
大数据背景下个性化音乐推荐方案探究
2016-08-11 05:45管鹏,张键,顾杰
无线互联科技 2016年11期
管 鹏,张 键,顾 杰
(1.南京邮电大学 贝尔英才学院,江苏 南京 210046;2.南京邮电大学 通信与信息工程学院,江苏 南京 210003)
大数据背景下个性化音乐推荐方案探究
管 鹏1,2,张 键1,2,顾 杰2
(1.南京邮电大学 贝尔英才学院,江苏 南京 210046;2.南京邮电大学 通信与信息工程学院,江苏 南京 210003)
随着移动互联网和云计算等技术高速发展,网络音乐库数量和种类呈现爆炸式增长,这使得面向音乐数据源的大数据分析需求应运而生。文章针对热门的个性化音乐推荐服务,初步探讨了基于大数据挖掘的概念性方法,并且研习了一种个性化音乐推荐方案。
大数据;数据分析;个性化;音乐推荐
随着移动互联网、云计算等信息技术的飞速发展,各行业所产生的数据量已呈指数级方式增长,并且各种新型数据源种类也呈现指数性增长,所谓的“大数据时代”已悄然降临[1]。每天,人们在移动端以及PC端使用音乐软件上留下了海量的新型数据源,这个新型数据源既含有非结构化的各种格式音乐文件,也包含存储在后台网络日记中的点击率、时长等数据。对于这种数据源如何进行有效数据分析和利用成为一个音乐业务提供商或者相关的虚拟运营商能否提高企业绩效和长期生存的关键。这是因为:客户管理对于一个音乐业务提供商很重要,大量客户意味着企业绩效。对于采用网络方式的虚拟运营商,他们也需要通过各种新型音乐服务来吸引客户,从而开展自身的主流服务。如电信虚拟运营商经常发布免费的流行音乐来实现辅助的广告,最终提高电信服务体验。
本文主要探讨大数据分析技术在个性化音乐推荐服务中的应用。基本思想是:通过对用户数据的挖掘,提取出用户的行为特征以及兴趣偏好,可以有针对性的向用户提供个性化的音乐服务,进而提升用户体验和扩大用户群体数量。
1 一种个性化音乐推荐方案
1.1大数据概念和治理概述
大数据是指数量特别多、数据体量巨大、数据源种类繁多、数据增长极快、价值稀疏的复杂数据[2]。与其他资产不同,大数据作为一种信息资产,其价值需要运用全新的大数据治理思维和解决平台来实现。
1.2一种大数据环境下个性化音乐推荐
大数据环境下的推荐系统是传统推荐系统的延伸,但应着重考虑大数据环境给音乐推荐系统带来的影响。其特点如下[3]:①需要处理的数据量更大,且数据的融合会引入高维稀疏性数据,数据存在更高的冗余和噪声,因此这要求系统具备更高的数据处理能力;②大数据环境下,音乐系统产生的数据以隐式反馈数据为主(比如用户对歌曲的点击率,收藏与拉黑情况等);③数据更新速度更快,这要求推荐系统具备
更快的计算效率;④推荐的时效性,推荐系统必须能对数据进行快速实时处理,以满足用户的需求。
2 个性化音乐推荐系统分析
个性化音乐推荐系统是基于分布式数据平台的推荐系统,它通过对音乐库以及用户产生的海量用户行为日志进行分析,通过相应的推荐算法挖掘出用户的行为偏好,从而向用户提供个性化的音乐推送服务。
2.1大数据环境下个性化音乐推荐系统结构框架
推荐系统在进行相关设置时主要包含两个阶段[4]:数据预处理和推荐生成阶段。数据预处理阶段,推荐系统需要不断地将用户产生的结构化以及非结构化数据进行存储与提取。推荐生成阶段,推荐系统根据用户行为信息,利用相应的推荐算法,从数据集中产生用户推荐项目。考虑到数据数量的庞大,传统的存储与处理技术已不能适应大数据的要求,通常都是借助Hadoop分布式系统来进行存储处理。图1展示了基于Hadoop平台的个性化音乐推荐系统框架。借助Hadoop系统的个性化音乐推荐系统框架图1所示。
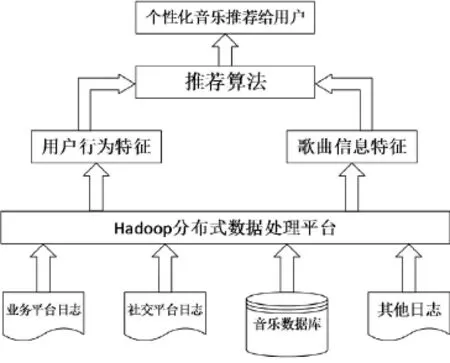
图1 基于Hadoop平台的个性化音乐推荐系统
2.2个性化推荐原理与算法
现在主流的音乐推荐方式是系统智能推荐。推荐系统通过机器学习的方式,根据同类人的偏好特征给相似的人群推荐他们都喜欢的歌曲,也有根据歌曲的内容推荐相似风格的歌曲。
综上,个性化音乐推荐的算法主要包括3种,即基于内容的推荐算法,协同推荐算法以及混合推荐算法。
2.2.1基于内容的推荐算法
基于内容的推荐算法,即最大相似度算法。其基本思想如下:首先根据用户的行为信息,比如用户收藏的曲目,用户经常点击的曲目等,分析这些曲目的特征(旋律,风格,歌手等)信息,以此构成该用户的特征向量,然后遍历音乐数据库,分析音乐库中文件的特征向量与用户的相关程度,选择其中相关程度较大的曲目最为推荐曲目推荐给用户。
2.2.2协同推荐算法
协同推荐算法,也叫作相似人群的推荐。它通过比较当前用户与其他用户对感兴趣音乐的相似度,计算出用户间的相似度,构成用户相似度集,从中选出与用户相似度最大的若干用户,将他们最喜欢的音乐推荐给用户。具体流程如下:
