
基于AMR-WB线谱频率参数的隐写算法
2016-06-08 06:07冯浩楠
计算机应用与软件 2016年5期
滕 达 冯浩楠
1(中国铁道科学研究院通信信号研究所 北京 100081)2(中国铁道科学研究院铁道技术研修学院 北京 100081)
基于AMR-WB线谱频率参数的隐写算法
滕达1,2冯浩楠1
1(中国铁道科学研究院通信信号研究所北京 100081)2(中国铁道科学研究院铁道技术研修学院北京 100081)
摘要AMR-WB(Adaptive Multi-Rate-Wideband)的线谱频率LSF(Line Spectrum Frequency)参数在编码过程中会分裂为若干子矢量。利用编解码过程中的ISF索引参数,提出一种在3G话音中隐藏信息的算法。该算法首先选择用于信息隐藏的LSF索引段,然后通过修改所选的LSF索引段进行信息隐藏。实验结果表明,改变特定LSF索引会在较少影响话音质量的同时隐藏信息,该算法在具有较好隐蔽性的同时又能较少影响语音质量。
关键词线谱频率AMR-WB信息隐藏
0引言
自适应多速率宽带编码AMR-WB是一种同时被国际标准化组织ITU-T和3GPP采用的宽带语音编码标准[1]。AMR-WB处理的音频是采样率为16 kHz的语音信号,具有6.60、8.85、12.65、14.25、15.85、18.25、19.85、23.05和23.85 kbps总共9种不同的速率,对于这9种不同速率的语音,经过AMR-WB编码后,每一帧的长度分别为132、177、253、285、317、365、397、461和477比特[2]。
线性预测LP(Linear Prediction)是语音信号处理中的关键技术,而LP系数是语音识别中重要的信息来源[3]。语音信号处理中普遍使用的是与LP系数在数学角度上完全等价的LSP(Line Spectral Pair)系数[4]。比起LP系数,LSP系数具有更优的量化特性、内插特性以及鲁棒性,与语音的短时谱包络紧密相关,并且LSP系数具有良好的动态范围,容易保证滤波器的稳定性。因此LSP系数在语音信号处理领域中得到了广泛应用[5]。
在LP系数向LSP系数转换的过程中,线谱频率LSF参数可以用来描述LSP系数的频域值[6]。在自适应多速率宽带编码AMR-WB的各种参数中,LSF参数也可以用来隐藏信息,选取特定LSF参数中的索引段,并在其中嵌入信息,然后选取嵌入后语音质量降低较少的LSF索引用于信息隐藏[7]。
1LSF参数的定义
在AMR-WB编码阶段,首先进行线性预测(LP)计算得到LP系数,再将LP系数通过LSF系数来转化为LSP系数,最后量化LSP系数并编码。通过在频域上使用LSP表达式来量化低通滤波器系数,即:
(1)
(2)
其中fi代表频率从0到6400 Hz的LSF参数,fs代表的是12.8 kHz的采样率。[f1…f15]组成了一个LSF向量ft,ft是矢量的转置。
在得到LSF向量后,需要量化残差LSF向量,这时要结合分裂矢量量化和多阶矢量量化的方法来使用一个一阶的移动平均预测器。具体的预测和量化过程如下所示:预测残差矢量r(n)的计算如下:
