
基于手势的交互式三维场景并行光线跟踪绘制研究
2016-06-07 03:27蒋聪陈纯毅
长春理工大学学报(自然科学版) 2016年2期
蒋聪,陈纯毅
(长春理工大学 计算机科学技术学院,长春 130022)
基于手势的交互式三维场景并行光线跟踪绘制研究
蒋聪,陈纯毅
(长春理工大学计算机科学技术学院,长春130022)
摘要:利用光线跟踪可以绘制出高质量的真实感场景画面,但计算量很大,难以实现实时交互式绘制。为此,三维真实感场景的实时交互式绘制往往需要用到集群,但集群的绘制速度是由绘制速度最慢的节点决定的,如果节点之间的任务没有被划分均匀,集群的绘制效率就会下降。为了满足实时交互式绘制的要求、提高集群的绘制效率,设计了在粗粒度和细粒度两个层次上同时实现并行计算的集群绘制系统,并针对集群的负载均衡问题提出了基于像素递归深度的负载均衡方法。该方法首先统计出每个像素的递归深度从而得到整个场景的递归深度图,然后对上一帧按递归深度进行均衡划分。根据连续两帧所对应的场景具有的时空相关性,上一帧的划分结果可作为下一帧划分的依据。本算法的优势在于能够快速实现三维动态场景下的集群负载均衡。实验表明,该集群绘制系统可以高效地实现基于Kinect的实时交互式绘制。
关键词:集群;光线跟踪;负载均衡;递归深度;实时交互
近年来,实时交互式真实感图形绘制是计算机图形学研究的热点。为了使绘制结果更加真实,往往采用光线跟踪进行绘制。如果绘制的场景包含较多的镜面材质对象,则系统需要对大量的二次光线和阴影探测光线进行处理,这会使绘制效率大大降低,而无法满足实时交互的要求。针对此问题,大致有两种解决方案:第一,优化现有的算法,设计高效的场景加速结构[1,2];第二,采用并行光线跟踪进行绘制,如集群绘制。
集群绘制是实现实时交互式绘制的一种有效途径,但集群绘制的速度是由绘制速度最慢的节点决定的,如果节点之间的任务分配不均匀,集群绘制的效率就会下降,甚至失去并行加速的作用。目前的负载均衡算法虽然实现了较好的负载均衡效果,但都很难满足实时交互式绘制的要求。
已有的负载均衡策略包括基于PBT树的自适应划分方法[3,4]和基于像素开销[5]的方法。基于PBT树的自适应划分方法利用场景绘制时前后帧所对应场景的时空相关性,以上一帧的绘制时间开销为参考,通过合并任务较轻的节点、分割任务较重的节点的方式对下一帧进行预估划分。但此方法无法使系统快速达到负载平衡状态,以至于不能满足三维动态场景的实时交互式绘制要求。基于像素开销算法的基本思想是系统首先根据像素开销图把场景划分成一定数量的块,然后平均分配给各个节点,各节点再用一个栈存储分到的任务块。在绘制过程中率先完成绘制任务的节点通过任务窃取机制[6]从其它未完成绘制任务的节点分担一些绘制任务。该方法计算复杂、网络通信负担重,而且节点内部不是并行的。
本文设计了在粗粒度和细粒度两个层次上同时实现并行计算的集群绘制系统以实现基于Kinect的自然人机交互绘制。同时针对集群的负载均衡问题提出了按像素递归深度对场景进行划分的负载均衡方法。
1 集群系统设计
1.1并行光线跟踪绘制
并行光线跟踪的并行设计方式分为粗粒度并行和细粒度并行,如图1所示[7]。粗粒度并行是节点间的并行,其光线跟踪设计两种不同的设计方案:基于物体空间的并行和基于屏幕空间的并行[8]。基于物体空间的并行设计是把场景中的物体分配给各绘制节点。基于屏幕空间的并行是把场景按屏幕尺寸划分成若干像素块,然后分配给各绘制子节点。细粒度并行是节点内的并行,本文利用NVIDIA 的OptiX引擎实现绘制节点内部的并行。集群节点之间的并行设计采用的是基于屏幕空间的并行方案。
