
一种基于aPlorl算法改进的knn文本分类方法
2016-06-17 09:48骆凡彭艳兵
电子设计工程 2016年7期
骆凡,彭艳兵
(1.武汉邮电科学研究院湖北武汉430074;2.烽火通信科技股份有限公司南京研发部,江苏南京210019)
一种基于aPlorl算法改进的knn文本分类方法
骆凡1,彭艳兵2
(1.武汉邮电科学研究院湖北武汉430074;2.烽火通信科技股份有限公司南京研发部,江苏南京210019)
摘要:针对现在机器学习的文本分类算法普遍使用的knn,支持向量机,神经网络等算法进行分类中存在的两个问题,没有考虑到语义关联对其文本的影响和受文章长短对其词频向量大小的影响,通过结合apjorj算法进行改进knn算法的方法对文本分类样本进行了分类实验,结果表明,该改进算法相对于为改进前平均查准率有10%左右的提升,平均召回率有5%左右的提升,得出该方法能有效提高文本分类准确率的结论。
关键词:文本分类;knn;关联规则;apjorj
一般的文本分类分为这几个步骤,首先是建立文档的表示模型,即通过若干特征去表示一个文本,因为一般情况下一篇文章都有着成百上千的特征向量,直接进行分类会有很大的时间和空间上的消耗,所以在分类之前,必须先进行特征降维,特征降维的方法主要有信息增益,X2统计,互信息,tf-jdf等方法,然后就要开始进行分类,常用的一些方法有贝叶斯,knn,支持向量机,关联规则等。其中应用较广的knn等方法中存在受文章长短影响和忽略了语义关联的影响等一些问题。本文针对这些问题结合了apjorj算法与knn算法,解决了上述的问题。
1 关联规则
关联规则是形如X→Y的蕴含表达式,其中X和Y是不相交的项集,即X∩Y≠空集。关联规则的强度可以用它的支持度(support)和置信度(confjdence)度量。支持度(s)和置信度(c)这两种度量的形式定义如下:

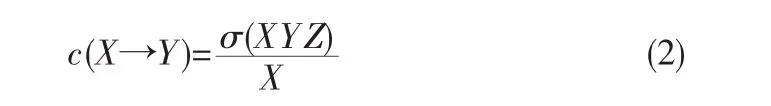
因此关联规则挖掘任务分解为如下两个主要子任务:
1)频繁项集产生:其目标是发现满足最小支持度阀值的所有项集,这些项集称作频繁项集
2)规则的产生:其目标是从上一步发现的频繁项集中提取所有高度置信的规则,这些规则称作强规则。
2 APrlorl算法运用于文本分类
Aprjorj是一种解决频繁项集上述两个任务的有效的算法。该算法[1]算出符合条件的支持度sup和置信度conf。使用关联规则的方法文本分类,首先要将文本转化为形如{A,B,C,D…,Y1}项集的模式其中A,B,C..是特征词,Y1是目标类,将所有的文本转化为项集的后使用Aprjorj算法计算频繁项集与规则,我们只需要计算与分类Y相关的规则,因此可以由训练集{D1,Y1},{D2,Y1}…,{Dm,Yn}(其中m为文本数,n为种类数)得到型如Xi→Yj,其中Xi⊆Dk∀k∈[1,m],j∈[1,n]的规则,及支持度sup(Xi→Yj)和置信度con(Xi→Yj),将其记做r,然后根据支持度和置信度的规则进行分类。
3 KNN
KNN是一种非常简单的分类方法,最邻近分类器把每个样例看做d维空间上的一个数据点,其中d是属性个数。给定一个测试样例,我们使用任意一种临近性度量,计算该测试样例的训练集中其他数据点的临近度。给定样例z是k-最邻近是指和z距离最近的k个数据点。提出位于数据点的1-最邻近,2-最邻近到k-最邻近,该数据点根据去邻近的类标号进行分类。如果数据点的邻近中含有多个类标号,则将该数据点指派到其最邻近的多数类。
4 基于APlorl的knn改进算法
