
基于计算机视觉的多特征手势识别
2016-07-19 02:07:22杨正瓴
计算机应用与软件 2016年6期
张 军 张 孔 杨正瓴
(天津大学电气与自动化工程学院 天津 300072)
基于计算机视觉的多特征手势识别
张军张孔杨正瓴
(天津大学电气与自动化工程学院天津 300072)
摘要目前常用单特征手势识别方法中,缺少完整的手势轮廓信息,对局部相似度高和形状复杂的手势识别率较低,为此提出一种将CSS特征描述子与Hu不变矩相结合的手势特征提取方法。首先,利用肤色模型把手势从复杂的背景中提取出来,然后分别提取手势的Hu不变矩和CSS描述子来构建融合特征,最后利用人工神经网络对新特征进行识别和分类。实验结果表明,与基于单一特征的识别方法相比,该方法整体识别率更高,对局部形似度高的手势识别率有很大提升。
关键词计算机视觉手势识别空间曲率特征Hu不变矩神经网络
0引言
手势识别是计算机视觉领域的一个重要分支,目前被广泛应用到人机交互(HCI)、手语识别等各种领域中。根据手势采集设备的不同,可以将手势识别分为基于数据手套的手势识别和基于机器视觉的手势识别[2]。基于数据手套的方法需要使用者穿戴特殊的手势数据采集设备,使用条件受到限制;基于计算机视觉的手势识别只需要简单的数据采集设备,能为使用者提供更简单自然地输入方式,目前已成为手势识别的研究重点。
目前,基于计算机视觉的手势识别主要有两个研究方向:基于彩色图像的识别和基于深度图像的识别。基于深度图像的手势识别主要是利用微软2010年推出的Kinect外设传感器来获取深度图像,再利用获得图像的深度信息来进行手势识别。物体在深度图像中的深度值与物体距离传感器的距离有关[3]。所以人手区域与背景区域在深度图像中有不同的深度值,根据深度值得不同,可以利用阈值分割的方法来进行手势区域检测,从背景中分离出人手区域。