
基于智能手机的维吾尔语语音控制系统的开发
2016-07-19 02:07:24米尔阿迪力江麦麦提吾守尔斯拉木努尔麦麦提尤鲁瓦斯
计算机应用与软件 2016年6期
米尔阿迪力江·麦麦提 吾守尔·斯拉木,2 努尔麦麦提·尤鲁瓦斯,2
热依曼·吐尔逊1,2 艾尼宛尔·托乎提21(新疆大学信息科学与工程学院 新疆 乌鲁木齐 830046)2(新疆大学新疆多语种信息技术重点实验室 新疆 乌鲁木齐 830046)
基于智能手机的维吾尔语语音控制系统的开发
米尔阿迪力江·麦麦提1吾守尔·斯拉木1,2努尔麦麦提·尤鲁瓦斯1,2
热依曼·吐尔逊1,2艾尼宛尔·托乎提21(新疆大学信息科学与工程学院新疆 乌鲁木齐 830046)2(新疆大学新疆多语种信息技术重点实验室新疆 乌鲁木齐 830046)
摘要以实现维吾尔语命令词识别为目的,重点研究维吾尔语命令词识别系统在Android平台下的开发与实现过程,介绍系统开发难点、核心技术及系统典型的几个功能。系统主要由Android开发包、Eclipse集成开发环境和API接口进行开发,并且通过自动选型规则来实现维汉英多种文字的正确显示及处理等问题,针对广大用户的不同说话方式,重新构建维吾尔语语音语法文件,解决各地不同方言问题。在一般实验室环境下做实验得到了90.56%的正确识别率和85.00%的成功执行率等测试结果,表明维吾尔语非特定人命令词识别研究中语法文件的结构及构建对系统有不同的影响。
关键词Android平台维吾尔语关键词识别槽语法命令词识别
0引言
近几年在新疆使用智能手机的用户越来越多,它将成为人们获取信息的主要设备,因此基于手机的应用软件愈来愈受到人们的关注和重视。目前Android技术是一个先进的、具有高人气的技术,它还是一个开放性移动设备综合平台[1]。
