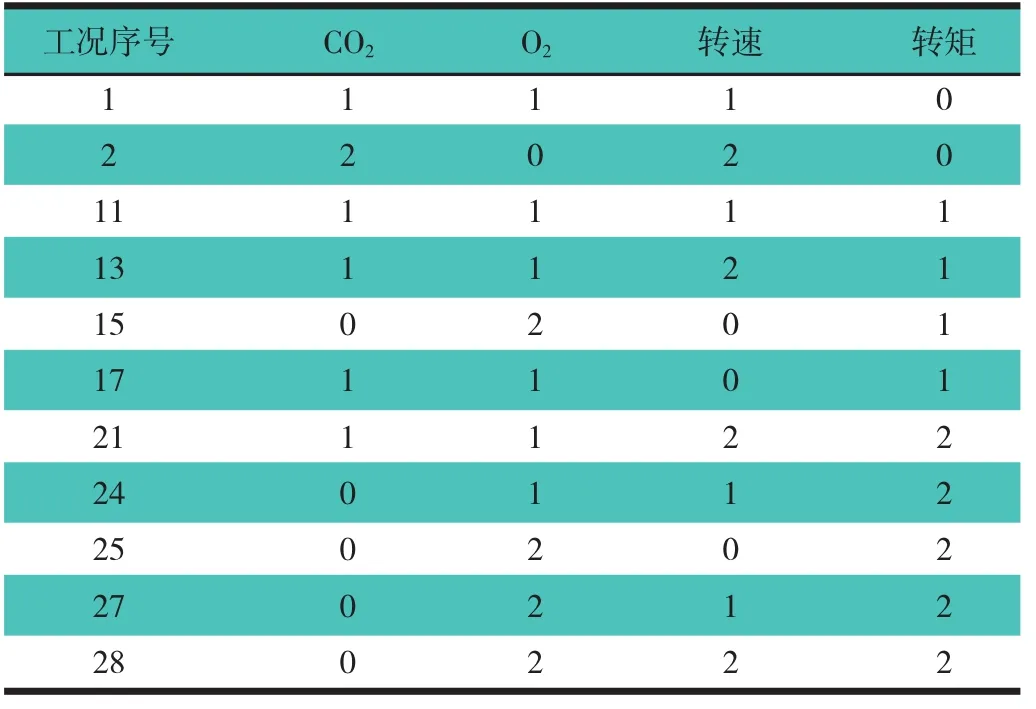
表5 各参数约简后的属性规则表
2 基于粗糙集与RBF神经网络的内燃机失火故障建模及诊断
将约简整理后的数据决策表作为神经网络的训练样本进行训练,获得各自的连接权值和阈值;然后存储相应的连接权值,形成知识库;最后用训练好的网络进行故障诊断。径向基(RBF)网络选取的参数少,网络稳定性比BP网络要强,无论在逼近能力、分类能力和学习速度等方面均优于BP网络,所以文章采用RBF神经网络建立模型。
2.1 RBF模型
RBF网络是一种3层前向网络[9],其输入到输出的映射是非线性的,隐含层空间到输出空间的映射是线性的,从而大大加快了学习速度并避免了局部极小问题。RBF网络结构,如图1所示。
2.2 网络训练过程
为便于比较约简前后的数据样本对RBF神经网络训练的影响及诊断精度,分别将约简前后的数据作为样本,训练2套神经网络模型。以约简前的数据建立的神经网络结构称为RBF1,该网络输入层为HC,CO2,O2,转速及转矩的归一化数据,隐层有8个神经元,输出层为决策属性(f);以约简后的数据作为样本建立的神经网络结构称为RBF2,该网络输入层为CO2,O2及转矩的归一化数据,隐层有4个神经元,输出层为决策属性(f)。表6示出CA6100发动机在失火现象和正常工况废气排放体积工况参数按照表5属性约简后的归一化处理值,利用MATLAB 7.0编制的RBF神经网络模型程序进行训练,表7示出2套神经网络模型的基本参数及训练情况。从表6可知,网络输出f值与期望值误差非常小,表明内燃机失火故障与排气成份的体积分数值、内燃机工况参数存在必然关系。从表7中可知,RBF2模型与RBF1模型相比,输入样本数和训练步数都减少了,而RBF1和RBF2的训练误差分别为0.009 4和0.000 61,说明经过粗糙集的约简处理,既简化了网络结构,又提高了网络学习效率和训练精度。
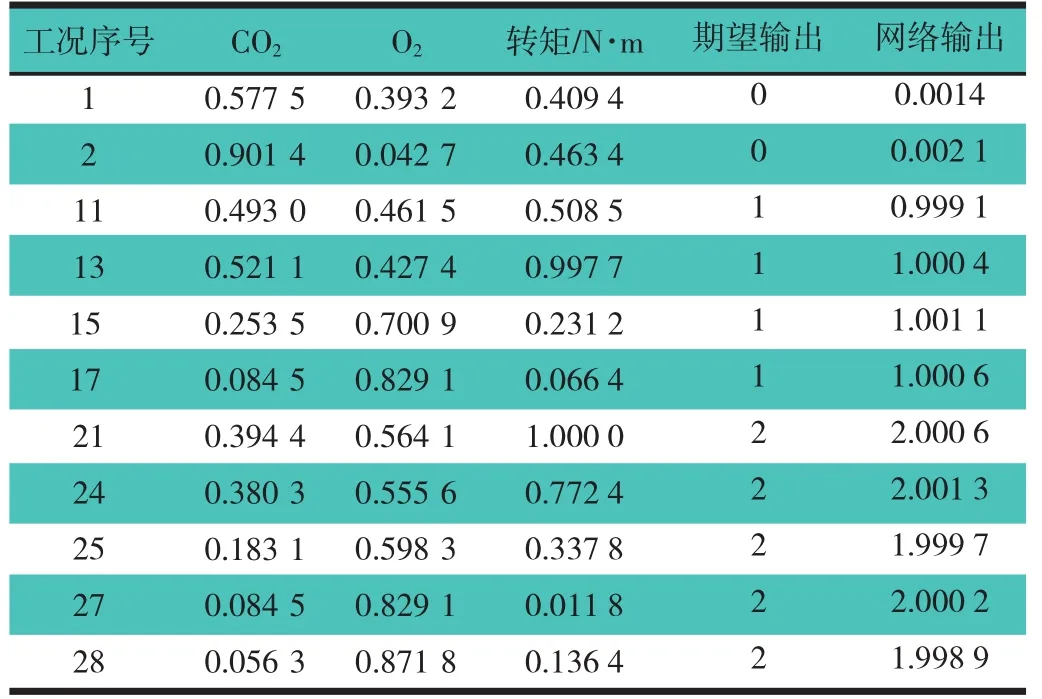
表6 失火现象和正常工况废气排放体积工况参数属性约简后的归一化

表7 RBF1和RBF2神经网络模型参数及训练情况比较
2.3 内燃机失火故障诊断结果
