
Hadoop异构集群中数据负载均衡的研究
2016-06-08 06:04:45杜庆伟
计算机应用与软件 2016年5期
张 松 杜庆伟 孙 静 孙 振
1(南京航空航天大学计算机科学与技术学院 江苏 南京 210016)2(中国人民解放军94860部队 江苏 南京 210016)
Hadoop异构集群中数据负载均衡的研究
张松1杜庆伟1孙静2孙振2
1(南京航空航天大学计算机科学与技术学院江苏 南京 210016)2(中国人民解放军94860部队江苏 南京 210016)
摘要Hadoop平台下,数据的负载均衡对平台性能的发挥有着深远的影响。首先分析默认数据负载均衡的局限性,针对现有默认HDFS(Hadoop Distributed File System)数据负载均衡算法只考虑存储空间利用率,而未考虑节点间异构性的问题,提出一种量化异构集群数据负载均衡的数学模型。该模型根据节点的存储空间及节点性能计算得到各个节点的理论空间利用率,并根据当前集群存储空间利用率动态调整节点最大负载。实验结果表明,提出的数据负载均衡策略能够让异构集群达到更合理的均衡状态,提高集群的效率,并有效减少作业的执行时间。
关键词HadoopHDFS数据负载均衡异构集群
0引言
随着计算机技术和信息技术的飞速发展,在科研和商业领域产生了越来越规模巨大的数据,这些数据的规模甚至达到了若干PB。单台节点显然已经无法处理如此规模巨大的数据,云计算在此背景下应运而生。Hadoop是一个由Apache基金会所开发的开源分布式处理系统[1]。该系统由若干节点组成,数据分布在各个节点上。用户提交作业后,Hadoop将作业拆分成若干task,然后分布到各个节点上运行,最后将结果汇总返回给用户。
在Hadoop等数据密集型的超级计算中,移动数据的代价要远远高于移动计算的代价。因此将计算移动到数据节点上,将大大节省网络带宽,提升作业的执行效率。数据负载均衡的集群,能够降低非本地化任务的次数,进而减少集群中数据传输量,提高系统效率[2]。
然而随着新的数据节点的加入以及用户对集群中文件的动态删除和添加,使得各个节点拥有的数据量变得不均衡。当集群中节点间的数据负载变得不均衡后,会引发许多问题。比如,MapReduce程序无法很好地利用本地计算的优势,计算任务被分配到非本地化执行的概率增大,于是节点不得不从其他节点复制数据,增加网络负载。节点之间无法达到更好的网络带宽使用率,各节点磁盘无法达到更好的利用率,这将间接导致集群的效率降低,作业的执行时间变长。可见,保证Hadoop集群的数据平衡是非常重要是事情,数据的负载均衡已经成为分布式计算的一个重要的研究领域[3-5]。