我国是一个多民族的国家,新疆是个多民族地区之一[2],Android平台的维吾尔语手机语音控制软件一直以来都是少数民族市场上的空白。在国外,关键词识别的研究初始于20世纪70年代,那时此研究序幕由Bridle[3]揭开的只称“给定词”识别,当时没有使用语法或词法信息,而是利用信号的LPC表示连续语音中的关键词进行了检测和定位。到80年代,Myers等人[4]利用基于DTW的局部最小算法来对关键词识别和连接词识别进行研究。90年代MIT、CMU和Dragon、Toshiba和IBM等公司就对KWS的研究得到了进一步发展,国外已经进入了高潮,但是国内研究历史并不久。国内利用基于音节的一种汉语无限制语音流的关键词识别系统,采用了独特的统计拒识方法[5]。科大讯飞作为国内和国际语音技术产业的领导者,国内语音技术及中文关键词识别、命令词识别技术进入了更高的一层。国内外连续语音识别及关键词识别技术取得了一定的成就,市场上也出现了一些应用产品,可是我国少数民族对关键词识别技术的研究与开发正处在初期阶段。
本文利用维吾尔语朗读式的语料训练而得到的声学模型作为本文命令词识别系统的声学模型,然后基于规则的方式,建立了槽语法文件。此文件由15个槽(slot) 和三个语法规则(
1软件总体架构及设计
1.1系统层次结构
本系统的设计首先通过对用户的需求进行一系列的调查与分析,最终明确了该系统的使用对象及其功能。即本软件的主要任务是在方便、有效的原则上为广大维吾尔族群众用户提供一个维吾尔语语音控制平台,本系统的总功能划分如图1所示。

图1 系统总功能结构图
从图1所示可知,此软件主要是由如下11个主模块组成:打电话、发短信、打开应用、网络导航、播放音乐、活动提醒、获取考试信息、获取新闻、天气查询、地图查询模块及软件附加模块等。
1.2系统设计
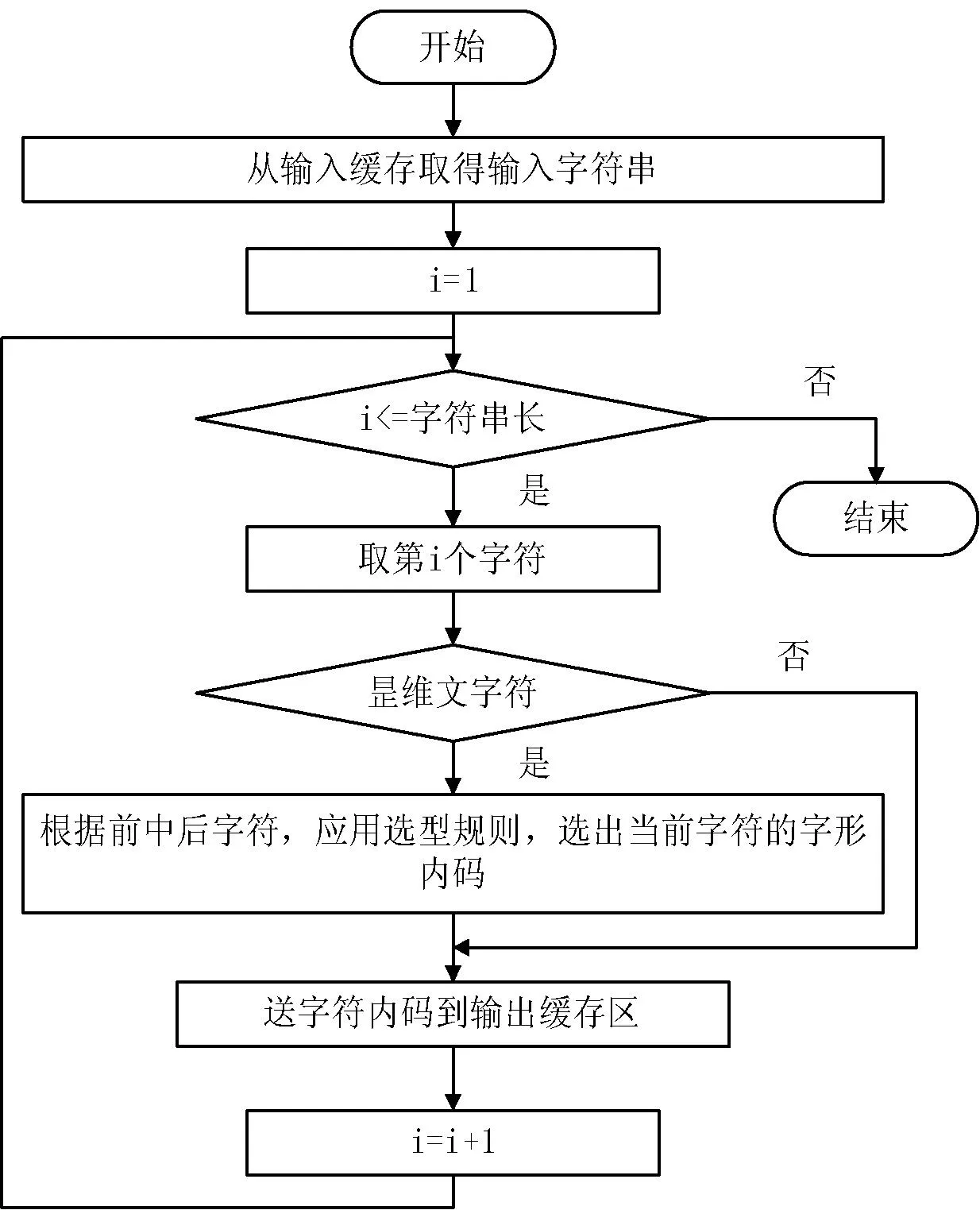
图2 输入处理模块流程图
