
基于共词分析和社会网络分析的国内外关联数据研究探析
2016-08-23 09:57邹美辰
现代情报 2016年3期
邹美辰
(1.中国科学院大学,北京 100049;2.中国科学院文献情报中心,北京 100190)
·管理论坛·
基于共词分析和社会网络分析的国内外关联数据研究探析
邹美辰1,2
(1.中国科学院大学,北京 100049;2.中国科学院文献情报中心,北京 100190)
准确把握国内外关联数据的研究方向及研究热点,梳理分析国内外关联数据的核心作者及核心团体,有效了解国内关联数据研究存在的问题与差距,以期为国内关联数据的后续发展提供借鉴与参考。以国内的CNKI和国外的Web of Science两个数据库中2006-2015年的相关文献为数据来源,运用共词分析和社会网络分析方法,分析整理该领域的研究方向及作者合作关系,并将国内外的相关情况进行对比分析。发现国内的研究相较国外存在一定的差距,认为在后续的发展过程中,国内应在深化已有研究方向的基础上,积极开拓新的研究方向,并加强作者和机构之间的合作关系,促进整个领域的知识传播。
共词分析;社会网络分析;关联数据;合作关系;聚类分析
关联数据(Linked Data)这一概念最初是由“万维网之父”Tim Berners-Lee于2006年提出的,之后便引起了国际范围内的广泛关注。其目的是构建数据之间的关联,形成一个能被计算机理解的数据网络(Web of Data),而不是传统万维网中仅仅能被人理解的文档网络(Web of Document)[1]。通过构建数据之间的关联,可以实现语义查询和知识发现等功能,从而将现存的信息孤岛整合成一个巨大的数据库。关联数据的提出具有划时代的意义,有效地推动了语义网的发展。
欧美对于关联数据的研究一直处于领先地位。2007年,W3C的关联开放数据(Linking Open Data,LOD)项目启动,极大地推动了关联数据的发展,包括英国广播公司(BBC)、美国国会图书馆(LOC)、瑞典国家图书馆在内的很多组织都开始参与到关联数据的发布当中。截止到2014年7月,LOD云图中的数据集已经达到570个[2]。近年来,国外又开启了关联数据研究的新阶段,趋向于将关联数据应用到知识发现和数据挖掘等前沿领域。
国内对于关联数据的研究则比较滞后,最早的研究始于2008年刘炜所做的引进介绍[3],随后刘炜等人又翻译了两篇关联数据领域的相关论文,分别为瑞典国家图书馆书目数据的关联化[4]和美国国会图书馆以关联数据的形式发布主题词表[5]。2010年之后,关联数据的相关研究开始出现大幅增长,达到高潮。但研究的重点主要集中于关联数据的概念、理论和发布等方面,相较国外存在一定的差距。因此,笔者认为对比分析国内外关联数据的研究情况是十分必要的,可以为国内关联数据的后续发展指明方向。
1 数据来源与研究方法
1.1 数据来源
为保证国内外研究数据的权威性,本研究选取的数据来源为国内的CNKI和国外的Web of Science两大数据库,检索时间为2015年6月27日。
国内数据的获取途径是在CNKI数据库中以主题词为“关联数据”或者“关联开放数据”检索2006-2015年的相关文献。同时为了保证查准率,将学科领域限定为“信息科技”,共得到文献589篇。经过人工筛选,剔除重复、无作者信息和非相关文献后得到有效文献270篇。
国外数据的获取方式则是在Web of Science核心合集中以主题词为“linked data”或者“linked open data”检索2006-2015年的相关文献,并在国家/地区当中排除中国和台湾地区。同样为保证查准率,将研究方向限定为计算机科学、图书和情报学、数学和医学信息学等领域,得到有效文献1 105篇。
