
一种基于Bagging-SVM的智能传感器集成学习方法
2016-06-13 09:09沈海斌
传感器与微系统 2016年2期
关键词:支持向量机
佘 斌, 沈海斌
(浙江大学 超大规模集成电路设计研究所,浙江 杭州 310027)
一种基于Bagging-SVM的智能传感器集成学习方法
佘斌, 沈海斌
(浙江大学 超大规模集成电路设计研究所,浙江 杭州 310027)
摘要:集成多个传感器的智能片上系统(SoC)在物联网得到了广泛的应用。在融合多个传感器数据的分类算法方面,传统的支持向量机(SVM)单分类器不能直接对传感器数据流进行小样本增量学习。针对上述问题,提出一种基于Bagging-SVM的集成增量算法,该算法通过在增量数据中采用Bootstrap方式抽取训练集,构造能够反映新信息变化的集成分类器,然后将新老分类器集成,实现集成增量学习。实验结果表明:该算法相比SVM单分类器能够有效降低分类误差,提高分类准确率,且具有较好的泛化能力,可以满足当下智能传感器系统基于小样本数据流的在线学习需求。
关键词:智能传感器; 集成学习; 增量学习; 支持向量机; Bagging算法
0引言
目前,以传感器技术与机器学习为基础发展出来的智能硬件已经广泛应用到人们生活的方方面面,如智能手环、智能家居、智能医疗设备等。尤其是随着集成电路工艺的不断进步,集成多个传感器的片上系统(system on chip,SoC)已成为一种发展趋势,因此,有必要对以传感器技术与机器学习结合为基础的智能传感器[1]SoC系统进行研究。
支持向量机(support vector machine,SVM)[2]技术是常见的多传感器数据融合算法,该分类算法能够利用小样本数据进行学习分类,具有较好的泛化性能。但是,单个SVM分类器无法对传感器数据流进行增量学习,因此,需要利用新样本对已有的单分类器的参数与内部结构进行调整,使分类器能够适应新样本。但是,在内部结构调整时,机上需要人为设定一些参数,并且这些参数对算法的影响很大,容易出现过适应的问题。而集成式增量学习[3]则能够有效避免上述缺陷,具有预测准确度高、对训练数据的分布与次序不敏感、泛化性能好等优点。
目前,关于机器学习的文献很多,针对智能传感器SoC的研究文献并不多。适应于智能传感器SoC的集成式增量学习,当前最成熟的两种方法分别为基于Boosting技术与基于Bagging技术而发展出来的一系列算法[4]。文献[5]则是采用了基于Boosting技术而发展出来的Learn++算法对于智能传感器的数据融合进行了研究。该算法各轮基分类器训练数据集与前面各轮的学习结果相关,因此,只能串行运算,需要耗费大量的时间,只能满足实时性要求较低的智能传感器系统需求。而基于Bagging的集成算法的各轮训练集之间相互独立,能并行产生训练数据集,适合并行计算,这点在多核智能传感器SoC中的速度优势将会更加明显。因此,本文提出了一种适应于智能传感器SoC小样本数据流增量学习的Bagging-SVM集成式增量学习算法。
1智能传感器SoC模型
集MCU、加速度计、陀螺仪、磁力计、温湿度传感器等各种传感器于一身的SoC已成为一种发展趋势。其示意图如图1所示。
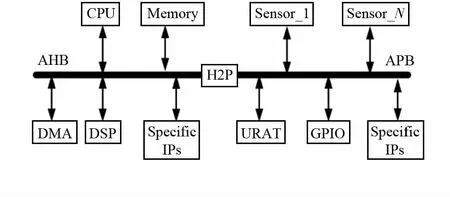
图1 多传感器SoC示意图Fig 1 Diagram of multi-sensor SoC
传感器在SoC中会产生大量数据,并且会随着时间的积累,数据量会越来越大。为了有效地管理和利用这些数据,需要对它们进行学习、分类。在智能传感器系统中,传感器的数据流是随时间产生的,在训练时不可能一次将所有的数据准备好,因此,只能逐步将所获取的样本中包含的信息纳入学习系统中,也就是进行小样本增量学习。