系统开发中利用Android的API函数接口,同时引用科大讯飞公司研究院所提供的安卓底层语音处理API接口和它所包含的AitalkRecognizer类的类方法getInstance( )和调用创建语音识别引擎的createAitalkEngine( )方法等核心方法。软件启动之前通过sdCard.getAbsolutePath( )必须获取用户SD卡的绝对路径,然后在用户的SD卡上通过File( )类在此绝对路径上创建一个"MyFiles"文件夹,再将我们预先准备的语法文件(grammar.bnf)放入到绝对路径上。对此语法文件进行动态修改,并将最初需要对用户说的维吾尔文通过UygToLat()方法来转换为拉丁文,并以拉丁文来进行后续操作,运行流程如图2所示。
2难点及核心技术
2.1维吾尔文处理
Android手机不支持从右向左的文字输入方向和系统输入法,为维吾尔文输入及处理带来一定的难度。维文字母与汉英文的不同,其特点主要表现在: 1) 书写方向相反。汉字和西文是从左到右, 而维文是从右到左; 2) 维吾尔文字母根据在单词中的位置不同会有四种变形; 3) 每个界面按钮和文本标签都是维吾尔文,命令都是普遍的维吾尔的标准词汇。系统中主要是用自动选型处理和字母序列转换函数来处理维吾尔文的正常显示和处理方式(如图3所示)。图中i为当前需要选形的字母,i-1是当前字母前面的字符,i+1是当前字母后面的字符,设定i-1、i、i+1字符值为0(特殊字母或非维文字母)或1( 普通字母) ,当i-1、i、i+1字符值为不同的值时,i字符选形也不同。即使用户手机没装维文字体和输入法,该软件也能有效解决处理。
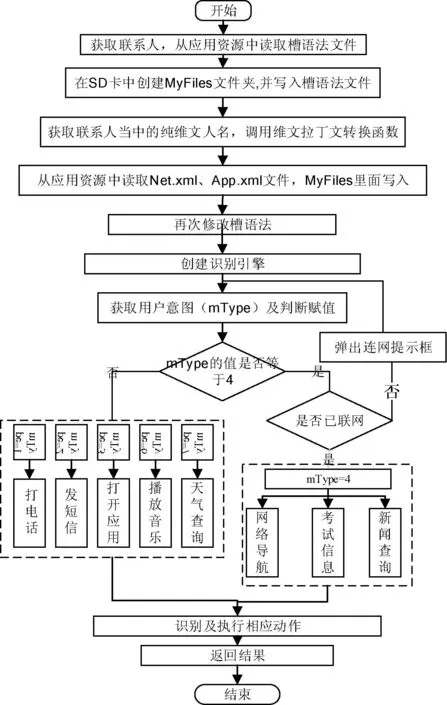
图3 系统总流程图
2.2语音关键词识别技术
