
基于交互意见和地位理论的符号网络链接预测模型
2016-06-30 07:44左万利
计算机研究与发展 2016年4期
王 鑫 王 英 左万利
1(长春工程学院计算机技术与工程学院 长春 130012)2(吉林大学计算机科学与技术学院 长春 130012)3(符号计算与知识工程教育部重点实验室(吉林大学) 长春 130012)4(广西可信软件重点实验室(桂林电子科技大学) 广西桂林 541004)(xinwangjlu@gmail.com)
基于交互意见和地位理论的符号网络链接预测模型
王鑫1,3,4王英2,3左万利2,3
1(长春工程学院计算机技术与工程学院长春130012)2(吉林大学计算机科学与技术学院长春130012)3(符号计算与知识工程教育部重点实验室(吉林大学)长春130012)4(广西可信软件重点实验室(桂林电子科技大学)广西桂林541004)(xinwangjlu@gmail.com)
摘要随着社会网络的普遍和流行,社会网络为符号网络(signed network)的深入研究提出了更多的全新问题,其中链接预测是符号网络研究的核心问题之一.交互意见和地位理论能够较好地解释符号网络中链接关系的构建和链接的符号属性,二者作为链接构建的诱因为提高链接预测的质量提供了理论基础.因此,通过研究交互意见和地位理论与链接关系的强相关性,构建符号网络链接预测模型.首先,利用交互意见增强待分解矩阵的可靠度,弥补由地位理论的对称性所带来的局限性;然后,在稀疏学习矩阵分解模型基础上,将交互意见建模为增强可靠度因子,同时将地位理论建模为稀疏学习模型的正则化项;最后,构建基于交互意见和地位理论的符号网络链接预测模型MF-SI.实验结果表明相比于其他基本方法,MF-SI模型获得了较好的预测质量,说明集成交互意见和地位理论能够较好地实现符号网络链接预测问题.
关键词符号网络;链接预测;稀疏学习;交互意见;地位理论
符号网络(signed network)是具有正或负符号属性标记的有向网络,其中正向链接(positive link)表示积极关系,负向链接(negative link)表示消极关系[1].具体而言,符号网络中的正向链接使用“+”表示,表达了2个节点之间具有信任、朋友、支持和喜欢等积极关系;而负向链接使用“-”表示,表达了2个节点之间具有敌对、不信任、讨厌和反对等消极关系.特别是在社交媒体领域,用户之间借助社交网络平台表达信任与不信任关系、构建朋友与敌对关系、对论坛内容发表支持与反对观点等.符号网络中链接预测问题是利用网络拓扑结构数据和用户行为数据预测尚未建立链接的2个节点之间是否可能建立链接关系以及标记链接关系的符号属性.
符号网络在机器学习和数据挖掘领域研究中具有重要的研究意义和应用价值,并引起越来越多研究人员的关注.因此,提出了高效的链接预测模型用于实现正向链接和负向链接的预测,并在Epinions数据集上构建多组实验,实验结果证明所提出的模型能够准确地预测符号网络中的链接关系.主要贡献如下:
1) 提出有效的量化策略分别量化交互意见和地位理论;
2) 将交互意见模拟为增强可靠度因子,模拟地位理论为稀疏学习模型的正则化项,利用矩阵分解学习模型融合交互意见和地位理论构建链接预测模型MF-SI预测链接关系,进而构建符号网络;
3) 在Epinions数据集上评估所提出的模型MF-SI,构建多组实验验证模型的有效性,并详细地阐述不同链接构建诱因以及不同量化策略对链接正负预测质量的影响.
1相关性研究
最早的符号网络研究起源于20世纪40年代的社会心理学领域,Heider[2]提出不同类型的社会关系对个体心理平衡产生不同影响,从心理学角度研究人在认知过程中所产生的正向关系和负向关系之间的相互作用.Cartwright 和Harary[3]在Heider的基础上系统地将线性的数学理论应用于Heider平衡理论中,对其形式化描述为正、负属性的符号网络.现有符号网络的链接预测问题采用的方法包含2个方面:监督学习和非监督学习方法.监督学习将链接预测问题视为在已知链接标识的基础上利用监督学习算法,如决策树[4]、迁移学习[5]、组合分类器[6]等实现分类问题;非监督学习利用网络结构的拓扑属性和交互行为进行分析预测,比如节点相似性[7-8]、链接存在的最大似然[9]和矩阵处理[10-11]等.
监督学习方法首先收集带有符号属性的链接标记数据,然后为用户对构建各种类型的特征.针对网络拓扑结构特征而言,正负链接中节点的出入度特征[12]和基于平衡理论的三角形特征[13]较为常见.Leskovec等人[12]重点考虑节点出入度等局部测度特征和待预测边所处的结构平衡理论三角形关系模式特征,并利用逻辑回归(logistic regression)方法训练模型对边进行分类并获得了较高预测准确度.实验证明符合结构平衡理论和地位理论的三元组对于待预测边的符号属性预测起到了重要作用.Chiang等人[14]认为平衡理论三角形关系特征并不具备鲁棒性,因为有的符号社会网络较为稀疏并且大多数用户并没有基于平衡理论三角形关系特征,进而提出引入长度为k的环特征量化不平衡指标,再利用分类算法预测边的符号属性.该方法从全局的角度出发利用网络的不平衡程度进行预测,从而实现对Leskovec等人局部度量方法的扩展.除了网络拓扑结构数据之外,用户的属性信息[15]和情境信息[6]也可作为参考特征,比如兴趣、职业、性别、家乡等.Patidar等人[15]首先通过训练基于用户属性信息的分类器预测未知链接,然后根据平衡理论判断是否保持或扩大平衡指数来预测未知链接.Zolfaghar等人[6]利用符号网络拓扑结构和情境信息构建熟识度、声誉度、相似度和个性化4个因素的特征集合,然后利用组合分类器算法预测网络中链接的符号属性.
非监督学习方法通常是根据符号网络中拓扑结构数据以实现链接关系的预测.一般来说,非监督学习方法依据不同策略可将链接预测分成2个方面:1)基于相似度的方法.首先定义相似度量化策略用于衡量节点的相似度,然后根据相似度推断链接的符号属性.2)基于矩阵处理的方法.该方法主要包括传播模型、矩阵分解[16]或矩阵填充方法预测链接的符号属性.在基于相似度的方法中,Javari等人[7]提出一种基于聚类和协同过滤的方法用于预测符号网络中正向和负向链接,首先在符号网络中引入簇之间的条件相似度概念,并将网络聚类成一定数量的簇,使其每个簇都满足平衡性,然后应用基于用户的协同过滤算法实现链接的预测,有效地解决了符号网络的稀疏性问题.Symeonidis等人[8]提出一种基于朋友推荐的算法,首先实现拉普拉斯矩阵谱聚类算法,然后定义同一簇的节点相似度和不同簇的节点相似度的计算方法,最后借助朋友推荐算法实现符号网络中的链接预测.在矩阵处理方法中,最早的信任传播模型研究是由Ramanthan等人[17]将负关系融入信任传播模型,利用4种基本的信任传播模式,实现在拥有较少的信任或不信任关系基础上以较高的准确度预测网络中2个用户之间的信任或不信任关系.矩阵分解是将矩阵分解成多个矩阵的乘积,利用低秩矩阵不断地逼近原矩阵进而补齐原矩阵中的缺失值,达到预测符号网络链接正负属性目的.基于矩阵分解或矩阵填充方法,Hsieh等人[10]验证在符号网络中弱结构平衡往往会产生全局的低秩模型,然后将链接预测问题转化为低秩矩阵填充问题.
