
基于行为特征学习的互联网流量分类方法
2016-06-28 13:19刘珍王若愚
电信科学 2016年6期
刘珍,王若愚
(1.广东药科大学医药信息工程学院, 广东 广州 510006;2.华南理工大学信息网络工程研究中心, 广东 广州 510006)
基于行为特征学习的互联网流量分类方法
刘珍1,王若愚2
(1.广东药科大学医药信息工程学院, 广东 广州 510006;2.华南理工大学信息网络工程研究中心, 广东 广州 510006)
基于连接图的互联网流量分类方法能反映主机间的通信行为,具有较高的分类稳定性,但是经验式总结的启发式规则有限,难以获得高分类准确率。 研究分析了主机间通信行为模式和 BOF 方法,从具有相同{目的 IP 地 址,目的 端 口号,传 输 层 协议}网 络 流量 中 ,提 取 主 机 间 连 接 相 关的 行 为统 计 特 征(HCBF),采 用 C4.5决策树算法学习基于行为特征的分类规则,其无需人工建立启发式规则。 在传统互联网和移动互联网流量数据集上,从基本分类性能和分类稳定性方面,与现有的特征集进行比较分析,实验结果表明,HCBF 特征集合的类间区分能力和稳定性较高。
互联网流量分类;行为特征;机器学习;通信行为;网络测量
1 引言
互联网流量分类是异常检测、网络计费、流量整形、网络 规 划 、QoS 部 署 和 网 络 协 议 研 究 等 的 重 要 基 础[1,2]。随 着动态端口号、端口伪装和载荷加密技术的使用,传统的端口号映射和载荷特征检测方法逐渐失效。至今,学术界提出了多种互联网流量分类方法,特别是基于机器学习和通信 行 为 的 流 量 分 类 方 法 成 为 研 究 热 点[3,4]。
基 于 连 接 图 (connectivity graph)的 流 量 分 类 方 法 通 过分析和描述网络应用的 IP 报文在主机间的传输行为模式 ,进 而 识 别未 知 IP 报 文 的 应 用 类 别 。参 考 文 献[5]基 于主 机 传 输 层 的 行 为 特 点 提 出 BLINC(blind classification)方法,从社会级别、功能级别和应用级别分析各类主机的行为,并建立通信行为模式,进而建立启发式规则用于流量分类。近期也发展出基于连接图的流量分类方法,此类方法 利 用 主 机[6]、节 点[7]或 网 络 流[8]建 立 连 接 图 , 基 于 连 接 图 的性质(例如顶点的出度数、入度数等)提取通信行为测度,进而基于这些测度建立分类规则。此类方法能描述网络应用在主机间的连接状况,体现通信行为,不易受网络环境的影响,较为稳定。但是难以提取完整的启发式规则进行流量分类,其分类精度和分类粒度有限。
基于机器学习的网络流量分类方法引入了机器学习算法,对网络 IP 报文根据五元组进行组流,在网络流的基础上进行统计特征提取(例如流持续时间、平均报文大小、报文数等),统计特征值描述网络流建立样本集合,作为分类算法的输入。在基于机器学习的网络流量分类方法领域 ,多 种 统 计 特 征 已 被 提 出[9,10],最 有 代 表 的 是 Moore 等 人提 出 的 248 个 统 计 特 征[9],包 括 了 报 文 大 小 、报 文 到 达 时 间间 隔 等 的 统 计 特 征 ,其 得 到 了 广 泛 的 应 用[11-13]。此 类 方 法 与基于通信行为的流量分类方法相比,其分类粒度和分类精度方面更优,但是,这些特征不能反映主机间的通信行为,随着网络应用逃避检测策略的发展,它们的类间区分能力可能被模糊化技术弱化,例如,参考文献[14]总结得 出模糊化报文大小的一种方式是随机清除发送缓冲区,这样可能削弱某种网络应用的报文大小的规律。