1.2 共词分析
共词分析是内容分析法的一种,最初是在20世纪70年代由法国计量学家提出的[6]。虽然目前对于共词分析没有明确的定义,但文献计量学领域已经开始广泛认可和应用这种方法。共词分析就是通过统计某一领域相关文献中关键词对同时出现的情况,来揭示该领域的研究方向与研究热点,分析该领域的发展趋势。共词网络与其他传统网络最根本的区分就是其节点是抽象的知识单元而非有形的实体,是一种具有认知意义的知识网络[7]。
运用共词分析进行文献计量研究的步骤为:第一,确定分析的问题和领域;第二,确定该领域的高频词;第三,构建高频词共现矩阵;第四,运用不同的统计方法揭示该矩阵所包含的各种信息。
1.3 社会网络分析
社会网络分析起源于数学领域的图论[8],并因为小世界理论的提出得到学术界的认可和重视。社会网络分析研究的是一组行动者之间的关系结构及其属性,可以广泛应用于舆情监测、数据可视化和数据挖掘等领域。
近年来,社会网络分析开始广泛应用于文献计量学领域,对其发展产生了深远的影响。传统文献计量学采用的主要是基于统计思想的研究范式,而社会网络分析则重视对图形的绘制以及对结构关系的研究,有效地弥补了传统文献计量学对于合作关系、引用关系和知识结构关系分析的不足。
1.4 研究流程
本研究主要从两方面展开,一是探析国内外关联数据的研究方向和研究热点并进行对比分析;二是研究国内外关联数据作者合作情况,探寻两者之间的差异。具体的研究流程如图1所示。本文的创新之处在于,将社会网络分析和传统的文献计量学相结合,对研究领域进行多角度、全方位的分析。同时,在共词分析的过程中,不仅仅依赖软件分析的结果,而是将软件分析和具体的文章内容分析相结合,以达到更好的分析效果,得到更有价值的研究结论。
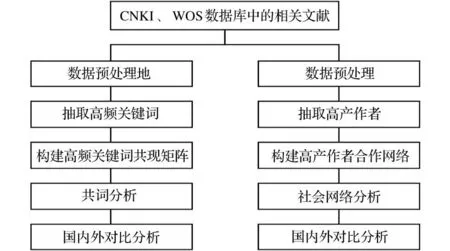
图1 研究流程图
2 国内外关联数据研究方向分析
当前关联数据已经经过了十年的发展,回顾国内和国外在这十年当中的发展历程,分析其研究方向与研究热点,对于该领域进一步的发展具有很强的指导意义。同时,有助于发现与国外的差距所在,为国内的后续研究指明方向。
2.1 构建关键词共现矩阵
在CNKI数据库和Web of Science数据库中分别以EndNote和HTML格式下载相关文献,并保存相应的文献题录信息。之后将其导入SATI软件[9]当中,提取文献的关键词并进行词频统计。为了全面地概括该领域的发展情况,同时减少低频关键词的干扰,将国内和国外相关文献中的词频选取阈值分别设置为4和8,得到高频关键词33个和36个。为了消除频次悬殊造成的影响,笔者使用ochiia系数构造高频关键词的相似矩阵[10]。相似矩阵中的数字代表关键词之间的相似性,数值越大表明相似性越高,反之相似性越低。国内和国外关联数据领域高频关键词的相似矩阵如表1、表2所示(由于篇幅所限,只给出部分数据)。
从相似矩阵中只能看出高频关键词两两之间的相似性,无法明确地表示其隐藏关系。为了进一步分析国内外关联数据领域的研究方向,需要采用聚类分析的方法。

表1 国内关联数据领域高频关键词相似矩阵(部分)

表2 国外关联数据领域高频关键词相似矩阵(部分)
2.2 聚类分析
聚类分析的主要任务就是基于数据对象之间的相似度,将其划分至不同的类别。聚类分析在共词分析中运用十分广泛,通过将高频关键词进行聚类,能够直观地展示该领域的研究方向与研究热点。
将表1、表2所示的相似矩阵导入SPSS统计分析软件当中进行层次聚类分析,得到的聚类结果树状图如图2、图3所示。