综上所述,虽然对符号网络链接预测模型的研究已有很多,大部分工作都是在2个节点之间已经存在链接关系的假设前提下预测链接的符号属性[18].但是,同时完成符号网络中任意2个节点是否建立链接关系以及预测链接关系的符号属性,在预测难度和准确率方面遇到了极大困难和挑战,这正是本文的工作重点和贡献.社会学理论有助于解释社会现象,从而获得对社会现象发生、发展的规律性认识,而带有符号属性的社会网络是由多个节点构成的一种社会结构,能够反映现实世界中用户之间的联系.因此,将社会学理论引入符号网络链接预测的研究,将会在很大程度上提高链接预测的质量[19-20].
2问题形式化描述
用D=[Z,E,R,G]表示Epinions数据集中所有数据的集合.其中,Z={u1,u2,…,un}表示用户集合,n为用户数量;E∈n×m表示用户-评论关联矩阵,m为评论数量,Ei j=1表示用户ui发表评论rj,否则Ei j=0;R∈n×m表示用户对评论的帮助评级矩阵,如果用户ui评级了评论rj的帮助程度,那么用Ri j表示帮助评级的分值;G∈n×n表示用户之间符号网络矩阵,如果Gi j=1表示用户ui与用户uj之间存在正向链接关系,用矩阵P∈n×n表示,而Gi j=-1表示用户ui与用户uj之间存在负向链接关系,用矩阵N∈n×n表示.
针对以上描述,符号网络链接预测问题转变为设计预测框架f,利用网络拓扑结构数据和用户的评级行为数据预测未知的正向和负向链接关系,即给定已有的符号网络关系矩阵G、用户-评论矩阵E、用户对评论的帮助评级矩阵R,目的是学习预测框架f预测未知的正负向链接关系矩阵P′和N′,即:
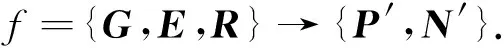
(1)
3数据分析以及链接构建诱因量化
3.1数据分析
Epinions.com是著名的商品评价的社交网站,是提供消费者对所购买的商品进行评论的平台,公正的评论值得用户信任,帮助用户确定购买决策.Epinions数据集*http://www.trustlet.org/wiki/Downloaded_Epinions_dataset的处理过程如下:1)获取由用户创建的信任和不信任链接关系,以及由用户行为数据构成的用户评价信息.对于链接关系,主要包括施信者(trustor)与受信者(trustee)之间建立的正向链接和负向链接,以及链接关系构建时间;对于用户行为数据,主要包括用户对商品的评论以及用户对评论的帮助评级.2)将用户的所有评级按照时间偏序排列,过滤掉构建链接关系时间之后的所有评级信息.3)由于不活跃或不重要的用户在一定程度上会影响评估结果,将少于2个施信者、2个评论及2个评级信息的用户过滤掉.表1为处理后的Epinions数据集统计结果.
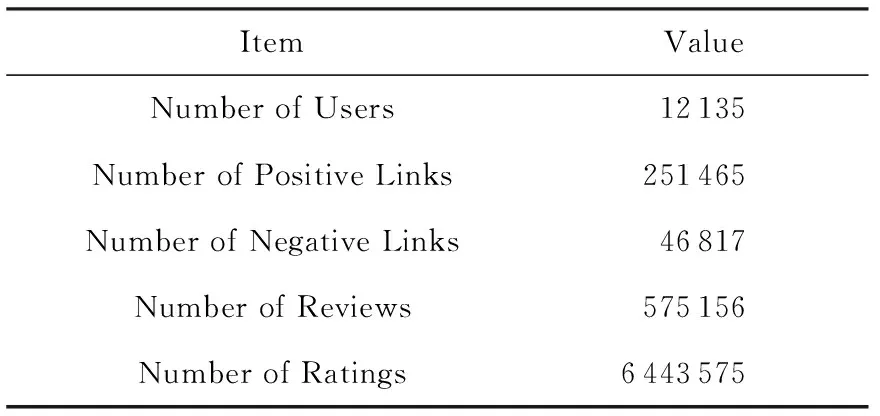
Table 1 Statistics of Epinions Dataset
3.2链接构建诱因量化
3.2.1交互意见量化
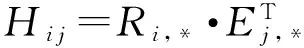
(2)
(3)
相反,负向意见倾向ET-(ui,uj)的量化公式如下:
(4)

3.2.2地位理论量化
在Epinions中,由于缺乏权威的第三方认定机构对用户社会地位的评估,只能借助网络拓扑结构量化策略衡量用户在社会网络中的地位.在符号网络中,正向链接入度有助于提升节点的地位,而负向链接入度降低节点的地位.由于经典PageRank算法未考虑入度链接的符号属性对节点地位的影响,因此提出引入正负向链接的地位理论的量化策略,用于计算用户的社会地位,即PolarityRank和PolarityIndegree.
1)PolarityRank.借鉴PageRank算法的思想,从全局角度衡量节点在符号网络中的重要地位.PolarityRank被定义为
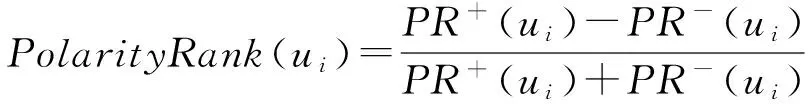
(5)
其中,PR+(ui)和PR-(ui)分别表示正向链接和负向链接对用户ui社会地位变化的贡献度,其公式为
(6)
其中,参数α表示阻尼系数,通常将其设置为0.85;Out(ui)表示节点ui的出度数;In+(ui)和In-(ui)分别表示节点ui正向入度数和负向入度数.
2)PolarityIndegree.借鉴投票机制,利用正、负向的入度链接数量,从局部角度衡量节点在符号网络中的重要地位.PolarityIndegree被定义如下:
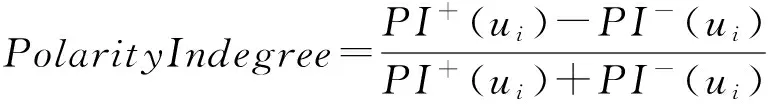
(7)
其中,PI+(ui)和PI-(ui)分别采用sigmoid函数形式衡量正、负向链接入度的贡献程度,定义如下:
(8)
其中,参数α表示控制入度链接的权重系数.
4链接构建诱因的动机观察
利用Epinions数据集,以交互意见和地位理论为理论依据分析用户之间建立链接的诱因.由于很难准确识别出建立诱因,仅仅通过最简单和直接的方式,即观测社会网络中真实的数据,针对不同诱因,利用网络拓扑数据和用户行为数据展开深入分析,进而产生设计符号网络链接预测框架的动机.
4.1交互意见
为了验证交互意见与关系符号属性之间的关联关系,利用正向和负向交互意见量化策略尝试回答2个问题:
1) 施信者的正向意见倾向大于负向意见倾向是否更可能与受信者建立正向链接关系?
2) 施信者的负向意见倾向大于正向意见倾向是否更可能与受信者建立负向链接关系?
为了回答以上2个问题,首先针对每对用户关系量化施信者对受信者的正向意见倾向ET+与负向意见倾向ET-的差值;然后统计正向关系和负向关系情感差异的密度分布.从图1可以发现,大多数信任关系(几乎达到92%)分布在意见差异值[0, 1]的区间内;相反,不信任关系的分布情况稍微复杂,不信任关系分布最多的2个位置分别在-1和+1,但是,仍然可从分布的结果中发现将近69%的不信任关系分布在意见差异值的[-1, 0]区间内.不信任关系分布复杂的原因是:在Epinions中,用户的评级数据较为倾斜(skewed),即大多数评级都分布在分值4~5之间.这说明绝大部分用户更加愿意对评论做出较为积极正向的评级,即使建立的关系是不信任关系.
