
苏州园林网络评论意见挖掘研究*
2016-08-04 02:08:12包亮,张莉,许鑫
网络安全与数据管理 2016年13期
包 亮, 张 莉,许 鑫
(1. 南京思杰系统信息技术有限公司,江苏 南京 211106; 2.南京大学 计算机科学与技术系,江苏 南京 210093;3.华东师范大学 信息管理系,上海 200241)
苏州园林网络评论意见挖掘研究*
包亮1, 张莉2,许鑫3
(1. 南京思杰系统信息技术有限公司,江苏 南京 211106; 2.南京大学 计算机科学与技术系,江苏 南京 210093;3.华东师范大学 信息管理系,上海 200241)
摘要:对抓取的苏州园林网络评论进行意见挖掘,基于词、词性和句法模式利用CRF模型抽取评论句中的评价对象,利用SVM分类算法对评论句中蕴含的情感进行分类,获得了较为理想的实验结果,表明所采用的算法较为有效,有一定的实用价值。进一步,基于评论意见挖掘结果,对苏州园林中的5个典型园林主要从整体用户情感倾向判断和寻找园林特质这两方面进行分析探讨,揭示意见挖掘的重要应用价值。
关键词:意见挖掘;特征提取;情感分类;条件随机场;支持向量机
引用格式:包亮, 张莉,许鑫. 苏州园林网络评论意见挖掘研究[J].微型机与应用,2016,35(13):86-89.
0引言
旅行地的口碑是旅行者非常关注的问题,而在互联网上搜索总结景点评价费时费力且完整性差,情感分析正是一种利用计算机来自动识别主观文本中的情感倾向的一种技术。随着需求的增加,人们除了想获知对于某个对象的情感外,还希望获知所评价对象的若干方面的属性。Hu和Liu等[1]在2004年首次提出了基于产品属性总结对象的情感,这种技术是情感分析的进一步发展,被称为意见挖掘。
本文将利用意见挖掘技术抽取携程网、同程网和驴妈妈旅游网上游客对于5A级景区苏州园林的游记评论中的评价对象以及相应的情感倾向,并基于意见挖掘结果进一步揭示其隐含的应用价值。
1相关工作
意见挖掘通常包括三方面工作:主题抽取(也称为评价对象抽取或特征抽取)、观点表达抽取和情感判断,当然也可以直接根据情感词典进行情感分类而不单独抽取观点表达。意见挖掘自问世以来就引起了广泛的关注,成为国内外自然语言处理和数据挖掘领域的一个研究热点。
评价对象抽取主要采用三种技术,一是利用领域知识相关的规则和模板,二是基于领域本体知识库,三是基于语言模型或机器学习算法。其中机器学习算法是目前评价对象抽取的主流技术,它可以减少人工参与且能获得不错的效果。蒙新泛等人[2]和张盛等人[3]均利用条件随机场模型(Conditional Random Fields,CRF)进行评价对象抽取,刘非凡等[4]利用层级隐马模型(Hidden Markov Models,HMM)识别产品评价对象。
