
一种基于肯定选择的异常检测方法
2016-07-06 01:49范九伦
西安邮电大学学报 2016年2期
范九伦, 苏 晗
(西安邮电大学 通信与信息工程学院, 陕西 西安 710121)
一种基于肯定选择的异常检测方法
范九伦, 苏晗
(西安邮电大学 通信与信息工程学院, 陕西 西安 710121)
摘要:对肯定选择算法进行优化,以提高异常检测的检测率。对网络中的正常行为特征进行K均值聚类,以各类的中心作为检测器并加入成熟检测器集合;使用肯定选择方法将检测到的异常行为特征进行K均值聚类,产生新的检测器且加入到成熟检测器集合中;检测器的检测顺序随着检测器与测试数据匹配次数的增加而优先,再根据二次免疫理论将成熟检测器集合中检测顺序优先的检测器加入到记忆检测器集合。分别使用优化后的方法和基于集群概率的检测方法对abalone数据集进行检测,结果显示,优化后的方法在测试数据为200时,检测率可提高1.8%,整体检测性能较优。
关键词:人工免疫;入侵检测;肯定选择;聚类
入侵检测系统(IntrusionDetectionSystem,IDS)的作用是加强信息网络和通信系统的安全性,衡量其性能的指标有检测率、误警率和检测速率[1]。
按照检测原理,入侵检测系统可分为误用检测和异常检测两类[2]:误用检测根据已知的攻击建立初始特征库,当发现用户的行为特征与特征库的记录相匹配时,认为遭受入侵行为;异常检测先建立正常行为特征的数据库,对系统和应用程序的行为特征和正常行为特征相比较,当与正常行为有明显的偏差时认为该行为是入侵。误用检测系统与异常检测系统相比,误警率的低,但不能检测出新的入侵行为,而异常检测却可以。误用检测需要指定已知入侵行为先验的特征数据库,而异常检测只需知道正常行为的一些信息。
生物免疫系统(BiologyImmuneSystem,BIS)是高度复杂、自组织和具有动态平衡能力的分布式系统,能够区分自体和非自体,抵御和消除外来的病毒入侵,维持生物体正常生命活动的稳定[3]。基于由此演化而来的人工免疫系统(ArtificialImmuneSystem,AIS),人们得出许多入侵检测方法。
基于B细胞生成原理的否定选择算法(NegativeSelectionAlgorithm,NSA)[4],是基于免疫系统的主要检测方法之一。否定选择算法中基于二进制的方法得到广泛应用,但是二进制具有空间局限性,无法适应复杂网络环境。若用实值形式反映空间结构,用欧几里德距离描述检测器[5],那么,由于检测器的半径难以估计,检测器对非自体集的覆盖重复率高,必然导致检测效率不高。高维实值空间下的检测器分布优化算法[6]可提高对非自体空间的覆盖率,但却不能很好地解决检测器间存在重复的问题。
