
航天控制系统中国产化海量数据处理优化技术
2016-07-20 10:21:36刘孟语上官子粮赵玉梅
航天控制 2016年6期
刘孟语 张 洁 上官子粮 赵玉梅 杨 喆
北京航天自动控制研究所,北京100854
航天控制系统中国产化海量数据处理优化技术
刘孟语 张 洁 上官子粮 赵玉梅 杨 喆
北京航天自动控制研究所,北京100854

信息化的发展使得航天武器装备在控制系统试验和使用中产生了海量数据。针对国外设备安全性无法保障和国产化软硬件平台性能不足的问题,本文提出一种基于国产化平台的海量数据处理优化技术,确保数据处理系统可以安全、快速地处理控制系统的试验数据。首先,采用多处理技术和分布式并行计算2种方式,提升系统数据计算能力。随后,采用最小单元UNIT模式对数据进行分级抽样等预处理,减小数据入库、出库的压力。数据查询实验结果表明,系统的数据查询速率有了大幅提升,且实现了任意试验时间段数据的秒级加载。
海量数据;国产化数据处理系统;多处理技术;分布式并行处理;最小单元;分级抽样
随着信息技术的发展和普及,新一代航天武器装备试验数据规模显著增加,数据量呈现出爆炸式增长的趋势[1],对于航天武器装备而言,控制系统的数据处理需求尤为突出。控制系统不仅面临试验数据量增加的难题,同时对试验数据处理的时效性和准确性提出了更高的要求。为了应对海量数据带来的挑战,目前的武器研制试验通常采用云平台或数据库进行数据处理。但是云平台基于web应用具有潜在的安全风险,在少数情况下会产生数据丢失,这对于航天武器装备的研制是致命的缺点。国外的数据库虽然性能稳定,处理速度快,但是由于国外数据库及服务器等基础设备和软件存在各种漏洞和后门,严重影响航天武器装备的安全服役,所以亟需针对航天武器装备研制产生的试验数据的特点,研究基于国产化软硬件平台的航天武器装备海量数据处理技术[2]。
经过国家“核高基”重大专项的大力发展,目前我国在处理器、操作系统及数据库等领域都拥有自己的核心技术,并形成了产品。通过以往的对比实验可以得知,国产化平台在数据入库测试中用时为国外平台7倍以上,在提取数据测试中用时为国外平台5倍以上。本课题研究的数据处理系统由龙芯3A/B多核处理器、中标麒麟操作系统和达梦数据库等软硬件平台构成。由于国产化产品的性能不足,面对航天武器日益增长的数据压力,导致了整个系统在海量试验数据的存储和查询速度上,都难以满足控制系统的性能要求。