表8示出待诊断样本实测值及归一化处理值。对训练好的2套神经网络分别进行诊断测试,将这6组工况对应的废气排放HC,CO2,O2浓度值的归一化数值和转速、转矩的归一化数值作为RBF1神经网络输入进行诊断测试;将这6个诊断样本按照粗糙集规则约简后的结果作为RBF2神经网络的输入进行诊断测试,2种网络的诊断结果,如表9所示。从表9诊断结果可知,2套神经网络模型的故障诊断结果和实际设置的故障类型基本一致,能满足故障诊断精度的要求,但经过粗糙集约简后的RBF神经网络的诊断精度更高。
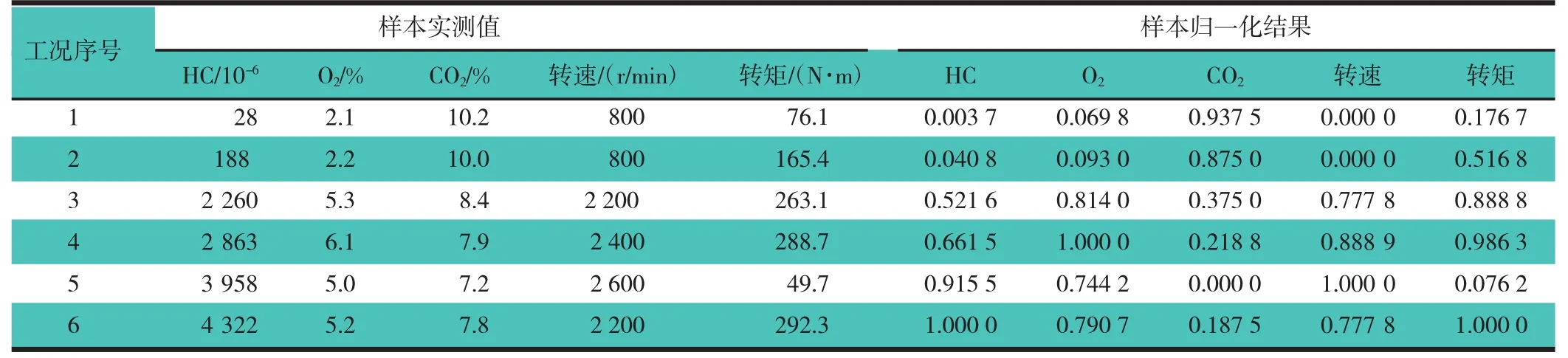
表8 待诊断样本实测值和归一化处理值

表9 RBF1和RBF2神经网络诊断结果比较
3 结论
1)提出了一种基于粗糙集的内燃机失火故障神经网络诊断方法,该方法利用内燃机废气排放成份携带的燃烧过程信息与内燃机工况参数,用粗糙集理论分析其属性集关系,化简输入样本,既优化了神经网络结构,也提高了神经网络学习速度和训练精度;
2)内燃机失火故障与排气成份的体积分数值和内燃机工况参数存在必然关系,粗糙集属性约简研究结果表明,废气排放中CO2,O2及输出转矩为主导属性,废气中HC和内燃机转速为次要属性,这表明在诊断内燃机失火故障时,可以不考虑废气中其他成份和内燃机转速;
3)基于粗糙集的内燃机失火故障神经网络诊断模型,便于工程实用,为内燃机其它故障诊断技术发展提出了参考思路和方法。
猜你喜欢
科教导刊·电子版(2021年6期)2021-05-06 05:05:10
中学生数理化·中考版(2019年9期)2019-11-25 09:39:48
成都信息工程大学学报(2019年2期)2019-08-28 10:00:46
——内燃机4.0 Highest Efficiency and Ultra Low Emission–Internal Combustion Engine 4.0
汽车文摘(2018年11期)2018-10-30 02:32:34
自动化学报(2018年2期)2018-04-12 05:46:01
成都信息工程大学学报(2017年1期)2017-07-21 14:14:11
厦门理工学院学报(2016年3期)2016-11-10 09:39:14
广东石油化工学院学报(2016年3期)2016-05-17 05:17:10
汽车零部件(2015年11期)2015-03-21 05:27:05
四川师范大学学报(自然科学版)(2015年1期)2015-02-28 14:07:21