并行光线跟踪的执行流程由场景划分与合并、网络通信、帧同步、数据压缩和负载平衡等环节组成,其中负载均衡是难点也是关键点。
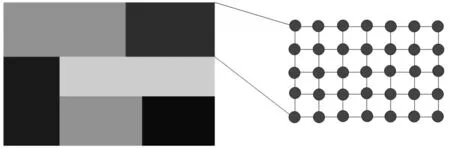
图1 粗粒度并行与细粒度并行
1.2系统运行流程
本文的集群绘制系统设计基于客户/服务器架构,系统工作流程如图2所示。服务器首先读取配置文件,得到各个绘制节点的绘制参数,包括这些节点的IP地址、监听端口、场景的初始划分参数等;然后启动处于监听状态的绘制节点,将相应的绘制参数发送给各个节点。客户端一直处于监听状态,当接收到服务器发来的绘制任务后,调用OptiX引擎执行绘制。绘制完成后,子节点对数据进行压缩并发送往服务器。服务器收到客户端发来的结果之后再反馈回去一个信号,客户端收到反馈信号之后再绘制下一帧,以此实现同步绘制。在绘制过程中,服务器可以随时检测人机交互指令并将指令发往客户端。
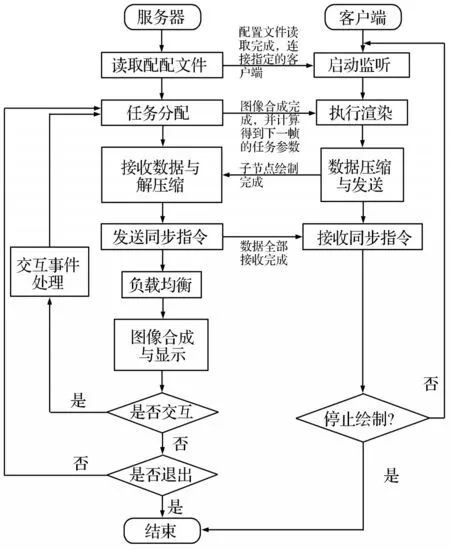
图2 系统工作流程图
1.3场景划分与合并
本文中,场景被划分成的块数与绘制节点数目一致,这样不仅可以降低网络通信开销,而且便于逻辑控制。系统产生的初始光线与屏幕上的像素一一对应,都有确定的坐标索引(屏幕像素坐标)。服务器把坐标索引作为任务参数发给绘制子节点,子节点只绘制指定的像素块,然后把结果数据发往服务器,如图3所示。
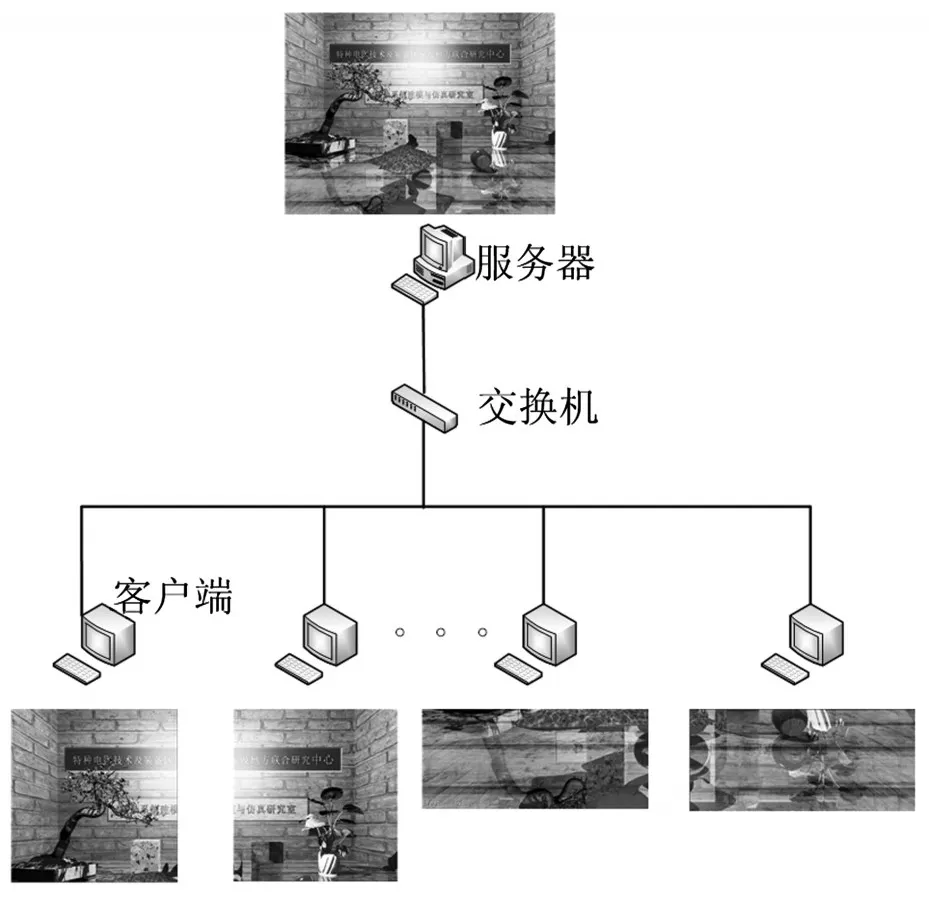
图3 场景划分,四台绘制worker示例
2 负载均衡
在集群绘制系统中,由于任务分配不均匀,不同节点完成绘制任务的时间开销不同,这样完成时间早的节点就会闲置等待绘制完成时间晚的节点,从而造成系统资源浪费,绘制效率低下。这就是集群普遍存在的负载不均衡问题[7]。
在负载均衡过程中,一个重要的环节就是统计场景各个部分的绘制时间,以量化子节点的绘制任务。在利用光线跟踪进行绘制时,光线与物体的遍历求交计算占据了绝大部分的绘制时间,所以场景中绘制任务较重的一定是产生二次光线较多的部分[6]。因此可用像素的递归深度值作为对场景进行划分的标准。由于动态场景的变化是一种连续的变化,因此,连续两帧对应的场景具有时间和空间上的相关性:连续两帧的同一个像素所绘制的场景点的空间位置和绘制该像素所花费的时间具有一致性。基于绘制同一像素时的时空相关性,系统首先记录每个像素产生的二次光线数量,从而得到整个场景的递归深度图,然后利用连续两帧所对应场景的时空相关性,对场景按递归深度进行划分,并把划分结果作为下一帧划分的依据。
对场景的划分是沿轴进行交替划分的,系统每次都按递归深度把当前块划分成大致相等的两块。划分过程如图4所示,先把当前块按行或列降维,即把每行或每列所有递归深度值的和存储为一维数组的一个元素。这样就把划分整块图像的问题转化为均衡划分一维数组的问题。可以假设有一个天平,分别从数组的两端取数,放到天平对应的两个托盘中。在取放过程中,根据天平的平衡状态,实时调节取数的位置,以维持天平的平衡。最终天平会在某一次取放操作达到最佳平衡状态。此时根据指针在一维数组中的位置,把当前块划分为均衡的两块。
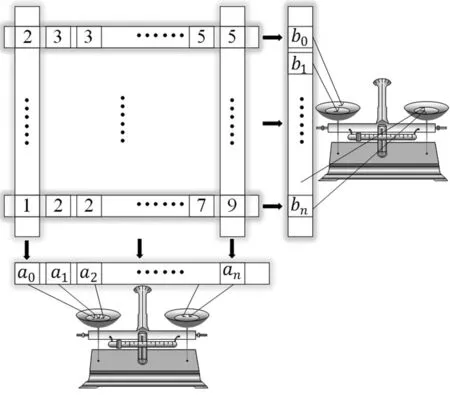
图4 基于天平平衡的负载均衡思想示意图
算法描述如下:
(1)递归深度统计算法
设变量depth代表像素的递归深度,初始值为0,系统每检测到一次镜面反射,depth就累加1。由于要在交点处还需要向光源发射一条阴影探测光线,再加上初始光线和初始阴影探测光线,系统实际产生的光线总数为2depth+2。