图2 国内关联数据领域高频关键词聚类结果树状图

图3 国外关联数据领域高频关键词聚类结果树状图
从聚类结果可以看出,国内在该领域的主要研究方向呈现为七大类,国外则大致分为十大类,笔者根据涵盖的高频关键词赋予其概括性的名称或含义,如表3所示。
从表3可以看出,国内外主要研究方向的前四类是十分相似的,但根据类别中的关键词和对文章内容的分析,其涵盖的内容和侧重点又有所区别。

表3 国内外关联数据领域主要研究方向
①关联数据的基本理论:国内在该研究方向上的文章大多为综述类的,介绍了关联数据的研究现状与最新进展,包括关联数据的概念、发布原则、应用情况以及面临的前景和挑战等。例如,潘有能等人对关联数据及其应用进展的研究[11],李琳阐述了关联数据在图书馆界的应用与挑战[12]。国外的文章则多集中于对特定技术和平台的研究,例如对某一具体关联数据集和技术工具的介绍。笔者认为产生这一差别的原因在于关联数据在国内的发展较晚,因此在目前阶段,综述类的文章占大多数。
②关联开放数据:国内在该方面的研究主要集中于分析关联开放数据的现状和应用以及关联开放数据的关联发现过程,大部分集中在理论层面。例如,严骏研究了关联数据的概念及应用[13],沈志宏、黎建辉等对关联开放数据关联发现过程的定位、目标和复杂性进行了分析[14]。国外则侧重于将关联开放数据和传统数据相结合或利用关联开放数据提供一些服务,大部分集中在技术层面。例如,利用DBpedia数据集开发关联数据移动浏览器[15]以及将关联开放数据和传统数据相结合,以提升数据挖掘的效果[16]。
③知识组织:国内在该方面的研究主要集中于利用关联数据改进原有的知识组织和管理方法,构建新的知识组织模式,并阐述其相对于传统方式的优势所在。例如,付旭雄基于关联数据的知识地图中知识链接的构建研究[17],以及牟冬梅、张艳侠等对于数字资源语义互联模式的比较研究[18]。国外在该方面的研究则集中于探索关联数据领域的词表和本体对于知识组织的促进作用,从文章内容分析来看,研究点更加明确具体。
④资源整合:国内在该方面的研究侧重于关联数据资源整合在图书馆中的应用,并构建了新的资源整合模式。例如,钟莉对于关联数据背景下图书馆信息资源整合的研究[19]。国外则侧重于资源整合过程中可视化技术的使用,从而构建新型的网络服务。例如,国外的Linked Jazz项目,以可视化的形式展示了爵士乐领域杰出音乐家之间的关联[20]。
通过上述分析,笔者以表格的形式对国内外在这四类研究方向上的侧重点进行了对比分析,结果如表4所示。

表4 国内外相似研究方向对比分析
下面笔者将对国内外在该领域的其他研究方向进行分析。国内的主要研究方向除了上述四大类,还包括数据挖掘与知识发现、关联数据的发布以及图书馆的知识服务。
①数据挖掘与知识发现:数据挖掘与知识发现是国内关联数据研究的新兴方向,国内在该方面的研究主要集中于知识发现研究体系和研究框架的建立,技术实现方面的研究较少,还不够深入和成熟。例如,李楠和张学福探索了有关关联数据知识发现模型和知识发现体系的构建[21]。
②关联数据的发布:国内在该方面的研究主要集中于关联数据的发布流程和发布技术。例如,夏翠娟、刘炜等人梳理了关联数据的发布模式和发布工具,并运用开源的语义网技术平台成功地将“中国历史纪年和公元纪年对照表”发布为关联数据[22],以及沈志宏、刘筱敏等人探讨了将科技文献和科学数据发布为关联数据的流程及关键问题[23]。但从文章内容分析来看,大部分的发布方式都是简单的将数据发布为RDF的形式,缺少本体和模型的支撑。
