
概率数据集的垂直数据格式挖掘
2016-06-16 06:27陈凤娟
安阳师范学院学报 2016年2期
陈凤娟
(辽宁对外经贸学院,辽宁 大连 116052)
概率数据集的垂直数据格式挖掘
陈凤娟
(辽宁对外经贸学院,辽宁 大连 116052)
[摘要]由于频繁项集挖掘在各种实际应用中起到了重要的作用,它已经成为了很多研究的主题,大部分研究的是在精确数据的事务数据集上进行挖掘。然而,有很多情况,数据是不确定的。在过去的几年里,提出了一些基于Apriori和基于树包含不确定数据的概率数据集上频繁项集的挖掘算法。这些算法从记录收集的角度把数据集看成水平的,本文则把包含不确定数据的概率数据集看成垂直的向量,并研究在此基础上的挖掘算法。
[关键词]概率数据集;概率频繁项集;垂直数据格式
1引言
频繁项集挖掘的目标是找出数据集中隐含的、未知的和潜在有用的信息,而这些信息以项集的形式出现,这些项集是数据集中的某些项的集合[1]。自从频繁项集挖掘被提出以来,它已经成为了很多研究的主题。它也在其他模式挖掘中起到了至关重要的作用,如共同位置模式挖掘、出现模式挖掘、流行模式挖掘及社交网络中的重要朋友圈挖掘等等。
在最开始对于频繁项集挖掘的研究中,大部分算法都是基于Apriori的生成-测试模型的算法。这类算法通过生成候选频繁项集,然后再测试这些候选项集是否为频繁项集,删除不频繁的项集。为了提高Apriori算法的效率,提出了基于树的FP-growth算法,这种算法在挖掘过程中,递归的创建FP树,从这些树中可以挖掘出频繁项集。无论是基于Apriori的算法,还是FP-growth算法,都是把数据集中的记录按照水平方式来处理,每一个记录包含了一组项的集合。相反的,数据集可以被看成垂直的,即一组向量或一组记录标号的集合。这个向量或记录标号的集合表示哪些记录包含当前的项。VIPER和Eclat算法是垂直挖掘数据集的两个算法。
无论是水平的还是垂直的挖掘算法都是在精确数据集上进行的,这种数据集中,用户很清楚地知道一个项在数据集中的某条记录中是出现还是不出现。然而,现实的应用中,有很多不能确定项是否出现的情况,仅仅是怀疑而不能保证该项一定出现。这种不确定性可以用一个与项相关联的存在概率来表示。为了能从这些概率数据集中挖掘频繁项集,已经有很多水平算法的扩展,如U-Apriori,UF-growth等[2]。本文主要研究在垂直数据格式上挖掘概率数据集,找到其中的频繁项集,主要通过对确定数据中的VIPER进行扩展,使其能在包含不确定数据的概率数据集中工作。
2不确定数据与期望支持度
不确定性可能是由测量的不精确引起的,也可能是人为添加到数据集中的。比如,在很多应用中,如环境监测和一些工厂环境中,传感器常被用来收集数据,一些错误或不精确或偏差可以是由一段时间内测量属性的快速变化而产生的无线传输错误或网络中的错误。在隐私保护中,会故意添加一些不确定数据到数据集中,起到保护用户隐私的作用。在实际应用中,有多种产生不确定数据的原因。
由于不确定性的存在,用户无法确定一个项x在一个记录ti中是否存在。对于这种是否存在的不确定性,可以用存在概率P(x,ti)来表示,它表示x在包含不确定数据的概率数据库的记录ti中存在的可能性大小[3]。存在概率P(x,ti)的范围是从一个接近于0的正数,表明x在记录ti中出现的概率非常小,到1,表明x在记录ti中一定出现。按照这种表示方式,在确定数据库中的每个项都可以被看成存在概率是1的不确定数据。
如果使用可能世界语义来解释不确定数据,对于给定一个项x和一个记录ti,就有两个可能世界。一个可能世界W1表示x在记录ti中出现,另一个可能世界W2表示x在记录ti中不出现。虽然无法确定这两个可能世界哪个是真正出现的,但是可以得到这两个可能世界出现的可能性大小,即W1出现的概率是P(x,ti),W2出现的概率是1-P(x, ti)。通常,给定m个不同的项和n条记录,就有2mn个可能世界。
在包含不确定数据的概率数据集中,假设其记录总数为n,如果一个项集X的期望支持度expSup大于用户给定的最小支持度minSup,那么这个项集X就是频繁的。项集X的期望支持度expSup可以用下面的式子得到[4]。
在这个等式中,sup(X,Wj)表示项集X在某个可能世界Wj中的支持度,prob(Wj)表示可能世界Wj成为真实世界的可能性大小。sup(X,Wj)可以通过在可能世界中统计项集X在记录中出现的次数来得到。
prob(Wj)可以用下式计算得到[5]
其中,x和y是项集X中的项。当项集中的每个项相互之间独立,就可以用下面的式子来计算expSup(X)。
这样就可以使用expSup(X)来计算所有项集的期望支持度了。
3概率数据库的垂直表示
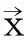
在确定数据集中,频繁项集挖掘算法VIPER使用了向量来表示每个项x在记录中是否出现,并从这些向量中采用自定向上的候选生成模式来挖掘频繁项集。在挖掘包含不确定数据的概率数据库时,保存每个项x在每个记录ti中的存在概率。那么,如何用垂直方式来表示包含存在概率值的概率数据库[6]。
为了表示概率数据库中的不确定数据,可以为每一个不同的项使用一个向量,由该项的取值和该项的存在概率组成。然而,潜在的问题就是数量太多,因为存在概率可以在0和1之间取任意的实数,所有从理论上它可能是不可数的无限数。实际上,在数据库中,这些<项的取值,存在概率>组成的一对值的数量是可数。
为了找到频繁概率,需要找到期望支持度大于最小支持度的项集,也就是说,我们需要找到比每个<项的取值,存在概率>的出现次数要多的所有频繁项集。因此,不需要保留所有的不同的<项的取值,存在概率>的向量,而是只需要对项集X中的每个x保留其向量。
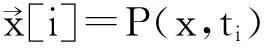
4基于垂直表示的频繁项集挖掘
在确定数据库中,VIPER算法通过统计向量中每个项的元素1的个数,然后与给定的最小支持度比较,如果大于等于最小支持度minsup,则该项就是频繁的。找到频繁1项集后,VIPER算法应用一个组织候选生成步骤,对两个向量做交叉形成候选2项集。重复上述比较过程,直到生成全部的频繁项集[7]。