(2)场景自适应划分算法
服务器根据绘制子节点发来的递归深度数据得到整个场景的递归深度图,然后基于递归深度值把场景均衡地划分成份。算法过程如算法1所示。
算法1基于递归深度自适应划分算法
算法以递归深度图C,迭代次数n,两个双端队列Q和P作为输入参数,用Q存储即将被划分的数据块,用P存储新划分好的数据块。在每次迭代中,系统会选取轴或轴把当前数据块划分成接近相等的两块,系统最终会把场景沿着、轴划分成块。CreateTile()用于创建初始场景块;Enqueue()负责把新生成的场景块入队;Dequeue()使即将待划分的场景块出队;SplitX(T)把当前场景块T沿着X轴划分成均衡的两块;SplitY(T)把当前场景块T沿Y轴划分成均衡的两块。
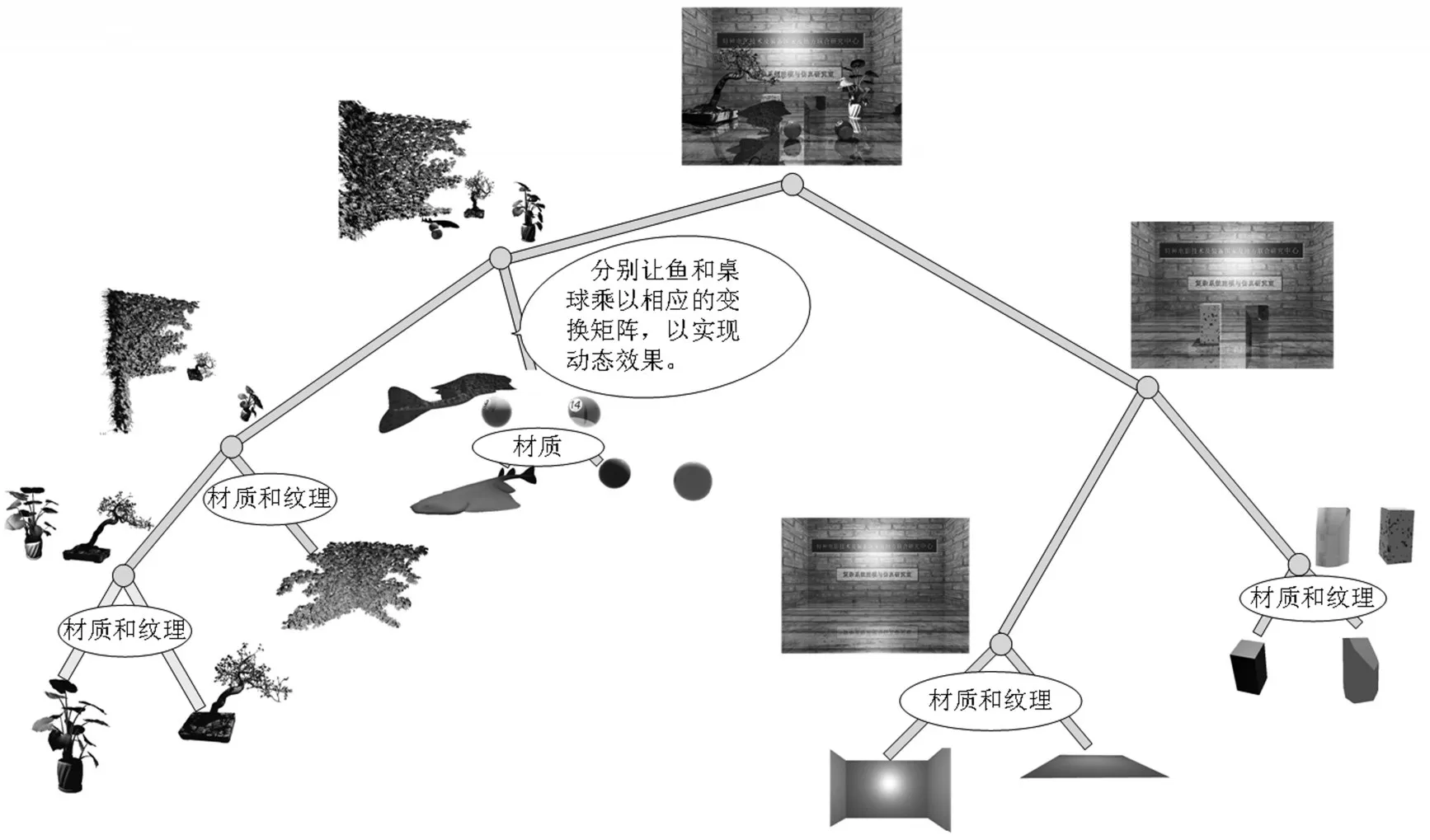
图5 场景1组织结构图
1.设置标定量Axis←0;
2.初始场景块Enqueue(P,CreatTile());
3.开始迭代for i←0 to n do
4.交换Q=P;
5.清空P,Clear(P);
6.While Q非空do
7.出队待划分场景块T=Dequeue(Q);
8.if Axis=0 then
9.沿X轴划分(T1,T2)←SplitX(T);
10.else
11.沿Y轴划分(T1,T2)←SplitY(T);
12.Q空end
13.入队新数据块Enqueue(P,T1);
14.入队新数据块Enqueue(P,T2);
15.end
16.Axis=1-Axis;
17.迭代结束end
3 基于Kinect的自然人机交互设计与实现
3.1场景绘制
场景绘制是用OptiX引擎实现的,该引擎是基于CUDA[9]的面向对象的可编程、并行渲染框架。OptiX程序由两部分组成:(1)基于主机的API,用于定义基于光线跟踪的数据结构;(2)一个基于CUDA C的程序系统,用于产生光线、光线与物体求交计算、创建包围盒和着色等。OptiX程序的主要组成对象是Context、Program、Variable、Buffer、Textur Sampler、Geometry、Material、GeometryInstance、Group、GeometryGroup和Acceleration等。
OptiX各对象模型之间有着严格的从属关系。三维场景的创建就是把这些对象模型按照设计者的需求组织成一棵场景树。本文用OptiX引擎绘制的场景1的场景结构图,如图5所示。
3.2交互实现过程
(1)人体骨骼点数据采集
本文主要利用Kinect的人体骨骼追踪系统进行交互设计。Kinect通过内置摄像机以每秒30帧的速率对人体25个部位的骨骼点进行实时捕捉。捕捉到的数据以数据帧(frame)的形式存储起来,以供相关库函数调用。
骨骼数据是以骨骼空间坐标系下的三维坐标的形式存在的。骨骼空间坐标系是以传感器为坐标原点的右手坐标系,骨骼数据就是该坐标系下的值,如图6所示。
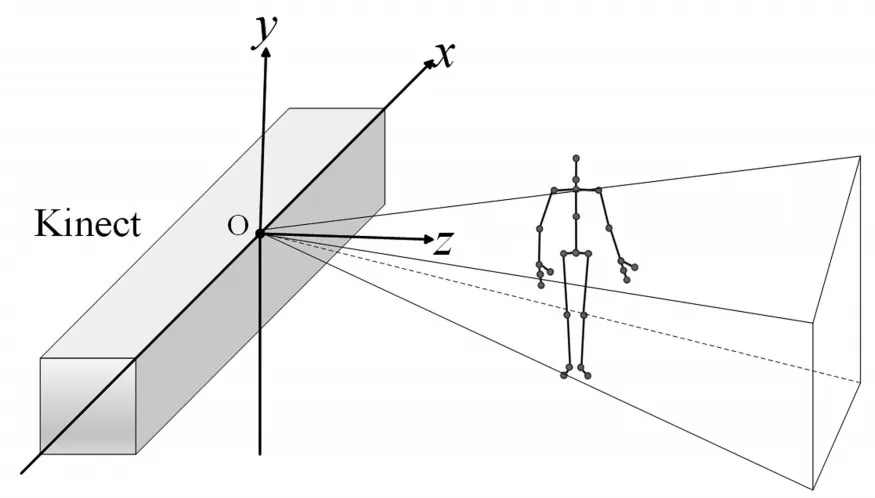
图6 骨骼空间坐标系
(2)手势识别
本文用Kinect提取出了人体六个部位的骨骼点,分别为:右手腕Hright、左手腕Hleft、右肘Eright、左肘Eleft、右肩Sright、左肩Sleft。基于以上骨骼点定义四个向量:Vright、Rright、Vleft、Rleft。
