
基于众包的数据库信息查询处理方法
2016-07-22 19:04王凡
电脑知识与技术 2016年16期
关键词:数据库系统
王凡

摘要:为解决传统数据库系统中,数据不完整或需语义理解时系统返回错误应答的问题,提出了基于众包的数据库信息查询处理方法。研究给出了基于众包的数据库系统的体系结构框架,并给出适用于该系统查询的类SQL语句,有效提高了数据库系统的信息处理能力。
关键词:众包;数据库系统;SQL语句;类SQL语句
中图分类号:TP311 文献标识码:A 文章编号:1009-3044(2016)16-0025-03
Abstract: In order to solve the problem of the data is incomplete or when needs semantic understanding the traditional database system returns an error response, this paper put forward the database information query processing method based on the crowdsourcing. Research shows the architecture framework of database system based on crowdsourcing, and given query types of SQL statements suitable for the system, which effectively improve the information processing capacity of database system.
Key words: crowdsourcing; database system; SQL semantics; SQL-like semantics
1 绪论
关系数据库系统不仅在最初预期的商业环境,而且在许多结构化数据如个人的、社会的,甚至科学信息等其他领域中得到普遍的应用[1]。然而,因为数据的创新和使用通过WEB网络,移动手机和其他技术变得越来越大众化,科学技术的限制越加明显。关系数据库管理系统对它们存储的数据做了几个关键的关于正确性、完整性和无歧义性的假设。当这些假设不被赞成,相关的系统会对用户的请求返回不正确的和不完整的应答,如果它们返回任何应答的话。
在关系数据库模型中,主要包括查询操作和插入、删除和修改操作两大部分。其中,因为关系的查询表达能力很强,是关系数据库操作中最主要的部分。然而,传统关系数据库中存储的数据都是结构化的,其查询也多为精确匹配。当数据库中所存信息不完整或需语义理解时,数据库常会对查询返回一个错误的应答。因此,仅仅依靠机器是不能应答所有的查询的。处理这些查询需要人的输入,以提供丢失的信息或加入人的判断。
现有的两种明显的状况是,数据不完整或需要对语义进行分析理解时。其中,数据不完整即信息的缺失。例如查询:
Select * from Student
Where name=”Wang Fan”;
会返回一个空的应答,如果在当时的数据库中,Student表中不包含一个“Wang Fan”的记录。这样一个记录的缺失,原因有多种:
1)遗漏。当录入Student表信息的时候,可能由于人为的输入而造成遗漏;
2)删除。可能在某些操作过程中,无意中删除了这一记录;
3)输入有误。如在本例中,“Wang Fan”这一记录,有可能被错误的输入为“Wang Fen”。
另一个问题是需要对语义进行分析理解时,例如查询:
Select * from SS
Where name=”CS”;
会返回一个空的应答,如果在当时的数据库中,“CS”被输入为“Computer Science”。对于人来讲,能够快速识别“CS”和“Computer Science”在现实世界中指的是同一实体,但对于机器而言,却无法进行识别。这其实也是判断的一种。另一种判断是,如查询:
Select idea from paper
Order By practical LIMIT 5;
找到5个最具实践性的想法,传统的关系数据库系统无法应答这样的查询,除非关于这些想法的实践性已经事先获得并存储在数据库中。
以上这些查询仅仅通过机器是不能被应答的,但可以容易的被人所应答。机器和人各有所长,因此,通过引入众包,来借助人的网络去完成不适合计算机执行的任务,从而有效的扩展传统关系数据库系统的信息处理能力。
2 众包
2.1众包