武器型号控制系统产生的试验数据为非关系型数据,需要对数据进行快速存储,实时回放,且需要对不同时间的数据趋势和范围进行研判和分析,其中包括几年试验数据的快速回放[3]。针对这个特点,本文通过开展基于国产化平台的数据处理优化技术研究,构建了一套完整、稳定和可靠的自主可控数据处理系统[4],实现海量试验数据的快速存储和实时查询,有效提升了航天武器控制系统研制的试验数据处理性能。

表1 国产化平台与国外产品性能对比表
1 系统计算模式
数据计算能力是海量数据处理过程中的核心能力。本文采用多处理技术和并行计算2种方式来提升数据计算能力。
1.1 多处理技术
衡量一个具有N个处理器的计算节点的性能指标可用式(1)表示。
(1)
式中,IPS(Instruction Per Second)为该计算节点每秒可处理的指令数,即此计算节点的性能。MF(Main Frequency)为处理器的主频,IPC(Instruction Per Clock)为每个时钟周期内可执行的指令数,F为计算工作中不可被并行化的部分所占比例,N为处理器数量[5]。

图1 SMP架构
在其他参数确定的情况下,N值越大,计算节点的处理能力IPS值越大。为了提高系统的计算能力,采用SMP架构的多处理器服务器。图1为SMP架构图。
由于国产化平台的单机性能过低,为了提升系统的数据处理能力,只能通过增大式(1)中处理器的数量N来实现。因此,采用刀片服务器的模式设计服务器系统[6]。图2即为本系统所使用的刀片式服务器的架构图。
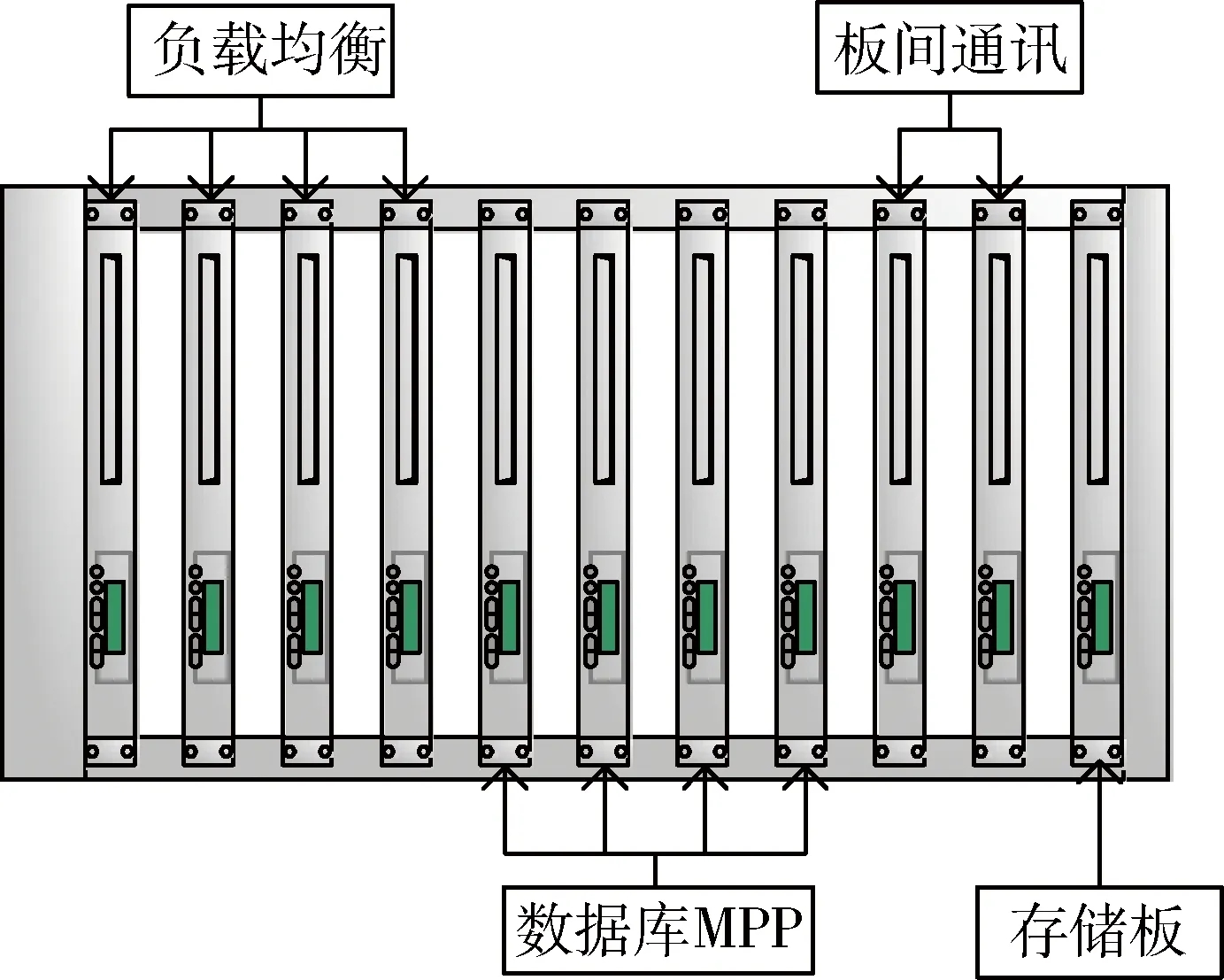
图2 刀片式服务器架构图
1.2 基于分布式并行处理
数据解析和数据分发可以提升计算任务的并行度,即可以降低公式(1)中的参数F,从而提高系统的并行比例。采用区域分解方法(Domain Decomposition),基于数据类型和数据量的大小,将所需要处理的数据分解为数据量相近的最小UNIT单元,然后将与这些子数据集相关的计算过程进行划分,最终得到分级抽样、数据压缩和批量导入3个子任务。
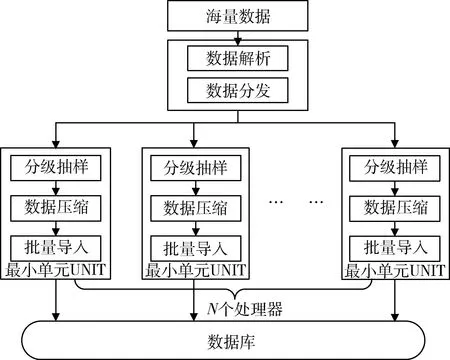
图3 并行处理示意图
1.2.1 数据解析
针对数据的特点,进行消息的解析。数据解析软件采用数据模板的方式,将数据的结构定义在脚本中(XML),实现加载不同的脚本模板,解析不同的消息,并在数据库中建立不同的数据库表项的功能。
当同一类型的试验数据被分发到不同的处理器中进行并行处理时,可能会因为不同处理器的处理时间不同,导致该类型的试验数据不按时间的先后顺序存储,造成试验数据的混乱。
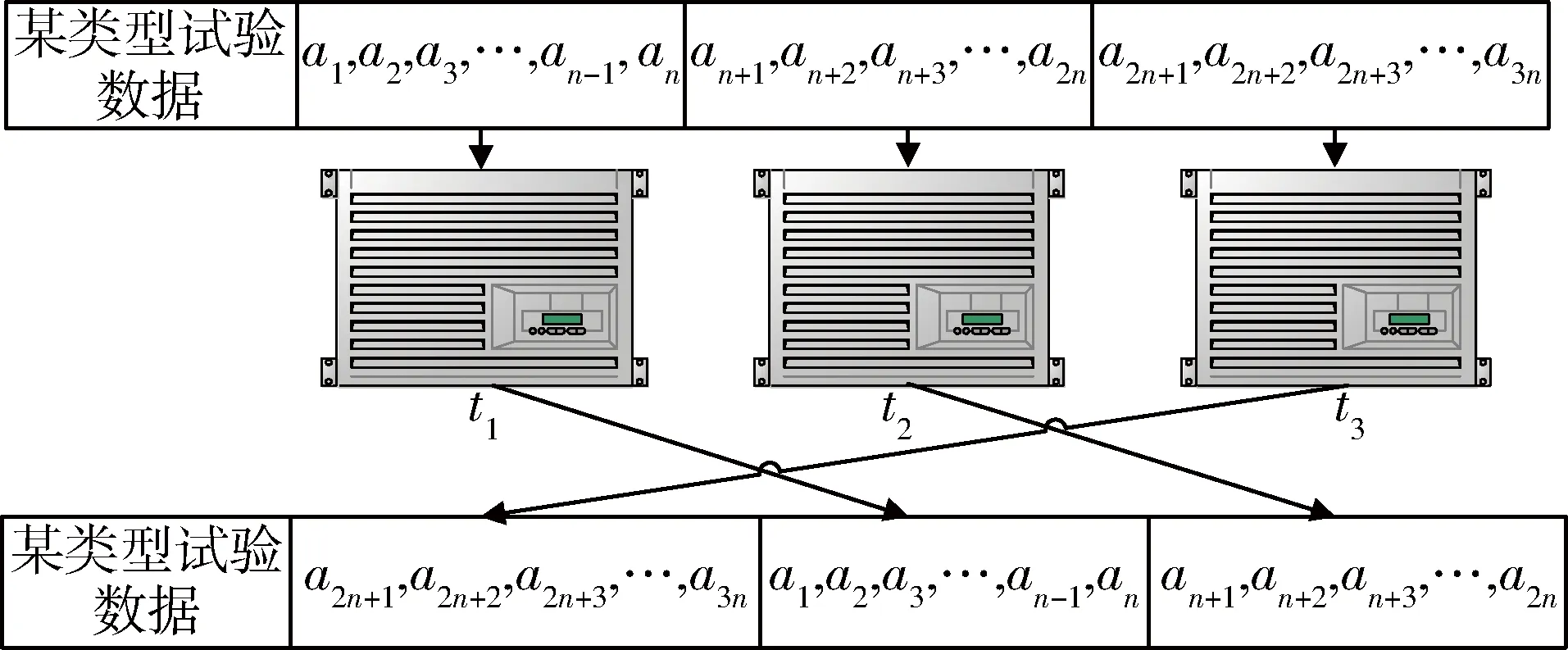