情感分类方面,可以根据情感分类的粒度将其分为两大类,一是单个词汇的情感分类,二是短语、句子和文档的情感分类。与评价对象抽取一样,机器学习算法也是主流的情感分类技术,例如PANG B等人[5]在2002年首次使用标准的机器学习算法朴素贝叶斯(NB)、最大熵(ME)和支持向量机(SVM)进行文本的情感分类比较,唐慧丰等人[6]将此研究在中文文本上进行了实践;刘康等人[7]基于层叠CRFs对句子的情感进行了分类。
本文将使用目前的主流技术即机器学习算法抽取评价对象和进行情感分类,评价对象抽取使用CRF模型,情感分类将使用SVM分类算法。
2网络评论意见挖掘方案
本文意见挖掘研究方案分为抽取评价对象和情感分类两部分。例如对于评论句“苏州园林中的建筑物都很气派。”,需要抽取的评价对象为“苏州园林中的建筑物”,情感为“褒义”。
2.1基于CRF的评价对象抽取
条件随机场模型(CRF)[8]是一种十分流行且有效的有监督学习算法。基于之前的实验结果[9],本文选择词、词性和若干个长度不超过5个词的典型的评价对象句法模式(结构)作为CRF的语言特征。句法模式如[状中结构+主谓关系](如“今日游客”),其以主谓关系为中心,在实际标注过程中,由程序自动按照模式顺序将设定的句

图1 利用CRF抽取评价对象实验结果
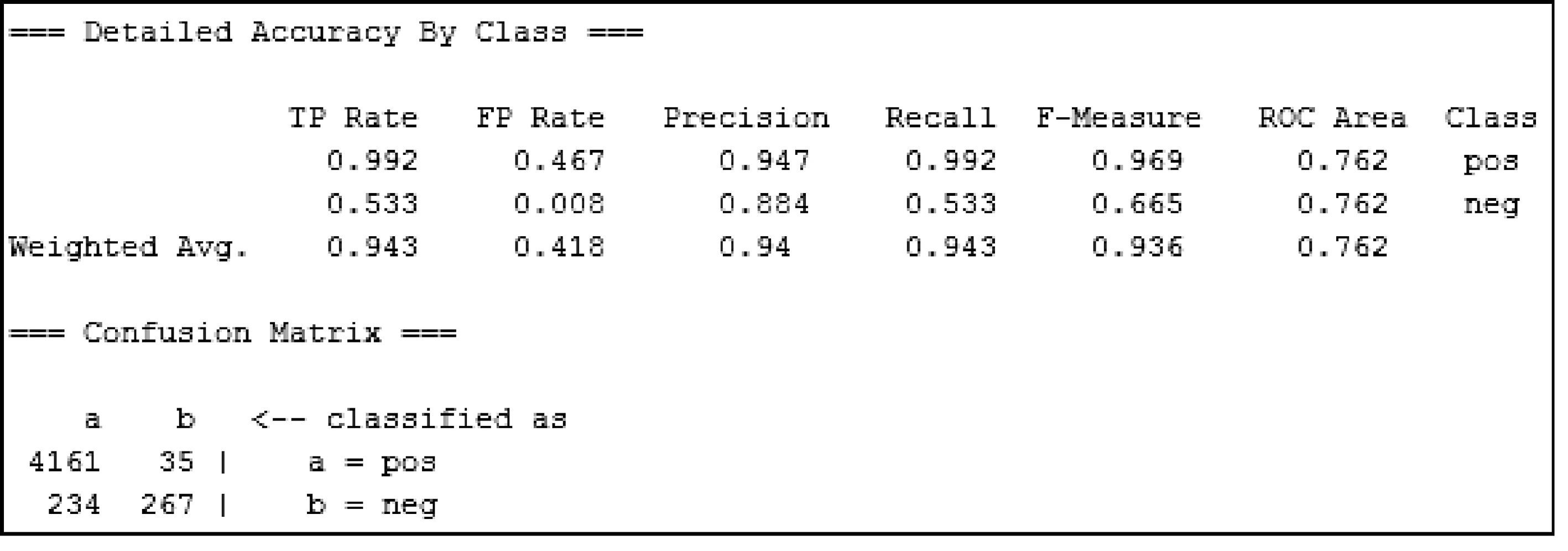
图2 用SVM进行情感分类的实验结果
法模式标出。
2.2基于SVM的情感分类
PANG B等人[5]和唐慧丰等人[6]分别使用NB、ME和SVM这三种经典的机器学习算法对英文文本和中文文本进行情感分类并进行比较,本文作者也在混合领域的语料上做了相似的工作[10],几个实验结果都可看出SVM在情感分类上具有明显优势,本文将选择SVM作为情感分类算法。
本文采用词作为向量空间模型的文本特征,考虑到数据稀疏问题,选择部分特有词性的词作为文本特征,唐慧丰等人[6]选取了名词、动词、形容词和副词这四种词性进行了实验,结果表明这四种词性的合集已经能够近似地反映整个文档的情感特征,本文又补充了名词修饰词、习语和缩略语,实验结果表明性能有所提高。因此,本文选用的词共有7种。
本文选择最常用的权重计算函数TFI-DF表示特征,使用经典的特征选择方法信息增益(IG)选择特征。
3实验结果与分析
3.1实验数据准备