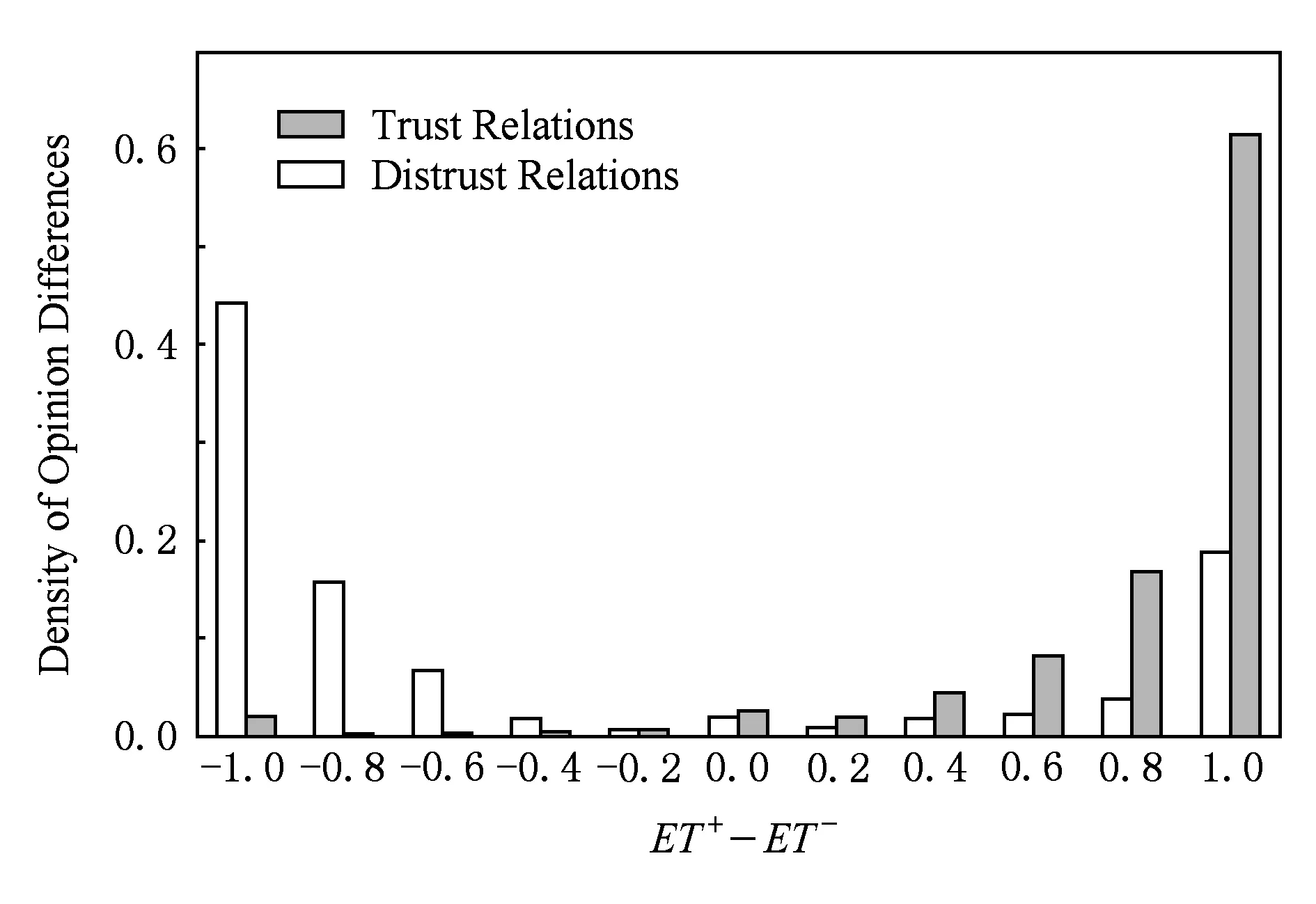
Fig. 1 Density distribution of opinion differences.图1 意见差异密度分布情况
另外,为了进一步验证交互意见的数量与建立链接关系的正负属性之间存在的关联关系,尝试回答2个问题:
1) 2个用户之间正向交互意见倾向数量越多,这2个用户之间更可能构建正向链接?
2) 2个用户之间负向交互意见倾向数量越多,这2个用户之间更可能构建负向链接?
为了回答第1个问题,首先形式化定义一些符号,如PIi j表示用户ui与用户uj的正向交互数量;Uk表示用户ui与用户uj正向交互数量不小于K的用户对〈ui,uj〉集合,Uk={〈ui,uj〉|PIi j≥K},其中K表示正向交互数量;PRk表示在Uk中正向关系对的集合,PRk={〈ui,uj〉|(PIi j≥K)∧Ti j=1}.然后,计算正向链接关系数量同正向交互数量比率PK:
(9)
正向链接关系数量同正向交互数量比率PK随着K变化的比率分布如图2(a)所示.随着正向交互数量K的增加,比率PK往往也随着增加,表明正向交互数量与正向链接关系存在较大的相关性,大部分正向链接关系是基于交互行为的意见倾向而构建,正向交互越多的用户之间更可能构建正向链接关系.这样的分布结果也正好回答了第1个问题.
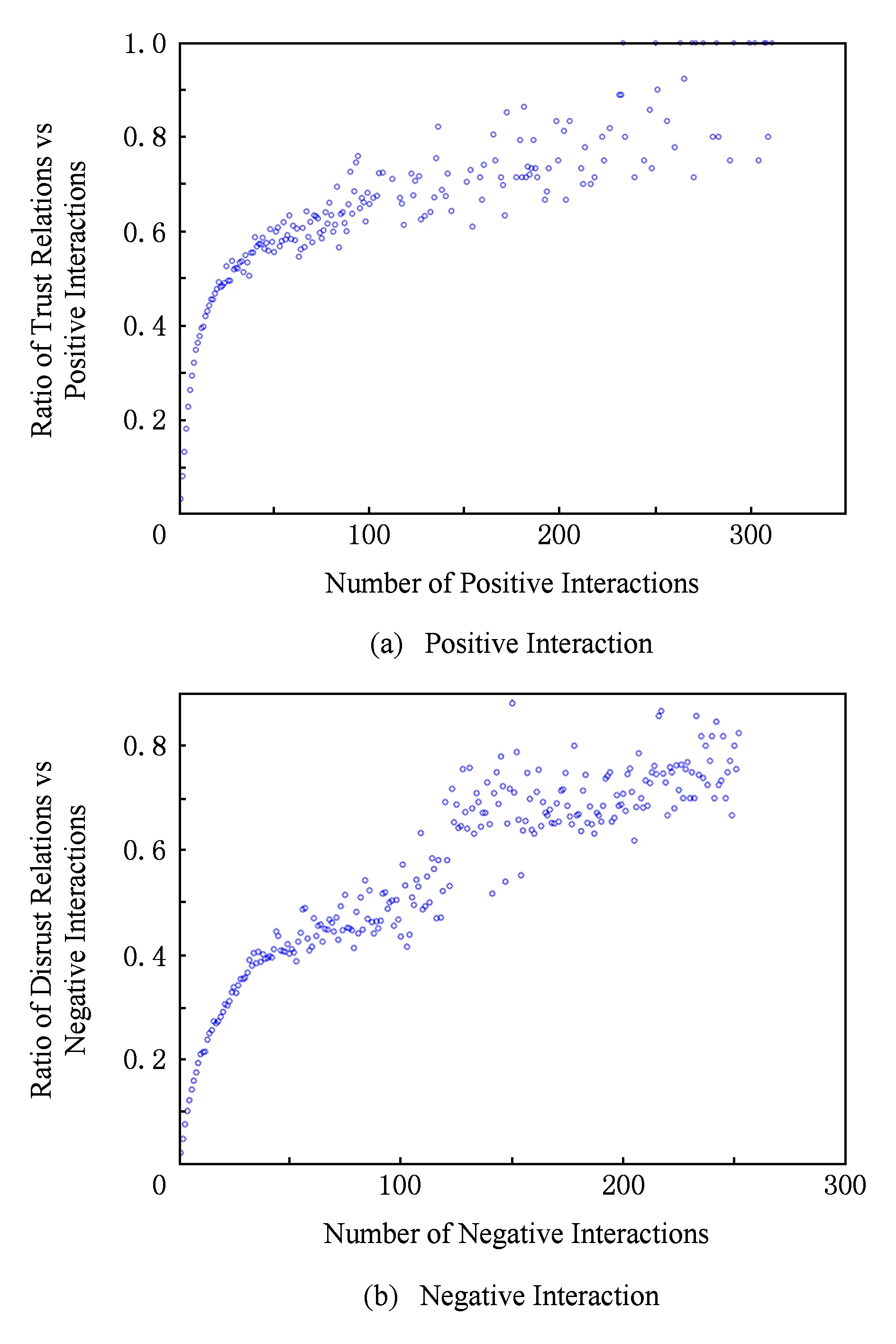
Fig. 2 Ratios of the number of links with respect to the number of interactions.图2 链接数量同交互数量比率分布情况
为了回答第2个问题,采取相反的方式定义负向链接关系数量同负向交互数量的比率NK,其计算公式为
(10)
负向链接关系数量同负向交互数量比率NK随着K变化的分布情况如图2(b)所示.随着负向交互数量K的增加,比率NK往往也随之增加,其结果表明负向交互数量与负向链接关系存在较大的相关性,相似的分布结果正好回答了第2个问题.