为提高基于机器学习流量分类方法的分类稳定性,参考文献[7]分析观察某类流量数据的通信特点,在多 流数据集上根据节点信息提取行为统计特征,但是此特征集合包含 的 信 息 有 限 。已 有 的 通 信 行 为 模 式[5]能 包 含 多 种 网 络 应用类别的通信行为,信息量更丰富,但以连接图的形式存在,缺乏研究文献在此基础上提取出行为统计特征。
针对上述问题,本文的主要贡献包括以下两方面。
(1)为结合基于连接图和基于机器学习的网络流量分类方法的优点,本文分析基于连接图的流量分类方法,根据 其 中 的 通 信 行 为 模 式 和 启 发 式 规 则 ,并 结 合 BOF(bag of flow)方 法 的 思 想 ,在 具 有 相 同{目 的 IP 地 址 ,目 的 端 口 号 ,传输层协议}的网络流上提取行为统计特征集合,用于描述网络流,建立的特征向量作为机器学习算法的输入,用于分类器训练。
(2)在传统有线网的流量数据集和移动智能终端手机的流量数据集上,利用 C4.5 决策树分类算法,从基本分类性能、分类时间稳定性等多个方面,实验分析行为统计特征的性能,并总结得出:仅基于行为统计特征训练的分类器的分类性能欠佳,综合描述连接行为和通信过程的行为统 计 特 征 (host communication behavior feature,HCBF)能 进一步提高流量分类性能;在移动互联网流量数据集上,基于节点间连接的行为特征不利于分类基于 HTTP 的多种移动服务,例如 Web 浏览、视频流等。
2 行为统计特征
本节主要介绍行为统计特征提取过程,并简要介绍现有的基于节点通信的行为特征集合,此特征集合将在实验部分与本文的特征集合进行比较分析。
2.1 通信行为模式
[5]通 过 观 察和 分 析 在 传 输 层 的 主机 间 通 信行为,提取其中的通信行为模式,并进一步提出启发式规则,实现网络流到网络应用之间的映射。此方法从 3个级别 分 析主 机 的 通 信行 为 :社 会 级 别 、功 能 级 别 和 应 用 级 别[5]。社会级别主要反映某个主机与其他主机通信的热门度(popularity)和 主 机 间 连 接 的 集 群 性 (community);利 用 目 的IP 地址 的数量或 IP 地址范围进行度量。功能级别主要反映主机在通信中扮演的角色(服务器、客户端或者两者皆有);利用源 IP 地址和源端口进行度量,例如客户端使用多个端口与多台主机连接,而服务器端则通常使用一两个端口与其他主机通信。应用级别主要反映主机间在通信过程中表现出来的传输层连接模式;利用源 IP 地址、源端口、目的 IP 地址、目的端口进行度量。主流应用的通信行为模式如图1所示。
基于连接模式,多种启发式规则被建立用于分类未知网 络 流 ,相 关 的 特 征 信 息 如 下[5]。
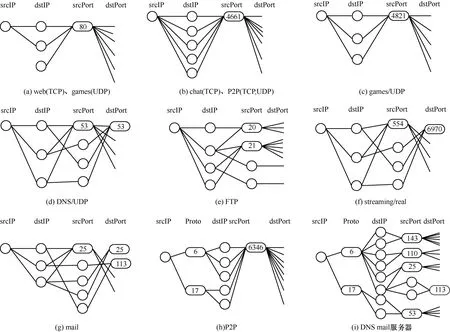
图1 主 机 间 通 信 行 为 模 式 示 意[5]
(1)传输层协议
基于 TCP 的网络应用包括 P2P、Web、chat、FTP 和 mail等,基于 UDP 的网络应用包括网络管理流量和游戏等,基于 TCP 和 UDP 的 网 络 应 用 包 括 P2P、streaming 等 。
(2)集合的基数
目的 集合(目的端 口和目的 IP 地址)的相对基数能够 区 分 不 同 的 应 用 行 为 ,例 如 区 分 Web 与 P2P 和 chat,或网络管理与游戏。此方法主要比较目的 IP 地址数和目的端口数,例如 Web 服务器端的目的端口数多于目的 IP 地 址 数 ,而 P2P 的 目 的 端 口 数 大 约 等 于 目 的 IP 地址数。
(3)使用每流的平均报文大小