基于肯定选择原理的肯定选择算法(positiveselectionalgorithm,NSA)[7],训练自体样本产生检测器,无需通过学习产生检测器,只需利用自我集合即可产生检测器。有实验表明[8],该方法在分类检测方面优于否定选择算法,但当自我样本数量较多时,运算时间呈指数增长,时间复杂度很大。
本文将给出一种实值聚类肯定算法(realvalueclusteredpositiveselectionalgorithm,RVCPS),对自体集聚类得到初始检测器,让检测器的检测顺序动态变化,根据二次免疫理论,选择性能较优的检测器,加入记忆检测器集合,以提高检测效率。
1基于RVCPS算法的异常检测
1.1检测器的生成
检测器是整个入侵检测的核心,检测器的好坏直接决定了入侵检测系统的性能。基于人工免疫的入侵检测系统很难完整定义自体集和非自体集,这是因为,自体集包含很多子集合,每个子集合都是自体集的一部分,各子集之间的行为特征都不相同,它们代表着不同类型的正常行为特征[9]。考虑到聚类算法可将一个数据集划分为若干个类,其中相似数据划归为一类,差别较大数据划入不同类,从而使每类数据具有相似特征,各类数据具有较大差异,现对自体集进行聚类产生检测器。
定义1(形态空间)一个n维的形态空间A,包含所有的正常行为特征和所有的异常行为特征。
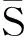
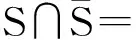
集合S的每个元素都是一个n维向量,每一维代表了不同的行为特征。
实值肯定选择算法将所有状态定义在n维空间,由于各维属性都有不同衡量标准,需要对原始数据正规化处理[10]。利用公式
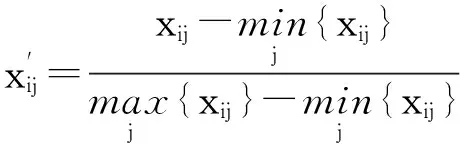
将各属性值映射到区间[0,1]。
采用K均值聚类算法对自体集合进行聚类,每类代表一个检测器。用类中心和半径描述该检测器,这样,每个检测器就是一个超球体[11]。对接近某检测器的待检测数据,若其与检测器中心的欧氏距离小于超球体半径,则认为此数据与检测器匹配,标记为“自我”,否则,转入下一检测器,继续进行匹配判断。
1.2优先检测器
对于下一检测器的定义,现行检测机制大都随机指定,或按设定好的序列选取。实际上,用户打开一个或者多个应用后,在一段时间内会持续使用这些应用,该段时间可分为许多很短的时隙,在每个时隙中,应用程序所产生的行为特征几乎一样,因此,短时间内得到的待检测样本大多具有相同行为特征。基于计算机应用程序的这一特征,对每个检测器设置动态的优先级,优先级最高的检测器第一个开始检测。通过检测器的优先级机制,可以减少时间复杂度,提高检测效率。
