
基于分布式系统的大数据随机抽样算法的实现
2016-08-19 18:51王磐李勋张涛
电脑知识与技术 2016年20期
关键词:大数据
王磐++李勋++张涛

摘要:Hadoop是当前处理大数据环境的一套生态系统,按照层次结构为节点内的HDFS,根据该FS特性编写的RPC,MapReduce框架,Yarn管理系统,其中各层次可细分或进行全层次结构的整合,如HBase关注于数据存储方向,使用其中HDFS和RPC通讯对键值对数据进行转换并实现分布式存储,Spark关注于数据高速运算,通过高速缓存内存直接向上作用于RPC的机制和Yarn对资源的管理进行实时的分布式计算。该文根据在大数据中的快速进行有需求抽样的需求,对存储于HDFS中的大规模非结构化数据,RPC机制,及MapReduce中Map模块做深入研究。
关键词:Hadoop;大数据;随机抽样
中图分类号:TP311 文献标识码:A 文章编号:1009-3044(2016)20-0009-03
1 概述
在对海量数据进行数据建模时,通常会遇到性能与耗时的问题,由于部分的数据建模算法是不可并行的,例如迭代,所以需要对数据进行预处理来大幅减少耗时。在传统数据分析流程中,数据抽样是一个较为通用的方法,但海量数据中不一定适用,因此本文提出了一种在Hadoop生态环境下的海量数据抽样算法。本文将在第一章介绍技术背景,第二章阐述海量数据抽样的可行性,第三章提供具体的技术路线及实现方法,最后进行验证和总结。
1.1 背景
Hadoop目前已经更新在2.x的线路中,2.x引入最重要的机制是包含了MapReduce 2.0的Yarn架构.MRv2最基本的设计思想是将JobTracker的两个主要功能,即资源管理和作业调度/监控分成两个独立的进程。在该解决方案中包含两个组件:全局的ResourceManager(RM)和与每个应用相关的ApplicationMaster(AM)[1]。这里的“应用”指一个单独的MapReduce作业或者DAG作业。[9]RM和与NodeManager(NM,每个节点一个)共同组成整个数据计算框架。RM是系统中将资源分配给各个应用的最终决策者。AM实际上是一个具体的框架库,它的任务是“与RM协商获取应用所需资源”和“与NM合作,以完成执行和监控Task的任务”。总之它具有良好的并行能力但不具备对总体的可见性。
1.2 抽样在统计分析及数据挖掘中的意义
抽样是非全面的对数据进行分析,从研究的总体中按随机原则抽取部分单位作为样本研究,并根据这部分数据的分析结果来推断总体,以达到认识总体的一种统计方法。使用抽样的条件:
1)用于不可能或不必要进行全面分析的总体特征的推断。
2)用于分析模型的评价和验证。
抽样调查与大数据分析是有差别的,最大差别来源于数据表达上:前者抽样调查,后者全面记录;统计调查具有科学性、准确性、权威性。大数据具有不确定性、复杂性。就像望远镜让我们能够感受宇宙,显微镜观测微生物一样,成为新发明和新服务的源泉。大数据与统计数据相互佐证,差异较大。从大数据理论的最终要解决问题出发,大数据分析与传统的统计分析完全不同,其分析内容不再是总体或群体特征,而是对个体特征的预测,是不需要进行抽样的。大数据分析的目的是直接匹配答案,是不需要理解和解释原因的分析理念。[2]现在环境存在两个问题:1)能够获取的数据永远仅是数据的一部分。2)数据的处理能力远不及数据的产生能力。
所以在这个阶段依然需要使用传统的数学模型,进行抽样,建模,拟合预测。同样,存在这个问题还有大数据的排序。[3]在调查研究中发现,有许多利用大数据工具对数据进行排序的算法和相关研究。并且著名的TERASORT也依赖于Hadoop原生的随机抽样算法。
2 分布式系统下的抽样可行性