许多应用表现出不同的传输报文大小的模式。例如:游戏、恶意软件和反垃圾邮件在通信过程中的报文大小几乎保持恒定。
(4)社 团 (community)
同一个社团的 IP 主机通常表现出一样的行为。
(5)递归探测方式
主机提供的某些服务可以通过递归探测其交互得到,例如反垃圾邮件服务器的识别可以通过递归式探测其与电子邮件服务器的交换,因为通常情况下,反垃圾邮件服务器只与电子邮件服务器通信。
(6)基于无载荷流识别
无载荷的流量或者失败的流量可能来自于攻击行为或者 P2P 网络(客户端试图建立 P2P 连接,连接可能失败)。
但是,这些启发式规则难以覆盖完所有的通信情况,而且适用范围有限,互联网流量在不断变化,而且目前移动互联网流行,这些规则不一定适用于现有的网络流量数据。
2.2HCBF
图1的通信模式表明服务端通常拥有大量的客户端与之通信。如图 2 所示,腾讯和阿里巴巴表现为热点服务,在 某 高 校 的 移 动 终 端 网 络 的 5 min 内 有 大 量 的 主 机 与 这些服务器通信。
腾讯服务与客户端通信的二部图如图 3所示,主要使用 80、443 和 8000 端口,此行为模式与图 1(a)的 Web 服务类似。但是,客户端的端口数与 IP 地址数并没有出现明显的差距。因此,仅依赖连接模式进行流量分类,难以取得高分类性能。
为了建立适合于传统互联网和移动互联网环境的流量分类方法,本文提出行为统计特征。此类特征属于多流统计特征,即在多条流上提取统计特征,进而描述网络流,建立特征向量,将其作为分类算法的输入,利用机器学习算法学习分类规则,而非人工总结分类规则。

图2 校园网与外网的通信连接

图3 腾讯服务的二部图
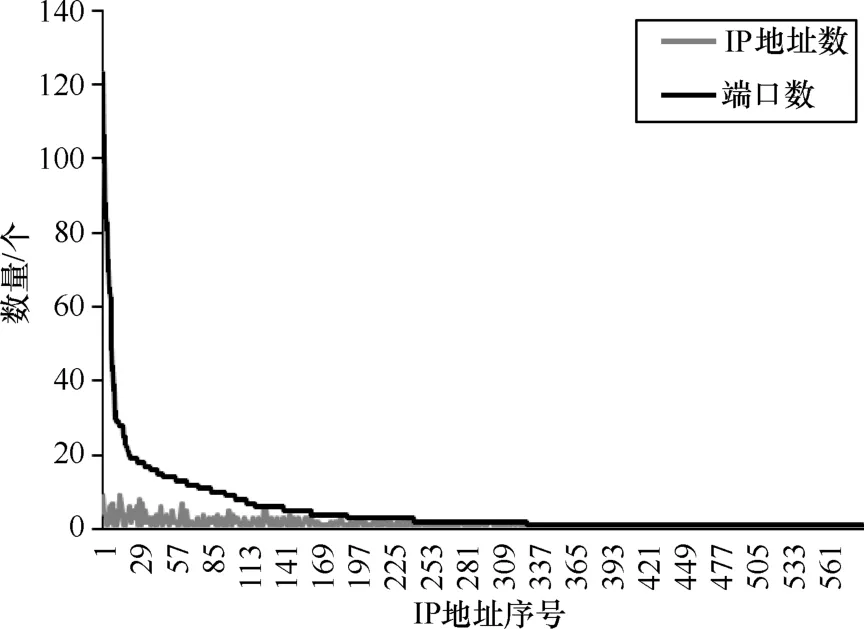
图4 HTTP 应用的源 IP 地址数和源端口数
参 考 文 献 [17]提 出 BOF 的 思 想 ,指 出 在 一 定 时 间 间隔 内 ,相 同 目 的 IP 地 址 (dstIP)、目 的 端 口 号 (dstPort)和 传输 层 协 议(Proto)的 网 络 流 属 于 同 一 种 应 用 。本 文 的 多 流特 征 基 于 相 同 的 {dstIP,dstPort,Proto}的 网 络 流 量 提 出 ,包括通信行为特征和通信过程特征。在提取特征之前,先 分 析 主 流 应 用 的 通 信 情 况 ,即 与 同 一 个{dstIP,dstPort,Proto}连 接 的 来源 主 机 信 息 。以 HTTP 和 BT 为 例 ,分 别 代表 Web 和 P2P 类的应用。在某数据集上,HTTP 和 BT 应用的源 IP 地址数目和源端口数分别如图 4 和图 5 所示。横 轴 是 源 IP 地 址 的 序 号 ,纵 轴 是 源 IP 地 址 个 数 或 源 端口数。从图 4 和图 5 表明,HTTP 应用的端口数明显少于源 IP 地址数 ,表明 客户端使用多个端口号与 Web 服 务建立连接。BT 应用流量中,部分主机的源端口比源 IP 地址多,而大部分主机的源端口和 IP 地址数一样,并且等于 1,即只与某个主机进行通信。
针 对 与 相 同{dstIP,dstPort,Proto}通 信 流 量 的 平 均 报 文大小,HTTP 和 BT 的情况分别如图 6 和图 7 所示。明显看出,BT 应用的报文大小的波动范围小于 HTTP 应用。
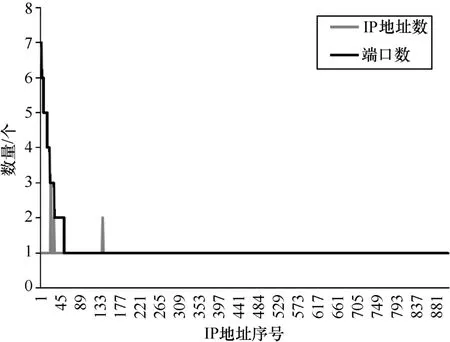
图5 BT 应用的源 IP 地址数和源端口数
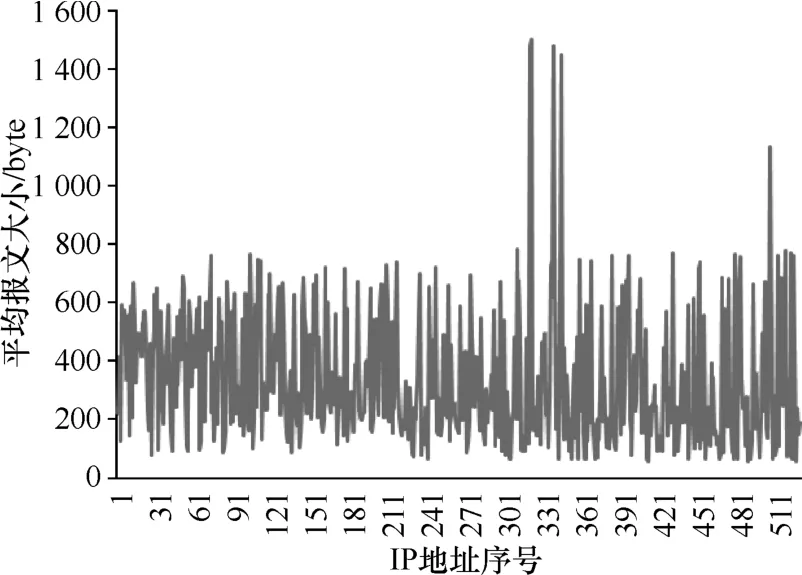
图6 HTTP 应用的平均报文大小