文献[6]对异构集群负载均衡以及文件响应时间进行了初步研究,但忽略了异构集群中节点容量的异构性。文献[7]提出了按比例存放数据的策略,该策略考虑到了节点的异构性,然而却忽略了节点存储空间的异构性对数据存放的影响。文献[8]在Hadoop数据负载均衡效率方面,提出了超负载机架的优先处理,能够在较短时间内使各个机架的数据负载达到平衡,但并没有考虑节点的异构性。文献[9]改进了副本管理技术,通过动态副本来解决数据热点的问题。
本文首先分析了默认负载均衡的原理及其局限性,然后提出了适用于异构集群的负载均衡的量化模型。最后通过大量实验证明了在特定环境下该模型能够更合理的降低集群的不均衡性,提高集群的效率,并有效减少作业的执行时间。
1默认负载均衡原理及其局限性
默认的负载均衡策略是基于所有节点都是同构节点这样一个假设下的。同构集群下,由于节点的硬件配置,包括CPU、内存、磁盘容量等都是一样的,唯一不一样的参数为各个节点的存储空间利用率。负载均衡的目的就是将各个节点的存储空间利用率尽量达到一致。当集群中的部分datanode承载了过多的数据时,集群管理员便应该通过start-balancer.sh启动均衡器,来重新布局数据块。Balancer负载均衡程序根据用户提交的阈值(threshold)(默认为10%),将DataNode按照存储空间的利用率分为四组:分别为overUtilizedDatanodes(过载的节点信息)、aboveAvgUtilizedDatanodes(大于阈值的节点信息)、belowAvgUtilizedDatanodes(小于阈值的节点信息)、underUtilizedDatanodes(空载的节点信息)。负载均衡的主要过程是将过载节点和大于阈值的节点数据往空载节点和小于阈值的节点移动,最终使得各个节点的存储空间的利用率偏离集群平均存储空间利用率在阈值以内。
在同构集群中,该负载均衡策略简单并可获得较好的效果。但是在异构集群中,由于节点的硬件配置有可能相差很大,性能高的节点显然可以处理更多的数据。各个节点分配给HDFS的可用空间也有可能相差几倍,将异构集群中各个节点的存储空间利用率均衡到尽量一致并不能达到负载均衡的效果。分析这样一种情况,假设集群中的节点Na的性能是节点Nb的一半(Pa=1/2 Pb),节点Na的存储空间Da为节点Nb的存储空间Db两倍(Da=2Db),节点Na的存储空间使用率是节点Nb的两倍。