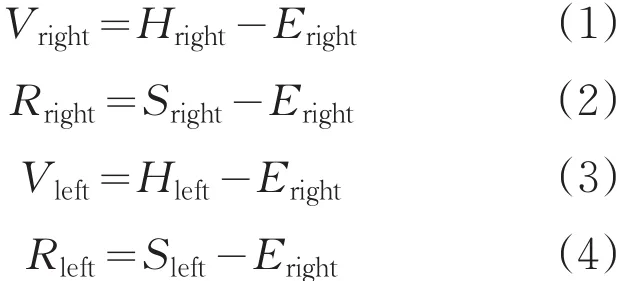
右臂招手的过程如图7所示。定义角度α为向量Vright和Rright的夹角;角度β为向量-Rright与y轴负方向的夹角。为了模拟手臂的自然抬升过程,本文针对夹角α、β和关键骨骼点间的位置关系设置了几个参考量:当且仅当夹角β依次大于5°、15°、30°,且夹角α小于45°,右手腕关节点y坐标大于右肩关节点y坐标时视为有效招手过程。
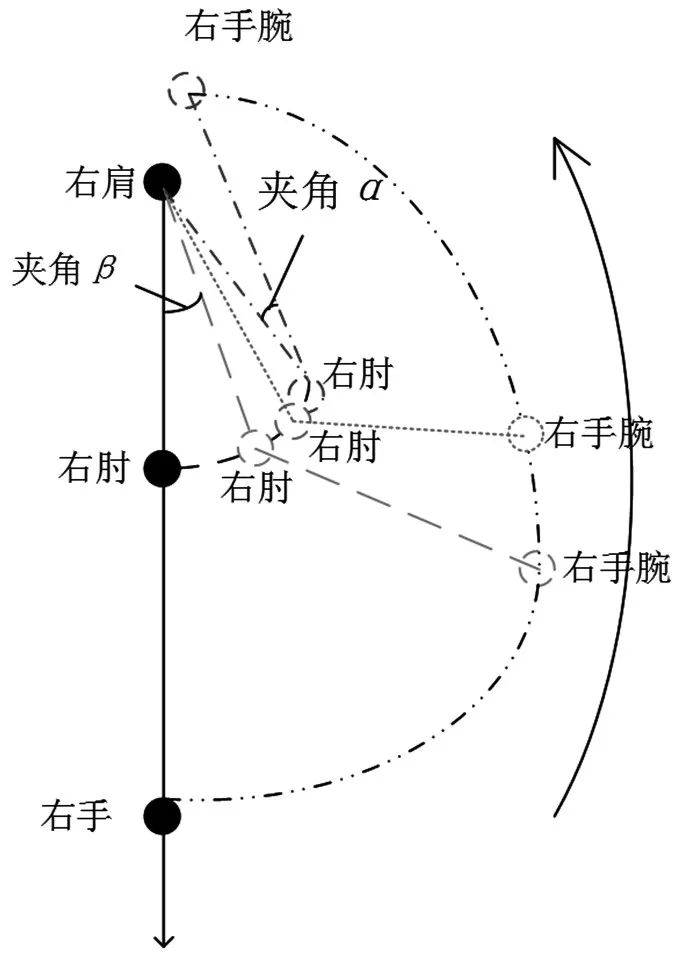
图7 右臂招手过程
左手臂挥手动作如图8所示。定义角度γ为Vleft与Rleft的夹角。为模拟自然挥手的过程,检测角度依次小于120°、90°、60°,并随后依次大于80°、100°、120°。设左肩、左肘和左手腕组成的三角形ABC,向量是从肘关节点A为起点,垂直于BC的向量。有效的左臂挥手动作,除了满足针对γ设置的一些临界值,还要满足左肘关节点的y坐标大于左肩的y坐标,且向量V的y坐标为负值。手势识别的正确率如表1所示。
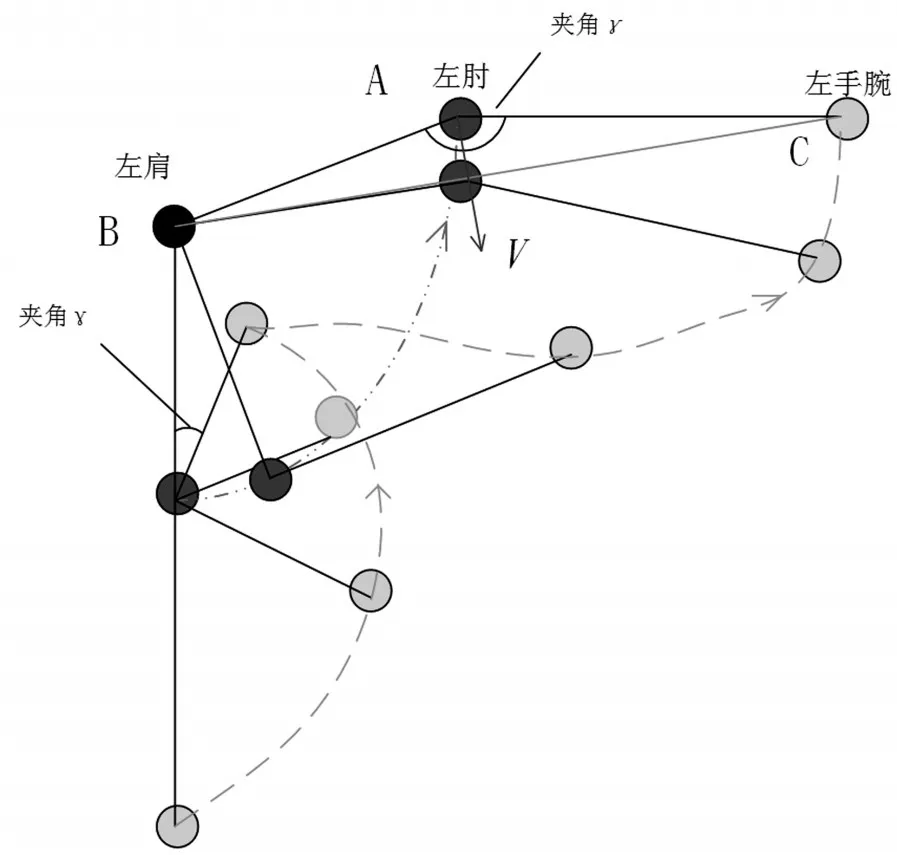
图8 左臂挥手过程

表1 手势识别正确率统计
4 交互事件设计
4.1运动状态设计
在场景2中一共设计了3种运动状态:(1)螺旋上升;(2)飞向场景中心;(3)绕某一特定轴旋转。仙子模型首先进入运动状态1,运动状态1结束之后,仙子模型调整姿态进入运动状态2,待运动状态2结束之后,仙子调整姿态进入运动状态3,运动状态3结束之后,进入运动状态1,如此循环往复。在任意时刻,仙子模型都可以对交互请求作出响应。仙子模型的运动轨迹如图9所示。
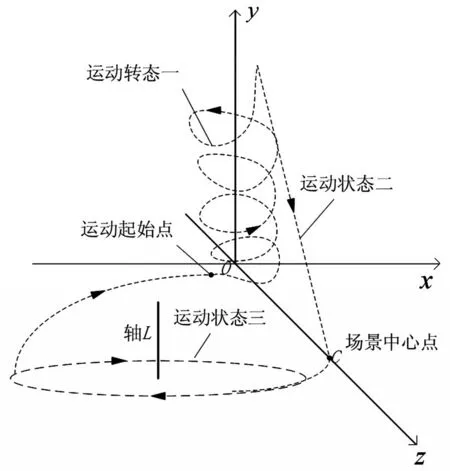
图9 仙子模型运动轨迹
模型是由三角形或四边形面片组成的,这些平片图形又是由三维空间中的点组成的。空间中的任意一点P,可以用它的齐次坐标来表示,即P(x,y,z,1),x,y,z分别表示点在三维空间中的实际坐标。通过对点P施加一个变换矩阵,就能把点P变换到指定的位置。因此,模型的运动状态可以通过矩阵变换进行控制。任何复杂的运动都可以由初等变换(平移变换、缩放变换、旋转变换)矩阵复合而成[7]。齐次变换矩阵如式5所示,它表示绕Y轴旋转θ角并平移(x0,y0,z0)。
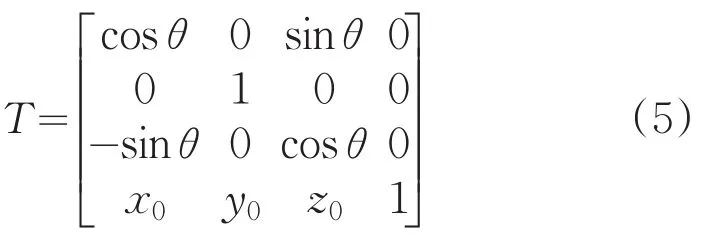
仙子模型的运动状态如算法2所示。
算法2仙子模型运动状态控制
首先从状态1开始;运动状态1结束后,进入运动状态2,置停运动状态1的所有运动参数;依次类推进入运动状态3,;运动状态3结束后,所有运动参数置0,并回到初始的运动状态,如此循环下去。
1.场景帧刷新While UpdateScene
2.开始运动状态1MoveState1();
3.状态1结束if(state1_end)
4.置停运动状态1Stop_MoveState1();
5.状态调整State_adjustment1();
6.开始运动状态2MoveState2();
7.运动状态2结束if(state2_end)
8.置停运动状态2Stope_MoveState2();
9.运动状态调整State_adjustment2();
10.开始运动状态3MoveState3();
11.运动状态3结束if(state3_end)
12.state1_end=flase;
13.state2_end=flase;
14.state3_end=flase;
15.end
16.end