r(n)=z(n)-p(n)
(3)
z(n)=fn-average(n)
(4)
(5)
其中z(n)代表去掉当前帧均值的LSF矢量,其中average(n)是统计数据,r(n-1)是当前语音帧之前语音帧的量化残差矢量。
然后是通过S-SMVQ量化器来量化残差矢量r(n),这样残差矢量r(n)被分裂成了两个子向量r1(n)和r2(n)。其中r1(n)向量的长度为9 比特,r2(n)向量的长度为7比特。接着需量化这两个子向量,步骤如下:(1) 分别将r1(n)向量和r2(n)向量量化为8比特;(2) 将r1(n) 向量分裂成3个3维的子矢量,分别以6、7和7比特进行量化编码,将r2(n)向量分裂为一个4维和一个3维的子矢量,都以5比特进行量化编码。通过这一系列的计算过程,得到了46比特的LSF索引[8]。
2算法思想
在LSF参数经过量化编码的过程之后,LSF参数总共被量化编码为5或者7部分,在非6.60 kbps的模式下,LSF参数被量化为7段,其长度分别为8、8、6、7、7、5和5比特,总共有46比特的长度。而在6.60 kbps的模式下,LSF参数被量化成5段,其长度分别为8、8、7、7和6比特,总共36比特的长度。
接收端接到语音信号的比特流之后,对其解码可以得到诸如基音索引参数、滤波器索引参数、固定码本索引参数、增益矢量索引参数、LSF索引参数和高频增益索引参数。接收端通过这些索引参数的顺序解码,就可以得到LSF索引参数。这些LSF参数在不同速率模式下被分为若干段,并且每一段的参数都有一定的长度,因此我们的想法是通过改变LSF参数来进行隐藏信息。在解码端,将隐藏的信息进行特定的编码后,通过改变LSF参数来将信息隐藏在LSF参数中。接受者通过解析LSF参数来得到发送端传送的隐秘信息。隐藏信息后,LSF参数被改变,在解码端进行语音重构的时候,必然会损失一部分语音的声音质量,如何有效使用这七段LSF参数进行隐藏信息是一个关键问题。
在非6.60 kbps速率模式下,LSF共有7段,将这7段LSF索引参数编号为1-7段,其中第一段对应于r1(n)向量量化的8比特LSF索引段,第二段对应于r2(n)向量量化的8比特LSF索引段,r1(n)裂化产生的6、7和7比特段分别编号为3-5段,r2(n)向量裂化产生的两个5比特LSF索引段被编号为6-7段。在6.60 kbps速率模式下,LSF共有5段,r1(n)向量量化产生的8比特LSF索引段被编号为第1段,r2(n)向量量化产生的8比特LSF索引段被编号为第2段,剩下的两个7比特和一个6比特LSF索引段被编号为3-5段。因此算法的基本思想为在保持其他几段LSF索引参数不变的基础下,分别改变这七段LSF参数进行信息隐藏,通过PESQ算法的测试,来选取最佳的LSF索引段进行信息隐藏。
3嵌入算法
3.1预处理
首先生成一个包含50项偏移值的偏移值表Table,每一项Tablei编码大小为2比特,值是随机产生的,范围介于0到3之间。然后将该偏移值表嵌入到某一秒语音信号的基音周期中,通信双方经过事先的约定,选定该秒语音并将该表隐藏。
3.2嵌入速率为50 bps的嵌入算法