基于深度图像的手势识别方法受光照和背景的干扰小,而且获取的图像分别率高,但是需要专门的Kinect设备;基于彩色图像的识别方法不受场景、环境等因素干扰,而且所需设备比较简单的。综合各种因素考虑,本文采用基于彩色图像的手势识别方法。
手势提取是手势识别的基础,手势轮廓提取效果的好坏对后面的手势特征的提取以及手势识别有很大的影响。肤色在颜色空间有很好地聚类特性,因此目前很多成熟的算法都是基于肤色模型来进行手势提取。徐占武等[7]采用高斯方法,此方法对复杂的背景有很好地识别效果,能够实现差异很大的肤色分割,但是高斯模型比较复杂,计算量大,不适用于实时操作环境。
人手是复杂的变形体,手势具有多义性、多态性,具有时间和空间上的差异性[5],因此特征的选择及提取是手势识别领域中的一个难点。目前常用的手势特征有两种,一种是基于图像表观特征的提取,另一种是基于人手模型的特征提取[9]。基于模型的特征提取就是根据经验知识建立人手数学模型,再根据手势的特征估计模型的参数,最后用模板匹配的方法进行识别分类。这种方法可以处理比较复杂的手势,缺点是计算量大,在图像分辨率低时,估计模型的参数比较困难。基于图像的表观特征就是利用图像上手势轮廓的手掌,手指等的几何特征来描述手势特征。文献[1-3]通过计算手势轮廓的指头数和指头间夹角来识别手势,这种方法计算量小,但是对于手指间夹角区分度小的手势识别率低。王先军等[4]利用Hu不变矩作为识别特征,得到7个具有平移、旋转、缩放不变性的Hu不变矩作为特征,取得了较高的识别率,但是对于局部相似度较高的手势(如图1所示M和N)识别结果仍然差强人意。Chang等[6]将CSS(曲率尺度空间)特征引入到手势识别领域,并对几个简单手势取得了很好地分类效果,但是由于缺乏整体性特征,对手语中比较复杂的手势(如图1中的X和H)识别效果很差。