17. end
18.end
4.2交互响应
本文只针对场景2进行了交互设计,在场景2中,分别设计了两个交互动作:右臂招手和左臂挥手。招手时,仙子模型即刻调整姿态向视点飞来;挥手时,仙子模型调整姿态并返回到原来的运动轨迹上去。仙子模型在任意状态下均可响应交互请求,交互嵌入流程图如图10所示,运动状态1、运动状态2和运动状态3如运动状态设计模块所述。如果系统没有检测到交互指令,模型按预定的运动方案依次循环执行三个运动状态;若期间检测到交互指令,则首先记录当前模型位置,然后触发相应的交互事件。
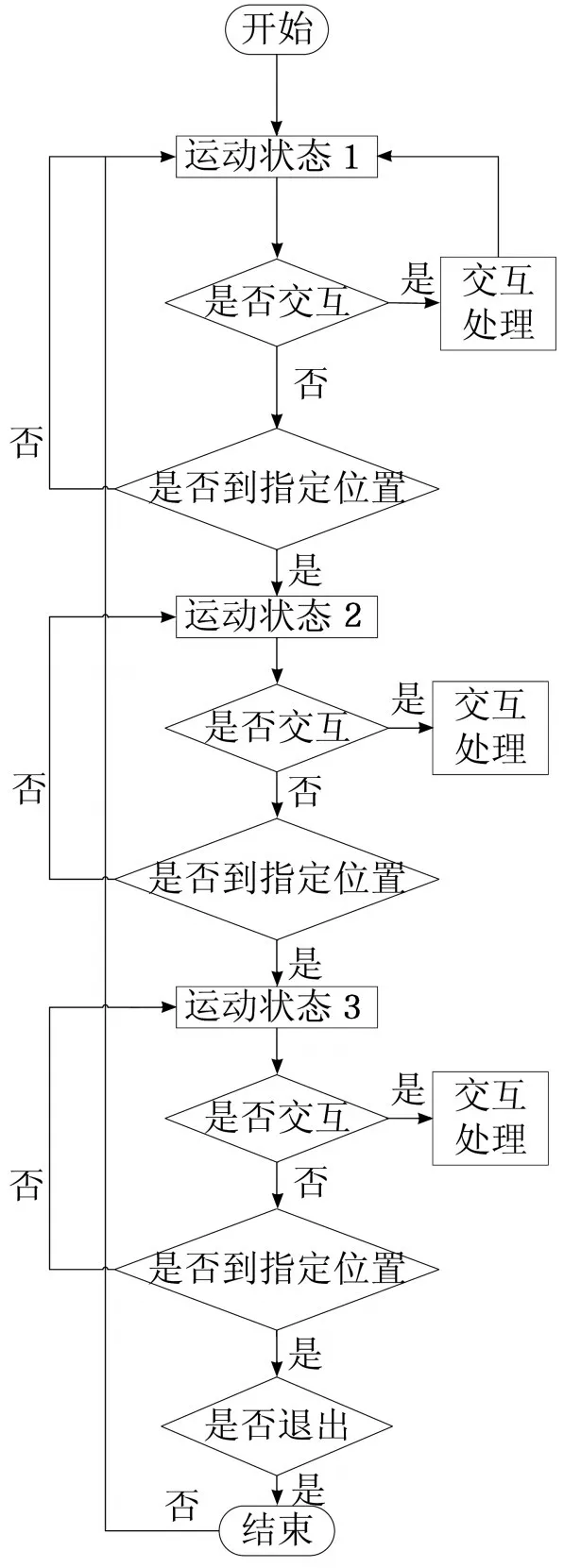
图10 交互嵌入流程图
在交互处理模块,仙子模型也需要实时检测用户的交互请求,并做出相应的处理。该模块对用户交互请求响应相对简单,只需要模型做一次转身调整,飞向观察者或返回原来的运动状态。交互处理模块的流程设计如图11所示。在交互处理模块,仙子模型只有飞向视点和返回原来位置两种运动状态。
当检测到招手指令时,仙子模型继续保持飞向视点的运动姿态;当检测到挥手时,立刻停止原来的运动状态(指飞向视点的运动姿态),然后进行直立转身状态调整并飞回初始位置。
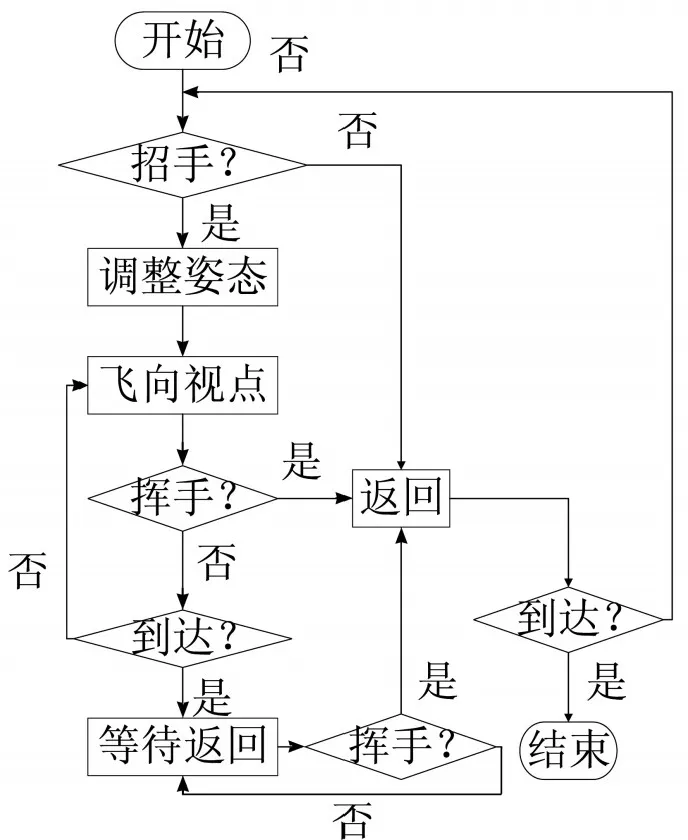
图11 交互处理模块设计图
算法3描述了交互嵌入流程和交互处理模块的具体实现。
算法3交互嵌入流程和交互处理算法
算法实时监测是否有交互请求:beckon(招手)和wave_away(挥手)。如果有交互请求,算法就把相应的标记变量赋值,这些变量去触发相应的交互处理模块。在招手处理模块中,仙子模型首先调用State_adjust()进行直立矫正,然后转身调整,接着飞向试点。在挥手模块中,也是首先进行直立矫正,然后转身背向试点,返回原来离开时的位置。整个交互过程需要调用preprocessing()对原来的运动状态做预处理。
1.更新场景While(UpdateScene)
2.如果招手if(beckon),设置标记变量fiary_ come←true,fiary_return←false,state_adjust_bool ←true,state_adjust_bool←true,bool_arrive=true;
3.招手变量标记完成end;
4.如果挥手if(wave_away),fiary_return←true,fiary_come←false,state_adjust_bool2←true,bool_ arrive=false;
5.挥手变量标记完成end;
6.if(fiary_come)index++;
7.交互相应预处理proprecessing();
8.if(state_adjust_bool and index>=2)
9.如果模型倾斜,则直立矫正
10.状态调整State_adjust();
11.state_adjust_bool←false;
12.记录离开时的位置;
13.if(index>3 and bool_arive),身体前倾并飞向观察者,end;
14.如果到达指定位置,bool_arrive←false,直立矫正;
15.如果招手if(fiary_return)index2++;
16.交互预处理preprocessing();
17.返回原来的位置;
18.if(state_adjust_bool2),直立矫正,end;
19.if(state_adjust2 and index2>=2),转身调整,State_adjust_bool2←false,end;