图4 某类型试验数据的并行处理示意图
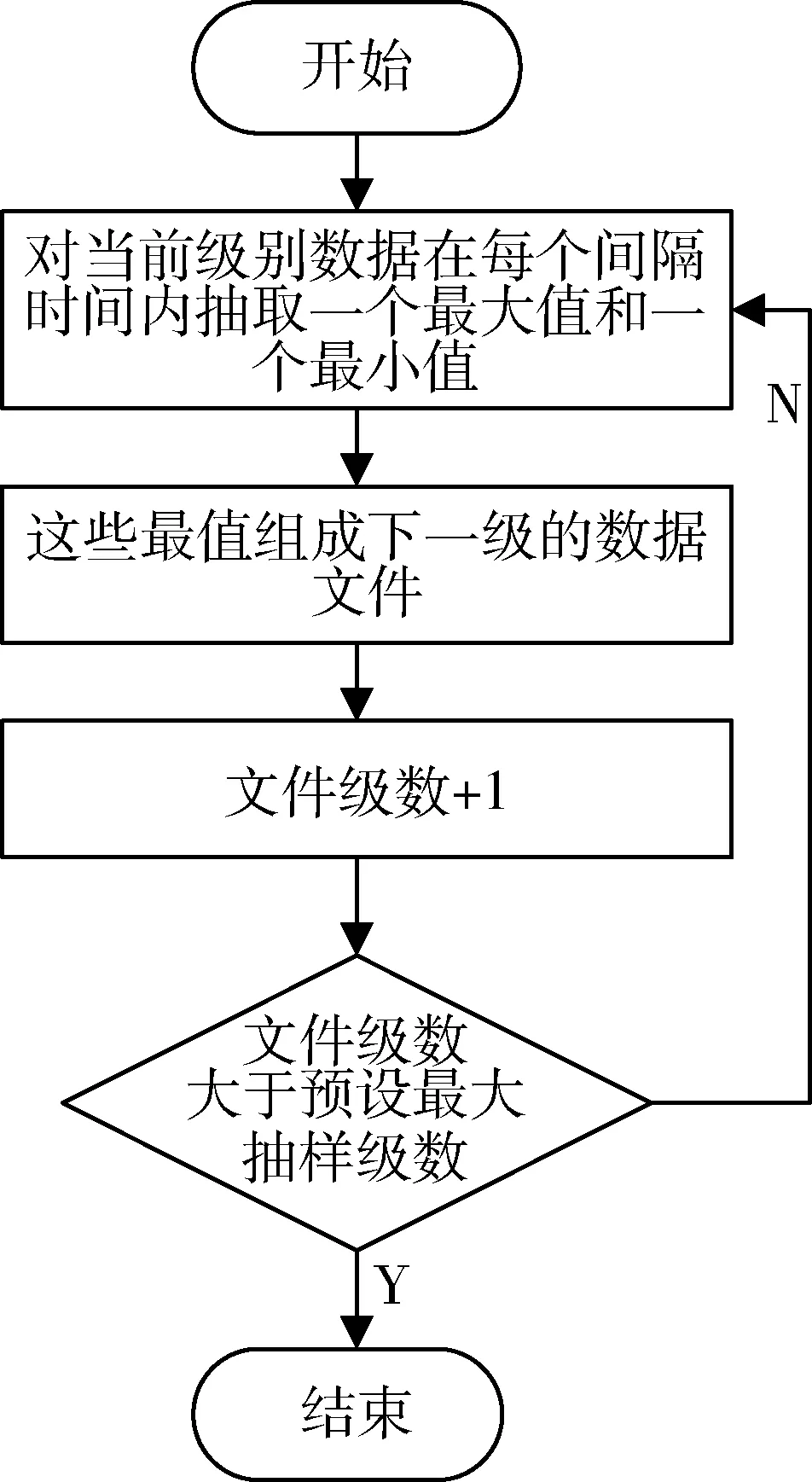
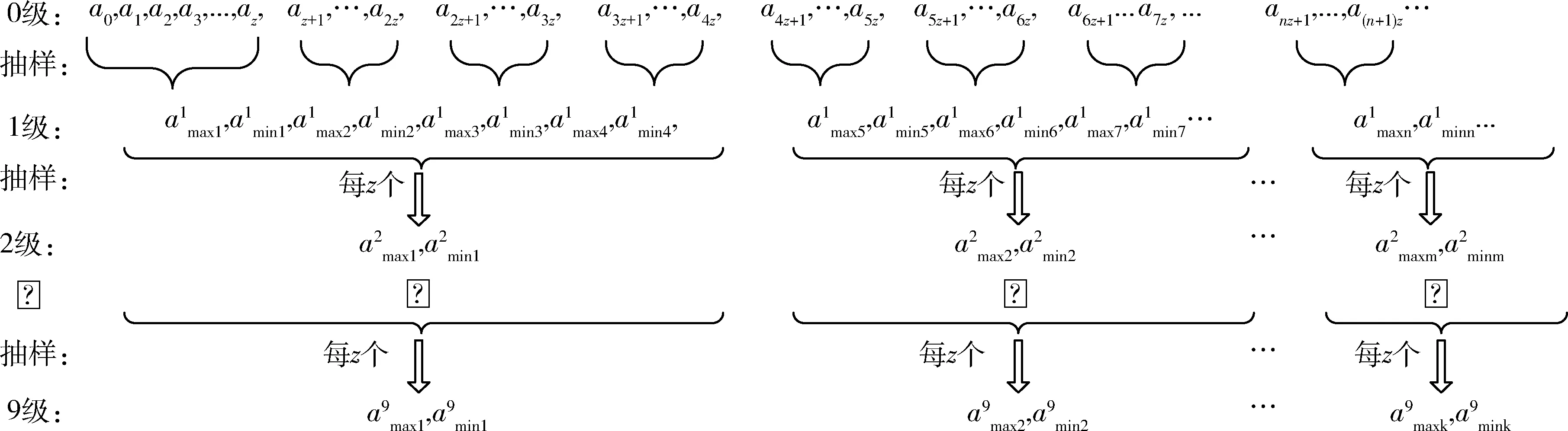
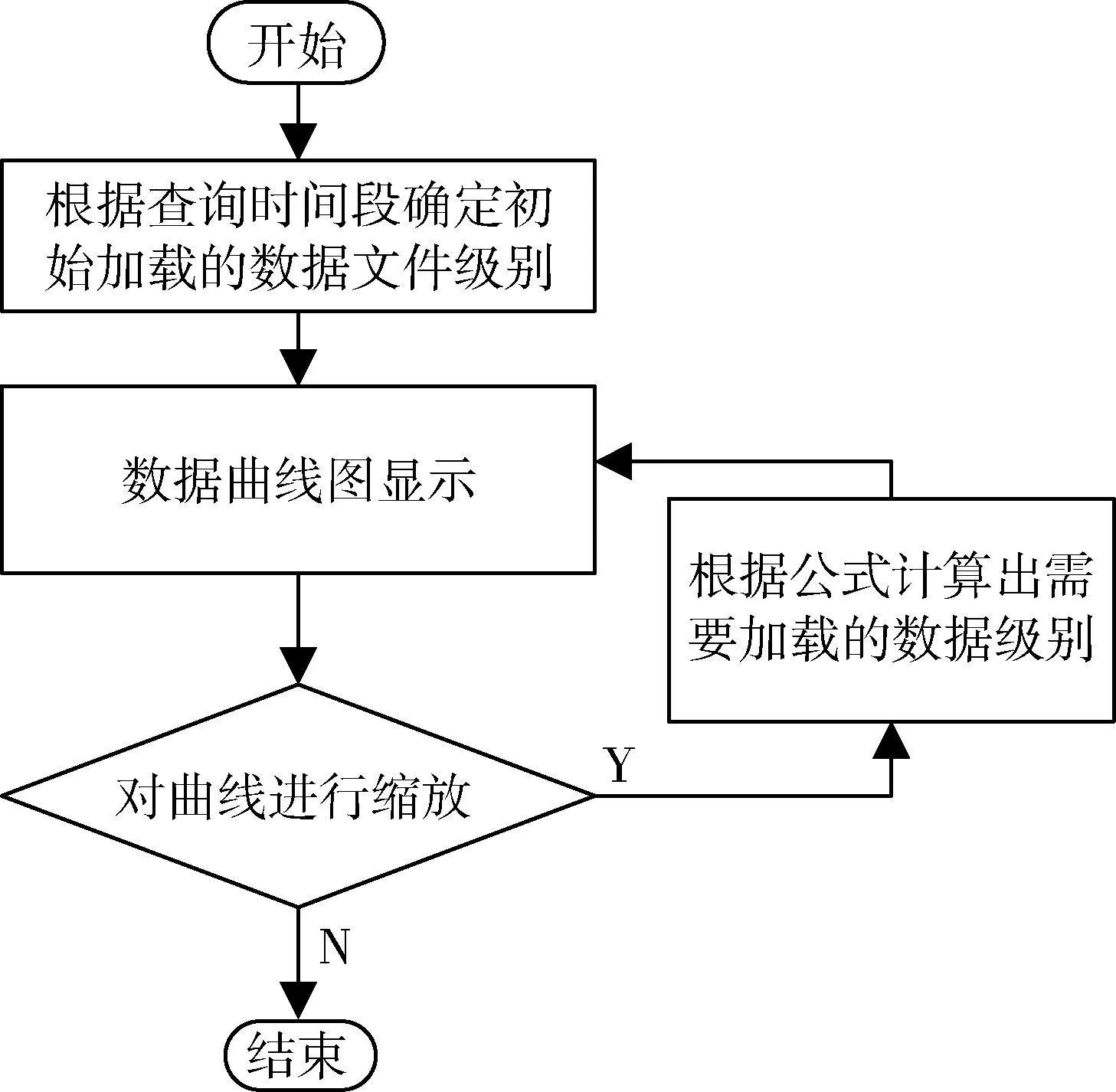
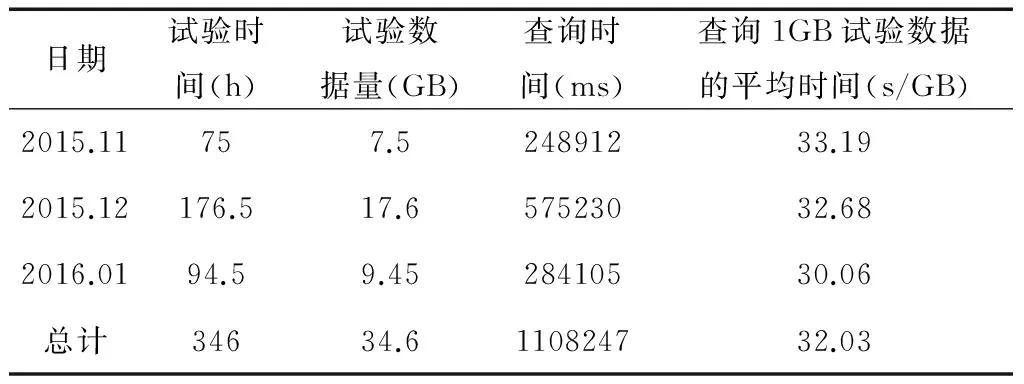
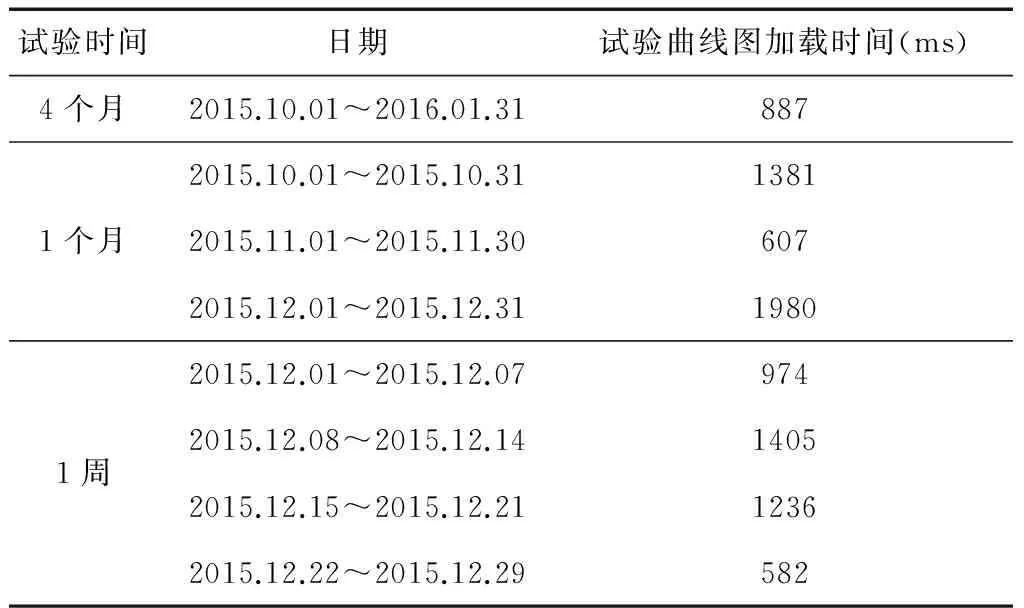
如图4所示,a1~an,an+1~a2n和a2n+1~a3n为在先后不同时间导入系统中的同一试验类型的数据。若将它们并行地进行数据预处理,当3块处理器进行数据预处理的时间t3 为了避免数据排列混乱,根据试验类型,将试验数据表加上相应的表头“TB_xxxx”。后期将同一表头的试验数据包按照接收的时间先后顺序,分发到同一个处理单元中进行数据预处理,从而保障了预处理后的试验数据排序的有序性。 1.2.2 数据静态负载均衡 基于长期试验数据流量的监测统计,将数据包根据概率算法均分到Data_1-Data_N的N个组,从而构造数据静态负载均衡调度表,如图5所示[7-8]。 图5 数据静态负载均衡调度表 采用如图6的LVS结构搭建负载均衡集群,试验数据包先到达集群系统的负载均衡器。在负载均衡器上根据静态负载均衡调度表进行请求任务的调度分配,进一步将请求任务分配到具体的后端服务器上进行处理[9]。 图5 LVS集群三层结构 通过多处理技术和并行计算这2种方式提升数据计算能力之后,进一步采用最小单元UNIT模式对海量数据做出一系列的预处理,以提高后期的数据查询速度,在一定程度上降低了数据的存储压力。 2.1 数据抽样 2.1.1 分级抽样 2.1.1.1 分级抽样算法原理 为进一步提高用户对状态量数据的查询效率,针对导弹武器研制与使用时产生数据的特征,采用一种新的数据分级抽样算法对数据进行打稀、抽样。 图6 分级抽样算法流程图 通过数据分级抽样软件,在达梦数据库为试验数据建立10级的表项,表项编号从0~9。其中,0为原始数据,9级为最大抽样级别。如图7所示,将数据以z为间隔进行抽样,抽取z个数中的最大值和最小值,组成下一级的数据文件。再对下一级的数据做同样的处理。以此类推,对数据做出9级抽样,每一级的数据存放在相应级别的文件夹里[10]。 2.1.1.2 数据存储形式 武器研制试验时,CPCI计算机每个时间周期向数据处理系统发送一次该周期内的试验数据。为了方便数据查询,数据库采用列存储的模式进行数据存储,而列存储中的数据索引是唯一的。