
表情数据驱动三维人脸模型方法
2016-06-07 03:28:02苗语石乐民刘桥盛译丹梁铭
长春理工大学学报(自然科学版) 2016年2期
苗语,石乐民,刘桥,盛译丹,梁铭
(1.长春理工大学 计算机科学技术学院,长春 130022;2.长春理工大学 机电工程学院,长春 130022)
表情数据驱动三维人脸模型方法
苗语1,石乐民1,刘桥1,盛译丹1,梁铭2
(1.长春理工大学计算机科学技术学院,长春130022;2.长春理工大学机电工程学院,长春130022)
摘要:提出了一种利用面部表情数据驱动三维人脸模型中骨骼特征点运动的方法。首先,利用面部表情捕捉设备对面部特征点进行采集,并使用XML格式对面部表情捕捉数据进行描述;然后将采集到的面部特征点与人脸模型中骨骼特征点进行映射配对;最后,使用面向对象图形渲染引擎演示面部表情,从而实现使用面部表情数据驱动三维人脸模型。方法验证实验的过程和结果表明了提出方法的有效性。
关键词:面部表情捕捉;骨骼特征点驱动;特征点匹配
数据驱动模型是将运动数据加载到对象模型上,使后者依照加载的运动数据呈现相应动作。以往实施上述过程时,较多方案选择采用了封装的商业化软件生成制作运动数据,如:MotionBuilder 2013、3DMax、Maya等,在这种方式下,运动数据的生成较多依赖于人工手动的编辑编排,在模型呈现效果的逼真性上存在较大的限定,很难让模型达到逼真的效果[1]。近年来,随着运动捕获技术的快速发展,以往对于高质量、大数量的数据获取需求得到了充分的满足,在运动捕获技术的支撑下,表演者的运动得以被细致、准确的捕获。在此基础上,通过后期处理,将原始数据转换为标准格式的模型运动数据,可实现对于多种模型的驱动。因此,面部捕获数据的提取与合成开始逐渐成为当前虚拟现实方面研究的热点。
在面部表情捕捉技术研究方面,自Frederic I Parke在1972年发表《Computer Generated Animation of Faces》[2]以来,学术界对真实情感建模及表情重建开展了大量的研究,并将取得的研究进展运用到了电影、虚拟现实、游戏、人体工程学等实际领域,取得显著的技术进步。
2009年上映的电影《阿凡达》将人类面部表情的识别和制作带到一个新的高度。在影片的制作过程中,采用了创新的表情捕捉系统,该系统通过头戴式面部捕捉设备对演员面部特定部位的高亮跟踪点进行捕捉采集,并与影片角色的面部对应位置进行了精密地绑定。通过摄像头实施记录跟踪上述跟踪点的位置变化,同步更新和驱动影片角色的面部表情,实现了真人面部数据驱动的虚拟影片角色面部表情呈现。此后的电影《猩球崛起》则首次采用了“脸部肌肉组织模拟技术”[3],进一步推进了影片角色面部表情的捕捉和表达性能。
随着面部捕捉技术在影视、游戏、虚拟现实等应用领域中的使用和推广,其存在的一些限制和不足逐渐显现,目前从面部捕获数据驱动表情的呈现效果来看,还存在以下方面的问题:
(1)在影视、游戏中,由于角色是单独进行表演的,演员通过眼神在与虚拟人物交互时,眼神无法正确匹配。
(2)面部表情的捕捉常与身体动作捕捉分开进行,会导致角色的面部表情与身体运动表达的脱节。
本文使用有标记点的面部数据采集方式捕捉演员实际面部表情,利用面部表情捕捉设备对面部特征点进行采集并使用XML格式对面部表情捕捉数据进行描述;在此基础上,将采集到的面部特征点与人脸模型中骨骼特征点位置进行绑定,最后通过OGRE引擎实现基于面部表情数据驱动演示三维人脸模型。
1 数据捕捉
本文采用有标记点面部表情捕捉方式,识别采集对象的面部感光标识点,并附加LED光源加强光照,增强标记点的映像效果,对感光标识点坐标或相对位置数据进行捕获。在数据采集默认的情况下,面部动作捕获数据的格式为BVH、C3D等[4],上述格式均采用层次化的运动描述方法记录运动数据。针对采集数据支持层次化方式封装的特点,本文选择XML格式数据文件作为数据记录和表达的载体,其具备以下方面的优点:
(1)降低面部表情数据内容与数据内容形式的耦合。通过将面部数据的显示样式从XML文档中分离并放入样式表文件中,使得在改动数据的表现形式时无需改动数据本身,仅改动控制数据显示的样式表文件即可。
(2)提高面部表情的检索效率。由于保存的XML文件是通过属性的方式对面部表情进行定义,将格式与数据分开进行存储,简便快速的对文档中面部表情数据进行检索,在检索时,只需查找到相关节点的属性就能快速找到指定内容,无需再次遍历整个XML文件。
(3)改进多种设备和软件系统之间的数据兼容性。基于XML格式数据文件采用文本方式表达的基本属性,其内容可以广泛被用户和各类系统阅读、导入和使用,将其作为数据载体,能够改进多种设备和软件系统之间的兼容性。