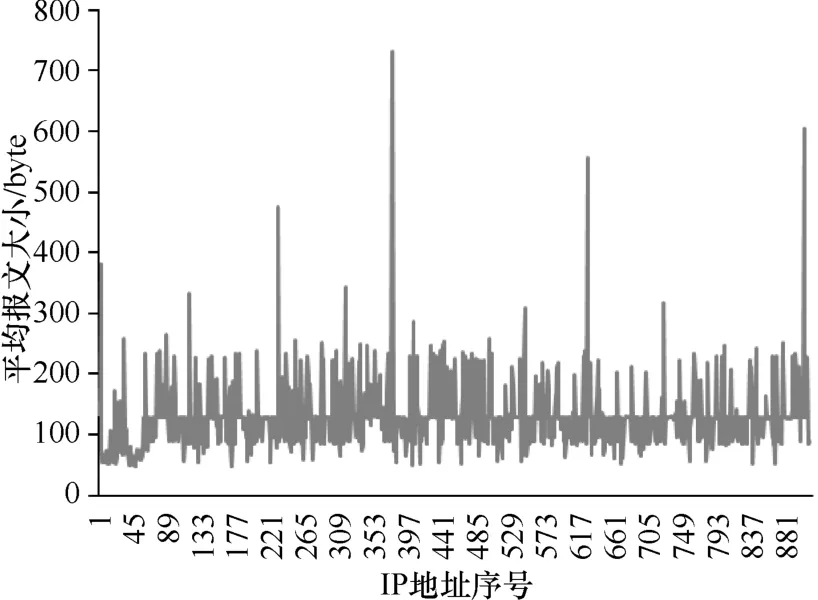
图7 BT应用的平均报文大小
基于上述分析,本文根据连接特征和传输过程的特征,建立通信行为统计特征集合,统称为 HCBF 集合,这些特征是在具有相同目的 IP 地址、目的端口号和传输层协议的网络流量上计算得到,具体见表 1。

表1 HCBF 特征集合
HCBF 特征解释如下。
(1)源端口数与源 IP 地址数的比值
从图 1 描述的各种网络应用的通信模式可看出,Web 服务器利用 80 端口与多个目的 IP 地址的多个端口进行通信,chat服务则利用 4661 端口与多个目的 IP 地址进行通信。总体上,服务器利用少量的端口号与多个客户端通信,这意味着客户端利用多个端口号与服务端通信。图4和图5也表明在真实数据集上有这样的情况,因此,利用某主机的源端口数与 IP 地址数的比值,可以区分传统服务或 P2P 应用。
(2)目的端口号
图1表明,某些服务仍然使用固定的端口号进行通信,例如 DNS 采用 53,mail使用 25 和 113 端口,端口号仍然具有一定的识别能力。
(3)报文数和字节数相关特征
多种应用表现出不同的传输报文大小的模式。例如:游戏、恶意软件和反垃圾邮件在通信过程中的报文大小(字节数)几乎保持恒定。图 6 和图 7 也表明 BT 的平均报文大小的波动范围小于 HTTP 应用。
(4)传输层协议
图1 (a)也 表 明 Web 和 games 的 区 别 是 games 使 用UDP,另外 mail、FTP 等 服务采用 TCP,P2P 可 能 使 用 TCP和 UDP,DNS 使用 UDP 等,传输层协议可区分这些应用。
(5)平均流持续时间
流持续时间反映一次通信连接的持续时间,P2P 网络存在节点的进入和退出的动态变化,大部分节点之间通信的持续时间较小,chat应用进行会话,持续时间比较长,网络流的平均持续时间特征的值较大。
(6)失败流数目
无载荷的流量或者失败的流量可能来自 P2P 网络(例如客户端试图建立 P2P 连接,连接可能失败)。
2.2 C4.5 决策树
在行为统计特征上, 本文采用 C4.5 决策树分类算法学习行为统计特征的分类规则,用于流量分类。另外,参考文 献[18]表 明 ,C4.5 决 策树在互 联 网流量数 据 集上具有 分类 精 度 和 分 类 效 率 方 面 的 优 点 。C4.5 决 策 树[19]是 通 过 迭 代式自顶向下选择测试属性作为树节点,测试属性选择是基于信息增益率。叶子节点被标记为类别,测试节点包括一个或多个输出,每个输出对应一棵子树。假设一个有 m 个类 别 的 数 据 集 S,由 特 征 向 量 A={A1,A2,…,An}描 述 ,假 设 特征 Ai(i=1,2,… ,n)有 υ个 离 散 的 取 值 。由 Ai划 分 的 信 息 增 益率为:
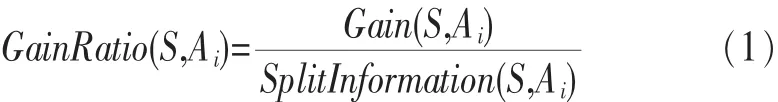
其中:

sj' 表 示 类 别 Cj的 流 量 集 合 ,sji表 示 Cj的 流 量 中 Ai取第 i 个 值 的 流 样 本 ,sji(j=1,… ,m)的 集 合 组 成 s.i。si表 示 特 征 Ai取第 i个值的流量集合。当 C4.5 决策树分类未知流样本时,从根节点开始,从上往下比较测试属性的取值,直到到达叶子节点。
3 实验与结果分析
3.1 实验数据