在维吾尔语关键词识别系统中如何理解用户的意图是一个非常棘手的问题。本系统先利用已经准备好的语料库进行前段处理、训练,从而建立声学模型;再规定语法文件,通过网络化结构的转换,得到语言模型;为了得到识别结果,依据已建好的声学模型和语言模型,利用一定的搜索算法,对输入的测试数据进行搜索匹配,再给出最终结果。关键词识别系统主要有隐马尔可夫模型(HMM),动态时间归正技术(DTW)和人工神经元网络(ANN)等模式匹配方法[8]。因此本实验也利用了应用最广泛、最成功的基于统计模型的HMM搜索匹配法[9]。
2.3槽语法
语法文件的创建在本系统开发过程中起着至关重要的核心作用。本文采用的是基于巴克斯范式BNF(Backus-NaurForm)的槽语法(SlotGrammar)[10]。将系统设定为只接受该语法约束下的信息查询语句,却略去无关信息,从而提高系统的性能和效率。一般槽语法中,槽的个数不能太多,因为当槽的个数太多,且也有嵌套层级的情况时,将会导致产生的语法网络较复杂,直接影响语法静态扩展无法实现。
创建语法文件后利用HTK的HParse[11,12]工具得到语言模型,因此该文件的构造是整个系统的最核心技术。本系统槽语法文件是按规定维吾尔文所对应的拉丁文(如表1所示)书写的。槽语法由!slot、!grammar以及< >,[ ],||组成。除此之外,还有
表1国际标准维文拉丁文对照表
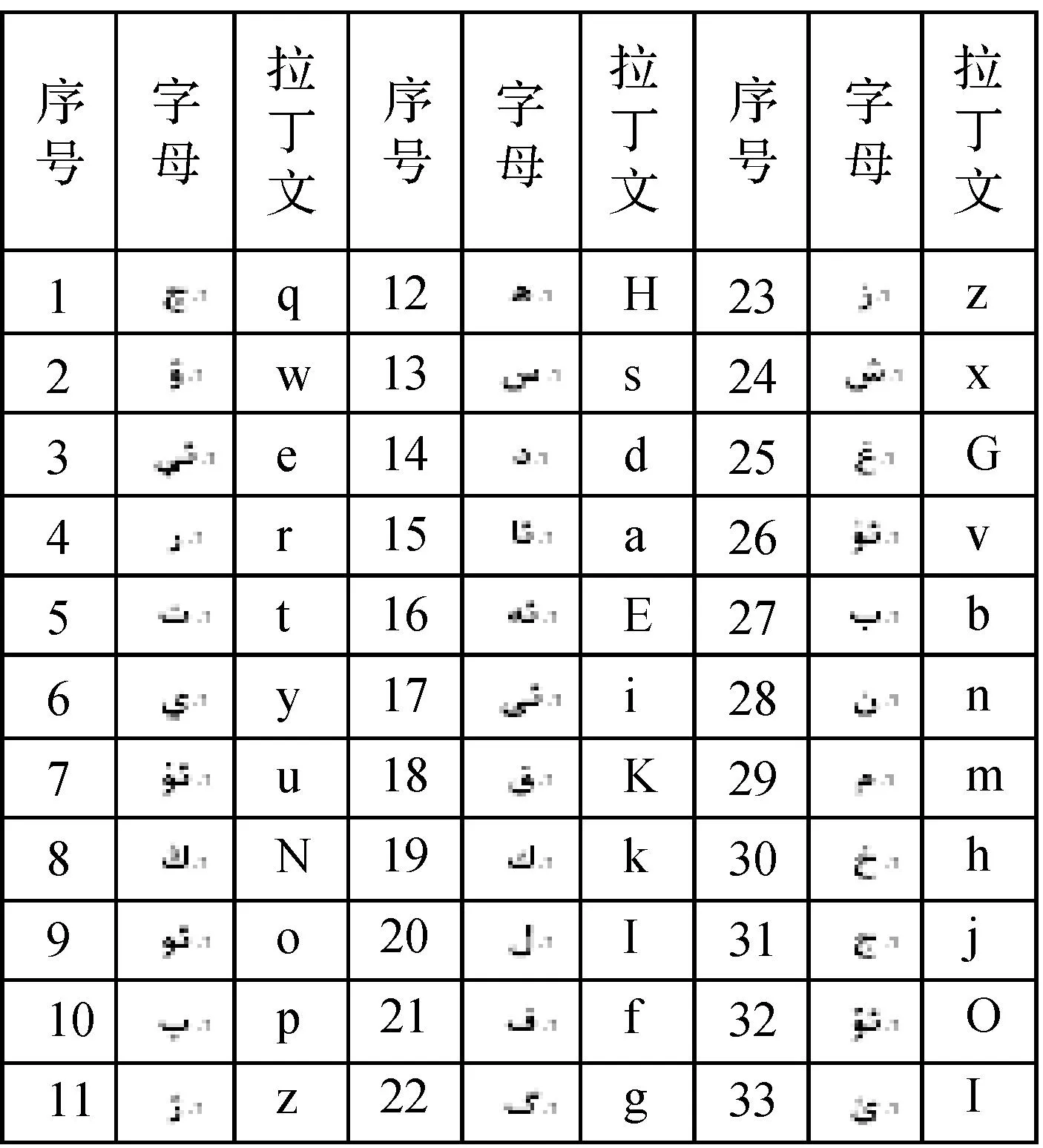
表2 槽语法中各个字符的含义
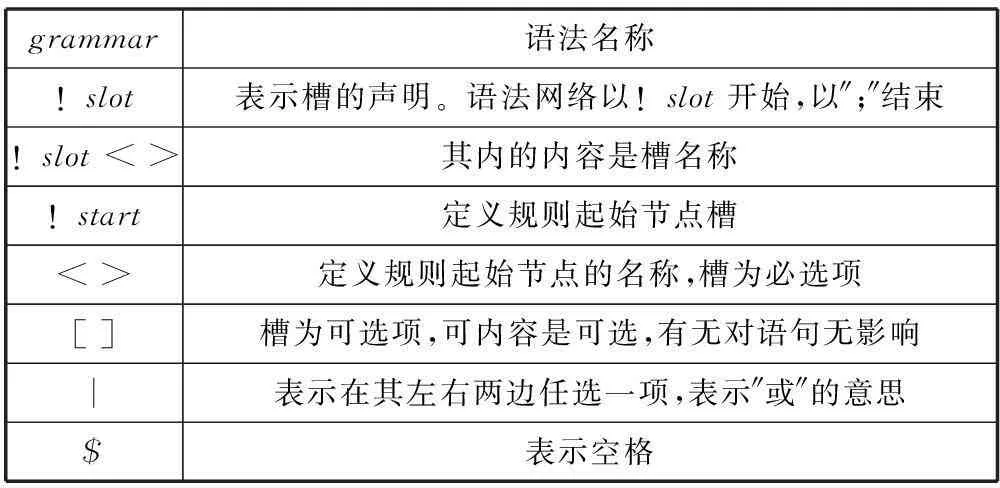
grammar语法名称!slot表示槽的声明。语法网络以!slot开始,以″;″结束!slot<>其内的内容是槽名称!start定义规则起始节点槽<>定义规则起始节点的名称,槽为必选项[]槽为可选项,可内容是可选,有无对语句无影响︱表示在其左右两边任选一项,表示″或″的意思$表示空格
3软件功能实现
3.1实现打电话功能