算法输入:比特流Strm,偏移值表Table[50],选定的LSF索引段Ii。
算法输出:Ii。
算法具体执行步骤:
Step1令BitLi=Strmi+Tablei,得到BitL[50]i;

Step3如果BitLj==0,转到Step 4;如果BitLj==1,则转到Step 5;
Step6如果j<49,那么j=j+1,转到Step 3;否则转到Step 7;
假设需要隐藏的比特流Strm包含m段长度为50比特的数据,由以上算法描述可以计算得出每一段比特流需要一个计算50次的循环,那么隐藏Strm的算法时间复杂度为O(n2),空间复杂度为O(n)。
3.3嵌入速率为100 bps的嵌入算法
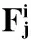
(6)
(7)
算法输入:比特流Strm,偏移值表Table[50],选定的LSF索引段Ii。
算法输出:选定的LSF索引段Ii。
算法具体执行步骤:
Step1令FbitLi=Strmi+Tablei,得到FbitL[50]i;

Step5如果j<49,那么j=j+1,转到Step 3;否则转到Step 6;
假设需要隐藏的比特流Strm包含m段长度为100比特的数据,由以上算法描述可以计算得出每一段比特流需要一个计算50次的循环,在100 bps速率下隐藏算法时间复杂度为O(n2),空间复杂度为O(n)。
4提取算法
接收端收到比特流之后,从中提取出带有隐藏信息的LSF索引段,再利用提取算法从LSF参数索引段中提取所隐藏的信息,最后再进行语音的重构。单LSF参数索引段提取算法如下:对于某一语音帧,将隐藏信息的LSF索引值根据实际要求做模m运算(m=2或4),结果n(n=0,1或者0,1,2,3)即为该语音帧LSF索引段隐藏的数据。通过解码特定语音帧可以获取偏移值表,将得到的所有隐藏信息每一项与偏移值表进行二进制加法运算。最后通过置换和最终的编码后,得到隐藏信息。提取算法是嵌入算法的反向运算,因此不再进行详细说明,提取算法的时间复杂度为O(n2),空间复杂度为O(n)。
5实验结果
5.1嵌入速率为50 bps单LSF参数索引段隐藏算法的实验结果
(1) 6.60 kbps速率下实验结果
在6.60 kbps速率模式下,LSF参数被量成5段,分别使用这5段LSF参数索引段进行信息隐藏,并使用PESQ算法测得MOS差值,具体结果如表1所示。

表1 6.60 kbps速率下实验结果
实验结果表明,在6.60 kbps速率模式下,使用第1、2、4段LSF参数索引的信息隐藏对语音的质量影响比较小,与原语音MOS值的相差不超过0.1,而使用第3、5段的信息隐藏会使语音质量下降较多。
(2) 非6.60 kbps速率模式下实验结果
在非6.60 kbps速率模式下,LSF参数索引段被量化为7段,分别使用7段LSF参数索引段进行信息隐藏,并使用PESQ算法测得MOS差值,具体结果如表2所示。

表2 50 bps速率下实验结果
实验结果表明,在非6.60 kbps速率模式下,使用第1、2、3、4、6段LSF索引参数进行信息隐藏所造成的MOS差值小于0.1,而使用第5、7段LSF参数索引进行信息隐藏所造成的MOS差值较高,因而使语音质量严重下降。
5.2100 bps速率下单LSF隐藏算法实验结果
(1) 6.60 kbps模式下试验结果
如表3所示,在6.60 kbps速率模式下,使用第1、2、4段LSF索引进行信息隐藏对语音质量的影响较小。

表3 6.60kbps模式实验结果
(2) 非6.60 kbps速率模式下的结果
如表4所示,实验结果表明在单LSF索引参数隐藏的算法中,使用第1、2、3、4、6段LSF进行信息隐藏,MOS值的减少均小于0.1,声音质量较小。