众包是继长尾理论后又一重要的商业概念,近年来得到广泛的关注。众包 (crowdsourcing) 这一概念是由美国《连线》杂志的记者杰夫·豪(Jeff Howe)在 2006年6 月提出的[2]。杰夫·豪对“众包”的定义是:“一个公司或机构把过去由员工执行的工作任务,以自由自愿的形式外包给非特定的(而且通常是大型的)大众网络的做法。具有低成本生产、联动潜在生产资源、提高生产效率,以及满足用户个性化需求等优势。
自众包概念提出以来,学术界对众包的定义一直没有公认的统一的界定。但是,从学者们对众包的概念分别从大众、企业、外包以及价值等多角度所进行的界定,我们可以总结出众包的基本特征:
1) 通过公开的方式来召集网络大众;
2) 众包任务一般是计算机单独难以完成的工作;
3) 大众通过协作或者独立的方式完成任务;
4) 是一种分布式的问题解决机制。
2.2众包的工作流程
众包的参与者主要有任务请求者[3],众包平台以及任务完成者。任务请求者需要通过众包平台来完成自己的任务,其工作流程为:
1)产生任务;
2)通过众包平台发布任务,等待任务的答案;
3)拒绝或接受任务完成者的答案;
4)整理任务完成者所返回的答案,完成自己的任务。
任务完成者的工作流程:
1)查找任务;
2)接受任务;
3)执行任务;
4)提交答案。
其具体流程如图1所示:
2.3众包应用于关系数据库系统
人类擅长某些特定的任务(如图像识别),但相对而言不擅长其他的一些任务(如数值计算)。同样,机器也有擅长与不擅长的工作。因此人和机器的能力可很好的相互补充。通过在传统的关系数据库系统中引入众包,可以很好的应答关系数据库系统无法应答的查询。
现有的微任务众包平台如亚马逊的土耳其机器人(AMT)[4]可以使人们以一种随需应变的方式来访问众包。这个平台提供基础设施,连通性和支付机制,允许成千上万的人在互联网上进行有偿工作。它提供了一种请求和管理工作的应用程序界面,其中任务请求者提供任务,工作者接受和执行任务。在我们这个基于众包的混合数据库系统中,通过使用一小部分请求人机输入的运算符来扩展传统的查询引擎,从而更好的使用这个平台。
3基于众包的数据库信息查询处理方法
在基于众包的数据库信息查询处理系统中,我们采用人机结合的处理模式,并采用类SQL语句来进行查询处理。
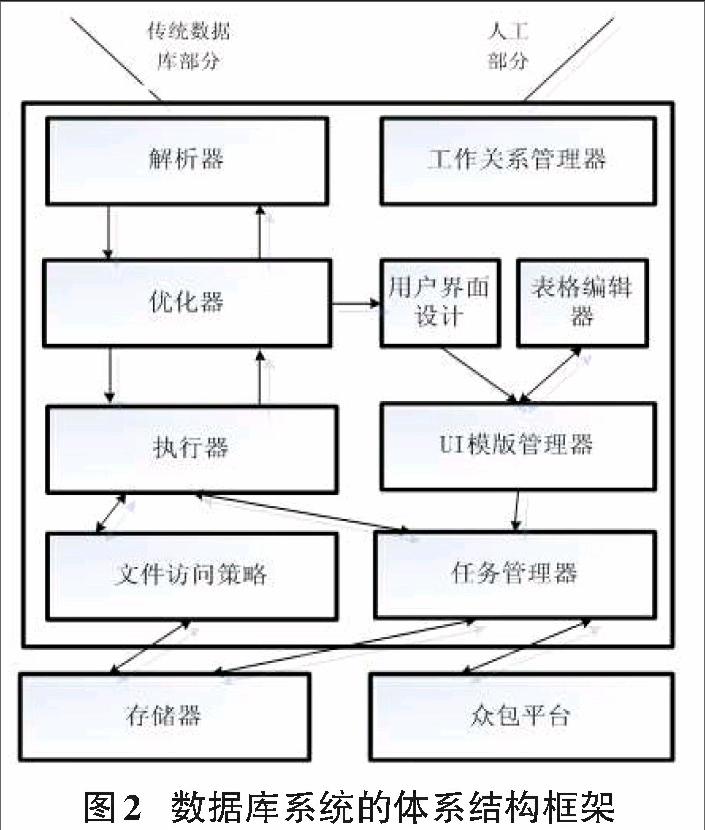
3.1数据库系统的体系结构框架
图2 展示了基于众包的数据库系统的体系结构的总体框架[5]。如果可能的情况下,会首先使用存储在本地表格的数据去应答查询,否则会调用众包。也即我们图中的机器可自动完成的传统数据库部分和需要人工输入的人工部分。如果传统机器数据库部分可以正确应答,则查询返回结果;否则,使用人工部分来调用众包,并且将通过众包所获得的数据存储在数据库中以便在未来的使用中无需重复操作。
如图中中间的传统数据库部分所示,众包数据库合并了传统数据库的解析器、优化器和执行部件,这些部件被扩展到处理人为的输入。在图中右半部分,是与众包平台相互作用的新部件。
工作关系管理器,在众包的使用中涉及人类工作者,与计算机处理器不同,因此众包工作者是不可代替的资源,并且任务请求者与任务工作者的关系会随着时间而发生改变,所以应注意培养和维持一个有效的工作池。工作关系管理器模块协助请求者及时的支付工人工资、发放奖金和报告并应答一些工人的意见。从长远来看,在改进结果质量,更好的反应时间和更低的代价方面起到很重要的作用。
与物理IO请求相比,众包的接口数据由自然语言的HTML表单和指令组成。CrowdDB用可获得的数据库模式信息生成HTML表单。这三个组件,UI设计,表格编辑器,UI模板管理器,负责创建、管理和编辑用户界面模板。
任务管理器提供了一个抽象层,它管理混合数据库与众包平台之间的交互。它实例化用户界面,使应用程序界面发布任务,评估他们的地位,并获得结果。任务管理器也与存储器进行交互,获取值预先加载到用户界面,并最终存储来自众包的应答结果。
3.2类SQL语句
在基于众包的数据库系统中,由于众包的引入,在对数据库进行操作时, 我们采用SQL语言的一个小的扩展即类SQL语句[6]。类SQL 语句与SQL语句的编写代码以基本相同的方式。即在大多数情况下,开发人员不需要知道他们的代码涉及众包。
对于传统数据库中数据不完整而导致查询错误的情况,有两种处理方式。第一,元组的特定属性可以被众包。第二,整个元组可以被众包。通过在SQL语言中添加关键字CROWD,即可完成这两种情况的处理。
例1:众包某一属性:在本例中的院系表中,URL属性被标记为众包。这种模型适合于新的院系自动生成时,其中,URL常不提供但可在其他的地方获得。
Create table Dept