对于集成多个传感器的SoC,由于片内存储和带宽资源所限,对训练和决策算法有如下要求:1)算法计算规模适中,收敛速度快;2)预测准确度高;3)算法稳定性和泛化能力强;4)传感器时时刻刻都在产生数据,能够在已有数据的基础上学习新的数据,亦即是能够进行增量学习。基于Bagging-SVM的集成式增量学习算法恰好满足上述要求,可以适应智能传感器SoC的小样本增量学习。
2基于SVM的集成式增量学习算法
2.1SVM 理论
SVM是建立在统计学习理论的VC维理论和结构风险最小化原理基础上的,能较好解决小样本、非线性、高维数和局部极小点等实际问题,具有较高泛化性能的学习算法。
SVM可以描述为如下有约束的二次优化问题
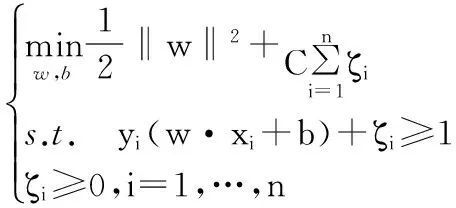
其对偶问题为
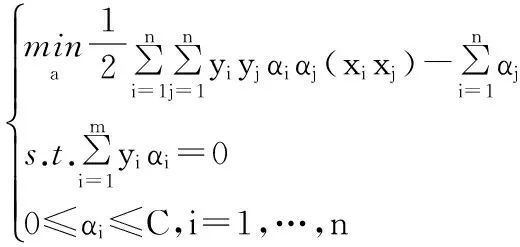
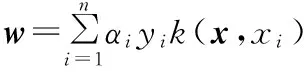
虽然SVM具有上述优点,但是在传感器网络中由于训练样本是随着时间的增加而逐步增加的,运用SVM算法来训练样本,其在保留原有的学习基础上无法再继续学习新类,这就导致了该算法在实时系统中的应用受到限制,而集成式增量学习能够有效避免上述缺陷。
2.2构造Bagging-SVM增量学习算法
集成学习(ensember learning)[6]是指利用数据集获得多个训练子集,通过对每个数据子集训练获得基分类器,然后将这些基分类器按照某种方式组合起来产生一个新的集成分类器。在对样本集进行训练时,集成学习通过综合各个基分类器的预测效果得到最终的决策结果。研究表明[7]:集成学习比传统的单分类器方法在提高学习系统的分类预测性能上更为有效。
Bagging算法是通过对训练数据集使用Bootstrap[8]放回式随机重采样来抽取训练样本集,利用这些样本集训练基分类器,从而创建集成分类器。下面给出构建Bagging-SVM增量算法的过程:
1)对于每个新增的样本集Sinc,首先通过Bootstrap重采样获得一个新的训练样本集Sk,然后利用SVM算法对Sk进行学习,获得基分类器Hk。
2)采用Bagging算法产生规模为K的一个基分类器集合Hinc,然后将Hinc与原来已有的基分类器集合Ho合并,得到新的集成分类器Hnew,即,Hnew=Ho∪Hinc。
集成式增量学习算法步骤:
输入:Sinc:增量数据样本集;
K:设定的增量集成分类器大小;
Ho:每一次增量训练前的目标集成分类器;
输出:Hnew:每一次增量训练后新的目标集成分类器;
基分类器训练算法为SVM。
训练阶段:
步骤 1:初始化,设定增量集成分类器为空集,即Hinc=Null。

Fork=1 toKdo
1)通过Bootstrap重采样,从Sinc中得到训练样本集Sk;
2)对数据集Sk进行SVM训练,获得基分类器Hk;
3)将新得到的基分类器与原来的基分器合并,即Hinc=Hinc∪{Hk}。
步骤3:将增量数据集训练得到的分类器集合与增量运算前的分类器集合合并得到新的分类器集合,Hnew=Ho∪Hinc,输出Hnew。
对于未知样本使用当前分类器进行分类时,在Hnew中的每一个基分类器都会得到一个分类结果,然后让所有的分类器进行投票,得票数最多的类别即为未知样本的分类结果。
3实验与分析
实验分别从集成分类器与单分类器的性能对比,集成增量学习与集成非增量学习的性能对比,集成学习的基分类器规模对正确率的影响3个方面来做研究。实验数据来源于UCI标准机器学习库中的4个数据样本集,实验平台配置为:酷睿i3(3.30 GHz),2 GB内存,Matlab2013b。
3.1实验数据设置
每个样本集随机取出一部分作为测试集,剩余的部分在没有进行增量学习的情况下整体用来作为训练集,若是进行增量学习,则将其均分成若干份作为增量集。