图1 部分相似手势
针对Hu不变矩缺少局部描述特征,而CSS特征描述子没有整体特征。本文将两种特征融合,从整体和局部两方面描述手势,再用人工神经网络对新特征进行分类,取得了良好的分类效果。本文具体流程参见图2所示。
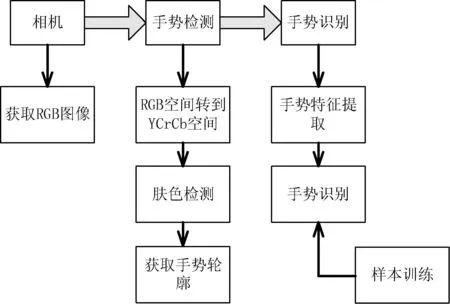
图2 流程图
1手势分割
手势分割就是从复杂的背景中把手势轮廓检测出来[2]。现在比较成熟的分割算法有帧差算法和肤色模型分割法。肤色分割法计算量比较小、模型简单,因此本文采用肤色模型分割法。
1.1肤色模型
肤色分割模型就是利用肤色在颜色空间上的聚类性,把感兴趣的区域从复杂的背景环境中分离出来。由于肤色在不同的颜色空间具有不同的聚类特性,所以要想取得良好的分割效果,必须选择合适的颜色空间。目前常用的颜色空间有RGB颜色空间、HSV颜色空间、YCrCb颜色空间三种。文献[8]通过大量实验,证明在YCrCb空间,肤色受亮度影响小,肤色聚类特性较好。因此本文选择YCrCbr空间作为手势分割的颜色空间。
1.2手势轮廓提取
实验中,我们采用一个单目相机来获取包含手势信息的图像,图像分辨率为320×240,通过下面步骤可以得到完整的手势轮廓:
步骤1用式(1),将图像由RGB空间转换到YCrCb空间,如图3(b)所示。
(1)
步骤2对得到的YCrCb图像进行阈值分割,得到手势的二值图像,如图3(c)所示。在我们实验环境下,Cr、Cb取值范围:133≤Cr≤183,78≤Cb≤131。
步骤3为了去除噪声和干扰,对阈值分割后的二值图像进行滤波和图形学处理,如图3(d)所示。
步骤4针对步骤三得到的二值图像进行轮廓提取,得到结果如图3(e)所示。