在包含不确定数据的概率数据库中,用向量来垂直表示概率数据库后,就可以在这个概率数据库中应用扩展后的VIPER算法,来挖掘垂直数据模式下的频繁项集了。这个扩展的VIPER算法可以称为U-VIPER算法[8]。
在U-VIPER算法中,首先要解决的问题是,如何计算只包含一个项的项集的概率支持度。对于确定数据库,可以通过计算向量中元素1的总个数得到项的支持度,类似的,在U-VIPER算法中,可以通过求向量中所有非零的存在概率之和来计算概率数据库中的期望支持度。
当U-VIPER算法计算出1项集的期望支持度后,用该期望支持度与用户给定的最小支持度进行比较,如果expSup(x)≥minsup,那么,该项就是频繁的,否则该项就是不频繁的。这样,可以找出所有的频繁1项集。然后,下面的问题是如何生成由更多项组成的候选项集,如2项集、3项集和k项集等等。
为了挖掘概率数据库中的频繁项集,U-VIPER算法计算保存在向量中的单个项的期望支持度,如果项集的期望支持度大于给定阈值,则该项是频繁的,否则,是不频繁的。找到频繁1项集后,应用向量点积运算,找出候选频繁2项集,再计算候选项集的期望支持度,并与最小支持度阈值比较,不断重复上述过程,直到得到概率数据库中所有的频繁项集。
5结束语
在包含不确定数据的概率数据库中挖掘频繁项集已经引起了越来越多的关注,现有的很多算法都是在水平表示数据库的基础上,给出挖掘算法。在确定数据库中,可以把数据库采用垂直数据格式来表示,同样,在概率数据库中,也可以在垂直表示的数据库上进行频繁项集的挖掘。
[参考文献]
[1]R. Agrawal, R. Srikant, “Fast algorithms for mining association rules,” in VLDB, 1994.
[2]C. Aggarwal and P. Yu. “A survey of uncertain data algorithms and applications, ” IEEE TKDE, 2009 , 21(5):609~623.
[3]O. Benjelloun, A.D. Sarma. “ULDBs:Databases with uncertainty and lineage,” in VLDB, 2006.
[4]C. Chui, B. Kao, E. Hung, “Mining frequent itemsets from uncertain data,” in PAKDD, 2007.
[5]T. Bernecker, H.P. Kriegel, M. Renz, F. Verhein, A. Zuefle,“Probabilistic frequent itemset mining in uncertain databases,” in KDD,2009.
[6]P. Shenoy et al.“Turbo-charging vertical mining of large databases, ” in SIGMOD 2000.
[7]C.K.S. Leung.“Mining uncertain data. Wiley Interdisc,” Data Mining and Knowledge Discovery,July/Aug. 2011,1(4):316-329.
[8]C.K.S. Leung. “ Mining probabilistic datasets vertically,” in IDEAS’ 2012.
[责任编辑:江雪]
Mining Vertical Data Format over Probabilistic Dataset
CHEN Feng-juan
(Liaoning University of International Business and Economics, Dalian 116052,China)
Abstract:As frequent itemset mining plays an important role in various real-life applications, it has been the subject of numerous studies. Most of the studies mine transactional datasets of precise data. However, there are situations in which data are uncertain. Over the few years, Apriori-based, tree-based mining algorithms have been proposed to mine frequent itemsets from these probabilistic datasets of uncertain data. These algorithms view the datasets horizontally as collections of transactions. In this paper, probabilistic datasets of uncertain data are viewed vertically as collections of vectors. Then an algorithm to mine probabilistic datasets vertically is be studied.
Key words:Probabilistic Dataset; Probabilistic Frequent Itemset;Vertical Data Format
[收稿日期]2016-01-21
[作者简介]陈凤娟(1979-),女,辽宁省本溪市人,副教授,主要从事数据挖掘、无线传感器网络研究。
[中图分类号]TP32
[文献标识码]A
[文章编号]1671-5330(2016)02-0041-04