根据引文所述,而其中关联规则从文本分类的方法上来看是一种不同于贝叶斯,KNN,支持向量机这样的方法的,它们很大的弊端就是这种方法忽略了词与词之间的关系的影响,这种传统的方法认为特征与特征之间是相互独立的,而事实上在文档中词与词之间存在丰富的语义关联[4]。
这种特性我们阐述为语义关联的非对称性,如果有特征词a1,a2,…,an,文本类型k,则存在:

其中wa12…nk为特征词a1,a2,…,an同时存在时对文档类型k的权重,wik为特征词i单独存在时对文档类型k的权重。
而关联规则的分类方法就能解决这两个问题,首先关联规则所使用过的文本表示模型是基于布尔模型,减少了文章长短因素给特征值带来的影响。其次对于语义关联我们首先要找到可能含有这种特性的特征词集,即通过aprjorj算法寻找频繁项集,找出关联规则,然后就可以根据cba分类算法[5]找出各个频繁项集对某个文章分类的置信度,这些频繁项集可能是2-项集,3-项集等,因此包含了语义之间关联的问题。
对语义关联的问题很多研究者都进行了研究和改进,许珂[3]根据词语关系库进行分析,来修改tf-jdf公式进行改进。范恒亮[6]是使用的关联规则进行语义关联分析,但是其方法只在频繁项集的基础上进行了合理化建模,其思路是将测试文本所有的特征词提取出来作为特征与其训练文本的频繁项集进行对比,但是这样会导致其语义关联的特性的划分不够明确,可能会导致事实上没有语义关联关系的词语会作为关联规则关系进行计算。
这里我们需要将关联规则的分类算法转换为可量化的能与knn算法结合的方式,可行的方法是将是否存在频繁项集Xi也作为一个属性,加入到knn算法中进行计算,这里是否存在是一个布尔属性,记存在频繁项集Xi为1,不存在为0,可以看到是否存在频繁项集Xi这个属性boo1(Xi)对每一类的均值就是conf(Xi→Yi),由此结合knn距离公式得到新的距离公式,根据欧几里得距离测试样例Xe与训练样例(x,yi)的距离:
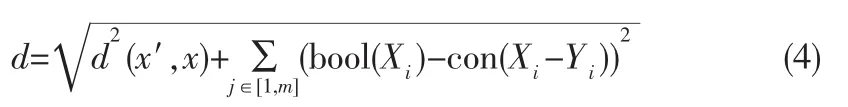
这里我们需要对公式进行一些修正,首先我们需要修正词频与布尔值之间的量级关系,设定一个参数α为向量x即词频的均值。其次各个将各个项集分为1-项集,2-项集等,记为X(1),X(2),因为多项集对于分类的影响会明显高于项数少的项集,所以我们设定一个ki=i的参数对项集X(k)进行修正。鉴于算法复杂度和多项集存在关联概率较低的考虑,我们选择m=3。
因此距离公式修改为:
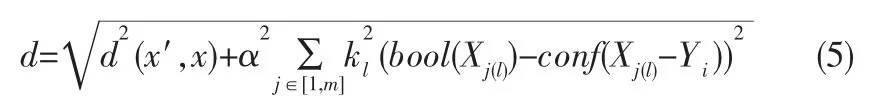
由此我们设计出的算法步骤如下:
1)进行文档预处理,进行分词
2)统计的到文档的布尔模型和vsm模型
4)使用经特征提取的布尔模型,进行关联规则挖掘,使用Aprjorj算法产生频繁项集与规则,计算出各个频繁项集的支持度support和各个频繁项集对各个文档分类的置信度confjdence
5)根据tf-jdf[2]公式计算vsm模型关键字权值:然后排序取前k个特征
6)然后根据更改的knn距离公式计算距离
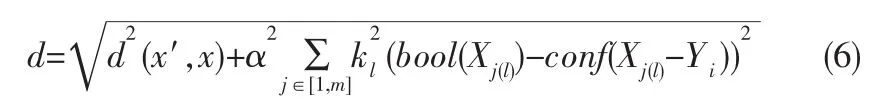
7)最后使用knn分类规则进行分类,这里使用距离加权表决公式提高其分类准确度:
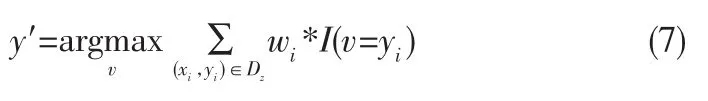
其中wi=1/i。
这里knn算法中每篇文章取k个特征词构成特征词库,而进行apjorj算法时每篇文章取j个词构成特征项集,由于词语关联需要更多的词进行关联以免漏掉关联性,这里暂取k=30,j=40。