首先识别用户所说的语音命令后,通过PrintContacts(c)方法,动态地查找和获取用户手机上的联系人信息,调用matcher(contactDisplayName)方法来解决不符合条件的维吾尔文联系人,然后需要引用startTalk(this,″nlp″)方法,在编写的onButtonRetryClick( )方法中调用命令词的识别,从而将会节省用户在一批联系人中的查找并翻阅的时间,从而更方便、快捷地完成用户打电话的需求。识别用户的命令,及转换为拉丁文,后将用户所说的语句显示在手机屏幕上,根据mType=1的情况,提取槽语法中“打电话”的槽“!slot
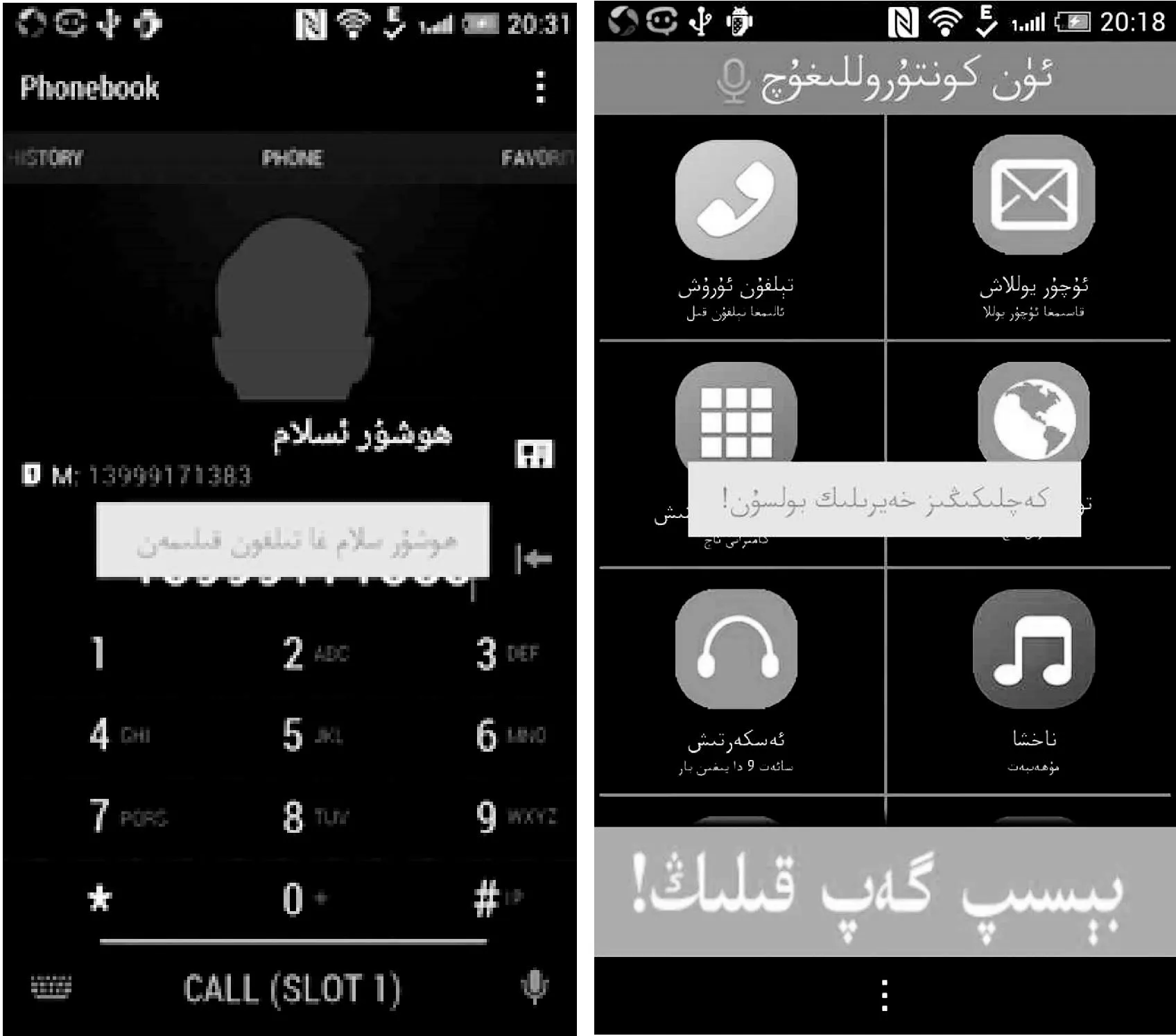
图4 系统主界面图 图5 打电话功能实现图
3.2实现打开应用功能

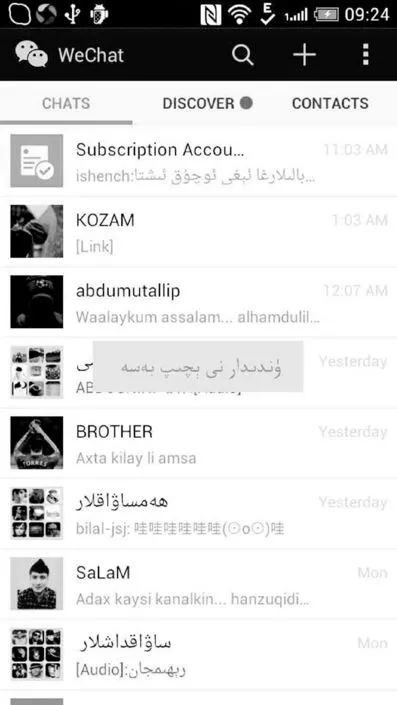
图6 打开应用实现图
4实验与结果分析
4.1实验数据与环境
本文利用英国剑桥大学研发出的基于隐马尔科夫模型[15]的HTK工具,并且在使用HTK进行特征提取、训练及得到声学模型[16,17]的基础上,利用建立的语法文件进行了语言模型的构建[18],再搭建本维吾尔语语音控制软件能够运行的Android开发平台。
训练集:一般环境下(如无人的教室、办公室等),录制朗读式连续语音作为训练集[19]。发音人是18~30岁的成年人总共356个人(189女,167男),共发声128小时的2456条语句,发音人配置高宝立式麦克风,阻抗160om、灵敏度56±3dB,频率范围100~16 000Hz。采样率选择16KHz、采样位选择16Bit。语音数据以wav文件格式存储,共有50 000多条语音文件。
测试集:录制的软件为CoolEdit2.0,语音采样频率为16KHz、采样位选择16Bit、单声道格式,共有300个语音文件,即对于每一个语法规则分别录制了100个文件。语音数据以wav文件格式存储。
4.2实验测试结果