步骤5为了去除非肤色区域的干扰,我们设定轮廓点数阈值T,当轮廓点数小于阈值T时,就认为该区域不是手势轮廓,用黑色填充,最后得到只有手势轮廓的图像,如图3(f)所示。
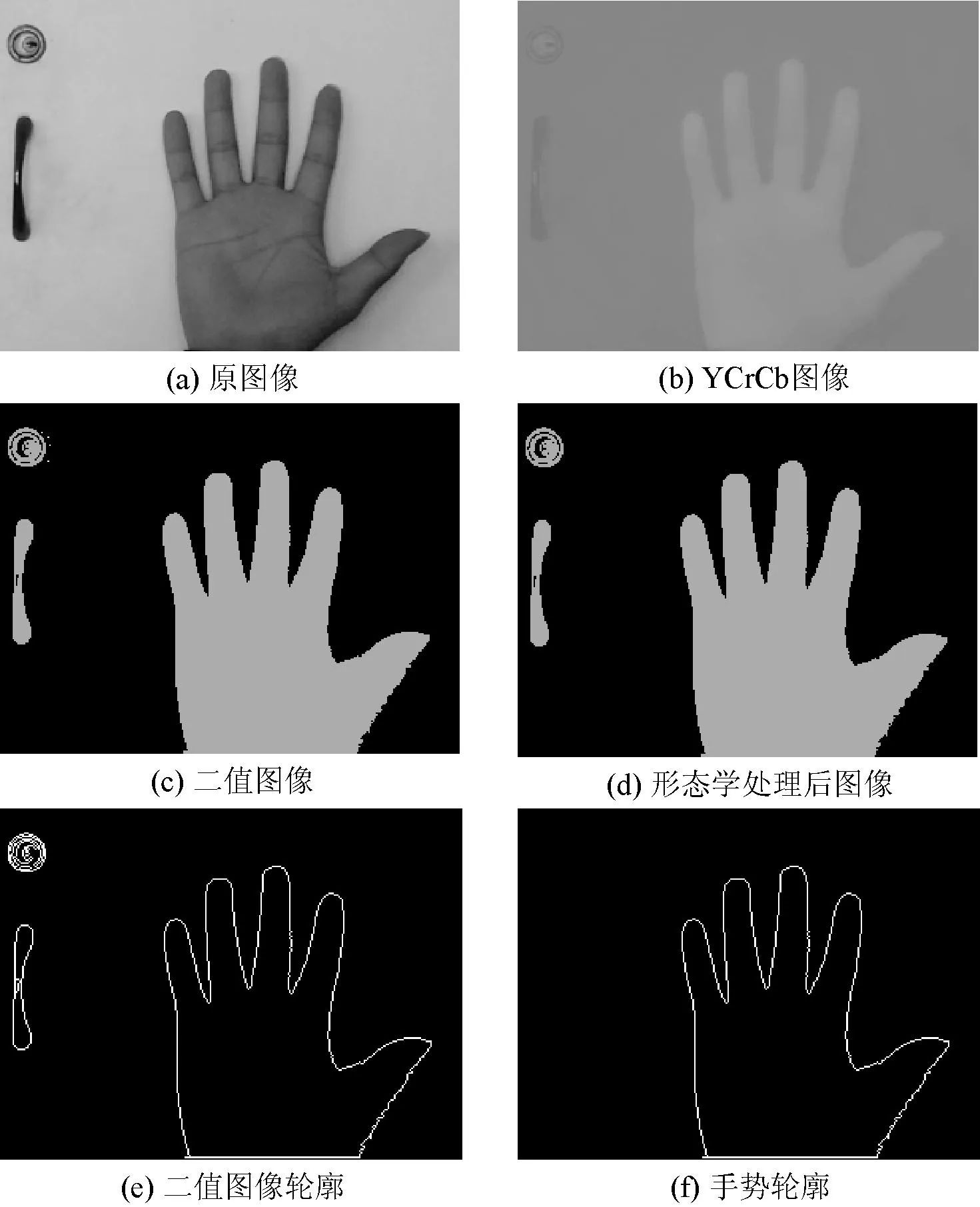
图3 手势轮廓提取过程示意图
2手势轮廓特征提取
2.1CSS特征描述子
CSS特征就是通过手势轮廓上各点的曲率来描述手势的形状特征,不同手势的轮廓上各点的曲率分布是不同的。CSS特征描述子就是找到手势轮廓在图像的尺度空间中的过零点,把这些过零点组合中的极值点位置及其对应的空间尺度信息的集合作为描述子。
2.1.1曲率计算
用弧长μ对曲线进行参数化表示:
L(μ)=(x(μ),y(μ))
(2)
则曲线上各点的曲率可由下面公式计算:
(3)
x(μ,σ)=x(μ)⊗g(μ,σ)
(4)
y(μ,σ)=y(μ)⊗g(μ,σ)
(5)
(6)
2.1.2CSS描述子生成算法
根据上面的曲率计算公式,对得到的手势轮廓进行曲率计算,并根据下面步骤得到CSS特征描述子:
步骤1对得到的手势轮廓进行参数化,得到L(μ)。
步骤2利用式(3)求出曲线各点的曲率,得到在尺度σ下的手势轮廓曲率序列。
步骤3判断在尺度σ下,曲率序列是否存在曲率的极值点。有则转步骤4,无则转步骤5。
步骤4记录下曲率极值点的位置和尺度,用(μ,σ)表示,增加尺度σ=σ+1,转步骤3。
步骤5将步骤4中得到的点绘制在(μ,σ)平面上,得到尺度空间图像CCSI。
在统一的离散化参数μ的条件下,所有CSSI中局部极值的坐标集合就是CSS形状描述子,即:
FCSS={(μi,σi)i=1,2,…,N}
(7)
手势U对应的CSSI特征如图4所示。
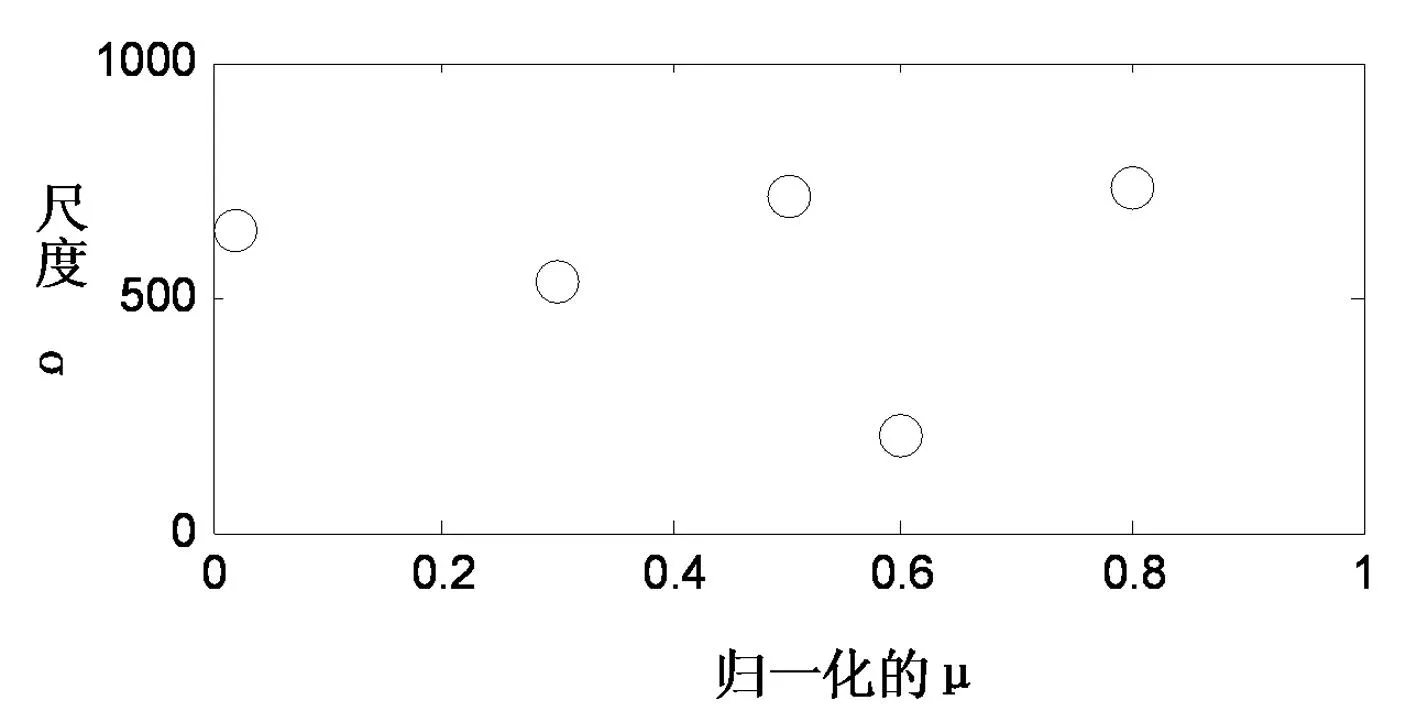