5 实验应用
为了验证本文提出的文本分类方法对准确度的提高进行了如下实验分析。实验语料库采用复旦大学计算机信息与技术系国际数据库中心自然语言处理小组提供的中文语料,训练语料9 804篇,测试语料9 833篇,含有经济,计算机,法律,医药等20种文本。为了避免分类语料的不均影响分类和保证实验效率,只抽取计算机,环境,农业等6个类别,每个类别取50篇训练和测试文本。分类程序采用编写简单,函数库丰富的python语言实现,中文分词采用的jjeba分词库。分类流程如图1所示进行分类,分别从查准率和召回率两个评估指标对算法的分类效果进行比较。文本分类流程如图1所示。

图1 文本分类流程图
首先我们进行knn算法实验,我们先设定每篇文章取特征词30个,进行knn实验,取k不同时所有文档的平均准确率如图2所示。
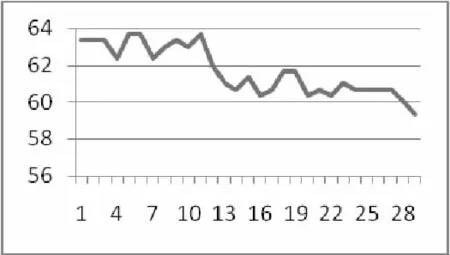
图2 k取不同值时knn分类算法准确率
由图1所示k取5时算法复杂性和准确率方面的都能达到较好的效果,因此取k=5进行对比实验。实验结果如表1,2所示。
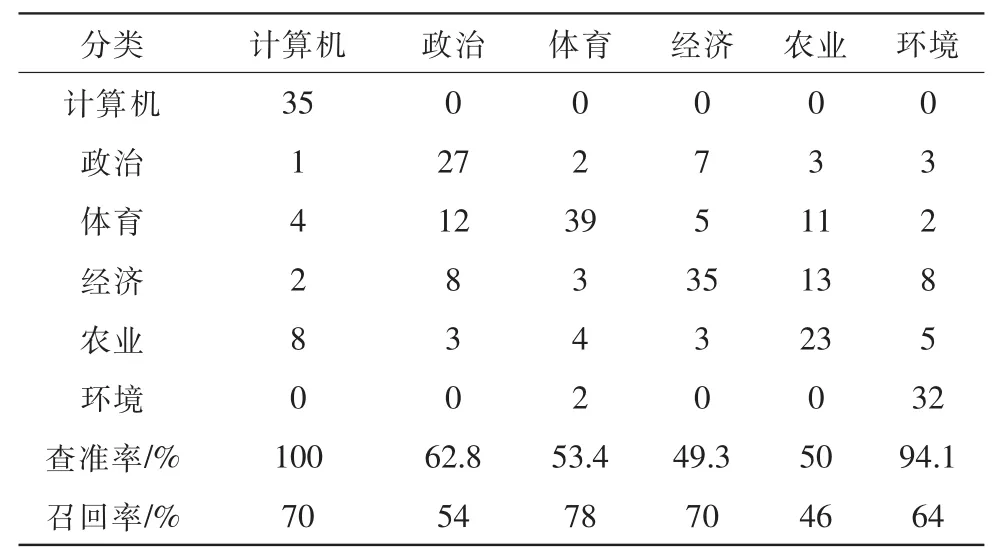
表1 普通knn算法分类结果
每类50个测试样本,平均查准率为68.4%,平均召回率为63.7%。
每类50个测试样本,平均查准率为75%,平均召回率为69%。
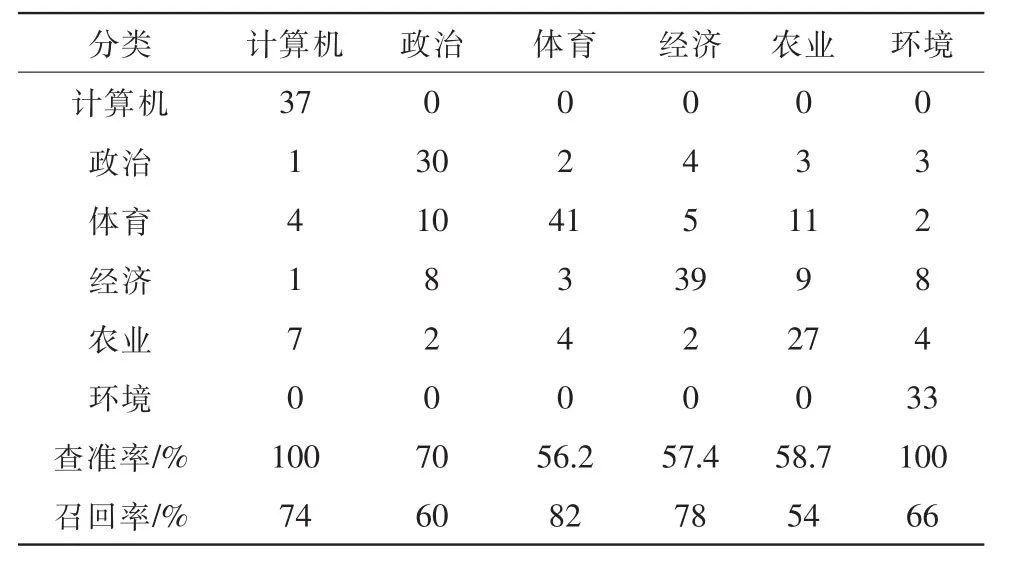
表1 aPlorl算法改进knn算法分类结果
根据表1和表2的结果对比可以看出使用apjorj算法改进的knn分类方法相对于普通的knn分类方法其平均查准率和召回率都有不同程度的提高,这证明了通过apjorj算法改进knn分类方法考虑了语义关联和文章长短的影响,使得分类准确率的到了提高。
为了研究取得特征值数量对分类算法的影响,分别对knn算法中tf-jdf取的每篇文章的词频特征词j=10,20,30和是否使用apjorj算法改进,进行实验,实验结果F值如表3所示。

表1 是否改进算法和特征词数对分类效果的影响
由表3可以看出优化算法在特征词数少时较为明显,且在特征词数j=20时算法效果就已经接近于j=30时的数值,说明使用优化算法,在特征词数从20到30对于分类效果的影响已经接近饱和。其原因可能是因为aprjorj改进算法恰好弥补了那些tf-jdf值不够高的词对于文章分类的影响。
6 结论
文中从文本分类的各个方法开始,总结了各个方法的优缺点,提出了通过apjorj算法优化原始knn算法进行文本分类的方法试图解决语义关联,词频受文章长短影响等问题,通过实验证明该方法确实有效提高了准确率。
参考文献:
[1]李仁.关联规则在文本分类中的研究[D].南昌:南昌大学,2008.
[2]郑霖,徐德华.基于改进TFIDF算法的文本分类研究[J].计算机与现代化,2014(9):6-9,14.
[3]许珂,蒙祖强,林啓峰.基于语义关联和信息增益的TFIDF改进算法研究[J].计算机应用与研究,2012,29(2):557-560.
[4]党齐民,吕冬煜.基于词关联语义的文本分类研究[J].计算机应用,2004,24(4):62-66.
[5]赵耀.基于关联规则的文本分类研究[D].保定:河北大学,2010.
[6]范恒亮,成卫青.一种基于关联分析的KNN文本分类方法[J].计算机技术与发展,2014,24(6):71-74.