20.if已返回,清除所有交互参数CleanAll(),end;end;end;
5 实验分析
本文使用的微机基本配置:Intel(R)Xeon(R)E3-1255 v3 CPU,4GB主存,NV Quadro K600 GPU。编译环境:win8.1 64位操作系统,VS2013、OptiX3.8.0、CUDA7.5。
本次实验一共绘制了两个场景,如图12所示。上面两图是场景1:地板材质是镜面材质、球表面材质是高光材质,其它为漫反射材质,视点可以通过鼠标和键盘的控制在场景中漫游,鱼可以自由游动。下面两图是场景2:在任意时刻人向Kinect招手,仙子模型就立刻停止原来的运动状态并调整姿态向视点飞来,在此过程中也可随时挥手让仙子模型返回到原来的运动状态。

图12 场景绘制效果图
在场景1中,物体具有不同的运动状态和材质,场景比较复杂,本文主要用场景1验证系统的负载均衡效果。图13显示了场景1分别在1台、2台、4台机器上绘制时,绘制每帧所用的时间(负载均衡之后的结果),由图可知,随着机器台数的增加,场景绘制效率大幅增加。但是由于机器之间的固有差异和网络传输等因素,绘制效率并不是线性增加的,不过已经接近比较理想的状态。
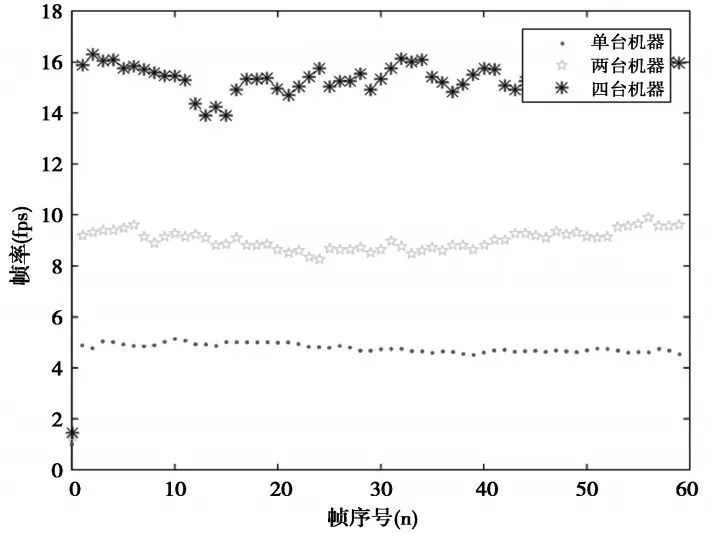
图13 多节点绘制对比图
图14显示了场景1负载均衡之前和之后的效果。在采取负载均衡之前,场景的划分方式为按屏幕尺寸把场景均分为四份,由于场景不同部分的绘制时间开销相差较大,所以划分的结果一定是不均衡的。采取负载均衡之后,服务器会实时地根据子节点发来的像素递归深度数据,对场景进行均衡地划分。实验表明,该方法可以达到很好的集群负载均衡效果。
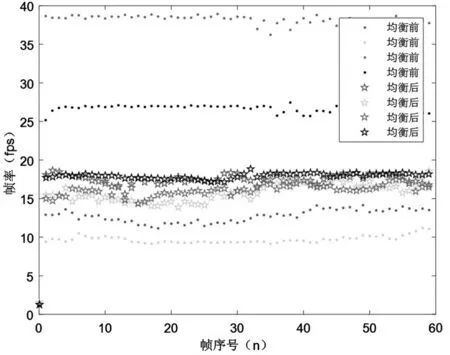
图14 负载均衡效果图
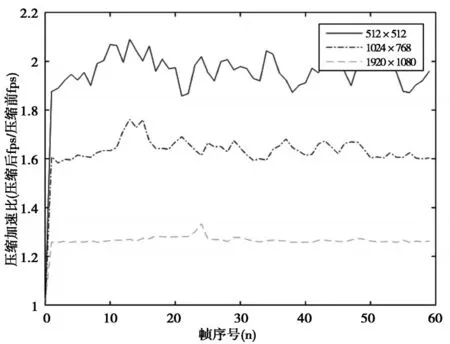
图15 不同分辨率下的压缩加速比
集群绘制中存在大量的数据传输。假设绘制的场景尺寸为1024×768,每个像素由R、G、B三个分量组成,场景绘制的帧率为20帧/秒,则系统需要每秒传输1024×768×3×20=45MB的数据量,这对系统来说是一个相当大的负担,因此节点有必要对结果数据进行压缩之后再传送。本文分别统计了不同分辨率下的压缩加速比,如图15所示。从图中可以看到,采取数据压缩的方法可以大幅度减少网络通信负担,提高绘制效率。随着分辨率的增加,压缩加速比逐渐减小,这是因为大分辨的场景数据量很大,即便对数据进行了压缩处理,网络负担仍然很重。
6 结论
为了实现实时交互式绘制,本文设计了一种在粗粒度和细粒度两个层次上同时实现并行计算的集群绘制系统,然后基于Kinect的骨骼追踪系统设计了一套交互手势。针对集群绘制的负载均衡问题,提出了基于像素递归深度的实时负载均衡算法。该算法通过统计每一个像素实际产生的二次光线数量,得到整个场景的递归深度图,从而量化了场景各个部分的绘制负担。由于每个像素的递归深度是已知的,而且连续两帧所对应的场景具有一致性,因此该算法可以使系统快速实现负载均衡。
参考文献
[1]Kun Zhou,Qi Ming Hou,Rui Wang,et al.Real-time k-D tree construction on graphics hardware. In Proc [C]. SIGGRAPH Asia(2008),27(3):1-11.