③图书馆的知识服务:国内在该方面的研究侧重于构建基于关联数据的图书馆知识服务模型,从而提升图书馆的知识服务质量,帮助用户更加高效地获取符合自身需求的知识。例如,贺令辉对于关联数据环境下高校图书馆知识服务的探讨[24]。
国外的主要研究方向还涵盖了大数据与社会化媒体、关联数据的质量、数据网络与互操作、实体识别、信息检索与语义查询以及云计算与众包。
①大数据与社会化媒体:国外在该方面的研究主要集中于将社会化媒体中产生的大量数据用关联数据和语义网的技术进行处理,以挖掘数据背后的隐藏信息。
②关联数据的质量:国外在该方面的研究主要集中于构建关联数据的原则和框架,以提升关联数据的质量。并且开发了一系列的工具和平台来验证关联数据的质量。例如,国外学者提出的绿色关联数据的原则和框架[25]。
③数据网络与互操作:国外在该方面的研究侧重于构建数据网络中的互操作机制和框架,包括模式变换、映射生成、查询转换和查询效率等。互操作机制对于用户获取和查询数据网络中的数据是十分关键的。
④实体识别:国外在该方面的研究侧重于探索实体识别的具体算法,以及一系列的关联发现框架。例如,Yves Raimond等[26]结合语义网中的音乐数据集,提出了基于文本匹配的互联方式以及基于图匹配的互联方式。国外的学者还提出了基于规则的关联发现框架SILK[27]和针对关系型数据的语义连接发现框架LinQuer[28]等。
⑤信息检索与语义查询:国外在该方面的研究主要集中于开发可用于信息检索的语义搜索引擎,促进隐形知识发现,为用户提供更加精准的检索结果。例如,Elbedweihy等概述了语义搜索引擎的评价方式[29]。
⑥云计算与众包:国外在该方面的研究主要集中于利用众包的方式进行关联数据的互联和集成,将机器和人工处理方式相结合。同时还探索了利用云计算处理大规模关联数据集的方法。众包指的是以自愿的形式,让大众参与到某个特定任务当中,涵盖了用户共创价值的理念。
通过以上分析可以看出:①国内外的主要研究方向存在重合,但具体的侧重点不同。国内重视理论层面的研究,而国外则偏重于技术。例如,对于关联开放数据的研究,国内侧重于关联开放数据的现状与应用,而国外则侧重于将关联开放数据与传统数据相结合,或利用其提供新型服务;在资源整合方面,国内注重资源整合在图书馆中的应用,以及新型资源整合模式的构建,而国外则注重可视化技术在资源整合中的使用。②国内是“面”的研究,而国外则是“点”的研究。例如,对于关联数据的基本理论,国内侧重于整个领域的研究现状与最新进展,而国外则侧重于特定的技术和平台;在知识组织方面,国内注重新型知识组织模式的构建,而国外则注重词表和本体对知识组织的作用。③国外的研究方向覆盖面更广,涵盖了一些前沿研究方向。例如,大数据与社会化媒体、信息检索与语义查询、以及云计算与众包等。而国内的研究方向则比较传统,在前沿方向上的研究匮乏,缺乏创新性。
笔者认为国内在后续的发展过程中,首先要深化已有研究方向,强调技术层面的研究。其次应逐步收敛研究方向,从“面”转移到“点”,注重特定的技术和平台。最后要加强对前沿方向的研究,提升研究的创新性。
3 国内外关联数据作者合作关系分析
运用社会网络分析方法分析作者合作网络,可以从总体上了解该领域的作者合作关系。同时通过网络密度与中心性分析,可以衡量该领域的知识流动性,识别该领域的核心作者与核心团体。
3.1 构建作者合作网络
将CNKI和Web of Science数据库中下载的相关文献导入SATI软件当中,提取文献的作者并进行发文量统计。由于构建整体的作者合作网络十分复杂,也不便于分析,所以为了能够直观地了解该领域的作者合作情况,需要进行作者筛选。笔者根据普赖斯定律选取了该领域的高产作者[30]。普赖斯定律认为,在相同的主题当中,半数的论文是高生产力作者完成的,高产作者的最低发文量计算公式如下。