本文所用的实验数据为2015年2月从携程网、同程网和驴妈妈旅游网上采集的游客对于苏州园林的游记评论,最终选取了有评价对象的4 697条评论,包含4 906个评价对象。由两名标注者对评论句中的评价对象、观点和极性进行标注,最后由第三名标注者进行统一,例如对于评论句“苏州园林中的建筑物都很气派。”,人工标注出评价对象、观点和极性,即:
{苏州园林中的建筑物; 很气派;1}
基于标注数据利用CRF和SVM分别抽取评价对象并进行情感分类。
3.2实验过程和结果
(1)基于CRF的评价对象抽取
在使用CRF进行评价对象抽取前,首先通过自行编写的Python程序将评论语句按照所选择的特征转化为组块(token)的格式。评价对象的抽取特征包含了词、词性和设定模式的句法结构,使用CRF(本文使用了CRF++0.58)进行训练需要使用的特征模板,词、词性和句法模式所选择的特征窗口均为5,范围是{-2, -1, 0, 1, 2}。
将标注后的数据文件交由CRF++0.58进行训练,利用上述模板生成模型,然后基于模型对待标注的评论句进行学习,本文使用5折交叉验证。将学习后的文件交由conlleval工具统计精确率(Precision,简称P值)、召回率(Recall,简称R值)和调和均值(F-measure,简称F值),实验结果如图1所示。
从图1可以看到,对于4 697条评论句中的4 906个评价对象,本算法共找到3 812个,其中正确的为3 559个,P值、R值和F值分别为93.36%、72.54%和81.65%。
(2)基于SVM的情感分类
对于4 697条评论句中标出的观点表达,利用自行编写的Python程序选择其中的名词、动词、形容词、副词、名词修饰词、习语和缩略语这7种词性的词或短语,并利用TFI-DF权重函数计算它们的权重。利用著名的数据处理工具Weka[11]将处理后的VSM表示文件导入Weka中。
首先利用Weka中的信息增益函数进行特征选择,使用默认参数值,然后使用分类算法SVM进行情感分类,本文使用台湾大学林智仁教授等开发的LIBSVM[12]并将其加入Weka 中,使用线性核函数(Linear),参数使用默认值,同样采用5折交叉验证,实验结果如图2所示。
3.3Baseline
将基于词和词性利用CRF进行评价对象抽取以及使用唐慧丰等人[6]提出的选择四种词性利用SVM进行情感分类作为Baseline与本文提出的方法做比较,实验对比结果如图3和图4所示。
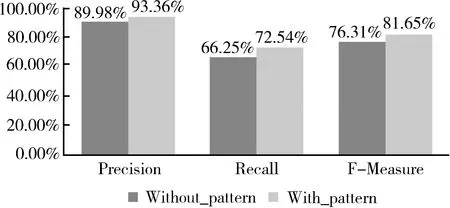
图3 基于不同语言特征的CRF评价对象抽取实验结果对比
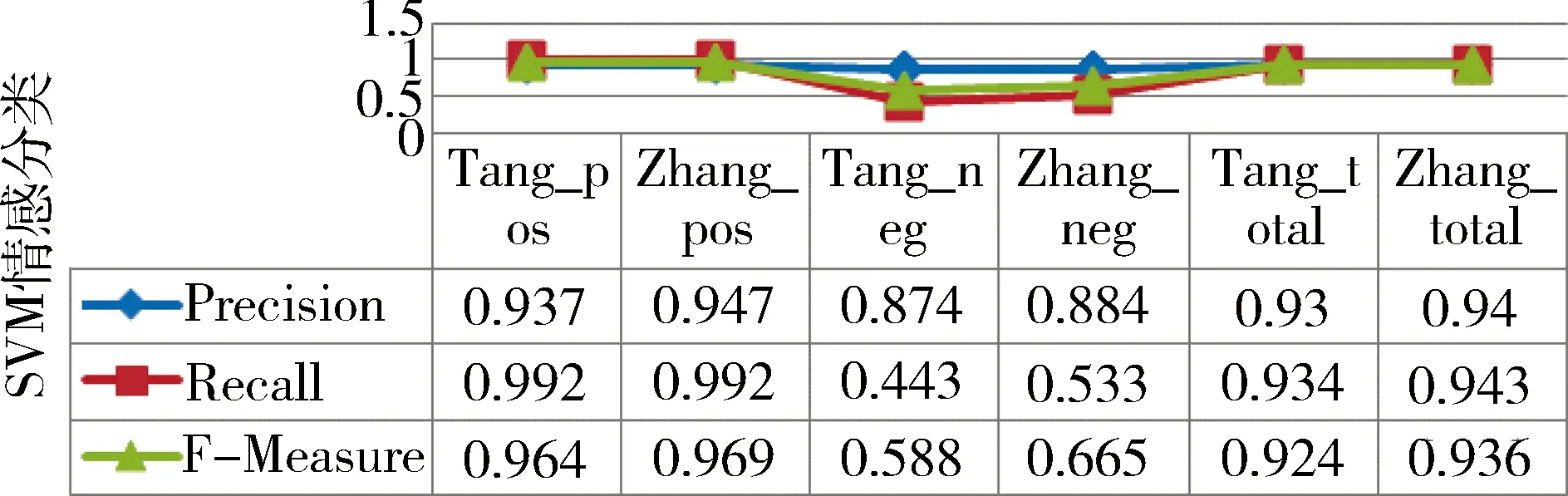