定义3(匹配次数)记检测器的匹配次数为c,其初始值为0。检测器匹配到一个待测数据后,匹配次数c值加1。
假设待检测样本集合为
T={t1,t2,…,tN},
K个检测器的初始优先级顺序为d1,d2,…,dK。从n=1开始,若待测样本tn与第1个检测器匹配,则对检测器的优先级顺序不作调整;若待测样本tn未能与前k个检测器匹配,而与第k+1个检测器匹配,则调整检测器优先级顺序,即交换第k和第k+1个检测器的位置,让后者成为优先级更高的检测器。
1.3异常检测器
如果待检测样本是异常行为的样本,它会首先计算和优先级最高检测器之间的欧氏距离,结果自然是不会被这个检测器匹配,也不会被后面的任何一个检测器所匹配,这个待测样本最后会被标记为“异常”。
当检测进行一段时间后,被标记为异常的样本会越来越多。设定一个阈值M,当被标记的异常样本数量大于该阈值M,且检测器集合中检测数量k小于检测器集合容量K时,将这些异常样本采用与自体集合相同的聚类算法进行分类,并选取其中k′(k′≤K-k)个类加入检测器集合。此时,检测器集合中既包含自我检测器,又包含异常检测器,且自我检测器和异常检测器具有不同标签。如此可使检测器具备学习性,能够检测到新的异常类型。当待测数据与异常检测器匹配时则认为此数据为异常。
检测器子模块可描述如下。
If(检测器集合不为空)
检测器按照优先级顺序依次与待测数据进行匹配;
If(匹配)
{查看该检测器标签,并标记该待测数据;
该检测器匹配次数值++;
该检测器优先级++;
}
Else将待测数据标记为异常;
End
1.4记忆检测器
生物免疫系统遭受初次外来病原入侵后,免疫系统能够发挥记忆效应,作出二次免疫应答,当再次遭受同样的病原入侵时,即可快速高效地产生大量抗体,将抗原清除[12]。在入侵检测中利用二次免疫的机理可以快速检测到异常。
将检测器集合中匹配次数c大于阈值H的检测器激活,加入记忆检测器集合,并将匹配次数c清零。每次检测开始让待测数据和记忆检测器相匹配,每匹配一次,匹配次数c加1,一段时间后检查各检测器的c值,将c值为0的记忆检测器删除,以保证记忆检测器集合中都是精英集合器。
记忆检测器子模块可描述如下。
If(记忆检测器集合不为空)
记忆检测器按优先级顺序依次与待测数据匹配;
If(匹配)
{
查看该检测器标签,并标记该待测数据;
该检测器匹配次数值++;
该检测器优先级++;
}
