
一种电子商务协同过滤推荐算法
2016-07-28 09:04大连艺术学院辽宁大连116600
湖南城市学院学报(自然科学版) 2016年1期
关键词:电子商务
高 华(大连艺术学院,辽宁 大连 116600)
一种电子商务协同过滤推荐算法
高 华
(大连艺术学院,辽宁 大连 116600)
摘 要:依据当前社会发展趋势及电子商务发展要求,设计了一种以用户偏好挖掘为基础的电子商务协同过滤推荐算法。此算法将用户隐性及显性偏好知识,运用用户偏好挖掘技术进行深入挖掘剖析,促进以用户偏好知识的智能推荐及最近邻居社区的构建得以实现。从本次研究的实验结果显示,此种算法在预期效果上比较理想,对于协同过滤推荐的准确性和质量具有显著提升效果。
关键词:用户偏好挖掘;电子商务;协同过滤推荐算法
1 电子商务协同过滤推荐算法分析
首先,用户相似度计算。张尧等[1]通过运用AVD方法,对用户的评分数据特征进行降维处理,对不同用户之间所具有的潜在语义予以获取,并以此为基础,计算用户的相似度,运用此种方法,对协同过滤推荐系统的处理准确性及效率给与提升;扈中凯等[2]提出以知识处理机制为基础的用户相似度计算,对定性知识转换及表示采用云模型予以完成,针对传统用户相似度计算方法方面所存在的不足进行解决,促使以云模型为基础的协同过滤推荐的实现。其次,用户信任计算。杨芳等[3]提出以信任为基础的协同过滤推荐方法,开展推荐服务主要依据用户之间所存在的一种信任关系,以此达到推荐服务的效率及质量的不断提升。最后,用户偏好计算分析。方耀宁等提出以多目标优化双聚类为基础的协同过滤方法,通过将用户注册时所填写信息进行深入分析,对用户的具体需求及偏好予以获取,以此为基础采取具有针对性的项目推荐活动。以用户偏好为基础的协同过滤推荐方法,不仅可以依据用户所存在的实际需求及偏好,将与之相适应的商品及资源向用户进行提供,其为在互联网使用当中所存在的信息过载问题给与了很好的技术保证及辅助支撑。但是推荐系统所常使用的用户偏好信息大的黄匡,多数均为针对用户的显性偏好所设置,比如用户所进行的投票及评分等内容,然而针对用户所存在的隐性的相关偏好信息却没有予以考虑,诸如用户的购买动机及在商品页面所停留的时间等;与此同时,伴随时间的推动以及用户在具体认知上的不断变动,用户所存在的偏好信息也会发生改变,因此,这就需要充分运用推荐系统,对用户可能产生的需求变化进行相应的预测。对用户的偏好信息进行更为深层次的剖析,特别是那些所存在的隐性信息及可能变迁的信息,对用户需求及偏好进行及时掌握,以此达到推荐系统效率及服务质量的不断提升。
2 电子商务协同过滤推荐算法
2.1用户偏好挖掘
(1)显性偏好知识的挖掘。针对挖掘显性偏好知识,当用户对一些网页进行浏览时,其将用户的评论信息及文本信息等作为挖掘对象;本文针对用户显性偏好信息相应的挖掘和分析,主要采用K-means聚类算法予以完成,对用户所具有的偏好知识类簇给与获取。可将用户显性偏好信息进行采集,对其实施数据预处理,当处理完毕后,将所形成的文本文档集进行设置,本次研究对用户显性偏好知识挖掘主要步骤如下:对初始类簇进行构建,将在D当中的全部文档,均将其作为单个初始用户相应的偏好类别形式;然后将任意类别相应的差别方面的相似度),(jiccsim给与计算,将所设定的阀值ε给与利用,优化和合并初始类簇,即获取对最大相似度类别当 max>ε时,可以合并ci和cj,并将新类别ck=ci∪cj给与最终形成;当 max<ε时,那么就将 ci和cj相应的类别进行深入保持,并将D给与新的子类簇进行划分;然后,将上述当中,所得子类簇C,运用K-means算法,对相应初始聚类中心的种子集给与获取,将di到si相应相似度sim(di, si)进行计算,然后将di纳入至聚类中心si相应类别ci当中,然后可将最终的聚类结果予以获取。
(2)隐性偏好知识的挖掘。当用户对电子商务网站进行浏览时,其中所存在的许多动作都能对用户所存在的偏好给与暗示,比如在实际的Web页面当中,用户所进行的点击量、访问次数及停留时间等。本文针对用户的隐性偏好知识,在具体的相似性方面急性综合计算,分别采用簇间相似度及序列簇内相似度给与完成,采用 K-中心聚集的算法形式,对所存在的单一页面的用户偏好知识进行挖掘。然后依据以往研究经验,对在网络社交当中,依据用户自身所存在的兴趣,所设计的相应数据挖掘处理方法,将所收集到的用户自身隐性偏好信息实施相应的处理操作,最终将用户行为序列集予以获取,将初始簇数设置为 k,对行为簇内相似度进行计算:

公式当中,ki所代表的是当簇数为k时,在相应的聚类模式当中,其就是其中的第i个簇,而Sw(ki)所代表的是,在第i个簇内的平均相似度。针对簇间及簇内相似度的计算来讲,其具体的计算公式为:

在公式当中,Sb(ki,kj)所代表的是在行为序列簇i与簇j之间所存在的组间相似度。通过挖掘分析用户的行为数据,从中对用户内含的需求及偏好予以获取,还可根据用户所使用的具体界面状况,依据浏览当中所使用的具体使用及点击量,预测用户所可能拥有或存在的偏好变迁,对于用户还没有对某些商品进行评价来讲,可以根据用户以往的评价内容及所具有的显性偏好状况,对所需要的内容进行预测和深入分析,最终便可将用户的隐性偏好知识予以获取。
以上述处理方法可知,针对用户偏好空间矩阵的构建,可运用加权关键词矢量模型的方法予以完成,即:

公式中,ik所代表的是,在用户所用偏好当中的第k个偏好类型,而kω所代表的是,用户在偏好类型当中的第k个。
2.2最近邻居社区的形成
针对电子商务协同过滤推荐来讲,其在具体的环节方面,对目标用户相应的最近邻居给与准确定位,然而通过对用户之间的相似性进行计算,才能对最近邻居进行确定,通常情况下比较常用的方法为
(1)Pearson相似性。其所具有的计算公式:

式中,P所代表的是评分项目集合,而商品项目a所具有的评分,采用Ra,u进行表示,而所代表的是平均评分。
(2)余弦相似性。将用户u和v,根据n维项目空间当中所存在的位置状况,设计为m、n,以此,就可将用户在u和v之间相似性给与表示,即:

修正的余弦相似性。此种相似性,充分考量了不同用户所存在的各种评分方式给,公式如下:
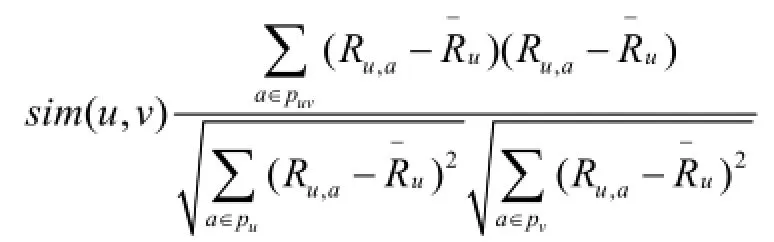
式中,pv,u所代表的是评分项目集合,而Pu及Pv所代表的是,用户在具体的u及v之间,所得出的评分过的项目集合,Ra,u所代表的是商品a所存在的的具体评分状况,所代表的是平均评分。
本文基于修正的余弦相似性,在用户相似度计算当中将用户偏好知识融入其中,公式为:
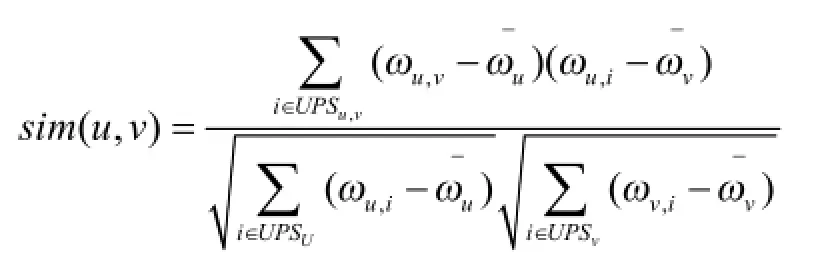
式中,UPSuv所代表的是用户u和v共同使用的偏好类型集合,UPSu代表的是用户u的偏好类型集合,而UPSv所代表的是用户v的相应偏好类型集合,ωi,u所代表的是用户u在偏好类型 i上相对应的权值,而ωi,v所代表的是用户v在相应偏好类型i上所具有的权值而及对用户相应u和v相应偏好类型所具有的平均权值。
在用户内在的空间中,将随机两用户之间相似度给与计算,满足其在用户聚类所具有的阀值φ,最终便可在最近邻居社区当中,得出相似或者相同的偏好类型。
2.3智能推荐
所谓智能推荐,就是依据修正的余弦相似性,所建立的最近邻居社区,将商品项目通过推荐操作改变为目标用户。首先,可将等待推荐的目标用户,采用m给与设置,并将其相似度设为sim。对于搜索目标用户m最近邻居用户来讲,可采用用户偏好空间UPS给与表示,最终将与m相同或相似的最近邻居集合给与得出,然而对于偏好类型i来讲,其UPS1与m之间所存在的相似性sim(m,UPS1)往往最高,以此进行类推。对于UPSmi当中的各个用户,用户各个偏好信息可进行相应加权平均操作,对目标用户相应需求及偏好进行预测,公式为:

公式当中,ωi,u所代表的是对用户u相应的偏好类型i的具体权值,其中,sim(m,u)所代表的是用户m与u之间所存在的相似度,和所代表的是相应的平均权值。利用上述公式,将所要预测的需求和偏好最高的相应前n项进行计算,最终向目标用户将Top-N给与推荐。
3 结束语
本文将用户偏好挖掘技术,在具体的协同过滤推荐当中给与有效融入,并以此建立以用户偏好挖掘为基础,在电子商务中给与运用的协同过滤推荐算法,针对此算法,与传统的协同过滤推荐算法相比较,其最大特点在于对用户的相似性进行计算过程中,不仅对显性偏好信息进行计算,而且还对隐性偏好信息进行计算,通过对二者信息的充分挖掘,然后对于用户存在相似性的偏好知识进行计算,最终促进以用户偏好知识为基础的最近邻居社区机制的形成,并基于此,针对用户的实际需求进行相应的智能推荐操作。
参考文献:
[1]张尧,冯玉强. 数据稀疏环境下基于用户主题偏好的协同过滤算法[J]. 运筹与管理,2014(02):145-152.
[2]扈中凯,郑小林,吴亚峰,等. 基于用户评论挖掘的产品推荐算法[J]. 浙江大学学报:工学版,2013(08):1475-1485.
[3]杨芳. 电子商务系统协同过滤推荐算法研究[D]. 天津: 河北工业大学,2006.
(责任编辑:吴 芳)
中图分类号:F724.6
文献标识码:A
doi:10.3969/j.issn.1672-7304.2016.01.053
文章编号:1672–7304(2016)01–0111–03
作者简介:高华(1975-),女,辽宁大连人,副教授,研究方向:计算机应用技术与电子商务。
A collaborative filtering recommendation algorithm e-commerce
GAO Hua
(Dalian Institute of art, Liaoning Dalian 116600)
Abstract:On the basis of the current trend of social development and the requirement of e-commerce development, we design a user preference mining based e-commerce collaborative filtering recommendation algorithm. This algorithm will be user's recessive and dominant knowledge, using the user preferences deeply analyzes mining mining technology, to promote to the user preference knowledge of intelligent recommendation and neighbor community building recently. From the experimental results of this research shows that this algorithm on the expected effect is more ideal, for collaborative filtering recommendation accuracy and quality have a significant boost effect.
Keywords:Mining user preferences; e-commerce; collaborative filtering algorithm
猜你喜欢
今日农业(2021年21期)2022-01-12
知识经济·中国直销(2018年10期)2018-11-06
现代营销(创富信息版)(2018年10期)2018-10-12
现代营销(创富信息版)(2018年9期)2018-09-03
时代金融(2017年1期)2017-02-13
中国商论(2016年34期)2017-01-15
山东工业技术(2016年15期)2016-12-01
现代商贸工业(2016年35期)2016-04-09
中国科技信息(2015年17期)2015-11-02
质量与标准化(2015年9期)2015-07-10