2.1 非分布式数据的抽样方法
通常需要抽样的情况都知道总体的大小,某属性的范围,例如从A中根据A1属性进行x随机因子的分层随机抽样:1.计算size(A);2.计算x*size(A),计算A1各值在x*size(A)中的占比;3.对每个标记A1值的子集进行抽样,合并。
2.2 蓄水池抽样算法
在大数据中,需要进行额外的一次数据遍历才能知道总量,甚至在有实时增量的数据中,知道总量是不可实现的,通常的解决方法是蓄水池抽样(Reservoir Sampling):从N个元素中随机的等概率的抽取k个元素,其中N无法确定。
算法流程描述为图1:
2.3 MapReduce数据处理模型
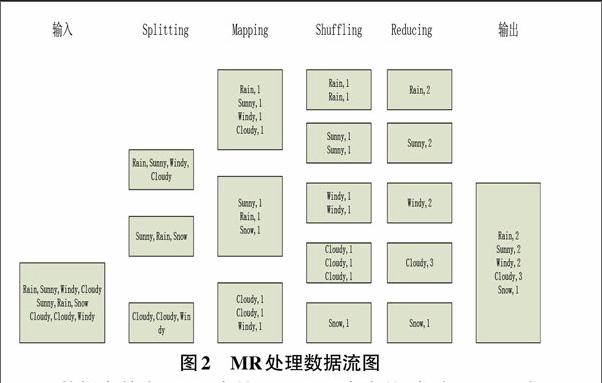
在海量数据中不知道数据总体的大小,数据总体不在同一片存储区,各存储区容量可能不同,无法用传统抽样方法或蓄水池法。使用MapReduce处理数据包含以下几个阶段,以WordCount为例,图2描述了在整个文章集中各个单词出现数量的统计过程。
数据存储在HDFS中是以BLOCK存在的,每个BLOCK有固定的大小及对应索引。在进入MapReduce程序处理前,形成建立KV值,根据当前集群的负载情况分成不定数的Split给Map处理。[6]Split记录的只是该片在文件中的起始字节偏移量,数据的长度,以及该Split所包含的第一个BLOCK所在的主机地址,而对文件的操作是从“一个具体的Input”的层面来读写数据,而不是从“一个BLOCK”的层面来读取数据。每台主机在Map阶段处理的仅是文件的某个片段,所以还需要一个对片段的结构描述,例如LineRecordReader,CSVRecordReader等,同样也可自定义RecordReader。
单个Map-Reduce任务的执行过程以及数据输入输出的类型如下所示:
Mapper的四个方法是setup,map,cleanup和run。其中,setup和cleanup用 于管理Mapper生命周期中的资源,setup在完成Mapper构造,即将开始执行map动作前调用,cleanup则在所有的map动作完成后被调 用。方法map用于对一次输入的key/value对进行map动作。run方法执行了上面描述的过程,它调用setup,让后迭代所有的key /value对,进行map,最后调用cleanup。Combine,Reduce的周期基本一致,在简单抽样的过程中,仅需要利用其setup和cleanup阶段进行数据扫描。
2.4 非等概率随机命中方法
大数据分而治之的思想无处不在,随机抽样也是如此,大数据在存储时已使用自身的算法对数据进行排序和索引。所以每个Split中的数据认为是均匀的,所以仅利用Map的抽样方法描述为:
对于样本数固定的抽样,在setup阶段利用近似估计法产生对应split中的随机数据的概率表,在cleanup中写入溢写区。
样本数为总体的百分比:
在setup阶段利用使用泊松分布计算某样本被选中的概率是否满足成为候选者,并记录下候选者。
setup阶段完成可知道某个split对应的样本总数。
cleanup阶段计算需要补足或删掉的候选者,由于候选数据是随机抽取完成,再次加入极少量数据不影响大数据下的随机性。[7]
3 抽样算法的实现
context.getConfiguration 获取抽样比例λ,数据结构描述,抽样方式参数组,伪代码描述:
3.1 抽样参数
一致性随机抽样可以使用伪随机,在BLOCK存储的数据是固定不变的使用随机种子可保证多次抽样结果一致。无放回的随机抽样中,需要保证每个独立样本如果可能被抽到,仅被抽到一次。上述算法描述即为无放回抽样。有放回随机抽样在Map中利用KeyValue值,在setup中通过泊松分布生成第一组随机数,该数字称为飞镖[8],在cleanup中对所有的飞镖再进行一次随机“射击”可保证每次“射击”都是该split中的全体数据集。