Else将待测数据交给检测器集合进行匹配;
End
2实验结果及分析
使用abalone数据集作为测试数据集,测试性能通过检测率(Detectionrate,DR)和误警率(Falsealarmrate,FA)两大指标体现。
以TP代表判定为异常的异常数据个数,TN代表判定为正常的正常数据个数,FP代表判定为异常的正常数据个数,FN代表判定为正常的异常数据个数。分别定义检测率和误警率为
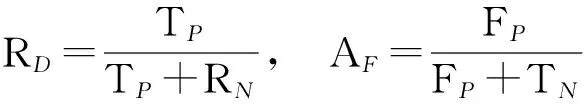
abalone数据集每条数据都有9个属性,选取其中7个属性,共4 178个数据进行测试。将abalone数据集中标记为F和M的数据认为是正常数据,标记为I的认为是异常数据。利用其中2 300个正常数据作为自体集,进行K均值聚类,生成初始检测器。将自体集合分为80个小类,检测器集合最大容量设为100。在检测阶段,选取300个异常数据和700个正常数据进行测试,所得结果如图1所示。
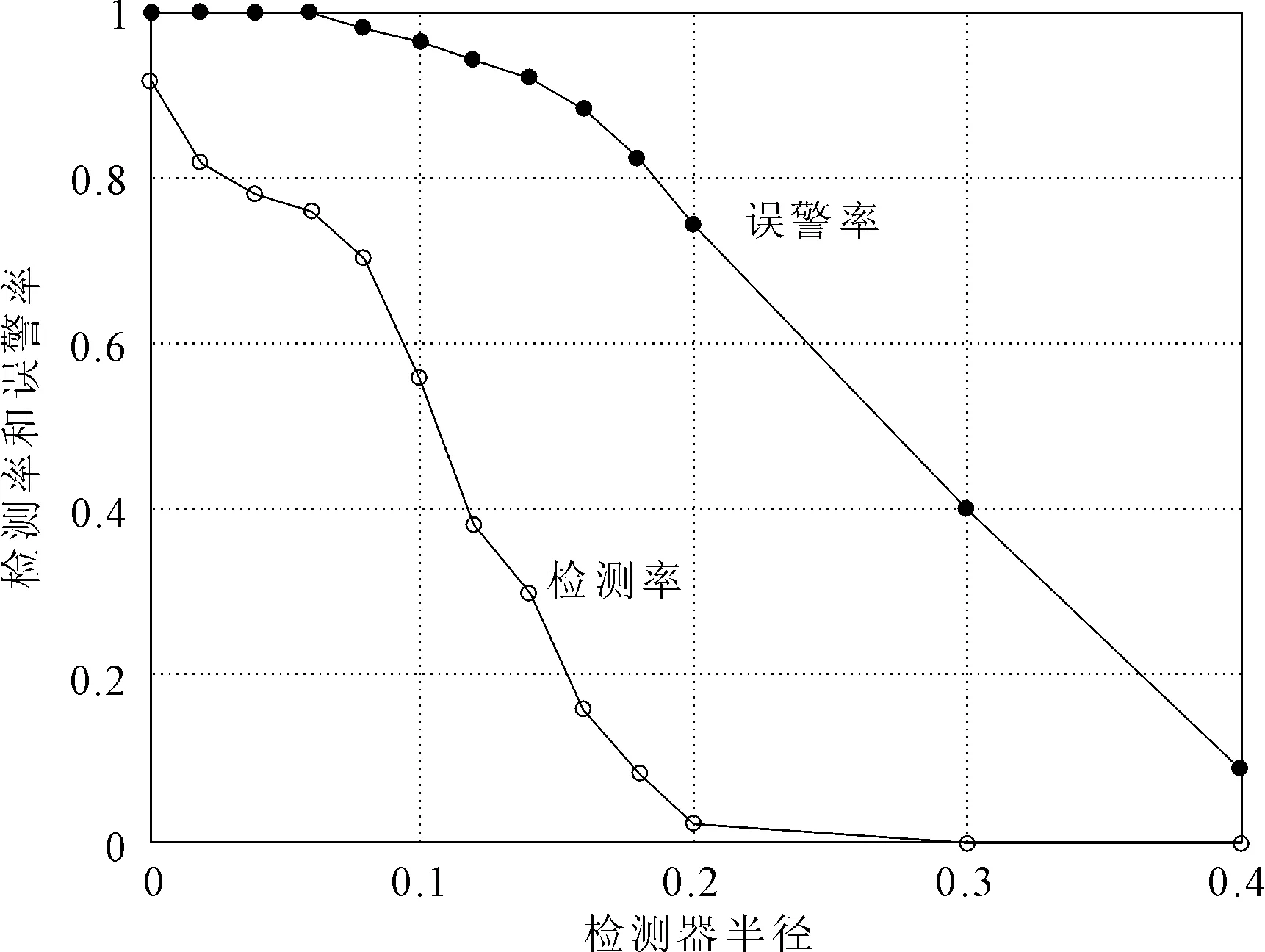
图1 abalone数据集检测率和误警率
由图2可见,检测器半径是影响检测器性能的主要因素,检测器的半径越小检测率越高,但相应的误警率也较高。在半径较小的时候,测试数据与聚类中心点的欧氏距离几乎都比半径大,造成很多的正常数据被检测器标记为异常数据,造成误判,使得误警率较大。实验显示,对于abalone数据集而言,当检测器的半径为0.18时检测的性能最佳。
基于集群概率的检测方法(clusteredprobabilisticartificialimmune,CPAI)[13],借用肯定选择算法,通过对自体集聚类,并计算概率密度函数来检测异常。选择abalone数据集,设置10组实验,每组测试数据中正常数据与异常数据比例为7∶3,检测器半径设为0.18,对比RVCPS算法与CPAI算法的检测率,结果如图2所示。
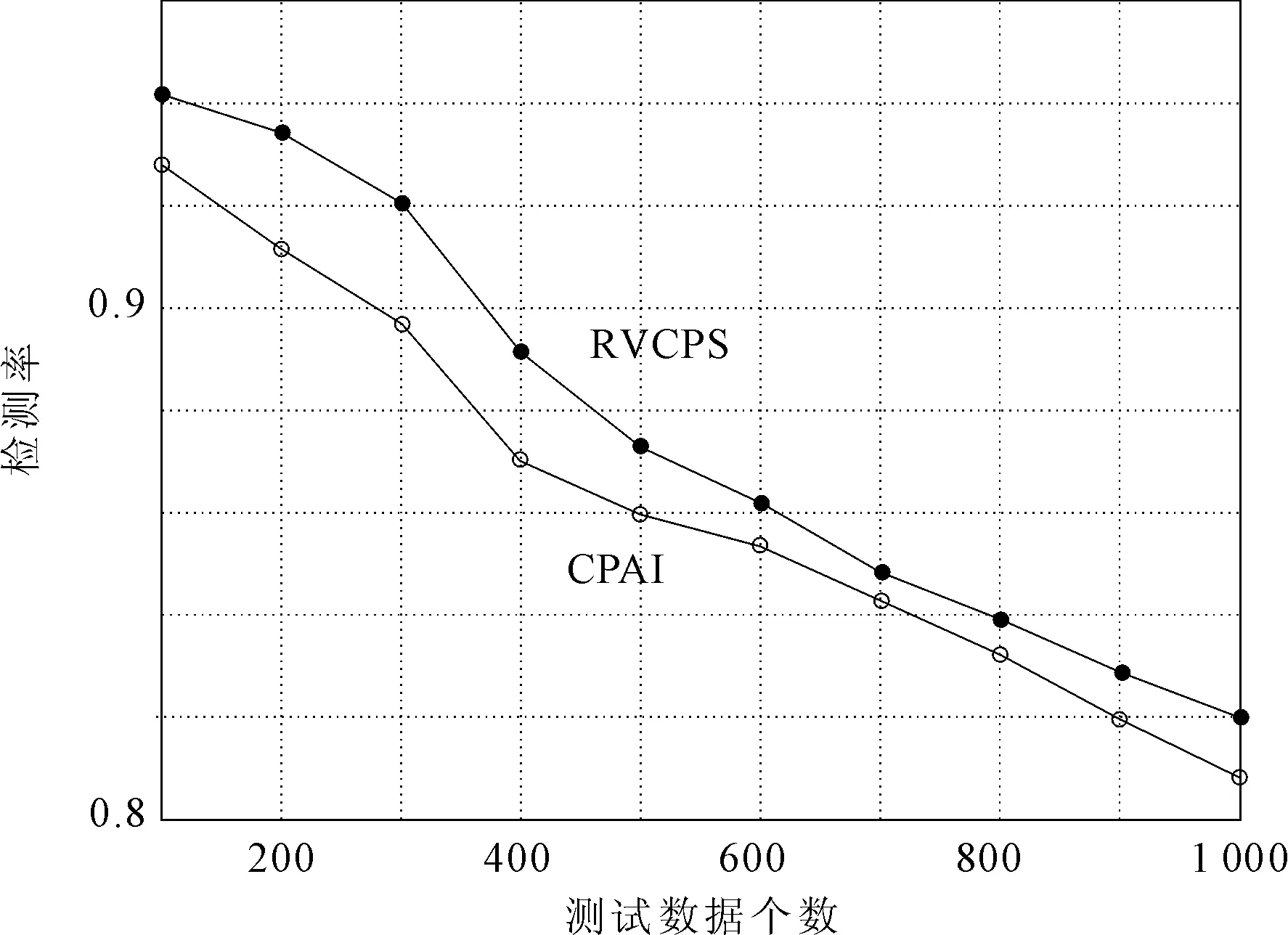
图2 RVCPS算法与CPAI算法检测率对比
参与对比的两种检测方法都具有较高检测率,但相比而言,RVCPS算法要高于CPAI算法。另外,两种算法的检测率都会随着测试数据量的增加而减小,这主要是由于,检测器是自体集聚类所产生,当测试数据越来越多时候,在肯定选择过程中没有出现的正常数据越来越多,检测器不能完全的识别这些正常数据,从而引起检测率随测试样本数量的变化。
3结语