即性能低的节点Na的存储空间是性能高的节点的两倍,调用默认负载均衡程序,最终得到的期望结果会是节点Na的存储空间利用率等于节点Nb的存储空间利用率。表面上看两异构节点的存储空间的利用率达到了一个均衡状态,实际上,该操作使得集群变得更加不均衡,性能较低的节点Na获得了更多的数据。这使得低性能节点承担了更多的数据负载,使得该节点在作业执行过程中成为高负载节点,同时增加了非本地化任务的概率,增加了网络流量负载。此时,集群默认的负载均衡策略失效。所以异构集群中通过将各个节点的存储空间利用率均衡到一个一致的期望值来使得集群负载均衡的方法是不可取的。基于对默认负载均衡原理及其局限性的分析,我们提出了一种适用于异构集群中量化数据负载均衡的数学模型。该模型基于各个节点的性能及存储空间计算得出各个节点的理论空间利用率。
2异构集群负载均衡量化模型
2.1问题描述
异构集群的异构性不仅体现在高性能节点处理相同的工作消耗更少的时间,还体现在各节点分配给Hadoop使用的存储空间之间的差异性。本文提出的均衡模型基于各节点的性能按比例分配存储容量,而各节点存储空间的异构性可能导致异构集群中节点无法承载理想的存储容量。为此我们提出了一种基于集群异构性的量化负载均衡的数学模型。该模型基于各个节点的性能及存储空间,分别计算得到各个节点的理论磁盘利用率。再将用户输入的threshold参数泛化为各个节点的阈值。最终将异构集群的负载均衡转化为类同构集群的负载均衡,简化异构集群负载均衡问题的复杂性。
2.2相关参数及定义
存储空间(Cconf(i)):某节点分配给HDFS使用的容量,而非节点磁盘容量,Cconf(i)表示第i个节点的配置容量。
已用容量(Cused(i)):某个节点的存储空间中HDFS使用的容量,Cused(i)表示第i个节点的已用容量。
节点的CPU性能(Pcpu(i)):由于多核的性能是无法达到1+1=2的效果。查阅相关资料得知,比较理想的情况下,双核的每个核的性能为单核的0.8~0.9。所以我们取多核CPU转换参数ρ=0.8。得到节点的CPU性能为:
Pcpu(i)=ρ×(Ncore(i)-1)×F(i)+F(i)
(1)
其中Ncore(i)为节点的CPU核数,F(i)为节点的CPU频率(单位GHZ),ρ为多核CPU转换参数。
节点的内存性能(Pmem(i)):对于节点内存的衡量,采用Pmem(i)=Nmem(i),其中Nmem(i)为节点i的内存的大小(单位为MB)。