3.2 验证及性能优化
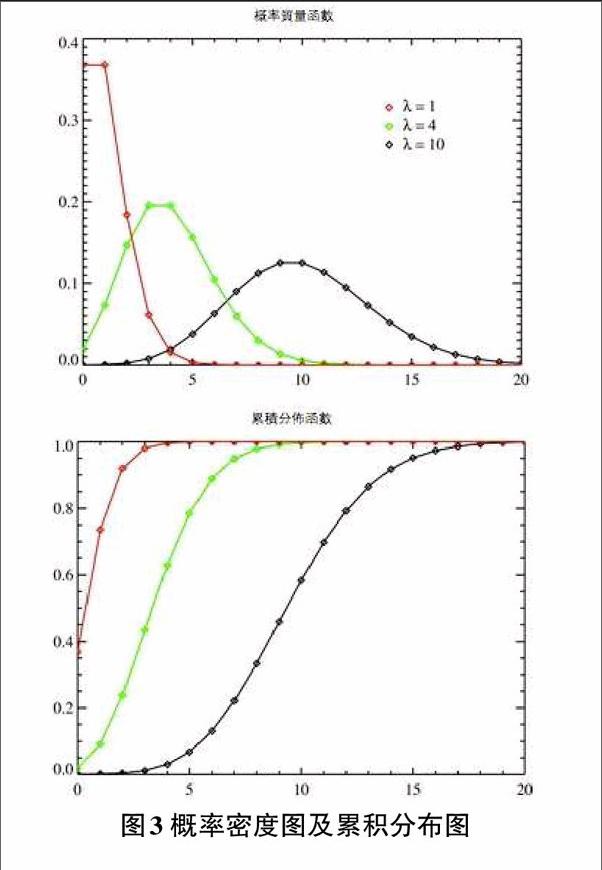
我们知道等概率的选取的样本应该满足正态分布,而正态分布的确定需要两个参数 λ和均值,其中的均值是无法得知的,而正态分布是二项分布的连续,从个体样本的选择出发仅有两种,备选和排除。在大数据中,假设数据量是足够大的,因此抽样过程可以描述为二项分布的极限情况,这正好符合泊松分布,参考图3在λ越大时,其分布图形趋近于正态分布,对应随机抽样分布:
根据德莫佛-拉普拉斯(De'Moivre-Laplace)中心极限定理,这列二项分布将趋近于正态分布。
合适的配置集群环境,数据处理速度影响最大的是非寄存器级的IO,所以分布的数据并非越多主机性能越优,在抽样过程的处理中,考虑到CPU高速缓存的处理速度大概是磁盘IO的10~100倍,及系统正常的负载,使用每个节点同时处理的MAP数量控制在10个。使用LZO压缩,MAP直接输出并未使用中间输出,不需要对缓存结果进行压缩和网络传输。调整Map和Reduce的数量到合适的值。根据分析逻辑使用Combiner使用最合适的Writable类型,无中间结果,重用Writable类型。
在节点内,各MAP再次分配对应64M的内存作为高速缓存,其中所有的local变量全部使用静态[7]。分析Task的运行
4 结束语
本文对应工程仅使用平均200秒完成对10^8条数据,共200G的数据的遍历,并仅使用一次遍历完成对工程未知规模数据的抽样。并通过100次20%的抽样对抽样的分布进行了拟合验证,验证结果表明完全符合泊松分布,测试曲线近似于正态分布,拟合度大于98%,符合在本文所处工程中的要求。
参考文献:
[1] Tom White. 华东师范大学数据科学与工程学院, 译. Hadoop权威指南3版[M]. 北京: 清华大学出版社, 2015.
[2] 李建江, 崔健, 王聃, 等. MapReduce并行编程模型研究综述[J]. 电子学报, 2011(11).
[3] 陈德华, 解维,李悦. 面向大规模图数据的分布式并行聚类算法研究[C]//第29届中国数据库学术会议论文集(B辑)(NDBC2012). 2012.
[4] ADAMS A, JACOBS D, DOLSON J,et al.The frankencamera: an experimental platform for computational photography. ACM SIGGRAPH 2010 papers,2010:1-12.
[5] DEAN J, GHEMAWAT S. Mapreduce: Simplified data processing on large clusters[J]. Communications of the ACM, 2008, 51(1): 107-113.
[6] GHEMAWAT S, GOBIOFF H.The google file system[C]. ACM SIGOPS Operating, 2003.
[7] 李超越, 徐国胜. Hadoop公平调度算法的改进[C]//第十九届全国青年通信学术年会论文集. 2014.
[8] 白永超, 付伟,辛阳. 基于Hadoop和Nutch的分布式搜索引擎研究与仿真[C]//第十九届全国青年通信学术年会论文集. 2014.
[9] 范东来. Hadoop海量数据处理 技术详解与项目实战[M].北京:人民邮电出版社, 2015.
