
数据库关键字查询清理技术分析
2016-06-14 19:08金妍
电脑知识与技术 2016年12期
金妍

摘要:随着信息时代的发展,加快了数据库技术与互联网技术的结合,而且更多的用户可以通过对在线数据库的访问来获取相关信息。该文将会对数据库关键字查询清理的基本方法和相关技术给予介绍,从而提高用户关键字查询的效率和准确性。
关键词:数据库;关键字;查询清理技术
中图分类号:TP391 文献标识码:A 文章编号:1009-3044(2016)12-0003-03
传统的数据库查询技术一般是由程序员来操控的,然后对用户所输入的关键字和相关条件对比,最终为用户提供所需要的结果,但是该方法所需要花费的查询时间比较长,为了提高其查询效率,本文将会对数据库关键字查询清理技术给予介绍,并对其相关实例给予介绍。
1 数据库关键字查询综述
对于普通用户而言,为了更好地适应时代发展步伐,他们开始访问在线数据库,但是他们对数据库模式知识和查询语言不了解,从而无法进行准确的查询。与此同时,数据库里存放了大量的数据信息,如果没有一个简便而有效的查询方法,将会浪费大量的时间和精力,因此不管是企业还是个人都要鼓励使用数据库关键字查询,下面将会对数据库关键字查询方法给予介绍。
1.1基于数据图的方法
大量的研究标明,通过数据图的查询不仅能够实现对相关数据的查询,而且还能提高查询结果的准确性。在进行数据库关键字查询过程中,主要包括以下两个步骤。首先,将数据库赋予一定的权重,并转化成相应的数据图,随后对数据图进行物化处理,根据数据图中所具备的节点元组和边元组关系来实现关键词的查询工作,从而构建了一个最小代价的简化子树。
一个数据图G一般包括了两个主要的集合,分别是一个节点的集合和一个边的集合。图G中又含有结构化节点和关键词节点两种类型的节点。关键词节点只含有入射边,而结构化节点不仅包括了入射边,同时还包括了一个出射边。因此,仅通过一个边是无法完成两个关键词的衔接。图G中还包括了前向边(u,v)和后向边(v,u) 两种类型,前向边(u,v) 中,u和v之间一般是借助主外键关联进行连接的,而后向边(v,u),与前向边(u,v)存在一定的相关性,而且只要图中具有前向边(u,v),才能够形成后向边(v,u)。实际上,大部分数据图的边具有单方向的特征,并对各个方向上的强弱关系给予表示。例如在对主外键关联边进行反映过程中,主键与外键正方向的边和反方向的边具备不同的功能。
总的来说,如果数据库中具备了一个关键词集合,就能够进行信息的查询,而整个查询过程包括两个阶段:第一个阶段是完成倒排表关键词的查找,需要借助节点ID才能够完成,该节点含有一个或多个关键词,又被定义为“关键词节点”。第二个阶段是借助图搜索算法,来查询与上述关键词相关联的节点,并对结果树进行排序,以供用户筛选所用。
1.2基于模式图的方法
该方法一般包含了以下三个阶段。第一个阶段:在数据库模式的基础上,将所有可能出现的连接表达式及查询结果进行一一列出。第二个阶段,按照一定的标准将连接表达式按照一定的方式向SQL语句进行转换,以保证其在数据库上顺利执行,从而提高数据结果的准确性。第三个阶段,完成所有可能结果的排序工作,然后将最终结果反馈给用户。在第一个阶段所进行的列举,会对表达式的方式和数目进行限制,对于过大的表达式尺寸,将会增加两个元组的距离,这样就需要增加更多的中间连接,从而导致检测结果失真。