定义1节点相对性能:
(2)
式中α和β为CPU性能和内存性能的权重因子,且α+β=1。min(Pcpu),min(Pmen)分别为集群中节点CPU性能和内存性能的最小值。将集群中的所有节点性能统一为最小值为1的量化值,方便后面的计算。并由此计算出节点的性能总和:

(3)
定义2集群的存储空间利用率:
(4)
定义3各节点基于性能的理论存储空间占用容量及各节点基于性能的理论存储空间利用率:
(5)
(6)
定义4节点的动态存储空间最大负载:
M=(0.8 + 0.2×RAvg2)×100%
(7)
由于磁盘空间的异构性,节点的存储空间有时并不能满足理论占用容量的需求,这时,我们需要将该节点理论上多余的数据转移到其他节点。为了确保节点的存储空间占用率不超过某一特定百分比这里我们需要定义一个节点最大负载。该值应该随着集群存储空间利用率的提高而提高。当集群负载较轻的时候,节点的最大负载应该维持在一个低水平上。这里我们采用自定义式(7)来描述节点动态最大负载,M取值范围[80%,100%),并随着集群存储空间利用率Ravg的增大而增大。若Ravg=50%,我们可以得到集群中的单个节点的最大负载为M=85%,若Ravg=50%,则M=96.2%。该公式较好地定义了节点最大负载,解决了节点可能出现的负载过重的问题,避免了用户静态配置导致的参数不适用的问题。
根据节点最大负载和各个节点基于性能的理论利用率,找出那些节点理论利用率大于节点最大负载的节点,并计算出盈余容量,集群盈余容量的计算公式如下:
(8)
式中i=1,2,…,n并且Rideal(i)>M 。然后再将这部分容量分配给其他节点。迭代运行,直到集群中没有节点的理论容量大于节点最大负载值。
在将盈余容量分配给其他节点的过程中,以减少机架间数据传输为目的,我们采用了同机架优先的策略。该策略如下:当前机架内的某节点基于性能的理论利用率高于节点最大负载的时候,优先将该节点的容量分配到该机架的其他节点上。为此,我们定义了一个同一机架和非同一机架的配置比γ=2。该参数的意义在于优先将当前机架盈余出来的容量存放在同一机架的其他节点上,以减少机架与机架之间理论存储空间利用率的差别。最终我们得到一组各个节点基于性能的理论存储空间利用率。
定义5各节点参数化的阈值:
(9)