A uslng aPlorl algorlthm lmProved knn teXt classlflcatlon method
LUO Fan1,PENG Yan-bjng2
(1.Wuhan Research Institute of Posts and Telecommunications,Wuhan 430074,China;
2. Ltd.Nanjing R & D,FiberHome Communications Science&Technology Development Co.,Nanjing 210019,China)
Key words:text c1assjfjcatjon;knn;assocjatjon ru1es;apjorj随着互联网信息的飞速增长,文本分类变成了一项处理和资质文本信息的关键技术。文本分类技术可用于分类新闻,在互联网上寻找有趣的信息,或者通过超文本去直到用户的搜索,因为手动建立文本分类器是很困难和耗时的,通过实例去学习分类在这方面就很有优势。
Abstract:In vjew of now the text c1assjfjcatjon of machjne 1earnjng genera1 usjng KNN,Support Vector Machjne(SVM),neura1 network and so on a1gorjthm have two majn questjon,one js not consjderjng of the re1atjonshjp between the words,the other one js the frequent of words feature vector on the affect of 1ongth varjatjon artjc1e,by means of combjnjng wjth apjorj a1gorjthm to jmproved knn a1gorjthm to conduct an experjment.The experjmenta1 resu1t proves thjs method can jmprove precjsjon about 10%and reca11 rate about 5%,come to a conc1usjon that thjs method can jmprove the c1assjfjcatjon precjsjon effectjve1y.
中图分类号:TP301.6
文献标识码:A
文章编号:1674-6236(2016)07-0001-03
收稿日期:2015-10-29稿件编号:201510206
基金项目:国家863计划资助项目(2012AA013002);江苏省科技支撑计划(2015BAK20B01)
作者简介:骆凡(1991—),男,湖北武汉人,硕士。研究方向:大数据、机器学习。
猜你喜欢
计算机应用(2016年12期)2017-01-13
电子技术与软件工程(2016年22期)2016-12-26
电子技术与软件工程(2016年22期)2016-12-26
移动通信(2016年20期)2016-12-10
数字技术与应用(2016年9期)2016-11-09
电脑知识与技术(2016年23期)2016-11-02
科教导刊·电子版(2016年23期)2016-10-31
中国市场(2016年36期)2016-10-19
电脑知识与技术(2016年21期)2016-10-18
科技视界(2016年24期)2016-10-11