4.2社会地位理论
为了验证地位理论与关系符号属性之间的关联关系,利用PolarityRank策略量化符号网络节点的地位等级信息以尝试回答2个问题:
1) 在符号网路中,低地位等级用户是否更可能与高地位等级用户建立正向链接关系?
2) 在符号网络中,高地位等级用户是否更可能与低地位等级用户建立负向链接关系?
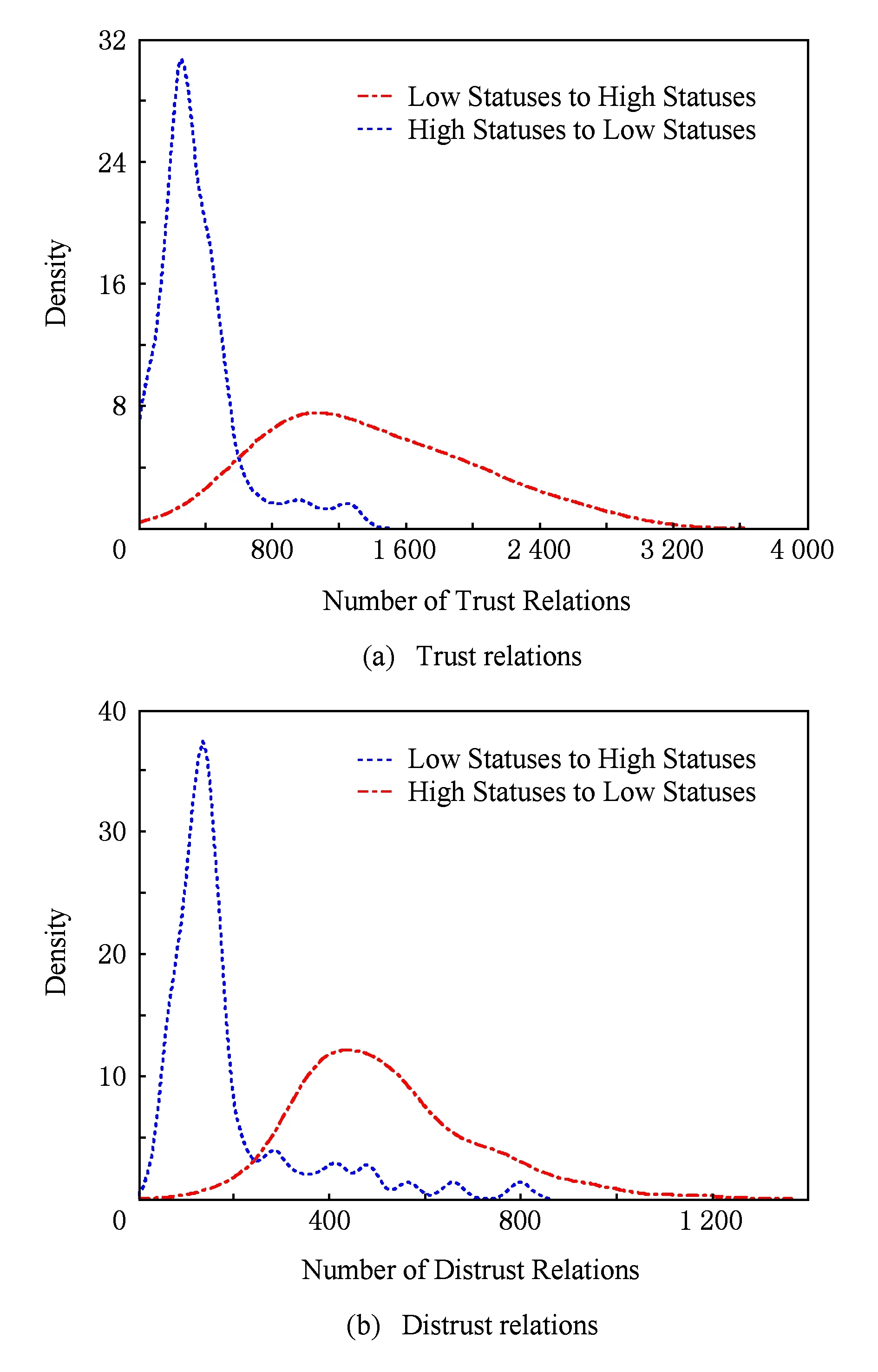
Fig. 3 Density estimate of numbers of trust and distrust relations.图3 信任和不信任关系数量的密度评估
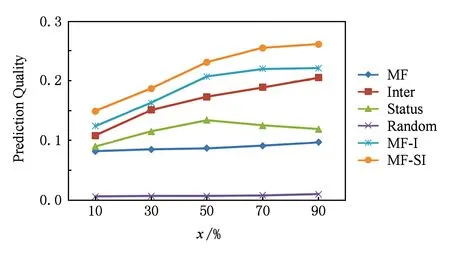
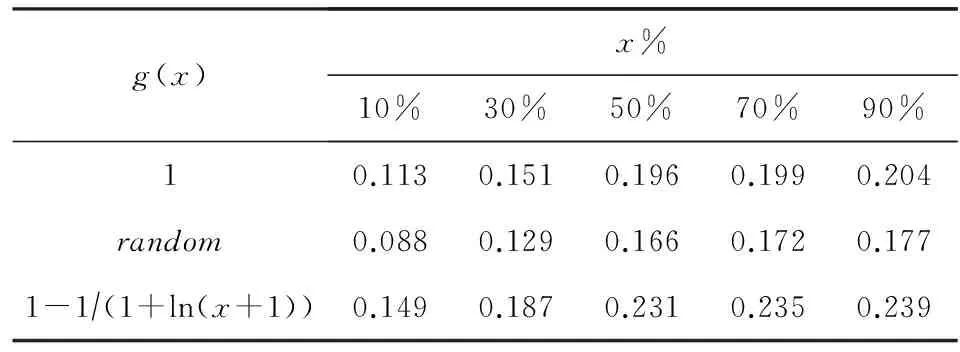
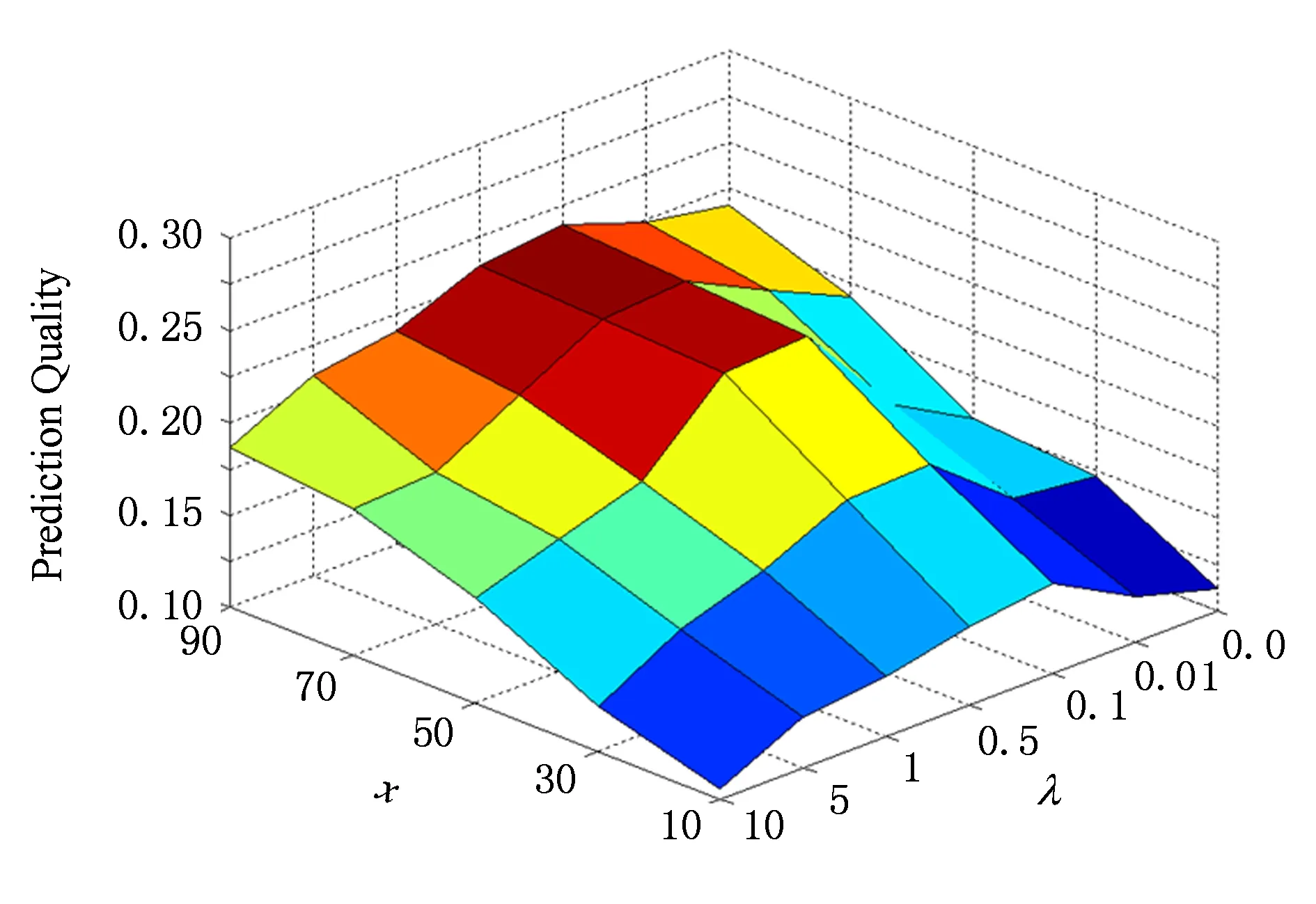
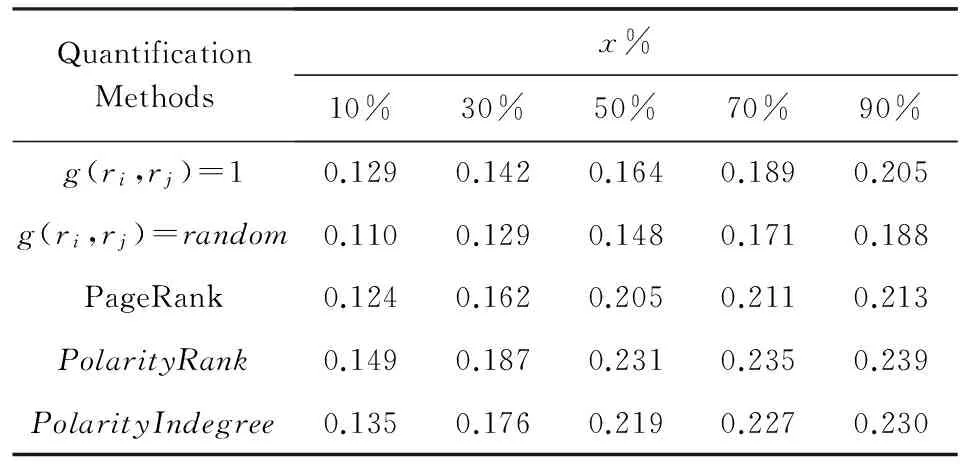
为了回答以上2个问题,首先将所有的用户依据PolarityRank值降序排列,并将用户的地位等级划分为K个等级,在验证中将设置用户等级的数量K=10.然后,针对信任关系分布统计构建2个样本,如果1≤i 从图3(a)可以看出,低地位等级信任高地位等级数量同高地位等级信任低地位等级数量相比拥有较大的密度中心,这正好回答了第1个问题:低地位等级用户更可能与高地位等级用户建立正向链接关系.同样,在图3(b)中,对于不信任关系数量,高地位等级不信任低地位等级的数量的密度中心大于低地位等级不信任高地位等级用户,这也正好回答了第2个问题:高地位等级用户更可能与低地位等级用户建立负向链接关系.这2个问题正好提供了关于社会地位理论和链接关系正负属性之间存在一定关联的证据. 5链接预测模型及优化算法 提出基于低秩矩阵分解方法[21],以交互意见和地位理论作为模型构建的动机,分别构建相应诱因的链接预测模型实现符号网络中链接关系的预测. 5.1低秩矩阵链接预测MF 符号网络G以邻接矩阵形式表示,Gi j=1表示用户ui与用户uj之间建立正向链接关系,而Gi j=-1表示用户ui与用户uj之间建立负向链接关系.由于符号网络矩阵G具有低秩结构特征[10]并且较为稀疏,因此利用矩阵分解方法寻求低秩逼近的表示方式.将符号网络矩阵G分解为低秩矩阵,并通过低秩矩阵的相乘重构符号网络矩阵G,补齐原矩阵中的缺失值,如式(11)所示: G≈UHVT, (11) G≈UHUT. (12) 由于符号网络矩阵G较为稀疏,通过添加合理的正则化项方式来避免过度拟合(over-fitting).因此,MF模型定义如下: (13) 5.2基于交互意见的链接预测模型MF-I 为了模拟交互意见用于链接预测,尝试利用交互意见倾向与链接关系符号属性之间存在的强相关性构建基于交互意见的符号网络链接预测模型MF-I.为了强调交互意见在符号网络链接预测过程中的重要性,采取不依赖于已知的符号网络拓扑结构信息,即仅利用带有意见倾向的评级行为数据构建伪符号网络矩阵X.因此,本模型假设已知的符号网络并不存在,利用交互数据构建伪符号网络矩阵X替换真实符号网络矩阵G.伪符号网络矩阵X中的元素xi j定义如下: (14) 其中,PIi j表示用户ui到用户uj的正向交互数量,NIi j表示用户ui到用户uj的负向交互数量. 伪符号网络矩阵X依据正负向的交互数量而构建,其元素值并不是真实的符号网络数据,因此该矩阵并不可靠.根据交互意见与链接关系符号属性之间的强相关性,引入权重矩阵W增强伪符号网络矩阵X的可靠度,当矩阵中Wi j权重越大,说明伪符号网络矩阵X中用户ui与用户uj构建链接的可能性越高.在矩阵分解过程中,通过矩阵元素Wi j控制对符号网络矩阵元素xi j学习过程的贡献.权重矩阵W的元素定义如下: (15) 其中,Ii j表示用户ui与用户uj产生的正向(或负向)交互数量,定义如下: (16) 在构建伪符号网络矩阵X的基础上,通过引入权重矩阵W用于增强待分解矩阵X的可靠度,进而扩展基于低秩矩阵分解的链接预测模型,因此,MF-I模型定义如下: (17) 其中,⊙表示Hadamard乘积,针对维度相同的任意2个矩阵X和Y,(X⊙Y)i j=Xi j×Yi j. 5.3基于交互意见和地位理论的链接预测模型MF-SI 当2个用户之间存在等级差异时,依据地位理论,2个用户之间应该同时建立正、负链接关系,即两者之间具有对称关系属性.但是,通过观察Epinions数据集发现,仅仅大约1.7%的关系之间符合对称关联属性.因此,当构建基于地位理论的符号网络预测模型时,不仅仅考虑2个用户之间的等级差异,还需利用交互意见的显著方向性特征克服地位理论对称性的局限,进而构建基于交互意见和地位理论的链接预测模型MF-SI.针对Leskovec等人[12,22]所提出的基于三元组的地位理论8种关系组合,用户ui和用户uj之间链接关系的符号属性及链接关系权重s(i,j)可被形式化建模如下: (18) 其中,sign(·)表示符号函数,g(ri,rj)表示2个用户之间等级差异权重.根据经验设置2个用户之间的等级差异权重g(ri,rj)为 (19) 地位理论的正则化项[23]可被定义如下: (20) 在基于低秩矩阵分解的链接预测基础上,融合交互意见和地位理论构建符号网络链接预测模型,将交互意见建模为矩阵分解方法的增强可靠度因子,而地位理论建模为矩阵分解方法的正则化项,MF-SI模型定义如下: (21) 其中,λ表示用于调谐地位理论贡献程度系数. 5.4优化算法 针对交互意见和地位理论分别构建基于交互意见的链接预测模型(MF-I)以及融合交互意见和地位理论的链接预测模型(MF-SI),其中交互意见是以增强可靠度因子形式来构建模型,而地位理论是以稀疏学习正则化项形式来构建模型.针对式(13)的低秩矩阵分解方法建模符号网络链接预测问题,采用Hsieh等人[10]所提出的方法,通过sigmoid变换函数惩罚分解时的符号不一致问题,以有效地解决算法优化问题并提高预测质量. 首先将式(21)的正则化项转化为矩阵形式,具体过程如下: 然后,将式(21)表示为第k次迭代的Lagrangian函数形式,形式如下: (22) 通过移除常量,Lk可被重写为 Lk=-2Tr((WT⊙WT⊙GT)UHUT)+ (UHTUT))UHUT)+2λTr(UTζU). (23) Lk关于U和H的偏导数定义如下: (UHUT))UHT+(WT⊙WT⊙(UHUT))UHT+ 2(WT⊙WT⊙GT)UH-2(W⊙W⊙G)UHT- (24) (25) 对于H和U的偏导数,目标函数(22)的优化解决方法可通过梯度下降法进行求解,具体如算法1所示: 算法1. MF-SI模型. 输入: 符号网络G、用户-评论关联矩阵E、用户-评论的帮助评级矩阵R; 输出: 正向链接关系对集合T′和负向链接关系对集合D′的排序列表. ① 利用矩阵E和矩阵R构建交互意见矩阵; ② 依据式(15)计算矩阵W; ④ 随机初始化U和H; ⑤ while 不收敛 do ⑨ end while 6实验 通过实验,验证3个问题: 1) 通过对比不同方法,所提模型是否有效地实现正向链接和负向链接预测? 