[2]Kirill Garanzha,Jacopo Pantaleoni,David McAllister. Simpler and faster HLBVH with work queues[C]. In Proceedings of the ACM SIGGRAPH Symposiumon High Performance Graphics,NewYork,(USA),2011.
[3]Cosenza B,Cordasco G,De Chiara R,et al.Load balancing in mesh-like computations using prediction binary trees[C]:2008 International Symposium on Parallel and Distributed Computing,Salerno(Italy),2011.IEEE.
[4]Biagio Cosenza,Gennaro Cordasco,Rosario De Chiara,et al. On estimating the effectiveness of temporal and spatial coherence in parallel ray tracing[C]. In Eurographics Italian Chapter Conference,Salerno (Italy),2008.
[5]Alan Chalmers,Erik Reinhard. Pratical parallel rendering[M]. A. K.Peters,Ltd.,2002:20-35.
[6]Biagio Cosenza,Carsten Dachsbacher,Ugo Erra. GPU cost estimation for load balancing in parallel ray tracing[C]. 8th International Conference on Computer Graphics Theory and Applications,Barcelona(Spain)2013.
[7]任崇辉.基于GPU的高真实感集群渲染系统[D].杭州:浙江大学,2011:21-25,30.
[8]孔令德.计算机图形学基础教程[M].北京:清华大学出版社,2008:113-115.
Study on Gesture-based Interactive 3D Scene Rendering Using Parallel Ray Tracing
JIANG Cong,CHEN Chunyi
(School of Computer Science and Technology,Changchun University of Science and Technology,Changchun 130022)
Abstract:High quality realistic scenes can be rendered by ray tracing. However,it is always time-consuming,which makes it difficult to achieve real-time interaction. Cluster of workstations is often used for real-time interactive rendering,but it always has a problem of load balancing. In order to