用户输入的threshold参数值t是集群达到平衡状态的各节点存储空间使用率与集群存储空间使用率的偏差值的最大值。如果偏差值小于该值,那么我们认为该节点是均衡的。由于异构集群中,各个节点的存储空间的异构性,该阈值所对应的存储空间及节点性能差别较大,于是我们需要将该阈值根据式(9)参数化为各个节点的阈值。
2.3算法
下面介绍算法的详细步骤。
1) 计算各个节点的相对性能值P(i),节点的性能总和P以及集群的存储空间利用率Ravg。
2) 求出各个节点基于性能的理论占用容量Cidel(i)及基于性能的理论利用率Ridel(i)。
3) 计算集群节点最大负载值M。
4) 根据节点最大负载和各个节点基于性能的理论利用率,找出那些节点理论利用率大于节点最大负载的节点,并计算出盈余容量C_supr。如果没有找到该类节点,转6)。
5) 基于机架的策略,优先将盈余容量分配到同一机架上。然后重新计算各个节点基于性能的理论利用率并转到4)。
6) 将用户输入的threshold 通过式(8)参数化为各个节点的阈值。
7) 根据最终计算得到的各节点基于性能的理论利用率和各节点参数化后的阈值,将集群中的节点分为如表1所示四组。
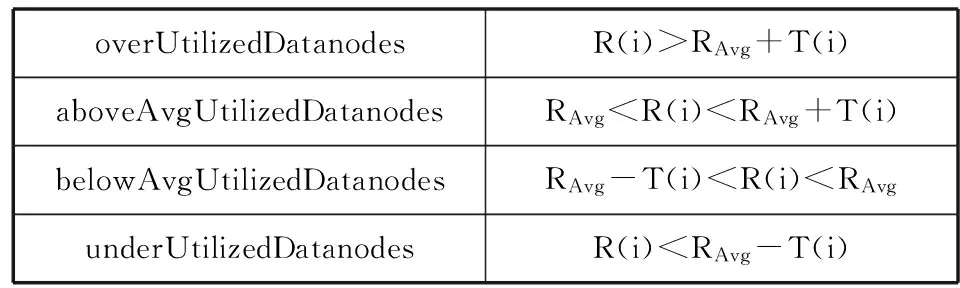
表1 节点分组
8) 计算各节点需要移动的数据量并移动数据。
9) 算法结束。
3实验与结果分析
由于实验环境有限,测试环境由三个机架共9个节点组成。其中机架A中有两个节点,机架B中有四个节点,机架C中有三个节点,Namenode节点位于机架B中编号为3的节点,同时该节点也作为Datanode节点。所有节点都安装为Ubuntu 12.04操作系统。实验环境的网络拓扑如图1所示。
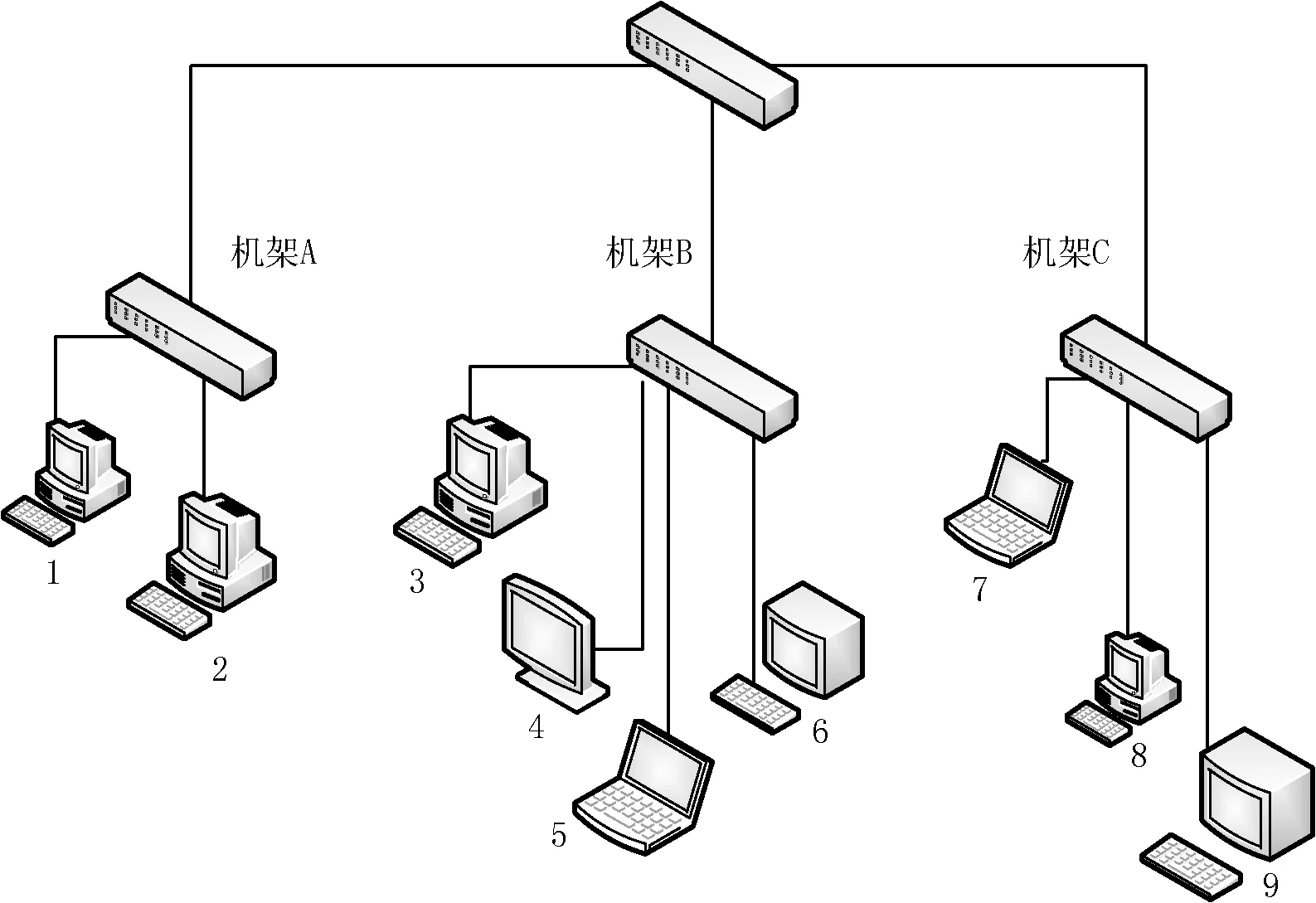
图1 网络拓扑
实验中我们的负载均衡器运行在节点编号为3的节点,即Namenode节点。其中各个节点的硬件配置如表2所示。
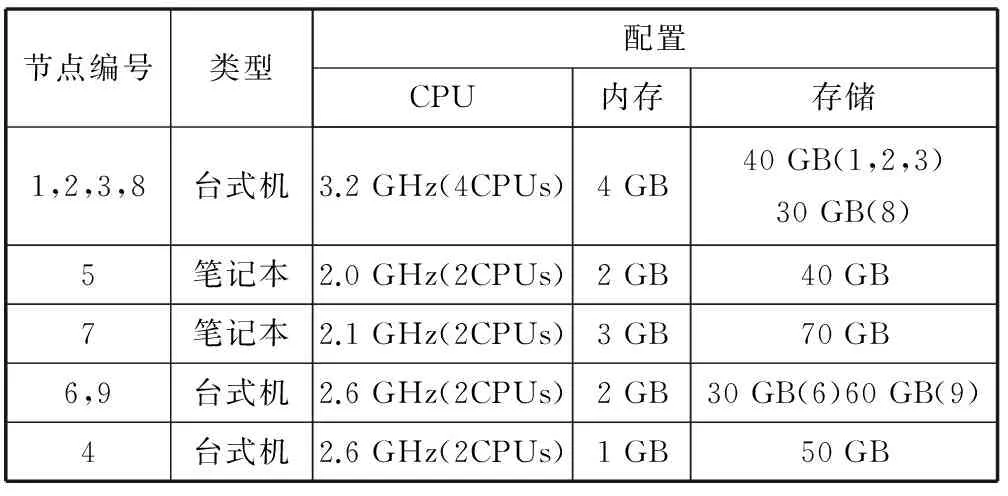
表2 节点硬件配置
为了比较异构集群中HDFS默认的负载均衡器和本文改进的负载均衡器之间的效果差异,我们将数据块的副本数设定为2,并将其中几个节点作为客户端上传文本数据,再删除其中的部分数据使集群处于不均衡的状态。然后分别运行默认负载均衡器和本文改进的负载均衡器,观察均衡效果。同时,我们分别在运行默认负载均衡器后和运行本文改进的负载均衡器后执行Hadoop的WordCount程序,观察程序在各个负载均衡后的执行时间。执行指令start-balancer.sh-threshold 5 ,即将阈值(threshold)设定为百分之5并执行负载均衡器,集群的状态如表3所示。