2) 交互意见和地位理论作为可靠度因子和正则化项在所提链接预测模型中的作用如何? 3) 通过对比不同量化策略,哪些量化方法对提高模型预测质量更加有效? 6.1实验设置和评价策略 实验设置:1)将所有的链接关系对表示为集合A,并按照链接的创建时间降序排列所有链接关系对,从A中选取时间T前的x%的链接关系对作为已知部分的符号网络信息;2)对于每个x,收集正向链接、负向链接、用户-评论关系信息和用户-评论帮助(helpfulness)评级信息等相关内容作为已知的网络拓扑结构数据和用户交互行为数据;3)在实验数据集A中的x分别取值10,30,50,70,100形成已知数据集Dx,其余1-x%作为待评估数据集. 采用通用评价标准[24]以衡量所提模型的预测效果.对于每个待评估数据集,正向链接关系对集合和负向链接关系对集合分别用T和D表示,并作为评价标准.然而,通过所提模型的预测结果依据模型所得置信度将所有用户形成的链接关系对按照降序排列,选取前|T|链接关系对作为预测的正向链接集合T′,后|D|链接关系对作为预测的负向链接集合D′.最终,模型的预测质量(prediction quality,PQ)被形式化表示为 (26) 6.2链接预测模型对比效果 为了回答第6节开始部分的第1个问题,对4个基本(baseline)方法进行比较: 1) MF方法.该方法是将正负链接关系以矩阵形式表示,并使用矩阵分解方法获得预测值.将越高的预测值看作是正向链接,相反,越低的预测值看作是负向链接. 2) Inter方法.该方法是基于交互意见与符号网络链接属性的强相关性而定义,依据正向和负向交互数量的排列链接关系对.正向交互数量越多,建立正向链接关系的可能性就越大;负向交互数量越多,建立负向链接关系的可能性就越大. 3) Status方法.该方法是基于地位理论与符号网络链接属性的强相关性而定义,依据链接关系2个用户的等级差异值排列链接关系对.正向等级差异越大,建立正向链接关系的可能性就越大;负向等级差异越大,建立负向链接关系的可能性就越大. 4) Random方法.该方法是依据数据集中正向和负向链接比例随机选取链接关系对.一般来说,在符号属性预测中,随机方法的结果就能达到约50%的准确率.因此,该方法在文献[24]中被建议作为基本方法,同随机方法相比,更能体现预测模型提高的效果和意义. 在本组实验中,由于MF-I模型与MF-SI模型所使用的待分解矩阵不同,因此依据交互的数量降序排列并选取同其他模型具有相同链接关系数量的交互数据构建伪符号网络矩阵.通过交叉验证方法调谐MF-I和MF-SI模型参数.为了达到一般性实验目的,将所有模型分解后矩阵H和U的正则化项参数设置为α=β=0.1.MF-SI模型中,设置参数l=0.1.实验对比结果如图4所示. Fig. 4 Performance comparison of different link prediction methods.图4 不同链接预测方法对比结果 通过实验结果可以看出: 1) MF-I模型和MF-SI模型在预测质量方面一致优于其他基本方法,特别是远远高于MF方法和随机方法,说明所提出模型涉及的2个链接构建诱因对提高模型预测准确度发挥一定贡献.另外,同MF-I模型相比,MF-SI模型具有最好的实验效果,预测质量平均高于MF-I模型0.025.说明集成交互意见与地位理论的模型要优于其他模型. 2) 从MF-I模型和MF模型的对比结果可以发现,将交互意见建模为增强可靠度因子能够提高矩阵分解方法的预测质量.另外,基于交互意见与链接符号属性强关联关系的Inter方法也具有较好的预测效果,优于Status方法和MF方法,充分说明交互意见在预测链接关系方面的重要作用. 3) MF-I模型和Status方法,随着x%的增加,特别是当达到50%以上时,实验效果不会显著提高,甚至Status方法会出现下降,其主要原因是随着已知链接关系数量的增加,等级差异不大的用户之间建立链接的准确率会有较为明显的下降. 对所有的实验结果执行T-test检验,其结果说明所提高的实验效果是显著的.总而言之,借助地位理论的正则化项所提出的MF-SI模型,同一些基本方法相比,特别是随机方法,实验结果都有显著提高;MF-I模型证明了交互意见在预测符号网络方面具有重要作用;同样,集成了交互意见和地位理论的MF-SI模型具有更好的效果,并且能够实现准确地预测符号网络链接关系符号属性.这也正好回答了第6节开始部分所提出的第1个问题. 6.3模型的参数分析 MF-SI模型有2个重要参数控制其实验效果,分别是:1)W用于控制交互数据对待分解矩阵的可靠度;2)λ用于控制融入结构平衡理论或社会地位理论对模型的贡献程度.在本组实验中,尝试固定一个参数取值同时调谐另一个参数方式,观测MF-SI模型的效果. Table 2 Different Measurements of Reliability Matrix W 从表2可以看出: 1) 同g(x)=1-1(1+ln(x+1))效果相比,g(x)=random效果降低较为明显.表明函数g(x)不能设置为随机数,同时也证明了基于交互数量定义的函数g(x)在模型中作用较为明显,能够提高模型的质量. 2) 通过设置g(x)=1后,相当于MF-SI模型去掉了交互意见的影响,同g(x)=1-1(1+ln(x+1))效果相比,g(x)=1的实验效果分别降低了0.03~0.04. 实验结果进一步证明集成交互意见的重要性,其能够有助于解决社会地位理论自身的局限性,进而提高预测质量.另外,以合理的方式融合多个社会学理论到稀疏学习模型中是能够提高预测质量的,这回答了第6节开始部分的第2个问题. 通过调谐参数λ控制地位理论正则化项的贡献程度,λ分别取{0,0.01,0.1,0.5,1,5,10}.实验结果如图5所示. Fig. 5 Performance comparison for different parameter λ.图5 不同参数λ取值实验效果对比结果 通过参数λ不同取值的比较,可以看出: 1) 对于MF-SI模型,当参数λ=0.1时,MF-SI模型达到了峰值. 2) 参数λ=0,相当于MF-SI模型去掉了地位理论正则化项部分. 随着参数λ从0开始增加,实验效果也随之得到了显著的提高.这样的结果说明地位理论的正则化项能够提高模型的预测质量. 6.4MF-SI等级量化策略对链接预测的影响 权重矩阵W的不同量化策略已经在实验6.3节中进行有效验证.在本组实验中,重点衡量MF-SI模型中社会等级系数,其用于控制2个用户之间等级差异大小.采用3种社会等级策略量化用户的社会等级,分别是PageRank,PolarityRank和Polarity-Indegree.依据量化后的权重排序所有节点,再利用式(19)计算2个节点的权重值g(ri,rj).