为了便于列存储数据的管理与查询,参照hashmap中键值对(key-value)的存储数据形式,创建了一种Map 数据抽样时,对z个不同时间(Datetime)下相同字段序号对应的数值进行比较,选取最大值和最小值。若某一时间点的某个字段序号对应的数值是最值,则数值将被保留,作为下一级的数据;若某一时间点的某个字段序号对应的数值不是最值,则将该数值以空格代替,以便该级别的数据抽样后,每个时间节点对应的数值个数相同,方便下一次抽样时进行数值的大小比较。抽样结束后,仍以Map<时间,Map<字段序号,数值>>的存储格式进行数据存储,以便进行下一级别的数据抽样。 图7 数据分级抽样原理图 2.1.2 分级数据查询算法 如图8所示,一段时间t内的原始数据个数为z9n个,每次抽样,在抽样间隔z内抽取一个最大值和一个最小值,组成下一级的数据文件,则下一级的数据量减少为上一级数据量的1/2z。由此,在不同级别数据文件下查询同一试验时间段内的试验数据所用的查询时间:t0>…>t7>t8>t9。数据查询软件根据查询的试验时间段T内的数据量与界面最佳显示点数,选择合适的查询加载级别的文件。当查询的试验时间段内原始级别数据文件中的数据量远大于界面最佳显示的数据量时,则会升级去查询更高级别的数据文件,以减少查询的数据量,加快查询速度。 图8 分级抽样后数据文件示意图 初始加载曲线图时,若查询的试验时间段t内的数据个数(t/T)约为试验数据曲线图的界面最佳现实显示点个数(m),则选择原始数据作为绘制曲线图的数据进行加载。 为了使查询的试验时间段t内的数据个数约为曲线图界面最佳显示点个数,曲线图初始加载时,根据公式: 计算出需要加载的文件级别。 当对曲线图进行放大(查询试验时间段t缩小)时,则减小时间段内的的数据个数a会小于最佳显示点个数m,根据公式: 计算出需要改变的级别数,再根据公式: x′=x+Δx 跳转到x′级别的数据文件进行数据的查询与加载。 当对曲线图进行缩小(查询试验时间段t增大)时,增大的试验时间段内的数据个数a会大于最佳显示数据个数m,根据公式: 计算出需要改变的级别数,再根据公式: x′=x+Δx 跳转到x′级别的数据文件进行数据的查询与加载。 图9 数据查询算法流程图 2.2 数值压缩法 为了减少数据库的压力,提高存储的效率,对于数据分析要求不高的数值量数据用“数值压缩法”进行数据压缩。接收到索引属性为数值量的数据时,以“数值+次数”的方式存储变化较大的数据,如果数据不发生变化,只存一个数据,或者某些数据在合理的范围内变化,就记录该数据的理论值。 