给出一种基于实值聚类的肯定选择,通过自体集聚类产生检测器,引入优先级和二次免疫的概念,可提高检测器生成效率和检测效率。将异常检测器加入到检测器集合,可使检测器具备多样性和检测未知异常的能力,同时避免否定选择算法随机选择样本所带来的弊端。实验显示,所给方法是一种有效的异常检测方法。检测器半径的选择是影响所给方法性能的重要因素,仍需寻求找到最佳半径的有效方法。
参考文献
[1]张玲,白中英,罗守山,等.基于粗糙集和人工免疫的集成入侵检测模型[J/OL].通信学报,2013,34(9):166-176[2015-10-10].http://mall.cnki.net/magazine/article/TXXB201309020.htm.
[2]芦天亮,郑康锋,傅蓉蓉,等.基于阴性选择算法的异常检测系统黑洞覆盖优化[J/OL].通信学报,2013,34(1):128-135[2015-10-10].http://mall.cnki.net/magazine/article/TXXB201301014.htm.
[3]金章赞,廖明宏,肖刚.否定选择算法综述[J/OL].通信学报,2013,34(1):159-170[2015-10-10].http://mall.cnki.net/magazine/article/TXXB201301017.htm.
[4]FORRESTS,PERELSONAS,ALLENL,etal.Self-nonselfdis-criminationinacomputer[C/OL]//ProceedingsofIEEESymposiumonResearchinSecurityandPrivacy.USACALosAlamitos:IEEE,1994:202-212[2015-10-10].http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.453.1098.
[5]GONZALEZFA,DASGUPTAD.Anomalydetectionusingreal-valuednegativeselection[J/OL].GeneticProgrammingandEvolvableMachines,2003,4(4):383-403[2015-10-10].http://d.wanfangdata.com.cn/NSTLQK/NSTL_QKJJ029895553.
[6]刘海龙,张凤斌,席亮.免疫入侵检测高维实值检测器分布优化算法[J/OL].清华大学学报:自然科学版,2012,52(10):1415-1419[2015-10-10].http://mall.cnki.net/magazine/Article/QHXB201210016.htm.