除了以上3种策略之外,与6.3节实验相似,设置g(ri,rj)=1和g(ri,rj)=random.其中,i,j=1,2,…,n;random∈[0,1].表3表示采用不同社会等级量化策略的实验对比结果. Table 3 Different Measurements of Social Statuses 从表3可以得出以下结论: 1)PolarityRank量化策略明显优于其他2种量化策略PageRank和PolarityIndegree,同时,PolarityIndegree量化策略优于PageRank方法,说明当量化符号网络中节点的等级时,传统PageRank方法没有考虑负向入度链接的作用,从而影响了节点最终的等级权重. 2) 同PolarityRank,PolarityIndegree和PageRank量化策略相比,g(ri,rj)=1和g(ri,rj)=random获得较差的效果,说明社会等级不能是随机数. 综合以上2点,该实验结果有效地回答了第6节开始部分的第3个问题. 7结束语 符号网络链接预测问题近几年吸引了越来越多的研究人员的关注,同在已知链接关系基础上预测符号属性问题不同,链接预测既要预测未知链接关系还要预测链接的符号属性.因此,符号网络中链接预测问题较为困难,并且预测质量也不理想.本文通过探索交互意见和地位理论实现符号网络链接关系预测,从而形成新颖模型MF-I和MF-SI.实验结果表明所提模型同其他基本方法相比具有较好的预测质量. 在今后的工作中,我们会继续探索社会学理论以及其他相关理论,以更好地解析符号网络数据;同时,进一步探索符号网络中相关应用研究,比如节点排序、社区发现、信息传播及推荐等. 致谢在此,衷心感谢亚利桑那州立大学DMML实验室刘欢(Huan Liu)教授、感谢DMML实验室的所有同行、感谢Yahoo实验室的汤继良(Jiliang Tang)博士! 参考文献 [1]Cheng Suqi, Shen Huawei, Zhang Guoqing, et al. Survey of signed network research[J]. Journal of Software, 2014, 25(1): 1-15 (in Chinese)(程苏琦, 沈华伟, 张国清, 等. 符号网络研究综述[J]. 软件学报, 2014, 25(1): 1-15) [2]Heider F. Attitudes and cognitive organization[J]. Journal of Psychology, 1946, 21(1): 107-112 [3]Cartwright D, Harary F. Structural balance: A generalization of Heider’s theory[J]. Psychological Review, 1956, 63(5): 277-293 [4]Borzymek P, Sydow M. Trust and Distrust Prediction in Social Network with Combined Graphical and Review-Based Attributes[G] //Agent and Multi-Agent Systems: Technologies and Applications. Berlin: Springer, 2010: 122-131 [5]Ye J, Cheng H, Zhu Z, et al. Predicting positive and negative links in signed social networks by transfer learning[C] //Proc of the 22nd Int Conf on World Wide Web. New York: ACM, 2013: 1477-1488 [6]Zolfaghar K, Aghaie A. Mining trust and distrust relationships in social Web applications[C] //Proc of the 6th Int Conf on Intelligent Computer Communication and Processing. Piscataway, NJ: IEEE, 2010: 73-80 [7]Javari A, Mahdi J. Cluster-based collaborative filtering for sign prediction in social networks with positive and negative links[J]. ACM Trans on Intelligent Systems and Technology, 2014, 5(2): 1-24 [8]Symeonidis P, Eleftherios T. Transitive node similarity: Predicting and recommending links in signed social networks[J]. World Wide Web, 2014, 17(4): 743-776 [9]Lv L Y, Zhou T. Link prediction in complex networks: A survey[J]. Physica A: Statistical Mechanics and Its Applications, 2011, 390(6): 1150-1170 [10]Hsieh C J, Chiang K Y, Inderjit S. Low rank modeling of signed networks[C] //Proc of the 18th ACM SIGKDD Int Conf on Knowledge Discovery and Data Mining. New York: ACM, 2012: 507-515 [11]Yi C, Gu R T, Ji Y F. Sign inference for dynamic signed networks via dictionary learning[J]. Journal of Applied Mathematics, 2013, 2013(3): 701-710 [12]Leskovec J, Huttenlocher D, Kleinberg J. Predicting positive and negative links in online social networks[C] //Proc of the 19th Int Conf on World Wide Web. New York: ACM, 2010: 641-650 [13]Zheng X, Zeng D, Wang F. Social balance in signed