2.3 数据入库 2.3.1 列存储 考虑到试验数据为非关系型的数据,后期只需要对数据的曲线图相对于标准值的超差进行监测、判读,所以试验数据采用了非关系型的列存储的模式以方便数据的后期读取。 为了保证非关系数据的完整性,在写入过程中加入类似关系数据库的“回滚”机制,当某一列发生写入失败时,此前写入的的数据完全失效。同时加入散列码校验,进一步保证数据的安全性。 2.3.2 批量导入 目前达梦数据库提供标准的入库接口ODBC接口实现本地和远程数据库的入库操作,这种接口由于采用分条处理的方式,数据入库效率过低。 为了提高数据入库的效率,采用批量导入接口将数据导入数据库。在大数据量和复杂数据环境下,批量导入软件为系统设定合适的批量装载时间,周期接收数据并将其解析,按照文本的方式存储在磁盘中。数据库入库任务负责将磁盘上的文件批量地读取导入到数据库中,从而提升数据的入库效率,有利于后续数据的接收和查询。 在对系统进行一系列软硬件的架构和研制后,通过设计实验验证本系统数据查询速度是否提升以及长时间段内数据是否实现秒级加载。 3.1 原始数据查询 3.1.1 实验设计 以某型航天武器装备的控制系统为数据处理实验对象,其在进行研制试验时,平均每小时产生100MB左右数据,10h的试验将产生1GB的数据量。我们随机抽取20d的历史试验数据进行查询,根据每天进行试验的时间和数据查询耗费的时间,得出在龙芯3A单路+DM7+中标麒麟V6平台下,平均查询1GB数据所耗费的时间。 3.1.2 实验结果 分别统计了2015年11月、12月和2016年1月的试验时间与数据查询时间,实验结果整理如表2所示。 表2 原始数据查询时间 由实验结果可以看出,在对国产化服务器进行刀片式架构和数据处理性能的软件级优化后,查询1GB的试验数据只需要约32s的时间,相比于优化前数据处理系统大约110s的查询时间,国产化平台下的数据处理系统的查询性能得到很大提升。 3.2 分级抽样后的数据查询 3.2.1 实验设计 分别以3个月、1个月、1周、1d和1h为查询时间段,加载试验数据的曲线图,比较这5种查询时间段下,试验数据曲线图的加载时间。经过验证,在分级抽样预处理和查询端软件优化后,系统对任意试验时间段数据实现了秒级加载。 3.2.2 实验结果 分别统计了2015年10月~2015年12月不同时间段的试验数据曲线图的绘制时间,实验结果整理如表3所示。 表3 分级抽样后数据查询时间 由试验结果可以看出:实验数据曲线图的加载时间并没有随着试验数据量的增大成正比例增长,而是维持在0.5~2s之间。