本文的实验数据包括传统互联网和移动互联网流量数据。有线网流量数据采集于某高校办公楼的出口路由器,采集时间为 2011 年 9 月 17 日和 2011 年 9 月 25 日,每次的采集持续时 间 为 30 min。这 两 天 的 流 量 数 据 包 含 了常 用 网 络 应 用 的 流 量 , 例 如 HTTP、BT、HTTPvideo、QQ等,其代表了用户日常使用网络的流量。对流量数据进行 如 下 处 理 :基 于 L7-filter 和 端 口 号 对 IP 报 文 进 行 类 别标 记[15];按 照 五 元 组 对 IP 报 文 进 行 组 流 ; 基 于 报 文 基 本字 段 计 算 行 为 特 征 值 ,建 立 特 征 向 量 ;每 10 min 的 流 量数据组成一个流样本集。两天的数据分别命名为 Day917和 Day925,它 们的流和 字 节 数 见 表 2 和 表 3,可 见 两者的 类 别 分 布 有 较 大 的 区 别 。在 Day917 中,eDonkey 的 网络 流 最 多 ,而 在 Day925 中 HTTP 和 DNS 的 网 络 流 较多,这与采集时间段内的用户上网行为有关。
移动网流量数据采集于志愿者的智能手机终端,采集时间 为 2016 年 2 月 29 日 ,利 用 GT 的 方 式[16]进 行 类 别 标 记 ,并对智能终端 App 进行归类,具体的类别分布情况见表 4。
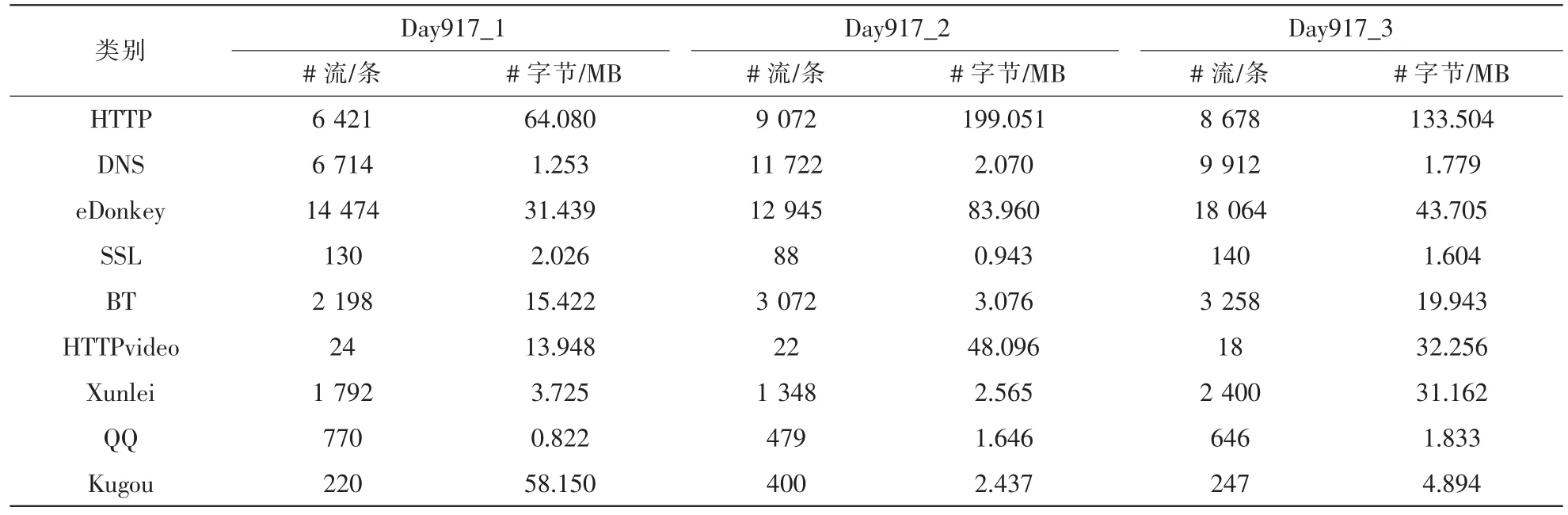
表2 Day917 数据集
3.2 评估指标
在互联网流量数据中,分类性能可以通过流或字节进行评估。本文采用的性能评估指标包括:单类流/字节分类准确率、总体流/字节分类准确率、流/字节 g-mean。这些评估 指 标 都 基 于 4 个 基 本 的 测 量 指 标 , 即 TP(true positive)、FP(false positive)、TN(true negative)和 FN(false negative)。对某个类 别 C0,TP 表示 C0的流 量 数 据中被正 确 分类的流 样本 (或 字 节) 数,FP 表 示被错误 分 类为 C0类别的 流 样 本(或 字节)数,TN 表示非 C0的流量数据中被 正 确分类的 流样本(或字节)数,FN 表示 C0的流量数据中 被 错误分类 的流样本(或字节)数。

表3 Day925 数据集
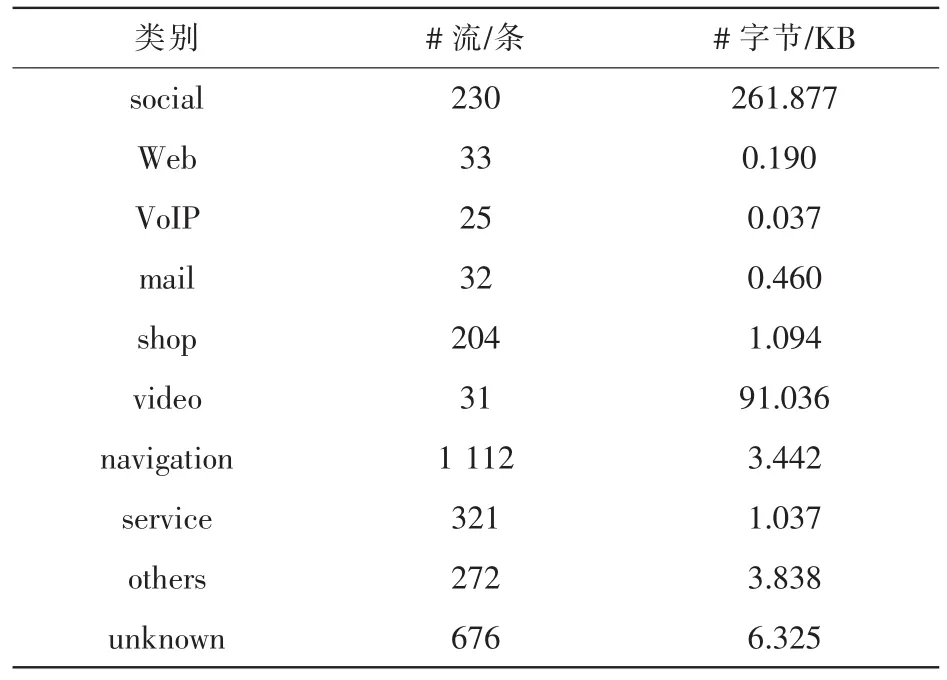
表4 移动网流量数据集
单类流/字节分类准确率表示每个类别的网络流中被正确分类的流/字节比率,如 式 (6)所 示 。Ri表 示 类 别 Ci(i= 1,…,m)的分类准确率。

总体流/字节分类准确率表示总体的网络流中被正确分类的流/字节比率,如式(7)所示。
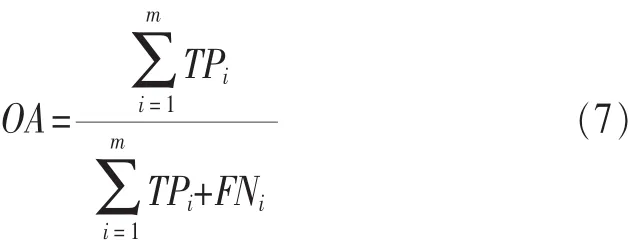
互联网流量数据存在类不平衡问题,即分类器可能偏向于分类大类(拥有大量的流样本)的流样本,而忽略小类(拥有少量的流样本)的流样本的分类性能。g-mean是不平衡分类问题中常用的评估指标,表示每类的分类准 确 率 的 几 何 平 均[11],如 式 (8)所 示 。当 所 有 类 别 的 分 类准 确 率 为 100%,g-mean 为 1;当 某 个 类 别 的 分 类 准 确率 为 0%,g-mean 为 0。好的分类模型在 g-mean 上应当接近于 1。

3.3 实验结果分析
3.3.1 基本分类性能
本文采用 C4.5 决策树作为分类算法,分别在 Day917和 Day925 数 据 集 上 ,以 前 10 min 数 据 作 为 训 练 集 ,后 两个 10 min 数 据 作 为 测 试 集 ,例 如 Day917_1 作 为 训 练 集 ,Day917_2 和 Day917_3 作为测试 集。在以下的实 验结果中,分类性能最好的以粗体标出。