图4 手势U对应的CSSI特征
2.2Hu不变矩特征
矩不变量最早是由Hu等人于1962年提出的,把矩不变量进行线性组合,得到具有比例不变性、平移不变性、和旋转不变性的矩[10]。
针对二维的数字图像f(x,y),对应的p+q阶矩为[4]:
(8)
则与之相对应的p+q阶中心距为[4]:
(9)
中心矩upq是平移不变的。对中心距upq进行尺度规范化,得到如下中心矩[4]:
(10)
对上面得到的中心距ηpq进行非线性组合,得到如下7个具有平移不变性的Hu不变矩:
M1=η20+η02
(11)
(12)
M3=(η30-3η12)2+(3η21-η03)2
(13)
M4=(η30+η12)2+(η21+η03)2
(14)
M5=(η30-3η12)(η30+η12)[(η30+η12)2
-3(η21+η12)2]+3(η21-η03)(η21+
η03)[3(η30+η12)2-(η21+η03)2]
(15)
M6=(η20-η02)[(η30+η12)2-(η21+η03)2]+
4η11(η30+η12)(η21+η03)
(16)
M7=(3η21-η03)(η21+η03)[3(η30+η12)2-
(η21+η03)2]-(η30-3η12)(η21+
η03)[3(η30+η12)2-(η21+η03)2]
(17)
利用上面得到的7个Hu不变矩来描述手势的轮廓特征,并将其表示为如下形式描述子:
FHu={M1,M2,M3,M4,M5,M6,M7}
(18)
2.3特征融合
通过计算空间曲率得到CSS形状描述子FCSS,通过Hu不变矩得到具有7个特征的Hu不变矩描述子FHu。但是CSS形状描述子和Hu不变矩描述子采用不同的距离度量方法,量纲不统一,而且CSS形状描述子的维数是不确定的,直接拼接会出现不平衡现象。所以不能直接将 2 种描述子融合使用,可以通过归一化和对特征进行加权来减小直接融合的影响,具体如下:
步骤1分别对CSS描述子和Hu不变矩描述子进行归一化,使其大小在0和1之间。
步骤2对归一化的距离进行线性加权,得到新特征:
F=a×FCSS+b×FHu
(19)
式中a、b为权值,需要在实验过程中确定,FCSS表示CSS描述子,FHu表示Hu特征描述子。
为了确定式(19)中线性加权系数a、b的数值,对a、b不同的取值进行试验,结果如表1所示。当a取值较小时,CSS特征所占比重比较大,缺少整体特征,识别率比较低,随着a的取值增大,整体识别率有所提升。当a增大到0.4时,识别率达到最大值,随着a继续增大,Hu不变矩特征所占比重逐渐增大,特征由于缺少局部描述,识别率开始下降。根据上述分析,本实验取a=0.4,b=0.6,结果如表1中第五行所示。
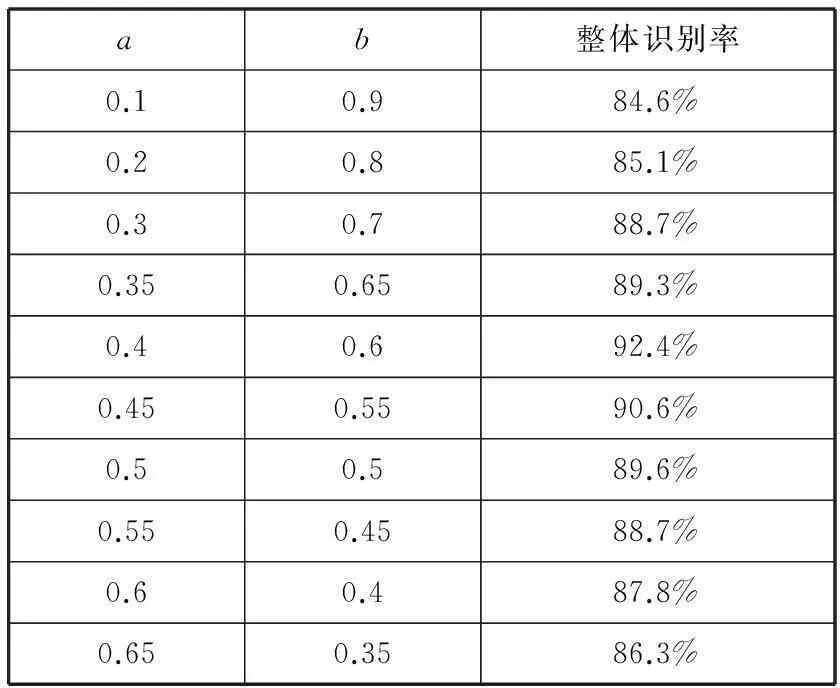
表1 不同权值a、b对应的识别率
3手势识别
本文采用BP人工神经网对图5中30个手语字母进行识别分类,取得了良好的识别效果。
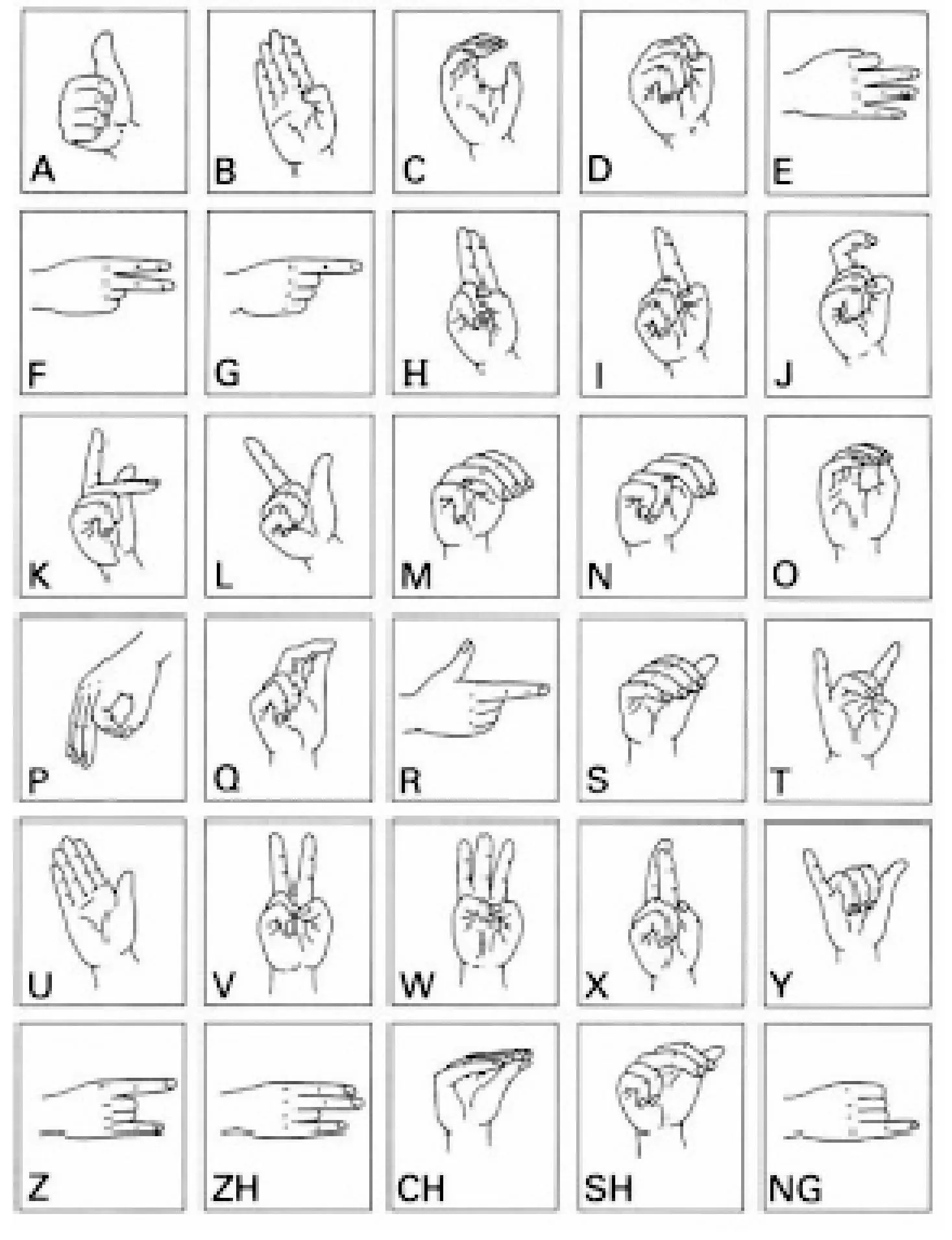
图5 手语中30个手势示意图
4实验结果分析及比较
针对图5中字母表中的30个手语字母,分别用摄像机对6个不同实验对象采集手势图像,每个手势采集20次,总共得到3600个样本,其中2700个用于样本训练,900个用于测试。900个测试样本的实验结果如表2所示。
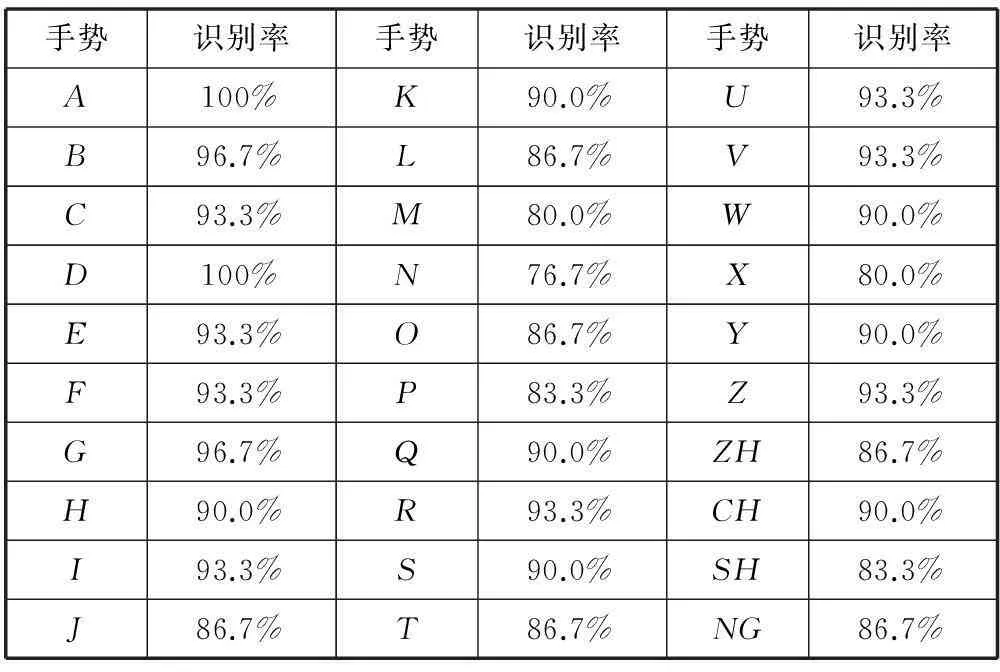
表2 不同手势识别率
900个测试样本,采用本文方法进行测试,取得了良好的实验效果,部分手势识别率达100%,整体识别率为92.4%。