由此可以进一步验证,通过数据预处理软件与数据查询软件的应用,系统实现了任意试验时间段试验数据曲线图的秒级加载与绘制。 阐述了发展航天武器装备研制专用的自主可控国产化海量数据处理系统的必要性。针对国产化平台性能不足的缺点,提出了一种数据处理优化技术,给出了具体的实施方法和路径。实验结果表明,本文的优化方法可有效提升国产化数据处理系统的数据查询速度,实现任意试验时间段数据曲线图的秒级加载。此技术的应用,实现了武器研制试验的信息化与数字化,为航天武器装备控制系统提供了一套基于国产化平台的高效数据处理解决方案。 后期将进行基于数据流量负载均衡数据的分发策略,动态根据每个处理器负载调整数据分发,以提高数据处理的适用性。 [1] Ashish Thusoo, Joydeep Sen Sarma, Namit Jain, et al. Hive-A petabyte Scale Data Warehouse Using Hadoop[C]. In Proceedings of the IEEE International Conference on Data Engineering, 2010. [2] 苏丽,张博为,等.大数据技术在航天领域发展与应用[J].遥测遥控, 2015(2):1-8. (Su Li,Zhang Bowei,et al. Develoment and Application of Big Data Technology in Aerospace Field[J]. Journal of Telemetry, Tracking and Command, 2015(2):1-8.) [3] 王晓强. 突破国产自主可控存储技术, 走出网络自信的现行之路[J]. 中国信息安全, 2014(7): 42-44. [4] 吴洪成,金亮亮. 自主可控的数据存储系统开发[J]. 信息化建设, 2015(7): 61-64. [5] 刘军.大数据处理[M]. 北京:人民邮电出版社, 2013. [6] 张勇.刀片服务器与机架式服务器的比较分析[J]. 中国教育信息化, 2009(9): 78-79. [7] Konstantinou I, Tsoumakos D, Mytilinis I, et al. DBalancer: Distributed Load Balancing for NoSQL Datastores[C]. Proc. of Sigmod, 2013: 1-19. [8] Md.Firoj Ali, Rafiqul Zaman Khan. The Study on Load Balancing