在关系数据库中,基于模式图的查询方法,一般需要通过以下三个阶段才能完成对关键字的查询。第一个阶段:将与关键字相关的候选答案一一列举出来,而且保证每个候选答案都拥有单独的元组连接树;第二个阶段,为每个答案进行分析和评价,并保证与查询相关的答案排到所有答案的前边;第三个阶段,将符合要求的结果反馈给用户。以DBXplorer为例,其一般需要通过以下两个步骤才能完成查询过程:(1)发布:主要是为数据库创建一个辅助符号和结构表,使其拥有一定的查询功能,此外在关键词查询过程中符号表起到了至关重要的作用,在查询时通过符号表的使用可以对数据库中关键词的具体位置给予准确的判定,从而加快查询结果的速度。(2)搜索:其能够从发布的数据库中搜寻到自己想要的结果,但是其一般需要借助系统来完成符号表的查找工作,从而确定关键词在数据库中的相关信息。其次,对所有连接树进行一一列举,并且任何一个连接树对于数据库模式图来说都具有十分重要的意义。最后,为每个连接树编写SQL语句,其不仅可以获得元组连接树,而且还可以完成对连接树中各个表的连接操作,并对所有关键词的元组连接树进行一一对应,然后并对取进行排序,并将最终的排序结果传输给用户。
2 数据库关键字查询清理技术分析
2.1语义矩阵及实例分析
语义矩阵最初是由Yu和Pu提出来的,是用于数据库中数据库单元和关键字序列中查询单元的一个矩阵组合,每一列表示数据库中查询单元和数据库单元在拼写上的距离,并按照大小进行排序。语义矩阵是数据库关键字查询清理中比较常用的技术,其一般是借助WordNet的同义词功能来组建语义方阵,并列举出与之相关的语义方阵算法。通过WordNet功能可以完成对关键字的同义词进行查询,而且WordNet中所有的关键字同义词序列会按照与关键字相似程度进行排序。因此,我们就能够按照WordNet列举出的同义词序列来完成语义方阵的构建。总的来说,语义方阵构建,和语义矩阵的形成具有一定的相似性,其一般是借助关键字序列中所具有的查询单元来实现的,而且任何一个查询单元都会由一个扩展单元与其相对应,并最终由扩展单元组成矩阵。在对数据库关键字查询过程中,每个扩展单元的建立,都需要遵循以下几个方面的原则:1)在相同的距离下,与在WordNet里提供的查询单元相比,查询单元本身具有较高的优先级;2)在不同的距离下,如果距离比较下其优先级就会越高,该过程一般区分是由查询单元本身扩展出来的还是由查询单元同义词扩展出来的,而将距离小的扩展直接排在前面,来组建查询单元的单元扩展序列。遵循上述原则我们可以将关键字序列中的某个扩展的具体算法进行介绍:
1)根据需求来调用WordNet的同义词查询函数,对数据库关键字中的每个同义词序列进行查询。
2)对每个关键字查询单元所具备的同义词序列进行全面的分析,然后按照扩展因子来对每个关键字序列的长度n进行分析,从而生成单元扩展。
3)对关键字查询中相同的查询单元分别扩展成与之相对应的扩展序列,然后将相似度比较高的扩展单元进行合并处理,该过程一般要遵循一定的标准,即将优先级高的排在最前面。对于扩展单元优先级的确定也要按照一定的规范进行评估。扩展序列的合并也要遵循以下两个过程:第一是将前两个扩展序列进行合并,然后将新生成的序列与下一序列进行合并。第二是根据要求生成一个空白序列,然后按照上述原则要对每个序列的优先级进行判断,并将其加入到空白序列中,并将该序列从原来的同义词序列中删除。一直这样下去,直至空白序列被全部填满为止。