其中,N为该领域作者最高发文量。在关联数据领域,国内发文量最高的作者为夏翠娟,发表论文13篇。国外发文量最高的作者为Auer,S,发表论文21篇。经过计算,分别选取国内和国外发文量大于等于3和大于等于4且存在合作关系的作者,构建作者合作网络。作者合作网络的构建需要借助UCINET社会网络分析软件,国内和国外的作者合作网络如图4、图5所示。图中的节点表示作者,连线表示其两端的节点在同一篇文章中出现,节点的大小表示与之有合作关系的合作者数量,连线的粗细则表示作者合作次数的多少。
从图中可以看出,国内核心作者之间的合作情况较少,且没有大型连通分量,网络的连通性较差。共有子网12个,最大的合作子网为5人的蛛型子网,其余大部分为双核子网和三核子网,子网内部的连通性较好。国外核心作者之间的合作情况虽然也不多,但存在一个大型连通分量,网络的连通性要明显好于国内。共有子网19个,最大的合

图4 国内关联数据作者合作网络

图5 国外关联数据作者合作网络
作子网为图5左侧的作者群,共62人。
3.2 网络密度分析
网络密度是指节点之间实际联结数目与最大联结数目之间的比值,比值越高,密度越大。一般认为,合作网络的密度越大,越有利于知识的传播,越能促进该领域的发展。经过计算,国内和国外的作者合作网络密度分别为0.0622和0.0227,整体结构都比较松散,知识的流动性较差,这一点在作者合作网络图中也能明显看出,但另一方面也说明该领域还处于成长期,有很大的发展空间。
国内的作者合作网络密度高于国外,并不是因为该领域在国内的发展较好,而是因为大型网络的密度一般都要小于小型网络。在实际生活中,一个人的精力是有限的,维持某些关系的能力也是有限的,所以大型网络的密度一般都较低。
3.3 中心性分析
中心性一般用于衡量一个节点的重要性,中心性越高,该节点在网络中充当的角色就越重要,中心性一般可以分为点度中心性和中介中心性。点度中心性衡量的是该领域的中心人物,作者的点度中心性越高,说明他与越多的作者存在合作关系。中介中心性衡量的则是该领域的枢纽或者桥梁,作者的中介中心性越高,说明他的桥梁作用越明显,其他作者必须通过其建立间接合作关系。
经过UCINET的计算,国内外关联数据领域点度中心性和中介中心性排名前10的作者,如表5、表6所示。

表5 国内外关联数据核心作者点度中心性
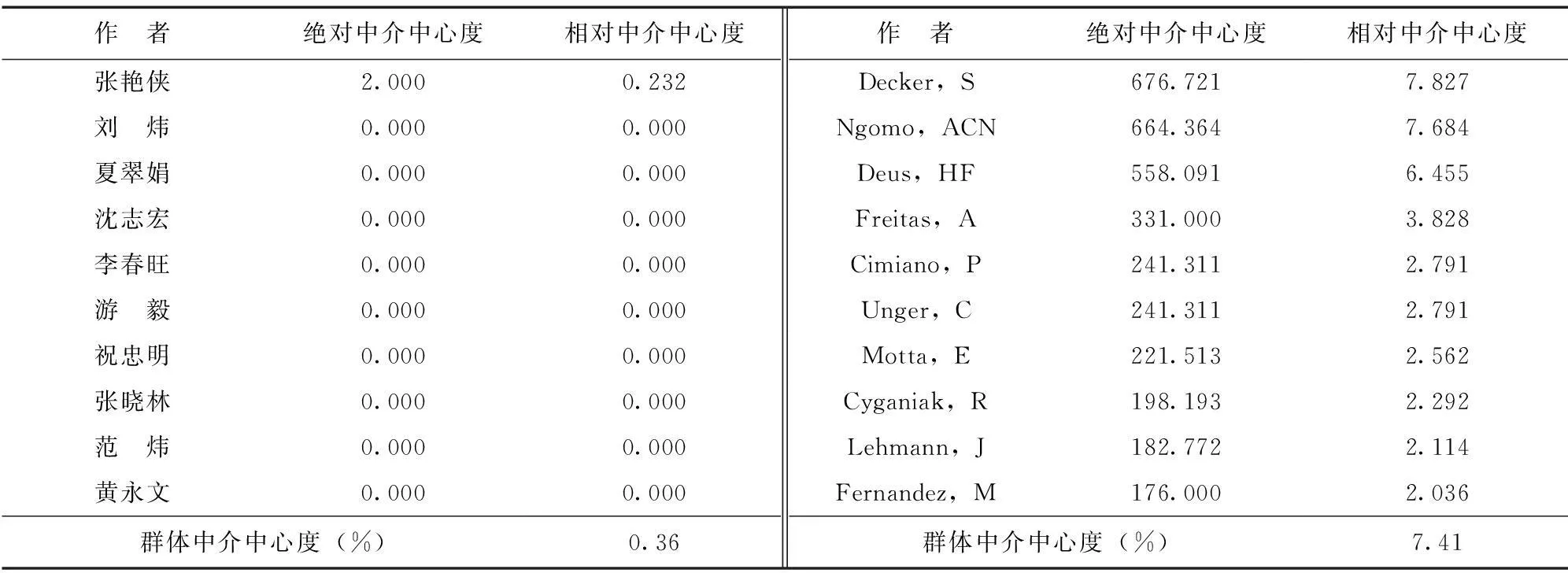
表6 国内外关联数据核心作者中介中心性
从表5可以看出,国内点度中心性最高的作者为付旭雄、周习曼、马倩倩、梁艳琪和高劲松,均来自于华中师范大学,绝对点度中心度为4.000,所占份额为0.054,是该领域的核心人物。国外点度中心性最高的作者为Decker,S,来自于爱尔兰国立大学,绝对点度中心度为16.000,所占份额为0.040,处于该领域的核心地位。国内和国外整个网络的点度中心度分别为5.88%和10.00%,说明国外的作者合作关系较多,而国内有待进一步提升。
从表6可以看出,国内中介中心性最高的作者为张艳侠,来自于吉林大学,绝对中介中心度为2.0,标准化中介中心度为0.232,说明其他人通过其进行沟通的可能性较高。整个网络中除了张艳侠之外,其他作者的中介中心度均为0,说明网络的连通性不好,各个合作团体之间的联系较少。国外中介中心性最高的作者仍为Decker,S,绝对中介中心度为676.721,标准化中介中心度为7.827,说明其占据该领域的枢纽位置。整个网络的中介性为7.41%,远远高于国内的0.36%,说明国外各个合作团体之间的联系更加紧密。