测试环境为:系统安装至单核、RAM256、ROM256,及系统版本是Android2.3.3的华为G606-T00和HTC智能手机、并在安静的实验室环境内进行了对于软件核心部分“意图”的人工实际测试。其中成功执行个数指的是在识别的基础上能够正确执行指令的个数,而执行失败指的是能识别但是未成功执行的个数。除此,识别正确率为正确识别个数除以总数、成功执行率为成功执行个数除以总数而得。噪声等周边环境[20]、底层语音识别率、用户声音低或者地方口音偏重、发音不够清晰正确及命令列表中不存在该词汇等不能正确识别。测试结果如表3所示。
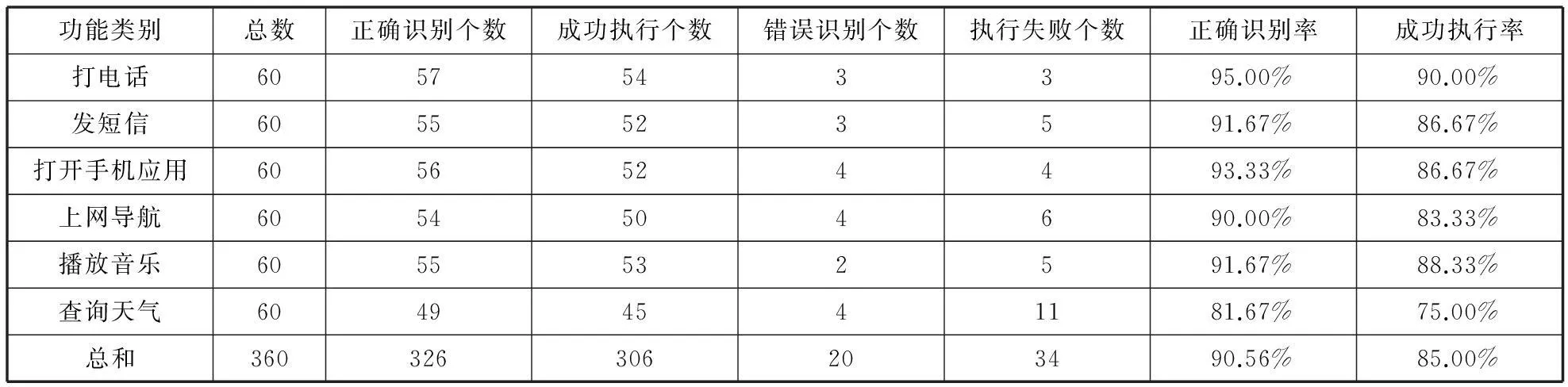
表3 对用户“意图”执行的测试结果表
5结语
本文以维吾尔语语法的特点出发,在符合命令词的语法形式的条件下,建立了维吾尔语命令词识别的槽语法文件,通过使用HTK得到其语法网络及语言模型,并且对于一些出现的带地方口音的单词及一些新型词汇等,对最终结果有一定的影响。未来用户使用发短信功能时本系统上将增加语音输入功能,除此还需要增加语音合成功能,为了使少数民族用户使用更加方便的语音软件,让系统达到更加完美效果,对系统进行更加智能化分析、添加语音翻译器是下一步研究重点。
参考文献
[1] 韩超,梁泉.Android系统原理及开发要点详解[M].北京:电子工业出版社,2010:340-343.
[2] 热依曼·吐尔逊,吾守尔,努尔麦麦提.多文种手机混合输入/输出技术及实现[J].计算机工程与科学,2006,28(4):103-104,118.
[3]BridleJS.AnEfficientElastic-TemplateMethodforDetectingGivenWordsinRunningSpeech[C]//Brit.Acoust.Soc.Meeting,1973.
[4]MyersCS,RabinerLR,RosenbergAE.AnInvestigationoftheUseofDynamicTimeWarpingforWordSpottingandConnectedWordRecognition[C]//Proc.Conf.ASSP,April.1980:173-177.