4)将数据库关键字序列中带有同义词的扩展序列结合在一起,然后组建成一个具有同义词的语义方阵。实例分析:例如,在进行数据库关键字查询过程中,其中“movie”是关键字,但是在“film”在数据库中也可以表示“电影”, 大多数的查询方法并未将两个单词结合在一起进行查询,这样一来会出现数据库中关键字字符不匹配的问题,而且还会有一部分用户感兴趣与“film”相关的信息,从而导致大量结果无法查询出来。本次分析结果表明,大部分数据是从互联网上获取的,主要有电影、音乐等的数据库IMDB。该过程中,最好将IMDB划分成独立的TEXT数据库来进行数据集测试。其包括了983920个元组,并通过JDBC连接Oracle9i,预处理方法借助JAVA实现,此外还引用了Lucene作为RDBMS的IR引擎。
实验一:测试同义词关联的有效性
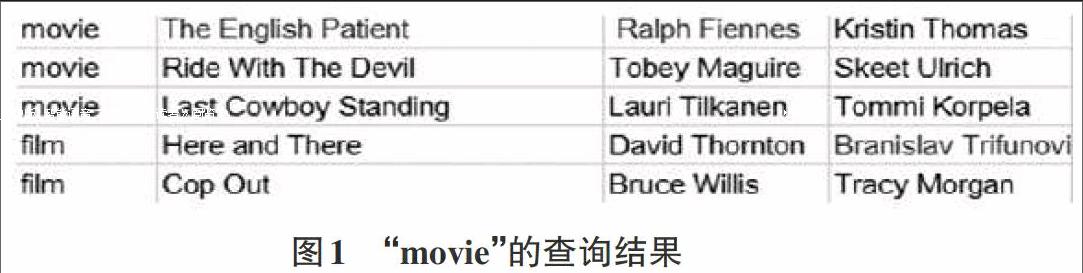
在数据库关键字搜索引擎上输入一个查询序列“movie”,就可以获得如图1所示。
从上述结果中可以看出,其结果中不仅包括了与“movie”相关的信息结果,而且还包括了与“movie”同义词“film”的结果,从而说明语义矩阵具备了与同义词向关联的效果。随后,在数据库关键字搜索引擎中还可以将“movie Bruce Willis” 的查询序列输入,这样就能够获得与查询序列同义词的结果,最终结果如图2所示。
从图2中我们同样可以看到与“movie” 同义词“film”的查询结果,又一次证实了语义矩阵技术是有效的,并且能够查询到同义词的。
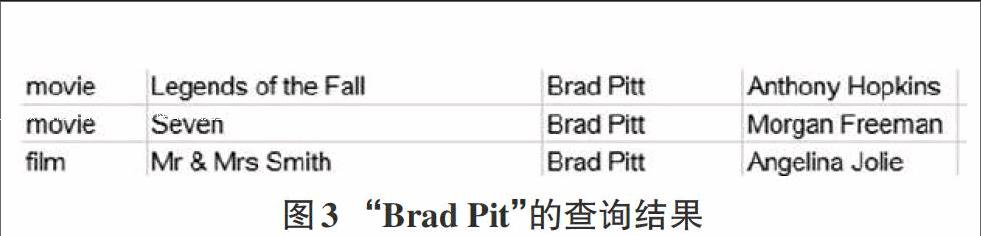
实验二:在系统中测试纠错功能与测试纠错结果的有效性密不可分,为了确保该过程的顺利进行,我们尝试查询数据库中的数据,例如“Brad Pitt”在数据库中对应了某位演员的相关信息,我们可以故意输入错误信息,来测试其是否能够查询到我们希望得到的结果。因此在数据库关键字搜索引擎上输入了“Brad Pit”来进行查询,最终查询结果如图3所示。
图3所示的结果显示,“Brad Pit” 的查询结果含有与“Brad Pitt”相关的信息,而且对“Brad Pit”中存在的错误地方进行了纠正。因此,语义矩阵在数据库关键字查询中具有纠错功能,以确保最终查询结果的准确性。
2.2 回溯算法及实验评估
回溯算法同样是数据库关键字查询清理过程中比较常用的一项技术,借助相关的函数和响应理论,可以得到最优分组问题。要想获取一个问题的最优解就是将与该问题相关的所有解逐一列举出来,然后对所有可能正确的结果进行检查,随后就能够获得我们所需要的结果。实际上,如果候选解数量有限时,可以对所有解进行一一检查,从而查找出我们所需要的解,这样不仅可以提高查询的效率,而且还能提高查询的最终结果。但是,在实际应用过程中,该种方法并未得到我们想要的结果,因为该方法的候选解空间范围比较大,一般可以达到指数级别,因此通常情况下可以借助回溯算法来实现关键字的查询,其可以减少问题求解过程中所需要的时间。
回溯算法应用过程中需要建立一个解空间,而且每一个解空间都含有一个与之对应的解。在数据库关键查询过程中中,解空间将会根据不同的分组给予不同的定义,并且每一个函数的调用都会得到与之对应的得分,这样可以便于解能被容易的查询到。实际情况下,我们会采用一个树的方法来对解空间进行有效的组织,该方法最重要的部分是树的延伸及根节点的选取规则,而且要求查询人员对树的根节点进行全面的分析和了解。首先对于序列查询过滤阶段,会生成一组附带查询编码的查询序列,然后对连续的查询单元进行一一查询,并将最终的查询结果组建一个查询词组的候选。其次通过该候选查询词组可以实现对相关数据库词组的查询工作。总的来说,就是将所有词组候选进行逐一搜索,并将每个扩展序列中与之相等的扩展单元结合在一起,就形成了一个新的查询词组。最后,还需要对整个数据库进行查询,如果得到的查询结果与上述查询结果一致,就说明该查询结果符合用户需求,可以反馈给用户。