图4 基于不同语言特征表示的SVM情感分类实验结果对比
3.4实验结果分析
从3.2节“基于CRF的评价对象抽取”的实验结果来看,评价对象抽取的F值为81.65%,该结果在目前的同类研究中相对较好,但是也可以看到,算法执行后P值较高,R值还有一定的提升空间,究其原因是有部分评价对象因为网络评论句本身表现形式自由,因此在词性和句法模式上难以用统一的固定模式去限制和选择,所以导致有些评论句未抽取出评价对象,由此R值并不理想。而从另一个方面来看,只要是模式规范或相对规范的句式则抽取的准确率都很高,由此可以获得较理想的P值。从图3与仅仅使用词和词性这两个基本的语言特征利用CRF进行评价对象抽取的实验结果比较来看,增加句法模式这一语言特征对于CRF的特征抽取是有帮助的(F值提高了5.34%)。
从3.2节“基于SVM的情感分类”的实验结果来看,基于7种词性,利用TFI-DF作为权重计算函数,IG作为特征选择方法,SVM作为分类算法可以获得较为理想的实验结果,表明了所选择的策略和算法是正确的。另外从实验结果也可以看到,贬义情感分类的R值很低(0.533),表明有较多的贬义情感没有正确确定,究其原因是因为本文所用的实验数据中包含贬义情感的评论句比例很低(10.7%),因此难以获得较高的召回率。而与唐慧丰等选择四种词性的特征表示方法相比(图4),本文提出的方法在贬义情感识别上有比较好的表现,R值提高了9%,F值提高了7.7%,在褒义情感识别上性能也有所提高,整体来看F值有1.2%的提高。
4基于评论意见挖掘的旅游领域应用
可以基于CRF和SVM抽取的评价对象和情感倾向判断结果对数据中蕴含的其他信息进行揭示,其结果可以进一步应用在园林和其他旅游领域。本文以苏州园林中5个典型的园林为例进行若干数据分析,主要从整体用户情感倾向判断和寻找园林特质这两方面进行应用分析。
4.1整体用户情感倾向判断
以拙政园、留园、狮子林、网师园和耦园这5个最具代表性的苏州园林为例,通过自动统计用户对其的评论得到整体用户的感情倾向,结果如图5所示。
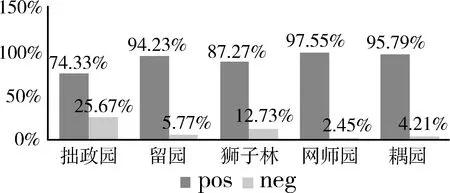
图5 用户评价褒贬比例
从图5可以看出,用户对5个园林的褒贬评价不一,拙政园的贬义评价最多,达25.67%,网师园的贬义评价最少,只有2.45%,这可能是因为拙政园在5个园林中最为有名,游客对其期望值较高容易产生失望。通过对贬义用户评论进行简单的词频统计发现,事实与猜测相符,用户的贬义评论主要集中在门票贵和人多这两个焦点上,而对于网师园和耦园由于游客的期望值不如拙政园,实际游玩时反而能够有惊喜因此负面评价少。