样本集设置如下:
1)Blance-scale数据集有625个样本,随机选取145个作为测试集,剩余480个作为训练集。
2)Ionosphere数据集有351个样本,随机选取81个作为测试集,剩余270个作为训练集。
3)Iris数据集有150个样本,随机选取30个作为测试集,剩余120个作为训练集。
4)Breast数据集有683个样本,随机选取173个作为测试集,剩余510个作为训练集。
以上4个数据集,在增量过程中,则将训练集随机均分成三份。每次取其中一份用来作为增量训练集,产生集成分类器,测试性能,到此,一轮增量学习结束。接着开始下一轮增量学习,直至所有的增量集训练完成。
3.2实验结果分析
算法1采用单个SVM分类器对所有样本进行训练,记为SVM;算法2 则是利用Bagging算法对SVM基分类器进行集成(分类器数目为20个),记为BSVM,其正确率如表1所示;表2则是对4个数据集采用增量算法(Bootstrap 采样为10次,即数据子集的基分类器为10个),分3批次学习,分别计算其正确率,其增量学习过程分别记为BSVM(1),BSVM(2),BSVM(3)。为了消除随机性,统计数据采用上述过程10次的平均值。
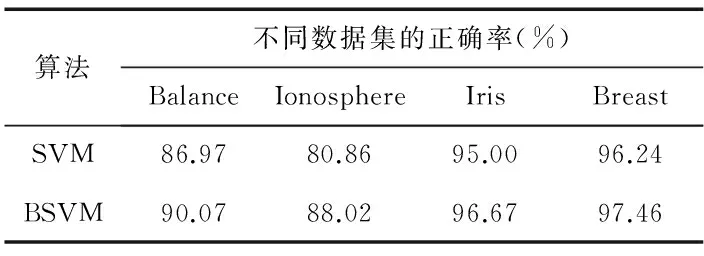
表1 2种算法性能对比
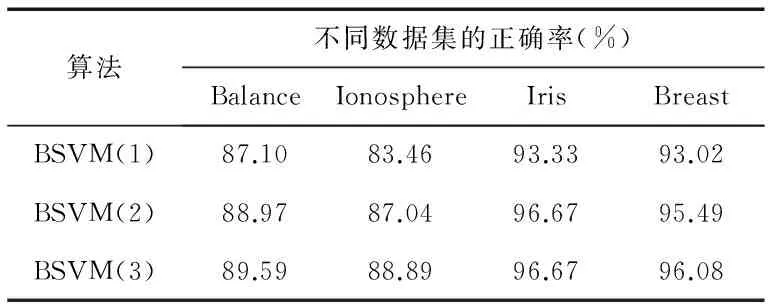
表2 增量学习分类精度
从表1中可以看出:相比于单个SVM分类器,Bagging-SVM集成算法的分类精度有了明显的提高,有效地证明了采用Bagging算法可以通过对样本集的独立采样,使得基分类器的差异性得到提高,整个集成分类器具有更好的泛化能力,能够改善分类性能;表2是每个数据集经过3次增量学习的结果,可以发现,一方面其分类精度总体上随着增量学习次数的增加略有提高,这是因为随着增量次数的增加,基分类器的泛化性能随着个数增加而得到提高,算法性能得以改善。另一方面也证明该算法具备增量学习能力,可以有效应对智能传感器数据流样本的学习与训练。
将Ionosphere数据集应用于集成学习时分类器个数对分类精度的影响如图2所示,可以发现在分类器数目较少时,精度随着分类器增多上升明显,后面变化趋势则很缓慢,略有上升。那么是否基分类器数量越多预测准确度越高,文献[10]指出当各个基分类器差异性越大,集成的效果越好,基分类器的数目应当随着类别的数目的增加而增加。实际上,对于智能传感器SoC,由于片内总线带宽和存储资源有限,因此,控制集成学习分类器的规模就显得很有必要,必须针对应用场合的数据集特点选取恰当的分类器数目。
4结论
本文针对智能传感器SoC在智能学习方面,提出了一种基于Bagging-SVM的集成算法,将SVM算法作为基分类器,能够针对小样本数据进行分类;而Bagging算法的独立重采样机制,对于增量样本所包含的新特征能够在增量集成分类器中将其融入进来,因此,可以持续学习并保证针对逐渐变化的样本集保持较高的分类正确率,适应智能传感器数据流的增量学习。
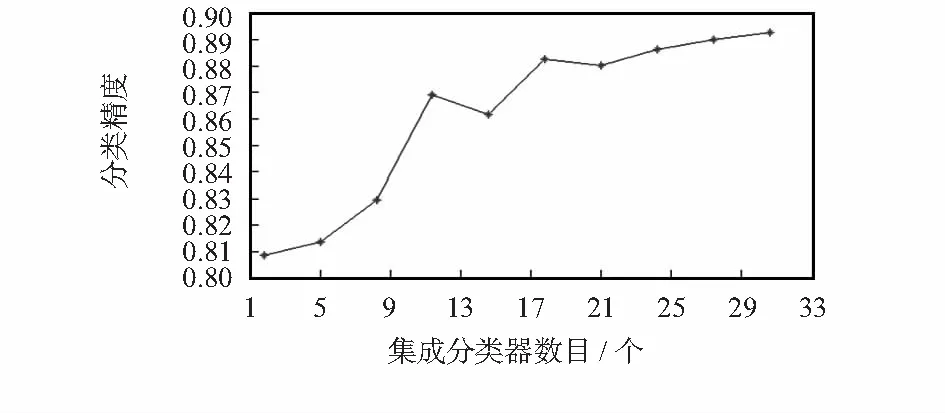
图2 分类器个数对分类精度的影响Fig 2 Influence of number of classifiers on classification precision
随着增量学习的进行,集成分类器的规模将持续增大,对于资源有限的智能传感器SoC,这将是不可接受的。因此,必须针对基分类器采取淘汰机制,让其规模在训练前后保持在适当大小,而不是任其规模随时间的增加而不断变大。这涉及到选择性集成的研究[10],将是今后研究方向。
参考文献:
[1]何金田,刘晓旻.智能传感器原理,设计与应用[M].北京:电子工业出版社,2012.