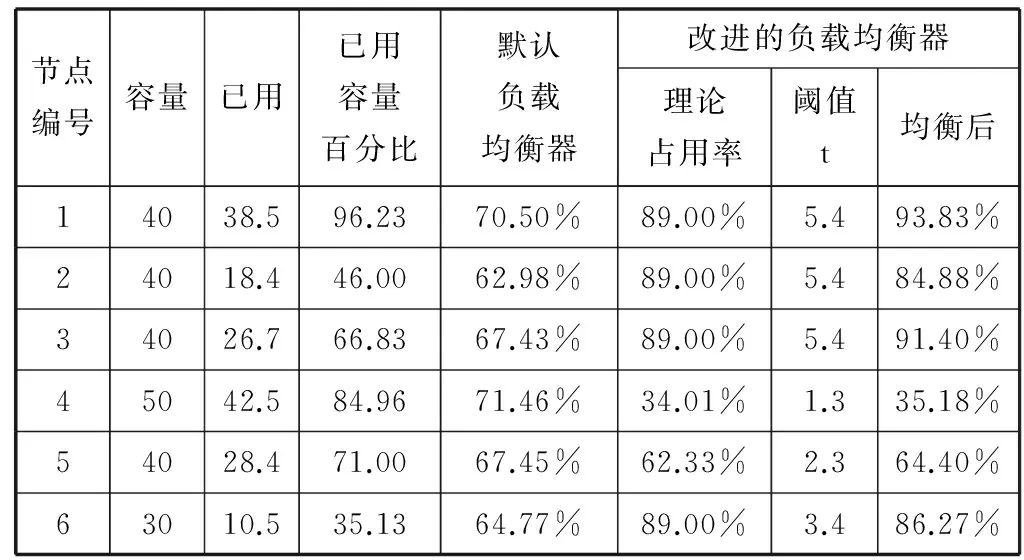
表3 集群负载状态
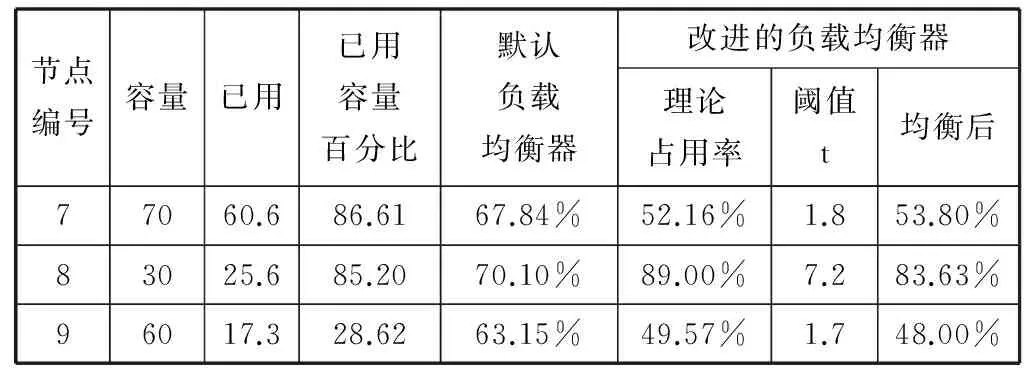
续表3
由表3的数据我们可以看出,改进后的数据负载均衡器能够较好地依据节点的性能调整数据的分布。为了验证本文改进的负载均衡器能够具有较好的数据均衡效果。运行WordCount程序以观察该程序在各状态下的执行时间。WordCount是Hadoop官方的MapReduce的demo程序。WordCount例程读取集群中文本文件,并统计文件中单词出现的频数。不同于蒙特卡罗方法计算π的demo例程,蒙特卡洛发计算π值,对节点的CPU性能要求较高,属于CPU密集型作业,而WordCount程序属于I/O密集型作业,对数据的分布更加敏感。本实验采用节点5作为客户端提交用户WordCount作业20次,观察作业的执行时间,并且作业执行前数据已经分布在集群中。
数据分布均衡的集群,可以有效减少作业调度带来的计算资源和数据资源在不同的物理节点而产生的数据迁移问题,并有效减少网络I/O,降低所谓的“非本地化任务”,缩短作业的执行时间[10, 11]。图2显示了在不同数据负载均衡算法下作业的执行时间,横坐标表示的是我们执行作业的序列号,纵坐标表示的是作业的执行时间。从图中我们可以清楚的看出,相较于默认数据负载均衡算法下作业的执行时间,改进后的数据负载均衡算法可以有效地减少作业的执行时间,提高集群效率。

图2 不同均衡算法下作业的执行时间
4结语
本文分析了集群默认数据负载均衡的局限性,并针对该问题提出了异构集群数据负载均衡的量化模型。该模型通过综合考虑节点性能的异构性和存储空间的异构性求得各个节点存储空间的理论均衡利用率,并将用户输入的阈值量化为各个节点的负载参数。然后移动各个节点的数据,使得各个节点的存储空间利用率与理论均衡利用率的偏差值不大于各个节点的理论阈值。通过实验分析,证明了该模型能够让集群达到更均衡的状态,一定程度上减少了作业的执行时间,提高了集群的整体性能。
后续的研究将继续关注Hadoop异构集群中数据的负载均衡,特别关注集群中作业的执行与数据副本之间的关系。
参考文献
[1] White T.Hadoop:The definitive guide[M].O’Reilly Media,Inc,2012.