Abacus和 HCBF 特征集合上的实验结果见表 5。在大部分数据集上,基于 HCBF 特征集合的分类器的总体流分类准确率和总体字节分类准确率更高,相比于基于 Abacus的分类器,分 别 提高了 5.16%和 61.8%。Abacus 主 要 表征节点之间通信的过程,即报文大小的分布情况,HCBF 从连接特征和通信过程两个方面描述网络流量,例如源端口和源 IP 地址的比值能区分传统的服务端和客户端以及P2P 应用。此外,端口号也作为特征,能区分使用固定端口号的传统应用,例如 mail、DNS、FTP 等。
大类(例如 HTTP、DNS 等)包含大量的网络流样本,对总体分类准确率的贡献大,高的总体流分类准确率表明大类的流样本能较好地被分类。重型流(具有高字节的网络流)样本对总体字节分类准确率的贡献大,高字节分类准确率反映对这些流的分类性能好。这些网络流会消耗更多的网络带宽,因此正确识别这些网络流,有利于实施网络容量规划等活动。

表5 基本分类性能比较
网络流量存在类不平衡问题,除了大类和重型流,某些小类的分类性能对网络管理也非常重要,例如即时通信应用 QQ,正确识别并有效传输此应用的报文,提高即时传输性能,从而改善用户体验。但是总体的流或字节分类准确率不能反映小类的分类性能。g-mean 通常用于评估不平衡数据集上的分类器的分类性能。表 4表明基于HCBF 的分类器总表现出更高的流 g-mean、字节 g-mean,这表明分类器在类间的分类性能更均衡。Abacus在Day917数据集上获得 0 的流 g-mean 和字节 g-mean。进一步分析单类的分类准确率(见表 6 和表 7),发现 HTTPvideo 应用获得0的流分类准确率和字节分类准确率。结合表1的网络流分布发现,此应用的网络和字节数较少,这可能由于类之间的网络和字节分布不平衡导致。Abacus反映与某节点通信的报文大小和报文数目的分布情况,需要大量的网络流量,此特征集合在 HTTPvideo 应用和其他小类上的区分能力较弱。
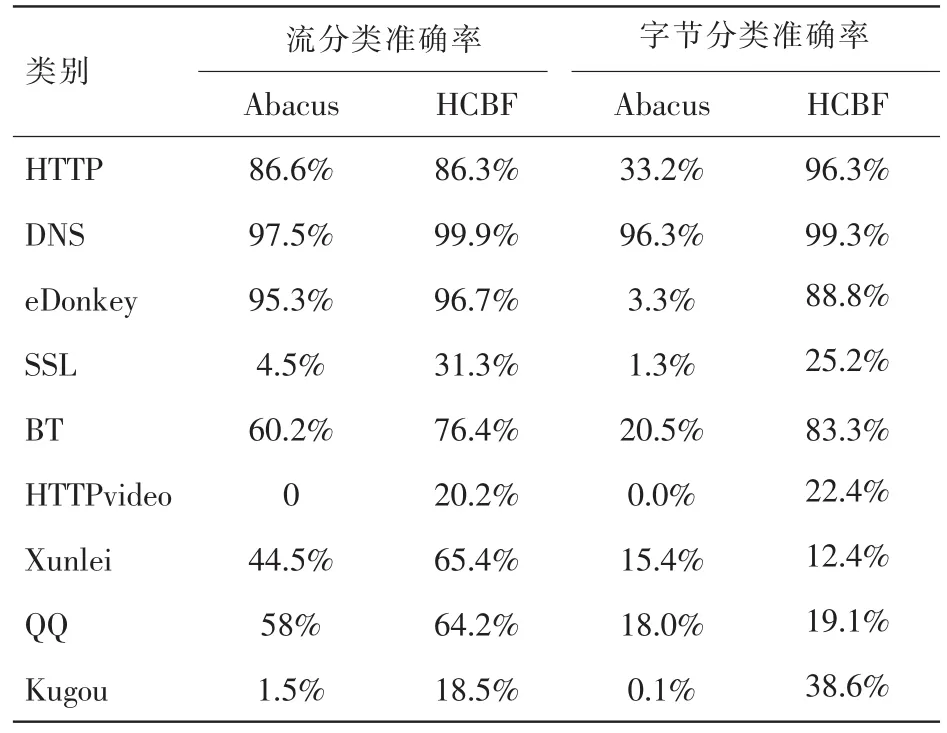
表6 Day917 的单类分类准确率

表7 Day925 的单类分类准确率
基于 HCBF 在多个小类上获得更高的流和字节分类准确率,例如 HTTPvideo、Kugou 和 SSL 等。在 Day925 数据集上,基于 HCBF 的分类器可为 SSL 获得 73.4%的流分类准确率和 55.1%的字节分类准确率。单类分类准确率再次证明HCBF特征集合在小类流样本上能获得更高的分类性能。
3.3.2 讨论
(1)时间稳定性
Day917 和 Day925 数据集之间相差 8 天。为评估时间稳定性,此部分将 Day917 数据集作为训练集,Day925 数据集作为测试集,分类结果见表 8。结合表 4 和表 5,实验结果表明 Day917 上训练的分类器,在 Day925 上的分类性能比在 Day917 上的差。这说明网络流量的统计特征的取值分布发生了变化。结合表 1表明,网络流在类间的分布也发生了变化。分类器的分类性能会随着时间的推移而弱化,即流量数据发生了概念漂移。表 8 表明 HCBF 仍然是性能最好的特征集合,因为此集合不仅反映主机间的连接行为,还提取了网络流量的通信过程,例如平均报文大小、流持续时间、报文大小的均方差等,具有更好的类间区分能力。
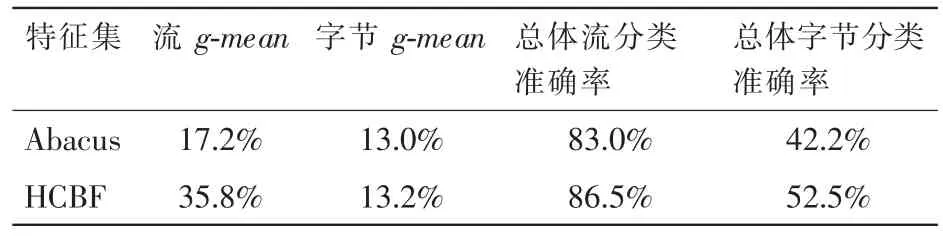
表8 Day917 与 Day925 的分类结果
(2)移动互联网流量数据上的分类性能