同时,国外有5位作者在点度中心性和中介中心性当中均排名前10,分别为Decker,S、Lehmann,J、Ngomo,CAN、Cyganiak,R和Deus,HF,说明他们既与较多的作者存在合作关系,同时也占有相对丰富的资源,应予以重点关注。
3.4 合作团体分析
合作团体的划分可以通过距离进行计算,在一定的距离范围内可达的节点为一个团体。利用UCINET软件中的N-派系分析方法,对作者合作团体进行划分。由于国内和国外作者数量差距较大,故选取不同的参数进行划分。在划分国内合作团体时,将距离设置为2,节点数量下限设置为3,划分结果为7个团体。
团体1,梁艳琪、高劲松、付旭雄、周习曼、马倩倩,均来自于华中师范大学,于2013-2015年合作发表论文3篇,第一作者均为高劲松,研究方向主要为关联数据的语义链接。
团体2,夏翠娟、刘炜、张春景、朱雯晶,均来自于上海图书馆,于2011-2015年合作发表论文9篇。团体中的核心人物为夏翠娟和刘炜,研究方向主要集中于关联数据的应用及其技术实现。
团体3,沈志宏、张晓林、黎建辉,均来自于中科院文献情报中心,于2011-2013年合作发表论文8篇。在该团体发表的论文当中,沈志宏均为第一作者,研究方向主要为关联数据的互联。
团体4,李春旺、黄永文、刘媛媛,均来自于中科院文献情报中心,于2011-2012年合作发表论文3篇,研究方向主要为关联参考服务的构建。
团体5,范炜、方安、洪娜,范炜来自于四川大学,其他来自于中国医科院医学信息研究所,于2012-2013年发表论文3篇,研究方向主要为医学关联数据的发展。
团体6,张艳侠、黄丽丽、毕强、牟冬梅,均来自于吉林大学,于2012-2014年合作发表论文5篇,研究方向主要为关联数据的语义互联。
团体7,王忠义、石义金、夏立新,均来自于华中师范大学,于2013-2015年合作发表论文5篇,第一作者均为王忠义,研究方向主要为关联数据的创建与发布。
通过对团体的分析,可以看出国内关联数据领域作者的合作关系受地域和机构影响较大,相同地区和机构的作者更容易形成合作关系。同时多数的合作关系为师生合作,随着学生的毕业,合作关系也就随之中断。目前,比较活跃的团体为团体1、团体2和团体7,其余团体没有最新的研究出现。
在划分国外团体时,将距离设置为2,节点数量下限设置为10,划分结果为11个团体。由于团体成员较多,不在进行一一列举。国外合作团体和国内的不同之处在于,不同团体之间存在交叉,且不局限于同一个机构,知识流动性较强。
基于上述分析,笔者认为,国内应首先加强作者和各个团体之间的合作关系,促进知识的流动。其次,合作关系不应受到机构和地域的限制,跨机构的合作更有利于该领域的发展,能碰撞出更多的思想火花。
4 结 语
本研究运用共词分析和社会网络分析方法,对国内外关联数据的研究现状进行了分析。分别以CNKI和Web of Science数据库中2006-2015年的文献数据为研究对象,分析了该领域的研究方向以及作者合作情况,并对国内外的相关情况进行了对比。通过分析得出:①国内外的主要研究方向存在重合,分别为关联数据的基本理论、关联开放数据、知识组织和资源整合。但具体的侧重点不同。国内重视理论层面的研究,而国外则偏重于技术;国内是“面”的研究,而国外则是“点”的研究。②国外的研究方向覆盖面更广,涵盖了一些前沿研究方向。而国内的研究方向则比较传统,在前沿方向上的研究匮乏,缺乏创新性。③国内外作者合作网络的密度较低,整体结构比较松散,知识的流动性较差,说明该领域还处于成长期,有很大的发展空间。④国内外作者合作网络的点度中心性和中介中心性存在较大差异,国外的作者和各个团体之间的联系更加紧密,连通性更好,而国内则有待进一步提升。⑤国内在该领域的合作团体相较国外受地域和机构影响较大,同时多数的合作关系为师生合作,随着学生的毕业,合作关系也就随之中断。