networks[J]. Information Systems Frontiers, 2015, 17(5): 1077-1095 [14]Chiang K Y, Natarajan N, Tewari A, et al. Exploiting longer cycles for link prediction in signed networks[C] //Proc of the 20th ACM Int Conf on Information and Knowledge Management. New York: ACM, 2011: 1157-1162 [15]Patidar A, Agarwal V, Bharadwaj K K. Predicting friends and foes in signed networks using inductive inference and social balance theory[C] //Proc of the 2012 Int Conf on Advances in Social Networks Analysis and Mining. Piscataway, NJ: IEEE, 2012: 384-388 [16]Priyanka A, Garg V K, Narayanam R. Link label prediction in signed social networks[C] //Proc of the 23rd Int Joint Conf on Artificial Intelligence. Menlo Park, CA: AAAI, 2013: 2591-2597 [17]Ramanthan G, Kumar R, Raghavan P, et al. Propagation of trust and distrust[C] //Proc of the 13th Int Conf on World Wide Web. New York: ACM, 2004: 403-412 [18]Lan Mengwei, Li Cuiping, Wang Shaoqing, et al. Survey of sign prediction algorithms in signed social networks[J]. Journal of Computer Research and Development, 2015, 52(2): 410-422 (in Chinese)(蓝梦微, 李翠平, 王绍卿, 等. 符号社会网络中正负关系预测算法研究综述[J]. 计算机研究与发展, 2015, 52(2): 410-422) [19]Wang Y, Wang X, Zuo W L. Research on trust prediction from a sociological perspective[J]. Journal of Computer Science and Technology, 2015, 30(4): 843-858 [20]Wang Ying, Wang Xin, Zuo Wanli. Trust prediction modeling based on social theories[J]. Journal of Software, 2014, 25(12):2893-2904 (in Chinese)(王英, 王鑫, 左万利. 基于社会学理论的信任关系预测模型研究[J]. 软件学报, 2014, 25(12): 2893-2904) [21]Liu Ye, Zhu Weiheng, Pan Yan, et al. Multiple sources fusion for link prediction via low-rank and sparse matrix decomposition[J]. Journal of Computer Research and Development, 2015, 52(2): 423-436 (in Chinese)(刘冶, 朱蔚恒, 潘炎, 等. 基于低秩和稀疏矩阵分解的多源融合链接预测算法[J]. 计算机研究与发展, 2015, 52(2): 423-436) [22]Leskovec J, Huttenlocher D, Kleinberg J. Signed networks in social media[C] //Proc of the SIGCHI Conf on Human Factors in Computing Systems. New York: ACM, 2010: 1361-1370 [23]Wang Y, Wang X, Tang J, et al. Modeling status theory in trust prediction[C] //Proc of the 29th AAAI Conf on Artificial Intelligence. Menlo Park, CA: AAAI, 2015: 1875-1881 [24]Nowell D L, Kleinberg J. The link prediction problem for social networks[J]. Journal of the American Society for Information Science and Technology, 2007, 58(7): 1019-1031 Wang Xin,born in 1981. PhD, lecturer. Member of China Computer Federation. His main research interests include data mining, machine learning, social network and recommendation system. Wang Ying, born in 1981. PhD, associate professor. Senior member of China Computer Federation. Her main research interests include data mining, machine learning, social computing and search engine. Zuo Wanli, born in 1957. Professor and PhD supervisor in the College of Computer Science and Technology, Jilin University. Senior member of China Computer Federation. His main research interests include information retrieval, Web mining