为了验证本文方法的有效性,分别利用Hu不变矩特征(文献[4]中的方法)和CSS特征(文献[6]中的方法)对900个样本(每个手势30个样本)进行了测试。部分对比实验结果如表3、表4所示,整体结果如图6所示。
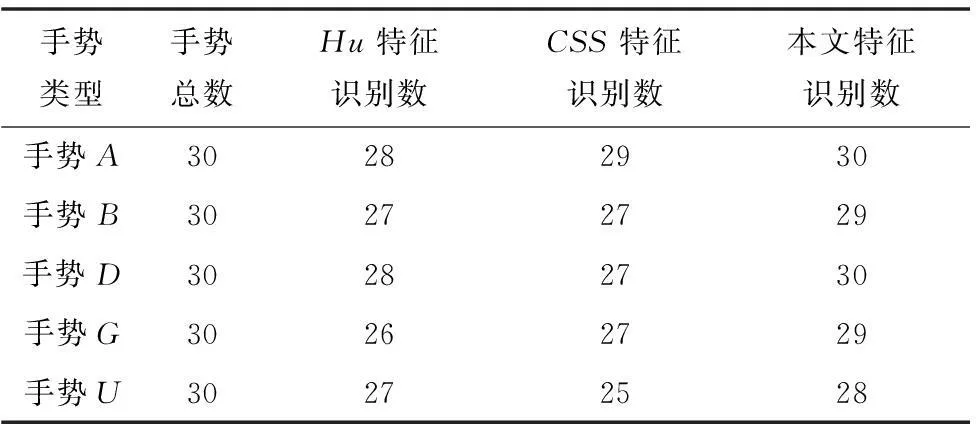
表3 针对手语中简单手势的不同方法实验结果对比
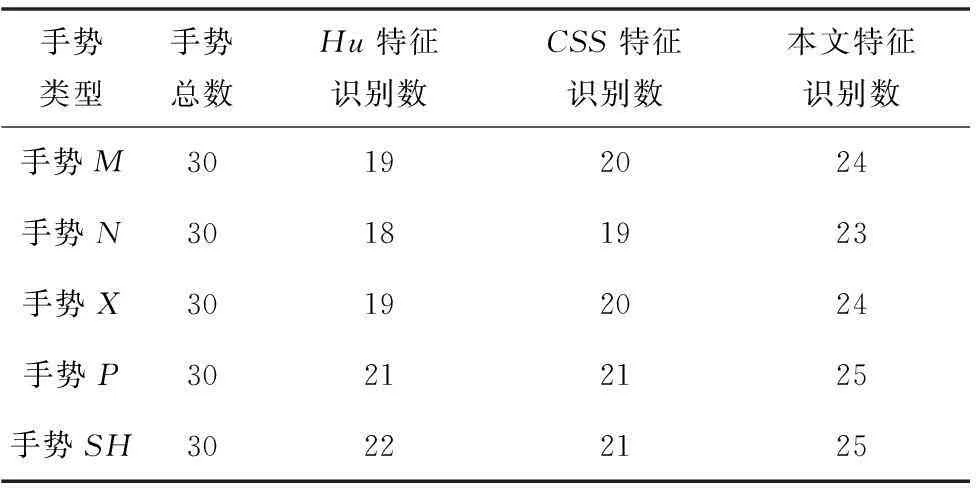
表4 针对手语中复杂手势的不同方法实验结果对比

图6 不同方法识别率对比图
从表3、表4可以看出,针对简单的手势,单独使用Hu不变矩或者CSS特征,可以取得较高的识别率。例如针对手势A,单独使用两种特征正确识别数分别达到28和29,但是对于一些复杂手势或局部区分度较小的手势,本文方法的识别率相较于单独使用一种特征有很大的提升。例如,针对手势M和手势N,这两种手势的局部相似度很高,单独使用CSS特征正确识别数分别为20和19,单独使用Hu不变矩特征,识别率分别为19和18,而综合使用CSS特征和Hu不变矩特征正确识别数分别达到24和23。
本文所有实验均是在如下环境完成:Inteli3 处理器,主频3.40GHz,2GB内存,Windows7操作系统VS2010+OpenCV2.4.9。所有图片分辨率为320×240。
5结语
针对Hu不变矩在静态手势特征描述中缺乏局部信息,而CSS特征描述子缺乏整体方面的描述,本文将两种描述子融合,作为一种新的特征。实验表明,相对于单一的CSS特征和Hu不变矩特征,融合特征对于局部相似度高和手语中较复杂的手势有很高的识别率,是一种更为有效的识别特征。
参考文献
[1] 翁汉良,战荫伟.基于视觉的多特征手势识别[J].计算机工程与科学,2012,34(2):123-127.