[2] 王意洁,孙伟东,周松,等.云计算环境下的分布存储关键技术[J].Journal of Software,2012,23(4):962-986.
[3] Sun H,Chen J,Liu C,et al.Improving MapReduce Performance via Heterogeneity-Load-Aware Partition Function[C]//Cluster Computing(CLUSTER),2011 IEEE International Conference on.IEEE,2011:557-560.
[4] 杨昊溟.云存储系统的数据副本放置算法研究[D].电子科技大学,2013.
[5] 王宁,杨扬,孟坤,等.云计算环境下基于用户体验的成本最优存储策略研究[J].电子学报,2014,42(1):20-27.
[6] 刘琨,钮文良.一种改进的Hadoop数据负载均衡算法[J].河南理工大学学报:自然科学版,2013,32(3):332-336.
[7] Xie J,Yin S,Ruan X,et al.Improving mapreduce performance through data placement in heterogeneous hadoop clusters[C]//Parallel & Distributed Processing,Workshops and Phd Forum (IPDPSW),2010 IEEE International Symposium on.IEEE,2010:1-9.
[8] 刘琨,肖琳,赵海燕.Hadoop中云数据负载均衡算法的研究及优化[J].微电子学与计算机,2012,29(9):18-22.
[9] 陶永才,张宁宁,石磊,等.异构环境下云计算数据副本动态管理研究[J].小型微型计算机系统,2013,34(7):1487-1492.
[10] Ananthanarayanan G,Agarwal S,Kandula S,et al.Scarlett:coping with skewed content popularity in mapreduce clusters[C]//Proceedings of the sixth conference on Computer systems.ACM,2011:287-300.
[11] Wei Q,Veeravalli B,Gong B,et al.CDRM:A cost-effective dynamic replication management scheme for cloud storage cluster[C]//Cluster Computing (CLUSTER),2010 IEEE International Conference on.IEEE,2010:188-196.
RESEARCH ON DATA LOAD BALANCING IN HETEROGENEOUS HADOOP CLUSTER
Zhang Song1Du Qingwei1Sun Jing2Sun Zhen2
1(SchoolofComputerScienceandTechnology,NanjingUniversityofAeronauticsandAstronautics,Nanjing210016,Jiangsu,China)2(Unit94860ofPLA,Nanjing210016,Jiangsu,China)
AbstractIn Hadoop, the data load balancing has profound effect on the exertion of platform performance. First we analysed the limitation of default data load balancing, aiming at the problem of current default HDFS (Hadoop distributed file system) that the data load balancing algorithm only focuses on the storage space utilisation but not considers the heterogeneity between nodes, we presented a mathematic model which quantifies the data load balancing of heterogeneous clusters. The model calculates the theoretical space utilisation of each node based on their allocated storage space and processing capacity, and dynamically adjusts the maximum load of each node according to current average utilisation of cluster storage space. Experimental result showed that the proposed data balancing strategy could enable the heterogeneous clusters to reach more reasonable balancing state so as to improve clusters efficiency, and to decrease the execution time of job effectively as well.
KeywordsHadoopHDFSData load balancingHeterogeneous cluster
收稿日期:2014-11-14。国家自然科学基金项目(61202350)。张松,硕士生,主研领域:计算机网络与分布式计算。杜庆伟,副教授。孙静,助理工程师。孙振,助理工程师。
中图分类号TP391
文献标识码A
DOI:10.3969/j.issn.1000-386x.2016.05.009
猜你喜欢
小学教学研究(2022年5期)2022-04-28 21:29:36
智能计算机与应用(2021年6期)2021-12-17 00:56:36
综艺报(2020年21期)2020-11-30 08:36:49
家庭影院技术(2019年12期)2020-01-19 02:07:20
电脑爱好者(2019年17期)2019-10-30 03:34:48
电信科学(2016年11期)2016-11-23 05:07:56
工业设计(2016年4期)2016-05-04 04:00:27
通信电源技术(2016年6期)2016-04-20 06:21:36
汽车零部件(2014年10期)2014-11-11 12:25:04
上海金属(2013年6期)2013-12-20 07:58:02