随着移动智能终端的快速发展,有效分类移动互联网流量有利于实施移动互联网的网络管理活动,目前也成为互联网流量分类的热点研究领域。此部分研究 3种特征集合在移动网流量数据集上的类间区分能力。 以 C4.5 决策树作为分类算法,10 倍交叉验证的结果见表 9。实验结果表明依然是基于 HCBF 训练的分类器取得更高的流g-mean、字节 g-mean 和字节分类准确率。基于 Abacus 训练的分类器获得 0%的流/字节 g-mean,进一步分析发现 Web,VoIP和 video 都获得 0 的分类结果,这是由于智能手机 App 大多基于 HTTP,与传统的 Web 流量很类似,若仅基于报文大小分布的主机间连接特征,较难区分这些应用。HCBF特征,不仅从 4 个网络流集合反映连接数、连接的 IP 地址数和端口数的比例、失败流数目,还有持续时间、报文数、字节数、传输层协议等信息,能从多方面表征每种网络应用的特性,从而具有更高的类间区分能力,在移动互联网流 量 数 据 上 ,取 得 92.9%的 流 分 类 准 确 率 和 85.3%的 字 节分类准确率。
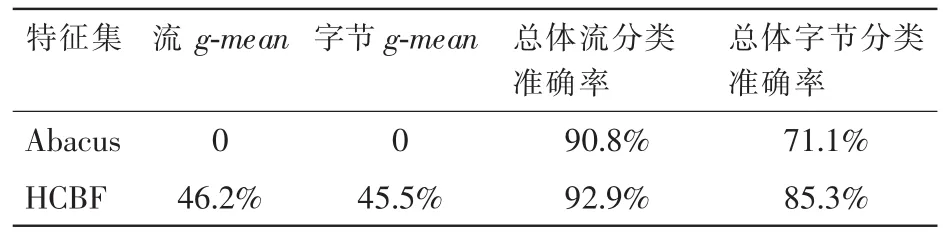
表9 移动网流量数据上的分类结果
(3)其他分类算法上的分类性能
上 述实验都 是 基于 C4.5 决策 树 ,为验证 HCBF 在 其他分类算法上的分类性能,接下来的实验利用随机森林(random forest)和 1NN 在 Day917 与 Day925 上 的 实 验 结 果见表 10。
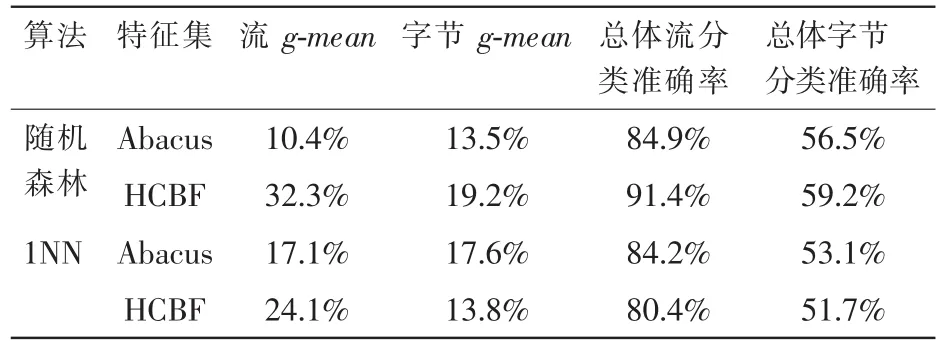
表10 random forest 和 1NN 分 类 结 果
实验结果表明,利用 1NN 算法,HCBF 的性能比Abacus差。但是,利用随机森林,HCBF 的分类性能仍然最优。本文的主要思想是利用 C4.5 决策树算法学习行为特征分类网络流量的分类规则,这说明基于分类规则的机器学习算法适合本文的行为特征。
(4)在其他数据集上的分类性能
在上部分只给出两天数据集上的实验结果,本部分给出在其他流量数据集上的分类结果,这些数据采集于2012 年的 5 月 1 日和 6 月 3 日。前者数据作为训练集,后者作为测试集,C4.5 决策树的分类结果见表 11。实验结果表明 HCBF 的 g-mean 和总体分类准确率仍然较优。
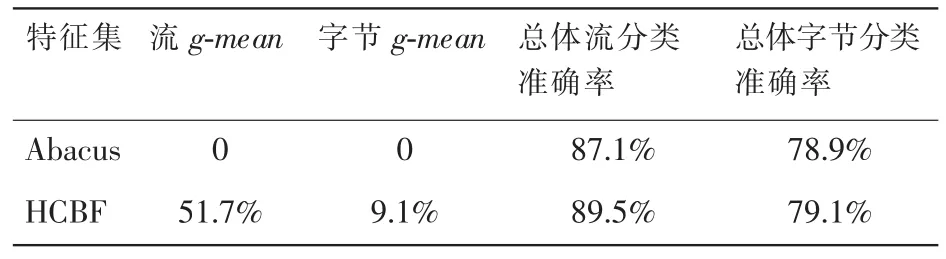
表11 其他实验数据集上分类结果
4 结束语
本文提取了基于多流的行为统计特征集合 HCBF,用于描述网络流,建立流样本作为 C4.5 决策树算法的输入,进而训练分类网络流量的分类规则。此特征集合建立在主机 间 通 信 行 为 模 式 之 上 ,从 {dstIP,dstPort,Proto}网 络 流 中通过提取主机间连接特性和通信过程信息获得。此方法结合了基于机器学习和基于通信行为的流量分类方法的优点,将其与已有的行为统计特征进行比较。实验结果表明,在分类精度和分类稳定性方面,HCBF 表现最佳。本文在传统互联网和移动互联网中提取了包含常用网络应用的流量,可代表用户的日常流量,实验的分类性能反映了统计特征在常用网络应用流量数据上的分类性能。
但是,基于 HCBF 的流量分类器的字节分类准确率较低,特别是在不同天数的流量数据集上,这可能是错分重型流造成,未来工作将研究重型流在主机间的传输型行为,并提取新的统计特征;HCBF 在全流的网络流量数据上获取到,难以用于在线流量分类,未来将研究在子流上提取行为统计特征,提高分类速度。
参考文献:
[1] WANG Y,XIANG Y,ZHANG J,etal.Internettraffic clustering with side information [J].Journal of Computer and System Sciences,2014,80(5):1021-1036.