本研究一方面概述了国内外关联数据的研究情况;另一方面为国内的后续发展提供了意见和建议。当然,本研究也存在很多不完善之处,要对该领域有更全面的认识,还需要进行引文分析等研究,追踪知识的产生和积累过程。这也是笔者后续所要关注的。
[1]Tim Berners-Lee.Linked Data-Design Issues[N/OL].http:∥www.w3.org/DesignIssues/LinkedData.html,2015-06-20.
[2]State of the LOD Cloud 2014[N/OL].http:∥linkeddatacatalog.dws.informatik.uni-mannheim.de/state/,2015-06-21.
[3]付瑶,杨畔.基于共词分析的我国关联数据研究进展探析[J].图书馆学研究,2013,(4):18-24.
[4]Martin Malmsten.将图书馆目录纳入语义万维网[J].李雯静,译.现代图书情报技术,2009,(3):3-7.
[5]Ed Summers,Antoine Isaac,Clay Redding,Dan Krech.LCSH,SKOS和关联数据[J].现代图书情报技术,2009,(3):8-14.
[6]廖胜姣,肖仙桃.基于文献计量的共词分析研究进展[J].情报科学,2008,26(6):855-859.
[7]范少萍,李迎迎,张志强.国内外共词分析研究的文献计量分析[J].情报杂志,2013,32(9):104-109.
[8]滕广青,牟冬梅,任晶.国外社会网络分析在文献计量领域的应用研究[J].情报资料工作,2014,(1):47-51.
[9]刘启元,叶鹰.文献题录信息挖掘技术方法及其软件SATI的实现——以中外图书情报学为例[J].信息资源管理学报,2012,(1):50-58.
[10]刘春年,陈通.基于共词聚类的能源互联网研究热点及发展脉络分析[J].现代情报,2015,35(11):127-133.
[11]潘有能,张悦.关联数据研究与应用进展[J].情报科学,2011,29(1):124-130.
[12]李琳.关联数据在图书馆界的应用与挑战[J].图书与情报,2011,(4):58-61.
[13]严骏.关联开放数据概念及应用[J].信息与电脑:理论版,2014,(12):88.
[14]沈志宏,黎建辉,张晓林.面向LOD的关联发现过程的定位、目标与复杂性分析[J].中国图书馆学报,2013,(6):101-108.
[15]Christian Becker,Christian Bizer.DBpedia Mobile:A Location-Enabled Linked Data Browser[J].LDOW,2008,369-370.
[16]Paulheim Heiko,Fümkranz Johannes.Unsupervised generation of data mining features from linked open data[C].Proceedings of the 2nd international conference on web intelligence,mining and semantics.ACM,2012:31-42.