[5] 徐明星,郑方,吴文虎,等.连续语音关键词识别系统的拒识方法研究[J].清华大学学报:自然科学版,1998,38(S1):89-91.
[6] 陶梅,吾守尔·斯拉木,那斯尔江·吐尔逊.基于HTK的维吾尔语连续语音声学建模[J].中文信息学报,2008,22(5):56-59.
[7]SteveYoung,GunnarEvermann,MarkGales,etal.HTKBOOK[M].HTKVersion3.4.CambridgeUniversityEngineeringDepartment,March,2009:199-211.
[8] 那斯尔江·吐尔逊,吾守尔·斯拉木.基于隐马尔可夫模型的维吾尔语连续语音识别系统[J].计算机应用,2009,29(7):2009-2012.
[9]WilponJG,LeeCH,RabinerLR.ApplicationofHiddenMarkovModelsforRecognitionofaLimitedSetofWordsinUnconstrainedSpeech[C]//ICASSP,1989,3(1):254-257.
[10]RohlicekJR,RusselW,RoukosS,etal.ContinuousHiddenMarkovModelingforSpeaker-IndependentWordSpotting[C]//ICASSP,1989,1(1):627-630.
[11] 李星星.基于HMM的汉语语音关键词检测研究与实现[D].武汉理工大学,2009.
[12]RoseRC,PaulDB.AHiddenModelBasedKeywordRecognitionSystem[C]//ICASSP,1990,1(1):129-132.