[2] ZHANG J,CHEN X,XIANG Y,et al.Robust Network Traffic Classification [J].IEEE/ACM Transactions on Networking,2015,23(4):1257-1270.
[3] DAINOTTI A,PESCAP A.Issues and future directions in traffic classification[J].IEEE Network,2012,26(1):35-40.
[4] CALLADO A,KAMIENSKI C.A survey on Internet traffic identification [J].IEEE Communications Surveys&Tutorials,2009,11(3):37-52.
[5] KARAGIANNIST, PAPAGIANNAKIK, FALOUTSOSM. BLINC :multilevel traffic classification in the dark [J].ACM SIGCOMM,2005,35(4):229-240.
[6] ILIOFOTOU M,KIM H,FALOUTSOS M,et al.Graption:a graph-based P2P traffic classification framework for the internet backbone [J].Computer Networks,2011,55(8):1909-1920.
[7] BERMOLEN P,MELLIA M,MEOB M,et al.Abacus:accurate behavioral classification of P2P-TV traffic[J].Computer Networks,2011(55):1394-1411.
[8] ASAI H,FUKUDA K,ESAKI H.Traffic causality graphs:profiling network applications through temporal and spatial causality offlows [C]//The 23rd InternationalTeletraffic Congress,Sept 6-9,2011,San Francisco,CA,USA.New Jersey:IEEE Press,2011:95-102.
[9] MOORE A,ZUEV D,CROGAN M.Discriminators for use in flow-based classification [C]//In Passive & Measurement Workshop 2003 (PAM2005),August1,2005,London,England.[S.1.:s.n.],2005.
[10]HAJJAR A,KHALIFE J,DAZ-VERDEJO J.Network traffic application identification based on message size analysis [J]. Journal of Network and Computer Applications,2015 (58):130-143.
[11]LIU Z,WANG R Y,TAO M,et al.A class-oriented feature selection approach for multi-class imbalanced traffic datasets based on local and global metrics fusion [J].Neurocomputing,2015(168):365-381.
[12]FAHAD A,TARI Z,KHALIL I,et al.Toward an efficient and scalable feature selection approach for internet traffic classification [J].Computer Networks,2013,57(9):2040-2057.
[13]HONG Y,HUANG C C,NANDY B,et al.Iterative-tuning support vector machine for network traffic classification [C]//The 2015 IFIP/IEEE International Symposium on Integrated Network Management,May 11-15,2015,Ottawa,ON,Canada.New Jersey:IEEE Press,2015:458-466.
[14]HJELMVIK E,JOHN W.Breaking and improving protocol obfuscation:No.2010-05,ISSN 1652-926X [R]. [S.1.:s.n.],2010:1-34.
[15]LEE S,KIM H,BARMAN D,et al.NeTraMark:a network traffic classification benchmark [J].ACM SIGCOMM Computer Communication Review,2011,41(1):23-30.
[16]GRINGOLI F,SALGARELLI L,DUSI M,et al.GT:picking up the truth from the ground forinternettraffic [J].ACM SIGCOMM Computer Communication Review,2009,39 (5):13-18.
[17]ZHANG J,XIANG Y,WANG Y,etal.Networktraffic classification using correlation information[J].IEEE Transactions on Parallel&Distributed Systems,2013,24(1):104-117.
[18]WILLIAMS N,ZANDER S,ARMITAGE G.A preliminary performance comparison of five machine learning algorithms for practical IP traffic flow classification [J].SIGCOMM Computer Communication Review,2006,30(5):5-16.
[19]徐鹏,林森. 基于 C4.5 决策 树的 流 量分 类 方法[J]. 软 件 学报,2009,20(10):2692-2704. XU P,LIN S.Internet traffic classification using C4.5 decision tree[J].Journal of Software,2009,20(10):2692-2704.
Internet traffic classification method based on behavior feature learning
LIU Zhen1,WANG Ruoyu2
1.School of Medical Information Engineering,Guangdong Pharmaceutical University,Guangzhou 510006,China 2.Information and Network Engineering and Research Center,South China University of Technology,Guangzhou 510006,China
The connection graph based internet traffic classification method can reflect the connectivity behavior between hosts.Thus,it has high stability.But the heuristic rules summarized for traffic classification are generally incomplete,and they difficultly obtain high classification accuracy.Host communication behavior model and BOF method was researched,and a set of host connection related behavior features (HCBF)was extracted from the multiple flows with the same {destination IP,destination port and transport protocol}.To evaluate the performance of HCBF,it was compared with the existing feature set on the respect of basic classification performance and classification stability.The experiments were carried out on the traffic collected in the traditional and mobile networks.Results show that HCBF out performs existing feature sets.
internet traffic classification,behavior feature,machine learning,communication behavior,network measurement
The National Natural Science Foundation of China(No.61501128)
TP393
:A
10.11959/j.issn.1000-0801.2016152

刘珍(1986-),女,博士,广东药科大学讲师, 主要研究方向为互联网流量分类、机器学习和移动互联网。

王若愚(1977-),男,博士,华南理工大学工程师,主要研究方向为计算机网络和模式分类。
2016-04-11;
:2016-05-09
王若愚,rywang@scut.edu.cn
国家自然科学基金资助项目(No.61501128)
猜你喜欢
汽车电器(2022年9期)2022-11-07
销售与市场(营销版)(2021年10期)2021-11-21
铁道通信信号(2020年4期)2020-09-21
数学年刊A辑(中文版)(2020年2期)2020-07-25
数学物理学报(2019年6期)2020-01-13
井冈山大学学报(自然科学版)(2019年4期)2019-09-09
中国外汇(2019年11期)2019-08-27
销售与市场(营销版)(2019年6期)2019-06-21
网络安全技术与应用(2017年9期)2017-09-20
铁道通信信号(2016年8期)2016-06-01