[17]付旭雄.基于关联数据的知识地图中知识链接构建研究[D].武汉:华中师范大学,2012.
[18]牟冬梅,张艳侠,黄丽丽.数字资源语义互联的模式及其比较研究[J].图书情报工作,2013,57(17):6-10.
[19]钟莉.基于关联数据的图书馆信息资源整合研究[D].杭州:浙江大学,2014.
[20]Lange Leanora,Pattuelli Maria Cristina.Linked Jazz:Building with Linked Open Data[N/OL].http:∥www.educause.edu/ero/article/linked-jazz-building-linked-open-data,2015-06-23.
[21]李楠,张学福.基于关联数据的知识发现模型研究[J].图书馆学研究,2013,(1):73-77.
[22]夏翠娟,刘炜,赵亮,等.关联数据发布技术及其实现——以Drupal为例[J].中国图书馆学报,2012,(1):49-57.
[23]沈志宏,刘筱敏,郭学兵,等.关联数据发布流程与关键问题研究——以科技文献、科学数据发布为例[J].中国图书馆学报,2013,(2):53-62.
[24]贺令辉.基于关联数据的高校图书馆知识服务探讨[J].图书馆研究,2013,(1):95-97.
[25]Hoxha Julia,Rula Anisa,Ell Basil.Towards Green Linked Data[C].COLD,2011.
[26]Raimond Yves,Sutton Christopher,Sandler Mark.Automatic Interlinking of Music Datasets on the Semantic Web[J].LDOW,2008:369.
[27]Volz Julius,Bizer Christian,Gaedke Martin,Kobilarov Georgi.Silk-A Link Discovery Framework for the Web of Data[J].LDOW,2009:538.
[28]Hassanzadeh Oktie,Kementsietsidis Anastasios,Lim Lipyeow,Miller Renée,Wang Min.A framework for semantic link discovery over relational data[C].Proceedings of the 18th ACM conference on Information and knowledge management.ACM,2009:1027-1036.
[29]Elbedweihy Khadija,Wrigley Stuart,Clough Paul,Ciravegnae Fabio.An overview of semantic search evaluation initiatives[J].Web Semantics:Science,Services and Agents on the World Wide Web,2015,30:82-105.
[30]邱均平,伍超.基于社会网络分析的国内计量学作者合作关系研究[J].图书情报知识,2011,(6):12-17.
(本文责任编辑:马 卓)
The Research of Linked Data in Domestic and Abroad Based on Co-word Analysis and Social Network Analysis
Zou Meichen
(1.University of Chinese Academy of Sciences,Beijing 100049,China;2.Documentation and Information Center of Chinese Academy of Sciences,Beijing 100190,China)
The paper aimed to grasp the research orientations and research focuses accurately,to analyse the core authors and the core groups related to linked data field in domestic and abroad,to understand the problems and gaps in domestic linked data research,and to provide advice to it in the following development.The paper took the related documents from 2006-2015 in CNKI and Web of Science database as the data sources.Based on the co-word analysis and social network analysis,the paper studied the research orientations and the cooperative relationships of authors in this field.After that,comparing the relevant situation of domestic and abroad.The paper found that the research in domestic was well behind abroad.It argued that the research in domestic should deepen the existing research orientations,develop the new orientations and strengthen the cooperative relationships of different authors and organizations,so that the knowledge dissemination in this field could be promoted.
co-word analysis;social network analysis;linked data;cooperative relationship;clustering analysis
2015-09-07
邹美辰(1992-),女,硕士研究生,研究方向:信息资源组织与建设。
10.3969/j.issn.1008-0821.2016.03.023
G203
A
1008-0821(2016)03-0135-09
猜你喜欢
计算机应用(2022年2期)2022-03-01
新世纪智能(数学备考)(2021年9期)2021-11-24
计算机应用(2021年4期)2021-04-20
计算机应用(2021年1期)2021-01-21
青年生活(2019年23期)2019-09-10
当代陕西(2019年15期)2019-09-02
学苑创造·A版(2018年11期)2018-02-01
读者(2017年5期)2017-02-15
中共南宁市委党校学报(2015年4期)2015-02-28
中国音乐教育(2014年7期)2014-02-06