[7]STIBORT,MOHRP,TIMMISJ,etal.Isnegativeselectionappropriateforanomalydetection[C/OL〗//GECCO’05Proceedingsofthe7thannualconferenceonGeneticandevolutionarycomputation.NewYork:ACM, 2005:321-328[2015-10-10].http://dx.doi.org/10.1145/1068009.1068061.
[8]洪征,吴礼发.基于阳性选择的蠕虫检测系统[J/OL].软件学报,2010,21(4):816-826[2015-10-10].http://www.cnki.com.cn/Article/CJFDTOTAL-RJXB201004022.htm.
[9]MOHAMMADIM,AKBARIA,RAAHEMIB,etal.Afastanomalydetectionsystemusingprobabilisticartificialimmunealgorithmcapableoflearningnewattacks[J/OL].EvolutionaryIntelligence, 2014,6(3):135-156[2015-10-10].http://link.springer.com/article/10.1007/s12065-013-0101-3.
[10] 罗敏,王丽娜,张焕国.基于无监督聚类的入侵检测方法[J/OL].电子学报,2003,31(11):1713-1717[2015-10-10].http://mall.cnki.net/magazine/article/DZXU200311027.htm.
[11]GONZALEZFA,DASGUPTAD.Anomalydetectionusingreal-valuednegativeselection[J/OL].GeneticProgrammingandEvolvableMachines, 2003,4(4):383-403[2015-10-10].http://d.wanfangdata.com.cn/NSTLQK/NSTL_QKJJ029895553.DOI:10.1023/A:1026195112518.
[12] 芦天亮,郑康锋,刘颖卿 ,等.基于动态克隆选择算法的病毒检测模型[J/OL].北京邮电大学学报,2013,36(3):39-43[2015-10-10].http://www.cnki.com.cn/Article/CJFDTotal-BJYD201303010.htm.
[13] 高炜,曹锐.一种基于集群概率的网络入侵检测算法[J/OL].电子技术与软件工程,2015(8):231-234[2015-10-10].http://www.cnki.com.cn/Article/CJFDTotal-DZRU201508169.htm.
[责任编辑:瑞金]
Ananomalydetectionmethodbasedonpositiveselectionalgorithm
FANJiulun,SUHan
(SchoolofCommunicationandInformationEngineering,Xi’anUniversityofPostsandTelecommunications,Xi’an710121,China)
Abstract:The traditional positive selection algorithm is optimized to improve the detection rate of anomaly detection. In the method, k-means clustering algorithm is applied on normal behaviors in the network, each class center is regarded as a detector, and the detectors are added to the mature detector set. The positive selection method is used to get a k-means clustering of the detected abnormal behavior characteristics, and the produced detectors are also added to the mature detector set. The priority of the detector in detection sequence is preferred, if the matching times of the the detector and the test data increase. According to the secondary immune theory, the detectors with high priority are added to the memory detector set. The optimization method and clustered probabilistic artificial immune method are used to detect the abalone data sets, and experiments results show that, the optimization method performs well in generral, and when the test data is 200, its detection rate increases by 1.8%.
Keywords:artificial immune, intrusion detection, positive selection, clustering
doi:10.13682/j.issn.2095-6533.2016.02.002
收稿日期:2015-11-30
基金项目:国家自然科学基金资助项目(61340040;61202183;61102095)
作者简介:范九伦(1964-),男,博士,教授,博士生导师,从事模式识别和信息安全研究。E-mail: jiulunf@163.com 苏晗(1990-),男,硕士研究生,研究方向为网络与信息安全。E-mail: suhanarppp@163.com
中图分类号:TN915.08
文献标识码:A
文章编号:2095-6533(2016)02-0012-05
猜你喜欢
铁道通信信号(2019年6期)2019-10-08
雷达学报(2017年6期)2017-03-26
现代电子技术(2016年24期)2017-01-19
现代商贸工业(2016年28期)2016-12-27
电子技术与软件工程(2016年22期)2016-12-26
电脑知识与技术(2016年21期)2016-10-18
互联网天地(2016年1期)2016-05-04
科技视界(2016年9期)2016-04-26
自动化学报(2016年8期)2016-04-16
智能系统学报(2015年4期)2015-12-27