[2] 赵爱芳,裴东,王全州.复杂环境中多信息融合的手势识别[J].计算机工程与应用,2014,49(5):180-184.
[3] 李瑞峰,曹雏清,王丽.基于深度图像和表观特征的手势识别[J].华中科技大学学报:自然科学版,2011,40(S2):88-91.
[4] 王先军,白国振,杨勇明.复杂背景下BP神经网络的手势识别方法[J].计算机应用与软件,2013,30(3):247-249,267.
[5]LiuY,ZhangL,ZhangS.AHandGestureRecognitionMethodBasedonMulti-FeatureFusionandTemplateMatching[C]//InternationalWorkshoponInformationandElectronicsEngineering,Harbin,PEOPLESRCHINA,2012:1678-1684.
[6]ChangCC,LiuChengyi,TaiWenkai.FeatureAlignmentApproachforHandPostureRecognitionBasedonCurvatureScaleSpace[J].Neurocomputing,2008,71(10-12):1947-1953.
[7] 徐战武,朱淼良.基于颜色的皮肤检测综述[J].中国图象图形学报,2007,12(3):377-388.
[8]DhruvaN,RupanagudiS,SachinS,etal.NovelSegmentationAlgorithmforHandGestureRecognition[C]//IEEEInternationalMultiConferenceonAutomationComputing,Control,CommunicationandCompressedSensing,Kottayam,INDIA,2013:383-388.
[9] 陈皓,路海明.基于深度图像的手势识别综述[J].内蒙古大学学报:自然科学版,2014,44(1):105-111.
[10] 张汗灵,李红英,周敏.融合多特征和压缩感知的手势识别[J].湖南大学学报:自然科学版,2013,34(3):87-92.
COMPUTER VISION-BASED RECOGNITION OF HAND GESTUREWITHMULTIPLEFEATURES
Zhang JunZhang KongYang Zhengling
(School of Electrical and Automation Engineering,Tianjin University,Tianjin 300072,China)
AbstractBecause of lacking full hand gestures contour information, current commonly used hand gesture recognition algorithms using single feature have lower recognition rate for the gestures with high local similarity and complicated shapes. Therefore we proposed a novel hand gesture feature extraction method, which combines the feature descriptor of curvature scale space (CSS) with Hu invariant moment. First, we used the skin colour model to extract the gestures from complicated background, and then extracted Hu invariant moment and CSS descriptor of gestures respectively to construct fusion features. At last, we made use of the artificial neural network to recognise and classify the new features. Experimental results demonstrated that compared with the recognition approaches based on single gesture feature, the proposed method has higher integral recognition rate, and improves significantly in recognition rate on gestures with high local similarity in shape.
KeywordsComputer visionHand gesture recognitionCSSHu invariant momentNeural network
收稿日期:2014-12-26。天津市创新基金项目(13ZXCXGX404 00)。张军,副教授,主研领域:图像处理,智能交通。张孔,硕士生。杨正瓴,副教授。
中图分类号TP3
文献标识码A
DOI:10.3969/j.issn.1000-386x.2016.06.037
猜你喜欢
阅读(快乐英语中年级)(2024年6期)2024-10-14 00:00:00
舰船科学技术(2022年20期)2022-11-28 08:23:02
疯狂英语·新悦读(2020年4期)2020-06-18 05:35:28
好孩子画报(2020年3期)2020-05-14 13:42:44
红领巾·萌芽(2019年9期)2019-10-09 03:42:56
小学科学(学生版)(2018年12期)2018-12-19 05:13:50
自动化学报(2017年4期)2017-06-15 20:28:54
小学阅读指南·低年级版(2017年6期)2017-06-12 01:39:24
电测与仪表(2015年3期)2015-04-09 11:37:56
华东理工大学学报(自然科学版)(2014年3期)2014-02-27 13:49:03