[2]丁世飞,齐丙娟,谭红艳.支持向量机理论与算法研究综述[J].北京:电子科技大学学报,2011,40(1):2-10.
[3]Oza N C,Russell S.Online bagging and boosting[C]∥IEEE In-ternational Conference on Systems,Man & Cybernetics,IEEE,2005:2340-2345.
[4]Bauer E,Kohavi R.An empirical comparison of voting classification algorithms:Bagging,boosting,and variants[J].Machine Learning,1999,36(1/2):105-139.
[5]卞桂龙,丁毅,沈海斌.适用于智能传感器系统的 SVM 集成研究[J].传感器与微系统,2014,33(8):44-47.
[6]Dietterich T G.Ensemble learning[J].The Handbook of Brain Theory and Neural Networks,2002,2:110-125.
[7]程丽丽.支持向量机集成学习算法研究[D].哈尔滨:哈尔滨工程大学,2009.
[8]Bühlmann P.Handbook of Computational Statistics[M].Berlin Heidelberg:Springer,2012:985-1022.
[9]Wang S,Yao X.Relationships between diversity of classification ensembles and single-class performance measures[J].IEEE Transactions on Knowledge & Data Engineering,2013,25(1):206-219.
[10] 张春霞,张讲社.选择性集成学习算法综述[J].计算机学报,2011,34(8):1399-1410.
An ensemble learning method based on Bagging-SVM for intelligent sensor
SHE Bin, SHEN Hai-bin
(Institute of VLSI Design,Zhejiang University,Hangzhou 310027,China)
Abstract:Intelligent system on chip(SoC) which integrates multiple sensors has been widely applied in Internet of Things.However,considering data fusion of multiple sensors,traditional SVM single-classifier can’t directly support small sample incremental learning for sensor data stream.Aiming at above problem,put forward a kind of ensemble incremental algorithm based on Bagging-SVM,the algorithm supports incremental learning by combining original ensemble classifiers with the new ones which can reflect new information change of incremental data sets,while the new classifiers trained by the data sets which is extracted from incremental data sets by Bootstrap means.Experimental results show that the algorithm compared with the single-classifier can effectively decrease classification error,improve classification accuracy and has good generalization ability,which can smoothly meet requirements of intelligent sensor system for online learning based on small sample data flow.
Key words:intelligent sensor; ensemble learning; incremental learning; support vector machine(SVM);Bagging algorithm
DOI:10.13873/J.1000—9787(2016)02—0026—03
收稿日期:2015—05—20
中图分类号:TP 18; TP 212
文献标识码:A
文章编号:1000—9787(2016)02—0026—03
作者简介:
佘斌(1990-),男,湖南邵阳人,硕士研究生,研究方向为智能安全与芯片设计。
猜你喜欢
现代电子技术(2016年23期)2017-01-12
现代电子技术(2016年23期)2017-01-12
无线互联科技(2016年13期)2017-01-10
中国水运(2016年11期)2017-01-04
软件导刊(2016年11期)2016-12-22
电子技术与软件工程(2016年20期)2016-12-21
价值工程(2016年32期)2016-12-20
价值工程(2016年29期)2016-11-14
科学与财富(2016年28期)2016-10-14
考试周刊(2016年53期)2016-07-15