在本文研究工作中,使用自主研发的面部数据转换与保存插件,主要是对面部特征点的提取[5]。对所采集记录的每一帧图像中27个面部表情数据三维坐标进行保存。其实现过程如下:
(1)目标对象及捕捉环境的标定。判别采集目标,根据感光标识点是否在面部捕捉软件中识别的个数调整目标对象与镜头的相对位置关系,确保全部感光标识点被面部捕捉采集设备正确识别。
(2)校验数据采集配置及环境。检查目标对象是否为处于非标准姿势,(相对于面向捕捉相机的姿势),检测环境及主动光源光照强度是否达到预定采集要求、目标对象面部部署的感光标识点是否被遮挡等情况。如检测发现采集要求不满足时,可采用动作捕捉软件对动作进行校正,校正后重新计算传回各标识点的三维数据。
(3)将捕获到面部标识点的三维数据保存至XML文件中。上述用于记录和呈现面部表情捕捉数据的XML文件内容项包括:(a)数据帧采集时间戳节点(数据项的标签名为<face timestamp>),其用于保存获取该帧数据的时间信息;(b)头部位置标定数据节点(数据项的标签名为<root>),对应感光表示点的个数标签名分别为<root-1>、<root-2>、<root-3>和<root-4>,其用于表示目标对象的头部空间位置;(c)面部骨骼节点的空间位置坐标(数据项的标签名为<section>),对应23个采集点的个数,采用与头部位置标定数据节点同样的方式依次定名为<section-1>,<section-2>,……。对于每一条面部骨骼节点空间位置坐标数据,有三个字段分别是标注其在三维空间中的X、Y、Z坐标,其在对应的骨骼节点标签中分别以“X”、“Y”、“Z”命名各字段。采用上述规格创建的XML格式文件内容示例及其与实际目标对象的映射关系如图1所示。

图1 XML格式文件内容示意图
2 面部模型构建
根据MPEG-4标准[6],人脸模型上定义了数据在空间上可参考的特征点,将这些特征点可分为不同的区域进行处理,并定义索引来表示特征点所在的区域,所有符合MPEG-4人脸动画标准的人脸模型均定义了上述所有特征点位置[7]。
在本文的研究工作中,使用3Dmax软件对人脸模型进行构建:首先,建立人脸面部模型,定义人脸模型面部骨骼特征点数量;其次,建立骨骼空间结构,在各个特征点之间构建关联,以配置和表达面部骨骼模型运动特性;最后,根据捕获到的面部数据特征点名称建立人脸模型特征点的映射关系,实现对人脸模型骨骼特征点的驱动,从而实现演员面部表情数据驱动虚拟角色面部运动并呈现表演效果。
上述过程中的人脸模型在软件默认的工作情况下采用3DS格式保存,该格式不支持OGRE对其直接读入和使用。因此,使用3DMax软件将面部模型进行转换,将其输出为网格格式,以支持使用OGRE进行三维数据表达,从而构建了3DMax和OGRE之间的兼容渠道。人脸模型如下图2所示。
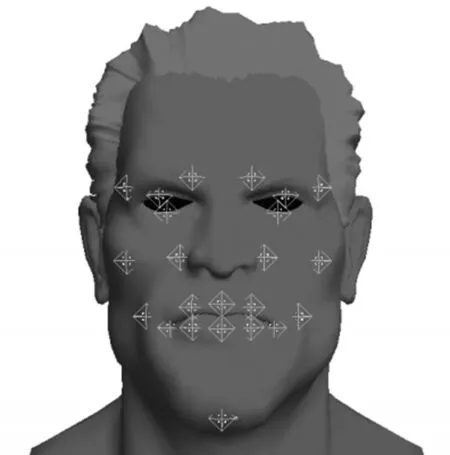
图2 面部模型骨骼点示意图
3 数据驱动
初始情况下,面部模型的世界坐标系与OGRE中的世界坐标系存在差异性。同时每个特征点也有其局部坐标系,在面部捕捉采集数据时,设置的特征点坐标与OGRE的世界坐标系也不相同,如图3所示。在开展数据驱动之前,需要统一各类数据的坐标系。本文把面部模型的世界坐标系,局部坐标和采集数据的特征点的坐标系都转换为与OGRE统一的坐标系[8]。
统一坐标系后,根据面部特征点位置变换参数与人脸模型骨骼特征点之间的对应关系,提取XML格式文件中的序列帧信息,这些信息对应于人脸模型中向量肌肉的收缩或者面部动作编码动作,通过跟踪面部表情的各个特征点映射到面部模型上,从而驱动面部模型的运动。
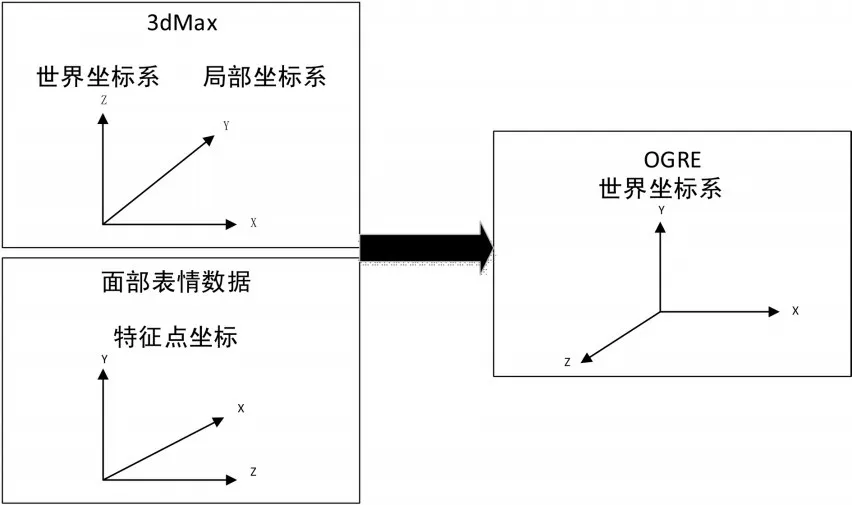
图3 坐标系示意图
一方面,将转化得到的人脸模型导入OGRE演示平台,提取人脸模型中各个特征点名称、特征点索引,根据人脸模型的特征点数量,创建临时特征点集合。其次,读取XML文件中的面部表情数据,逐帧提取面部表情数据,根据人脸模型的特征点名称、特征点索引与XML格式文件中的特征点名称及索引进行绑定。另一方面,将保存完成的面部表情信息与人脸模型骨骼特征点进行映射,实现数据驱动。虽然人物脸部特征的差异性较大,但是对于表情呈现的效果仍可满足基本的演示需求,在保证面部数据与模型特征点的同步工作情况下,运用OGRE能够实现面部表情的有效演示。
4 实验结果及分析
上述研究工作在实际实现过程中,采用有标记点的OptiTrack动作捕捉系统配合ARENA动作捕捉软件共同对面部表情进行捕捉,捕获面部表情动作采用VS2008和OGRE软件支持环境进行实际验证。运动捕获后,将捕获的三维运动数据转换为模型驱动数据,加载到三维模型进行模型驱动实验。图4显示了演示产生的表情效果图,包括张嘴表情、皱眉表情和挑眉表情三种面部表情效果。