4.2寻找园林特质
根据用户评论中的情感词可以大致判断出某个园林的特质,本文通过对观点表达自动分词以及利用同义词词林聚类统计得到5个园林的褒义评价词,据此寻找园林特质。表1所示为每个园林的前10个褒义评价词。

表1 园林代表褒义评价词
通过集合操作可以去掉5组评价中共同包含的词如“美”和相当于共同包含的词如“精美”和“精致”(因为已包含“美”,可以认为“精美”=“精致”+“美”),大致可以得出每个园林的代表特质,例如拙政园与其他4个园林相比有“大”和“大气”的特点,如果喜欢有趣味的园林则可以选择狮子林,而网师园和耦园相对安静。
以上通过结合集合操作得到的结论也可以通过UCINET和NetDraw所生成的社会网络图推导得来。图6所示为利用5个园林的褒义评价词(包括了所有的褒义评价词,并且没有进行进一步严格的词合并)生成的社会网络图,在图中仍然可以看出拙政园与其他园林之间有较大的差别,拙政园和狮子林更具有自己的特色,网师园和耦园相对安静。
基于网络意见挖掘结果对整体用户情感倾向进行判断以及对园林特质寻找等进行分析,园林管理方可以根据其结果发扬或改善园林的优缺点,用户则可以基于这些结果进行游览的选择。依此构建用户推荐系统,有利于后续形成旅游产品开发方案或游览路线设计方案。
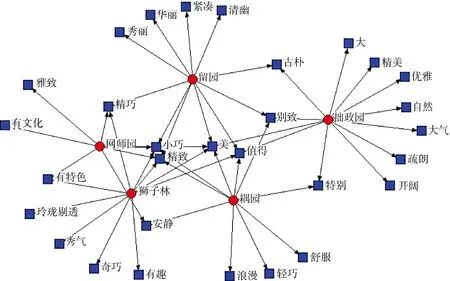
图6 基于用户褒义评价的园林特质关系网络图
5结论
本文提出利用CRF对苏州园林的评论抽取其评价对象,并且利用SVM对情感进行分类,获得了较理想的实验结果,表明所用算法较好,有一定的实用效果,后续将继续采集更多的网络评论,并扩展CRF所使用的语言特征以期获得更好的效果。同时基于意见挖掘结果从整体用户评论情感倾向和园林特质这两方面进行分析探讨,揭示其蕴含的应用价值。
本文提出的算法并不局限于某一个或一类景区,对其他景区同样适用,同时,这些算法也不仅仅适合旅游领域,除了传统的产品和电影等领域外,也同样适合用于微博和书评的意见挖掘中。
目前在人工标注方面较为费时费力,如何半自动地进行标注是今后研究的一个方向。另外,对于一个范围内各个园林或其他景区的自动聚类并为不同需求的用户推荐游览路线也将是今后研究的重点。
参考文献
[1] Hu Mingqing, Liu Bing. Mining and summarizing customer reviews[C]. In Proceedings of the 10th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining,2004:168-177.