只要该查询单元未按照要求进行合并,就可以通过一些函数来组建一个单独的查询词组。通过该方法还可以将过滤后的查询序列来进行初步分组,最终形成一个符合初始化的分组情况,并将其定义成一个解空间树的根节点。在对每一个查询序列进行分组时,需要加强与语义矩阵的有效结合,这样一来就会完成不同查询序列的分组。此外,我们还可以根据得分函数来对每一个查询序列分组情况进行评估。通常情况下,在分组情况确定的条件下,如果一个查询序列需要选择一套比较靠前的语义矩阵,而且要选择那些具备较小扩展距离的元素,换句话说,就是语义矩阵中具有较小行号比的元素,因此我们先调用得分函数来对扩展距离的大小进行判定,然后该情况下所得到的结果就是最终查询序列分组单元。然后再对剩下的情况进行一一对比,对比结果一般是用得分更高分组来取代该分组,否则我们就会将该分组定义为我们所需要查询的分组。
解空间树的延伸规则主要是借助组合的方法来完成的,并且不同树的节点具有与之对应的分组情况,任何一个节点的分组情况都能够找到与之对应的最终的完全查询序列分组。这样一来我们能够完成对解空间树的搜索工作,并借助与之相应的得分函数来对其进行评价,从而找到得分最高的那个分组,这样一来就可以确定数据库关键字查询序列的分组情况。
实验评估:本次实验的配置为一台内存2GB的PC机,其硬盘SATA7200转80G,PCU英特尔酷睿双核2.33GHz,操作系统是Windows XP SP3,数据库是Oracle9i。具体操作过程中,一般需要从互联网上获得所分析的数据,其包括了电影、音乐等的数据库IMDB。该过程中,最好将IMDB划分成独立的TEXT数据库来进行数据集测试。其包括了983920个元组,并通过JDBC连接RDBMS,预处理方法借助JAVA实现,这样一来我们就可以通过回溯算法来达到最终的清理算法。
如图4描述的是实验清理前与后时间对比关系。图4描述了数据库关键字查询从3逐渐增加到7的变化情况。从图中我们可以看到相同的查询序列中,经过清理以后的查询所需要花费的时间明显低于未经过清理的查询时间,因此通过对数据库关键字查询进行清理处理后,可以有效提高其查询效率。并且查询序列的长度越长,查询过程中所需要的时间就越长,而且呈现出指数级增长的趋势,从而说明处理后的查询时间也具有一定的指数级增长现象。但是这样的处理效果,一般在查询较长序列时,所起到的效果才是最明显的。
3 结束语
近些年来,随着我国互联网技术的发展,数据库关键字查询清理技术得到了广泛的应用,并且相关技术的研发不断深入,各种新成果不断涌现。而语义矩阵和回溯算法在数据库关键字查询清理中应用较多,其需要对查询序列进行有效的清理,只有这样才能对其作出有效的查询,提高查询确效率,并确保了查询结果的准确性。
参考文献:
[1] 陈廷.数据库关键字查询清理技术 [J].信息技术与信息化,2015,3(3):62-63.
[2] 沈文婷.数据库关键字查询清理技术研究 [J]. 电脑知识与技术,2011,14(34):89-90.
[3] 冯丽敏,杨艳,钟颖莉.基于相关查询的关键字搜索优化技术[J]. 计算机研究与发展,2013,5(z1):104-105.
猜你喜欢
华人时刊(2022年1期)2022-04-26
动漫界·幼教365(大班)(2019年10期)2019-10-28
计算机研究与发展(2017年7期)2017-08-12
环球时报(2009-11-25)2009-11-25
现代营销·经营版(2007年6期)2007-05-14