5 结论
本文提出了一种基于面部表情捕捉设备对面部表情变化进行数据采集,实现面部表情采集数据驱动面部模型中骨骼点运动的方法。采用面部表情捕捉数据,对各种角色模型进行驱动,使面部骨骼模型能够按照面部表情运动轨迹正常运动。通过使用该方法,能够提高数据在多个软硬件系统平台的可用性,实现了演员面部动作采集驱动角色面部表情,并达成合理的呈现效果。本文为面部表情合成提供了新的技术路线,改进和扩展了面部数据捕捉的使用方式和应用范围。

图4 显示的是表情效果图
参考文献
[1]高湘冀,郑江滨.基于视觉运动捕获数据的三维模型驱动方法[J].中国体视学与图像分析,2009,14(2):182-186.
[2]Parker F.Computer Generated Animation of Faces [C].In Proceedings ACM ANN Conference. New York,1972.
[3]蒋斌,贾克斌,杨国胜.人脸表情识别的研究进展[J].计算机科学,2011,38(4):29-31.
[4]郭力,何明耘,陈雷霆.基于BVH的OGRE骨骼动画[J].汁算机应用研究,2009,26(9):6-10.
[5]王淑媛.人脸识别特征提取算法研究[D].长春:长春理工大学,2005.
[6]Ovevriew of the MPEG-4 Standard[S].ISO IECJTC1 SC29 WG11N2323,Dublin,Ireland,1998.
[7]於俊,汪增福.一种基于MPEG-4的单位人脸表情运动算法[J].中国科学技术大学学报,2011,41(4):307-315.
[8]宋晓,付林,龚光红,等.一种虚拟人动作及面部表情的驱动机制[J].中国传媒大学学报:自然科学版,2011,18 (3):67-71.
The Method of Facial Expression Data Driven 3D Face Model
MIAO Yu1,SHI Lemin1,LIU Qiao1,SHENG Yidan1,LIANG Ming2
(1.School of Computer Science and Technology,Changchun University of Science and Technology,Changchun 130022;2.School of Mechatronical Engineering,Changchun University of Science and Technology,Changchun 130022)
Abstract:This paper proposes a method which utilizes the facial expression data driving skeletal feature points in three-dimension(3D)face model. Firstly,we capture the facial feature points with the face capture devices,and adopt XML-format file to specify the captured data. Then we continue to map the collected facial feature points to the skeletal feature points of the facial model. Finally,we utilize the Object-oriented Graphics Rendering Engine (OGRE)enabling to present the facial expressions. In this way,we are enabled to drive the 3D facial models with the facial expression data. We compose the procedures and results of validating the method at the end of paper.
Key words:facial capture;skeletal features point driving;feature point matching
中图分类号:TP391
文献标识码:A
文章编号:1672-9870(2016)02-0112-04
收稿日期:2015-10-27
作者简介:苗语(1980-),女,博士,讲师,E-mail:custmiao@126.com