and machine learning. Exploring Interactional Opinions and Status Theory for Predicting Links in Signed Network Wang Xin1,3,4, Wang Ying2,3, and Zuo Wanli2,3 1(SchoolofComputerTechnologyandEngineering,ChangchunInstituteofTechnology,Changchun130012)2(CollegeofComputerScienceandTechnology,JilinUniversity,Changchun130012)3(KeyLaboratoryofSymbolicComputationandKnowledgeEngineering(JilinUniversity),MinistryofEducation,Changchun130012)4(GuangxiKeyLaboratoryofTrustedSoftware(GuilinUniversityofElectronicTechnology),Guilin,Guangxi541004) AbstractWith the wide spread and pervasion of social network, it brings more opportunities and novel problems for deep research on signed network, where link prediction is one of key problems in signed network. Interactional opinions and status theory are contributed to explain the construction and sign property of link relations, and provide theoretical principles for improving prediction quality. Therefore, this paper investigates link prediction problem in signed network from the perspective of interactional opinions and status theory, and constructs link prediction model by studying the strong correlation between two inducements and link relationship. Firstly, it explores interactional opinions to enhance the reliability of the decomposed matrix, and makes up for the limitations of status theory. Then, it models interactional opinions as enhanced reliability factor of matrix, and models status theory as the regularization terms. Finally, we construct the model of link prediction in signed network, namely MF-SI. Experimental results demonstrate that the model of MF-SI owns the best prediction quality compared with other baseline methods, which shows that the method of integrating interactional opinions with status theory implements link prediction in signed network. Key wordssigned network; link prediction; sparse learning; interactional opinions; status theory 收稿日期:2015-12-12;修回日期:2016-02-03 基金项目:国家自然科学基金项目(61300148);吉林省科技计划青年科研基金项目(20130522112JH);广西可信软件重点实验室研究课题资助(kx201533) 通信作者:王英(wangying2010@jlu.edu.cn) 中图法分类号TP181 DOI:计算机研究与发展10.7544issn1000-1239.2016.20151172 Journal of Computer Research and Development53(4): 776-784, 2016 This work was supported by the National Natural Science Foundation of China (61300148), the Science and Technology Development Program of Jilin Province of China (20130522112JH), and Guangxi Key Laboratory of Trusted Software (kx201533).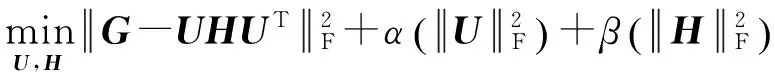
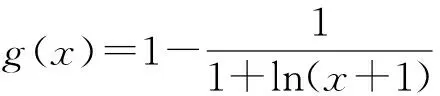
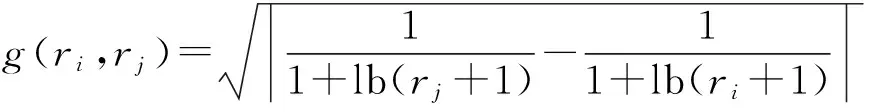

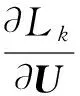
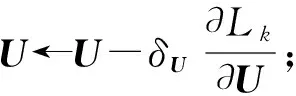
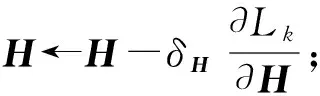








猜你喜欢
幼儿园(2021年6期)2021-07-28
小学生学习指导(低年级)(2019年11期)2019-11-25
学苑创造·A版(2019年9期)2019-11-07
意林·全彩Color(2019年7期)2019-08-13
学苑创造·A版(2019年2期)2019-02-19
小学生导刊(2017年13期)2017-06-15
中央民族大学学报(自然科学版)(2016年3期)2016-06-27
南都周刊(2015年4期)2015-09-10
南都周刊(2015年3期)2015-09-10
南都周刊(2015年1期)2015-09-10