University varchar(20)
Name varchar(20)
Url crowd varchar(20)
Phone varchar(11)
Primary key(university name);
例2:众包表:本例中模拟一个教师名单为一个众包表。这个例子对于人们只希望代表性的获得一个部分的教师的子集是适用的。即,如果要求处理特定的查询,那么众包数据库需要通过众包增加更多的教师。
Create crowd table teacher
Name varchar(20) primary key
Email varchar(11) unique
Dept varchar(20)
Foreign key (university,dept)
references dept(university,name)
为了表示众包列中还没有获得的值,类SQL语言扩展了SQL语言中的NULL为CNULL,它与NULL等价,用于表示当第一次使用它的时候该值应该被众包。另外,删除和更新语句在类SQL语句中没有改变。而对于查询语句,允许两个众包表格的连接和子查询。
除了找到不完整的数据,在基于众包的数据库系统中,另一个主要的应用是客观的进行比较。为了支持这种函数的功能,众包数据库新建了两个函数Crowdequal和Crowdorder。Crowdequal有两个参数(左值和右值),并访问Crowd去决定两个值是否相等。正如语法所说的,使用~=和一个插入表示法。正如在下列中显示的:
例3:当需要查询关于“CS”的所有信息时,可形成包含“~=”符号的查询,在数据库中,查询的编写者用可能的计算机科学的名称去请众包平台来进行解析。
Select * from SS
Where name ~=”CS”;
当排序或整理结果需要众包时,会用到Crowdorder。如以下例子:
例4:当需要查询最具实践性的5个想法时,可通过Crowdorder来实现。
Create table idea(
Idea varchar(20),
Subject varchar(20);
Select Idea from paper
Order by crowdorder(idea,which idea has the better practical)
LIMIT 5;
当完成这些查询时,其结果将会被存储在数据库中,以便众包被相同的查询只访问一次,从而提高系统的效率。
4 结束语
本文中,数据库和新兴的众包技术是我们研究的重要领域。基于众包的数据库信息查询处理方法的提出,很好地解决了传统数据库系统中无法应答的查询请求,有效的扩展了数据库系统的信息处理能力。人机结合来处理问题是未来应该关注的重要发展方向,具有很好的应用前景。
参考文献:
[1] Franklin M, Kossmann D,Kraska T, et al.CrowdDB: Answering Queries with Crowdsourcing[C]. In SIGMOD, 2011: 61-72.
[2] HOWEJ.The rise of crowdsourcing[J].Wired Magazing,2006,14(6):176-183.
[3] 冯剑红,李国良,冯建华.众包技术研究综述[J].计算机学报,2014,37(106):1-16.
[4] Feng M, Franklin D, Kossmann T, et al. Crowd DB: Query Processing with the VLDB Crowd[C]. Proceeding of the VLDB Endowment,2011,12(4).
[5] Trushkowsky B,Kraska T,Franklin M J.A Framework for Adaptive Crowd Query Processing[C]. AAAI,2013.
[6] 王珊,萨师煊.数据库系统概论[M].4版.北京:高等教育出版社,2006.
猜你喜欢
中国交通信息化(2021年10期)2021-12-31
电子制作(2019年24期)2019-02-23
数码设计(2018年10期)2018-12-29
电子测试(2018年14期)2018-09-26
制造技术与机床(2017年4期)2017-06-22
中国交通信息化(2017年11期)2017-06-06
电子世界(2017年17期)2017-04-14
电信科学(2016年10期)2016-11-23
网络安全技术与应用(2016年10期)2016-02-06
核科学与工程(2016年3期)2016-01-03