(1)将用户对于歌曲的喜爱程度做量化。比如:单曲循环=5,分享=4,收藏=3,主动播放=2,听完整首歌曲=1,跳过歌曲=-1,拉黑=-5[5]。则通过数据分析我们可以分析出不同用户对于不同歌曲喜爱程度的向量。
(2)生成相似人群集。即使用向量空间相似度的计算方法,通过计算向量之间的夹角余弦值来衡量用户之间的相似度。根据预先确定的相似度阈值,选择相似度大于阈值的作为相似用户,或者根据预先确定的相似用户数N,选择相关度最大的N个用户作为相似用户[6]。
(3)生成推荐集,即将某用户的邻居用户的最喜爱的歌曲进行排序,找到邻居用户最喜爱而该用户没听过的曲目,将其推荐给该用户。具体的实现过程如图2所示。
2.2.3混合推荐算法并根据各自的混合权重对音乐进行综合评分,选择评分最高的项作为推荐项。
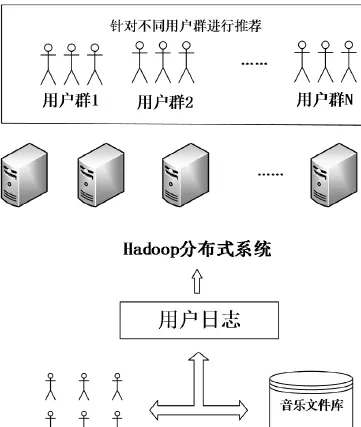
图2 协同推荐算法下个性化音乐推荐系统
3 结语
随着大数据时代的真正来临,分布式大数据挖掘平台Hadoop等开源项目正在不断发展和应用。在大数据治理思维下,业务提供商借助于这些平台来搭建个性化音乐推荐系统,这将有利于业务提供商向用户提供个性化音乐服务。对于高度稀疏性音乐数据,实际推荐的准确性往往难以保证。对此,今后音乐服务需要研究相关的大数据分析算法来提高数据分析的性能。
混合推荐算法,即融合内容推荐和协同推荐两种方案,
[1]盛杨燕,周涛译.大数据时代[M].浙江:浙江人民出版社,2013.
[2]徐宗本.大数据大智慧[N].人民日报,2016-03-15.
[3]孟祥武,纪威宇,张玉洁.大数据环境下的推荐系统[J],数据库与数据处理,2015(2):2-3.
[4]张玉忠,方艾,金铎,等.大数据在音乐推荐质量提升中的实践及应用[J].电信科学,2014(10):44-47.
[5]卢丽静,朱杰,杨志芳.基于大数据的个性化音乐推荐系统[J].广西通信技术,2015(1):
Analysis of the Personalized Music Recommendation Method Based on Big Data
Guan Peng, Zhang Jian, Gu Jie
(1.Nanjing University of Posts and Telecommunications Baer School of Excellence, Nanjing 210046, China; 2.School of Communication and Information Engineering, Nanjing University of Posts and Telecommunications, Nanjing 210003, China)
With the quick advancement of mobile internet and cloud computation, the number and variety of music databases expands exponentially, which gives rises to the data analysis that is focused more on these topics. This essay focuses on the recommendation of popular music, primarily explores the theorized method which is based on Data Mining, and analyzes a unique and personalized music recommendation method.
big data; data analysis; personalized; music recommendation
项目名称:南京邮电大学2015年STITP项目;项目编号:XYB2015525。项目名称:南京邮电大学2014MOOC课程建设计划;项目编号:2014MOOCA4专项。
管鹏(1995-),男,江苏淮安。
猜你喜欢
中国自动识别技术(2023年6期)2024-01-12
西安邮电大学学报(2022年2期)2022-09-19
环球时报(2022-08-16)2022-08-16
包装工程(2022年10期)2022-05-27
西安邮电大学学报(2021年6期)2021-05-10
计算机与生活(2018年3期)2018-03-12
金色年华(2017年8期)2017-06-21
中国科技期刊研究(2017年2期)2017-05-14
重庆邮电大学学报(自然科学版)(2016年6期)2017-01-03
中国化肥信息(2016年41期)2016-05-17