meet the requirements of real-time interaction and improve the efficiency of the cluster rendering,this paper designs a cluster rendering system which is parallel both in coarse-grained and fine-grained level. On the phenomenon of load imbalance,it also presents a real-time solution based on the recursion depth of the pixel. This method firstly counts the recursion depth of each pixel to get the recursion depth map of the entire scene and then divides the scene evenly according to the recursion depth. Due to the spatial and temporal coherence of two consecutive frames,the division result of the previous frame can be used as the estimation of the next frame. The advantage of this method is the ability to quickly realize the cluster load balance to support real time interactive rendering. Experiment shows that this cluster rendering system can efficiently perform Kinect-based real-time interactive rendering.
Key words:cluster;ray tracing;load banlancing;recursion depth;real-time interaction
中图分类号:TP391
文献标识码:A
文章编号:1672-9870(2016)02-0090-08
收稿日期:2015-10-30
基金项目:吉林省重点科技攻关项目(20140204009GX);长春市重大科技攻关(14KG008)
作者简介:蒋聪(1990-),男,硕士研究生,E-mail:jaingcong0303@hotmail.com
通讯作者:陈纯毅(1981-),男,博士,副教授,博士生导师,E-mail:chenchunyi@hotmail.com
猜你喜欢
军事运筹与系统工程(2019年4期)2019-09-11
电子制作(2018年11期)2018-08-04
中国交通信息化(2017年3期)2017-06-08
知识就是力量(2017年2期)2017-01-21
软件导刊(2016年12期)2017-01-21
软件导刊(2016年12期)2017-01-21
计算技术与自动化(2016年4期)2017-01-11
企业技术开发·中旬刊(2016年10期)2016-11-12
学习月刊(2016年14期)2016-07-11
科技视界(2016年3期)2016-02-26