表4 单100bps速率下实验结果
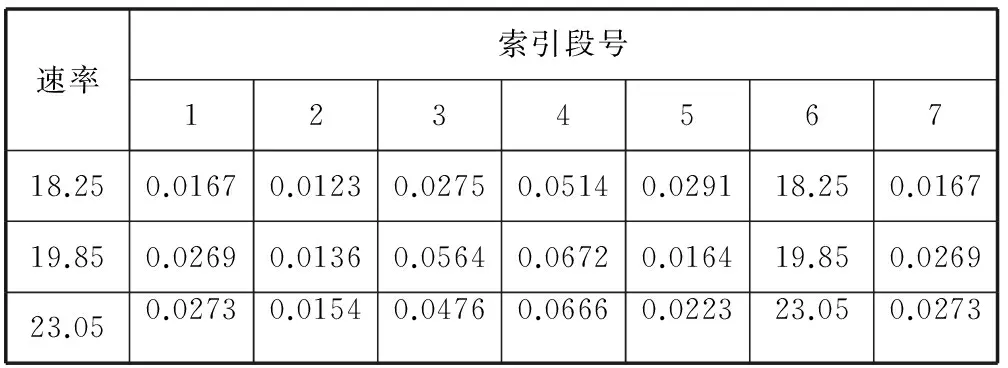
续表4
6结语
AMR-WB语音编解码的过程中,在6.60 kbps速率模式下,LSF被裂化为了5段;在非6.60 kbps速率模式下,LSF索引被裂化为了7段。本文在不同速率模式下,使用编解码过程中的LSF索引参数,提出了一种在语音信号中隐藏信息的算法。该算法首先需要选择进行信息隐藏的LSF索引段,然后通过修改选择的LSF索引段的LSF参数进行信息隐藏。实验表明,语音信号中特定LSF索引参数的改变较少影响话音质量,正常通话的过程中难以分辨,具有良好的隐蔽性。
参考文献
[1] Zhang C L,Zhao S H,Xiao H Y,et al.An improved method for AMR-WB speech codec[J].Advanced Materials Research,2013(756-759):1259-1263.
[2] 解廷福,杨果,王晶.基于算术编码的AMR—WB参数变速率压缩[J].电声技术,2013,37(7):48-51.
[3] 高建敏,施海彬,唐骏.一种快速的固定码本搜索方法[J].计算机工程,2011,37(8):265-267.
[4] Zhou J,Yang Z,Niu X X,et al.Research on the detecting algorithm of text document information hiding[J].Journal of China Institute of Communications,2004,25(12):97-101.
[5] Yu Z,Huang L,Chen Z,et al.High Embedding Ratio Text Steganography by Ci-Poetry of the Song Dynasty[J].Journal of Chinese Information Processing,2009(4):55-62.
[6] Feng Dengguo.Status quo and trend of cryptography [J].Journal of China Institute of Communications,2002,23(5):18-26.
[7] Faisal Alturki.Theory and applications of data hiding in still images[D].School of Mechamical Engineer,Georgia Institute of Technology,2001.
[8] Kadambe S,Boudreaux-Barrels G F.Application of the wavelet transform for pitch detection of speech signals[J].IEEE Transactions on Information Theory,1992,38(2):917-924.
A STEGANOGRAPHY ALGORITHM BASED ON LINE SPECTRUM FREQUENCY PARAMETERS OF AMR-WB
Teng Da1,2Feng Haonan1
1(SignalandCommunicationResearchInstitute,ChinaAcademyofRailwayScience,Beijing100081,China)2(RailwayTechnologyResearchCollege,ChinaAcademyofRailwayScience,Beijing100081,China)
AbstractIn encoding process, the parameters of line spectrum frequency (LSF) of AMR-WB (Adaptive Multi-Rate-Wideband) will be split into several sub-vectors called LSF indexes. This paper proposes an algorithm of hiding information in 3G speech by using the LSF index parameters in encoding/decoding process. The algorithm chooses the LSF index sections for information hiding first, and then hides the information by making modifications on these selected index sections. Experimental results show that to modify certain LSF indexes can lead to information hiding with little degradation of speech quality. Therefore this information hiding algorithm has good concealment quality while degrades little in voice quality as well.
KeywordsLine spectrum frequencyAMR-WBInformation hiding
收稿日期:2014-10-29。滕达,博士生,主研领域:交通信息工程与控制,无线通信。冯浩楠,助理研究员。
中图分类号TP393.17
文献标识码A
DOI:10.3969/j.issn.1000-386x.2016.05.069
猜你喜欢
四川轻化工大学学报(自然科学版)(2021年1期)2021-06-09
汉字汉语研究(2020年2期)2020-08-13
电子制作(2019年22期)2020-01-14
阅读(快乐英语高年级)(2019年5期)2019-09-10
电子制作(2019年14期)2019-08-20
电子制作(2019年9期)2019-05-30
疯狂英语·新读写(2018年3期)2018-11-29
小说界(2018年5期)2018-11-26
海峡姐妹(2017年10期)2017-12-19
三联生活周刊(2017年33期)2017-08-11