[13]ChristiansenRW,RushforthCK.DetectingandLocatingKeyWordsinContinuousSpeechUsingLinearPredictiveCoding[J].IEEETrans.onASSP,1977,25(5):361-367.
[14]AlanLHiggins,RobertEWohlford.KeywordRecognitionUsingTemplateConcatenation[C]//ICASSP,1985,1(3):1233-1236.
[15] 郑方.连续无限制语音流中关键词识别方法研究[D].北京:清华大学,1997.
[16] 努尔麦麦提·尤鲁瓦斯,吾守尔·斯拉木.面向大词汇量的维吾尔语连续语音识别研究[J].计算机工程与应用,2013,49(9):115-119.
[17] 努尔麦麦提·尤鲁瓦斯,吾守尔·斯拉木,热依曼·吐尔逊.维吾尔语连续语音识别声学模型优化研究[J].计算机工程与应用,2013,49(2):145-147.
[18] 努尔麦麦提·尤鲁瓦斯,吾守尔·斯拉木,热依曼·吐尔逊.基于音节的维吾尔语大词汇连续语音识别系统[J].清华大学学报:自然科学版,2013,53(6):741-744.
[19] 努尔麦麦提·尤鲁瓦斯,吾守尔·斯拉木,热依曼·吐尔逊.维吾尔语大词汇语音识别系统识别单元研究[J].北京大学学报:自然科学版,2014,50(1):149-152.
[20]TakebayashiY,TsuboiH,Kanazawa.ARobustSpeechRecognitionSystemUsingWord-SpottingwithNoiseImmunityLearning[C]//ICASSP,1991,2(1):905-908.
DEVELOPMENT OF UYGHUR VOICE CONTROL SYSTEM BASED ON SMART PHONE
Miradeljan Mamat1Wushour Ialam1,2Nurmamat Yolwas1,2Rayima Tursun1,2Anwar Tohti2
1(College of Information Science and Engineering,Xinjiang University,Urumqi 830046,Xinjiang,China)2(Key Laboratory of Xinjiang Multilingual IT,Xinjiang University,Urumqi 830046,Xinjiang,China)
AbstractWith the purpose of implementing Uyghur command words recognition, we elaborately studied the development and implementation process of Uyghur command words recognition system on Android platform, introduced the development difficulties, core technologies and typical functions of the system. The system was developed mainly using Android SDK, eclipse integrated development environment and API interfaces, and realised the functions of correct display and processing of multiple texts of Uyghur, Chinese and English through automatic styles selection rule. Aiming at different speaking styles of the majority of users, we rebuilt Uyghur voice and grammar files, and solved the problem of different dialects around the Region. Moreover we gained the testing results of right recognition rate of 90.56% and the successful implementation rate of 85% in the experiment made in usual Lab condition, this showed that in the research of Uyghur non-specific command words recognition, the structure and construction of grammar files had different effects on system.
KeywordsAndroid platformUyghurKeyword recognitionSlot grammarCommand words recognition
收稿日期:2014-08-23。国家自然科学基金项目(60762006);国家工信部电子发展重大项目(159018);新疆自治区自然科技项目(2011 211A012)。米尔阿迪力江·麦麦提,硕士生,主研领域:嵌入式智能应用开发,语音处理,自然语言处理。吾守尔·斯拉木,教授。努尔麦麦提·尤鲁瓦斯,讲师。热依曼·吐尔逊,副教授。艾尼宛尔·托乎提,工程师。
中图分类号TP311.1
文献标识码A
DOI:10.3969/j.issn.1000-386x.2016.06.053
猜你喜欢
时代英语·高一(2019年1期)2019-03-13 10:29:48
时代英语·高三(2019年1期)2019-03-13 10:29:26
时代英语·高三(2018年1期)2018-02-23 19:33:53
新高考(英语进阶)(2017年10期)2017-12-23 09:15:06
少年博览·小学低年级(2017年8期)2017-09-29 17:37:39
少年博览·小学低年级(2017年7期)2017-09-29 16:14:35
自动化学报(2017年4期)2017-06-15 20:28:55
少年博览·小学低年级(2017年1期)2017-06-09 18:57:45
中国诗歌(2015年4期)2015-11-17 16:10:02
新疆大学学报(哲学社会科学版)(2015年5期)2015-10-12 01:16:14