[2] 蒙新泛,王厚峰. 基于CRF 的对象抽取及对象抽取的领域特定性研究[C]. 第一届中文倾向性分析评测论文集.北京:第一届中文倾向性分析评测委员会,2008:32-37.
[3] 张盛,李芳.基于迭代两步CRF模型的评价对象与极性抽取研究[J].中文信息学报,2015,29(1):163-169.
[4] 刘非凡,赵军,吕碧波,等.面向商务信息抽取的产品评价对象识别研究[J].中文信息学报, 2006,20(1):17-20.
[5] PANG B, LEE L, VAITHYANATHAN S. Thumbs up? Sentiment classification using machine learning teehniques[C]. EMNLP’02,2002:79-86.
[6] 唐慧丰,谭松波,程学旗.基于监督学习的中文情感分类技术比较研究[J].
中文信息学报,2007,21(6):55-94.
[7] 刘康,赵军.基于层叠CRFs模型的句子褒贬度分析研究[J].中文信息学报,2008,22(l):123-128.
[8] LAFFERTY J, MCCALLUM A, PEREIRA F. Conditional random fields: probabilistic models for segmenting and labeling or sequence data[C]. ICML 2001,2001:282-289.
[9] 张莉,钱玲飞,许鑫.基于核心句及句法关系的评价对象抽取[J].中文信息学报,2011,25(3):23-29.
[10] 张莉. 跨领域中文评论的情感分类研究[J].计算机应用研究,2013,30(3):736-741.
[11] Lin Zhiren. Machine learning group at the university of Waikato. Weka[EB/OL]. (2013-12-20) [2015-10-22].http://www.cs.waikato.ac.nz/ml/weka/.
[12] CHANG C C, LIN C J. LIBSVM算法[EB/OL].(2015-12-14) [2015-12-18]. http://www.csie.ntu.edu.tw/~cjlin/libsvm/.
*基金项目:国家社会科学基金项目(11CYY031)
中图分类号:TP309
文献标识码:A
DOI:10.19358/j.issn.1674- 7720.2016.13.028
(收稿日期:2016-03-11)
作者简介:
包亮(1976-),男,硕士,工程师,主要研究方向:蓝牙技术,Android系统开发。
张莉(1976-),女,博士,副教授,主要研究方向:自然语言处理。
许鑫(1976-),男,博士,教授,主要研究方向:网络信息处理与分析,管理信息系统。
Research on opinion mining about Suzhou garden network comments
Bao Liang1, Zhang Li2, Xu Xin3
(1. Citrix Systems Inc., Nanjing 211106, China; 2.Department of Computer Science and Technology, Nanjing University,Nanjing 210093, China; 3.Department of Information Management, East China Normal University, Shanghai 200241, China)
Abstract:This paper mines the opinions of Suzhou garden crawled from the network. CRF model is used to extract the features based on the word, part of speech and syntactic pattern. The SVM algorithm is used to execute the sentiment classification. Experiment result is good, showing the algorithm’s effectiveness and its practical value. Furthermore, from aspects of users sentiment analysis and gardens’ character finding, 5 typical ones from all Suzhou gardens are discussed based on the result of Suzhou garden opinion mining, which reveals the important application value of opinion mining.
Key words:opinion mining; features extraction; sentiment classification; conditional random fields; support vector machines
猜你喜欢
电子制作(2019年15期)2019-08-27 01:12:00
电子制作(2018年19期)2018-11-14 02:37:08
中国生物医学工程学报(2017年6期)2017-02-10 05:11:45
中国水运(2016年11期)2017-01-04 12:26:47
软件导刊(2016年11期)2016-12-22 21:52:38
电子技术与软件工程(2016年20期)2016-12-21 10:21:33
价值工程(2016年32期)2016-12-20 20:36:43
价值工程(2016年29期)2016-11-14 00:13:35
科学与财富(2016年28期)2016-10-14 21:19:17
广西科技大学学报(2016年1期)2016-06-22 13:10:38