Strategies in Distributed Computing System [J]. International Jouranl of Computer Science & Engineering Survey (JICSES), 2012, 3(2): 19-30. [9] 王红斌. Web服务器集群系统的自适应负载均衡调度策略研究[D].吉林大学,2013. [10] Ao Li, Yu Deshui, Shu Jiwu. A Tiered Storage System for Massive Data: TH2TS[J]. Journal of Computer Research and Development, 2011, 48(6): 1089-1100. [11] Lan H Witten, Alistair Moffat, Timothy C. Bell. 管理海量数据[M]. 北京: 电子工业出版社,2014. The Optimization Technique of Mass Data Processing Based on the Domestic Platform of Aerospace Control System Liu Mengyu, Zhang Jie, Shangguan Ziliang, Zhao Yumei, Yang Zhe Beijing Aerospace Automatic Control Institute, Beijing 100854, China Withthedevelopmentofinformation,Massdataareproducedwhiletheaerospacecontrolsystemistestedandused.Accordingtotheinsecurityofforeignequipmentandthelowperformanceofdomesticserver,adataprocessingandoptimizationtechniquebasedondomesticserverisimplemented,whichensuresthesafetyandfleetnessofdomesticDPS (DataProcessingSystem)forcontrolsystem.Firstly,multi-processing,distributedandparallelcomputingtwotechniquesareimplementedtoupgradethedataprocessingcapacity.Then,inordertodecreasethepressureofdata-inputanddata-output,theminimumUNITmodeisappliedtopreprocessdata.Theresultofdataqueryexperimentsshowsthatthespeedofdataqueryisincreasedgreatlyandthedatainarbitrarytestperiodcanbeloadedinsecondlevel. Massdata;DomesticDPS;Multi-processing;Distributedandparallelcomputing;MinimumUNIT;Tieredsampling 2016-08-25 刘孟语(1991-),女,安徽人,硕士研究生,主要研究方向为自主可控控制系统;张 洁(1971-),男,河南人,博士,研究员,主要研究方向为飞行器导航、制导与控制;上官子粮(1986-),男,山西运城人,硕士,工程师,主要研究方向为计算机应用技术;赵玉梅(1965-),女,北京人,本科,高级工程师,主要研究方向为计算机应用技术;杨 喆(1989-),女,河南人,硕士,工程师,主要研究方向为计算机应用技术。 TP39 A 1006-3242(2016)06-0057-07
2 最小计算单元UNIT模式

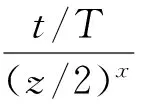
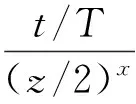
3 实验验证
4 结论
猜你喜欢
中国交通信息化(2023年10期)2023-11-30 06:04:48
军民两用技术与产品(2022年7期)2022-08-06 07:19:10
能源工程(2021年3期)2021-08-05 07:26:14
北京大学学报(自然科学版)(2021年3期)2021-07-16 07:13:40
矿山安全信息(2021年21期)2021-07-04 06:33:32
东北师大学报(自然科学版)(2021年1期)2021-03-27 01:22:14
矿山安全信息(2020年37期)2020-12-26 07:25:58
电脑爱好者(2020年19期)2020-10-20 06:02:06
矿山安全信息(2020年2期)2020-03-05 05:13:56
矿山安全信息(2020年3期)2020-03-04 10:18:08
