
基于信息熵的网络课程学生分类模型研究
2016-05-30 01:29黄金晶黄黎
宁波职业技术学院学报 2016年5期
黄金晶 黄黎
摘 要: 在网络课程教学中对学生进行分类,教师能为不同类别的学生制定相应的教学策略,提高教学质量。文章将信息熵理论运用于学生分类,在预处理之后的数据上,采用ID3算法构建了基于信息增益的决策树,生成相应的决策规则,为新的输入数据提供了分类依据。
关键词: 网络课程; 信息熵; 决策树; 信息增益
中图分类号: TP 393 文献标志码: A 文章编号: 1671-2153(2016)05-0084-03
0 引 言
网络课程[1]教学是信息时代下课程新的表现形式,它以学生为主体,利用现代网络技术,为学生提供多方面的学习素材,如文档、视频等;同时也支持多种形式的师生互动,如在线答疑、讨论,使学生在任何时间任何地点都可以身临其境的学习。此外,在线测试也提供了对学生学习效果的检测。
随着网络学习人群的增加,网络教学平台中留下了大量的数据,利用数据挖掘技术[2]可以从中获取有用的信息。登录网络教学平台学生的基础数据不同,如访问时长、论坛活跃度、学习能力等。若对学生进行分类,对不同的类别的学生采取适合其特点的教学策略,这为个性化学习、因材施教提供了可能。本文主要探讨数据挖掘技术中的信息熵[3]在学生分类模型中的应用,通过对已知样本的学习,预测未知类别学生的分类。
1 学生分类数据挖掘流程
学生登录网络教学平台后,留下了大量的访问数据,比如学号、访问资源、访问时长等,在这些数据中用人工的方式提取有价值的数据是一件非常困难的事,因而可以借助数据挖掘技术对数据进行分析,整体流程如图1所示。
图1中,整个流程分为数据采集与预处理、模式发现、规则分析。原始数据中包含了大量带有噪声的和冗余的信息,这些数据的存在会对分析的结果造成干扰,所以必须对其进行过滤和清洗,并将其变成高质量的数据。在模式发现阶段,使用决策树[4]的分类算法对数据集进行分析,获得不同的分类规则,规则1、规则2…规则n,当新的学生数据进来后,根据已有的规则进行匹配,获得新数据所在的类别,即对新数据进行预测。
2 分类模型构建与分析
2.1 学生分类模型构建
分类模型的构建有多种方法,本文使用ID3算法[5]进行分类的构建。构建学生的分类模型,首先要获得参与决策的相关属性,为每个属性计算信息增益[6],选择最大信息增益的属性进行划分。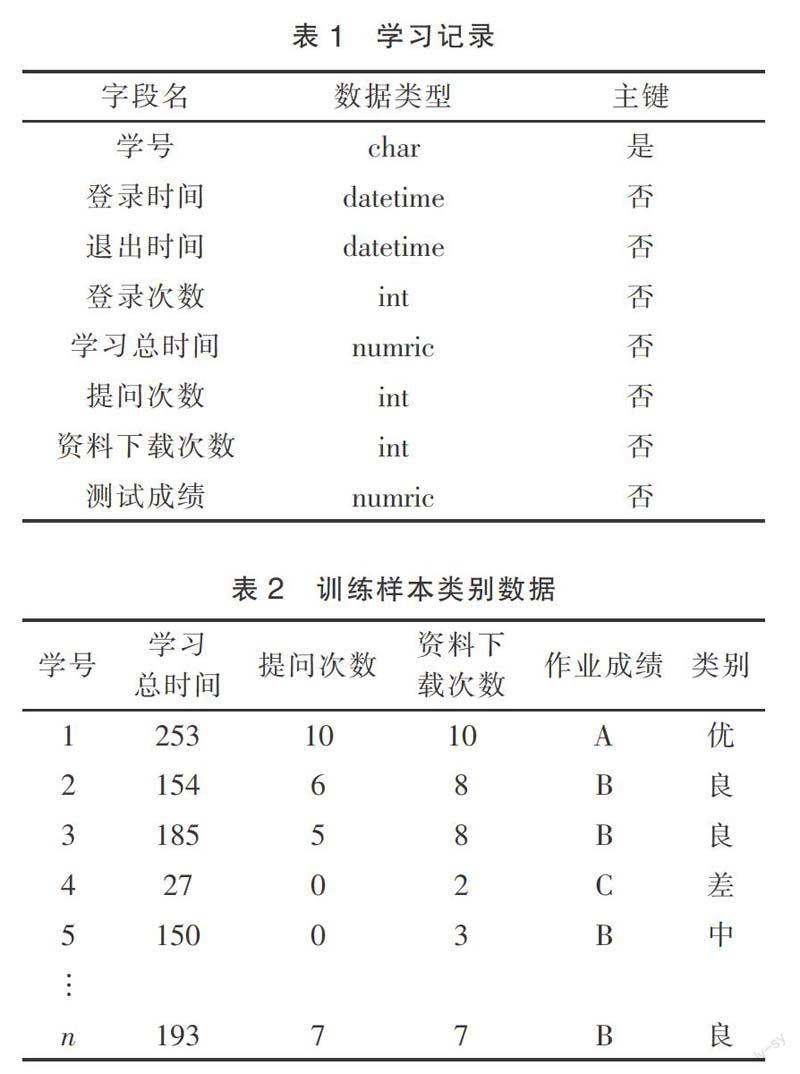
表1为学生学习记录表,从该表中可以获得影响决策的属性,如学习总时间、提问次数、资料下载次数以及测试成绩。利用聚类算法[7]对预处理后的训练数据进行聚类,得到数据集对应的分类,优、良、中、差4个类别,如表2所示。
根据训练样本数据计算各属性的信息熵。表2中部分属性以数值的方式呈现,比如学习总时间,可以对其进行相应转换,转换规则:≥180为学习时间长,100~179学习时间中等,小于100为学习时间短。其他属性可以做同样的转换。以前10条记录为例进行分类模型构建,数据如表3所示。
在属性“学习总时间”上的信息增益:Gain(S,A)=lnfo(S)-lnfo(S,A)=1.295-0.59=0.705位。
同理,为剩余的每个属性计算信息增益,选择最大信息增益的属性进行划分。
Gain(S,“提问次数”)=0.345位;Gain(S,“资料下载次数”)=0.81位;Gain(S,“作业成绩”)=0.97位。因而选择作业成绩作为决策树根节点的划分属性。而后,按照相同的方法进行递归选择,直到数据不能进一步划分为止,最终的决策树如图2所示。
2.2 分类规则描述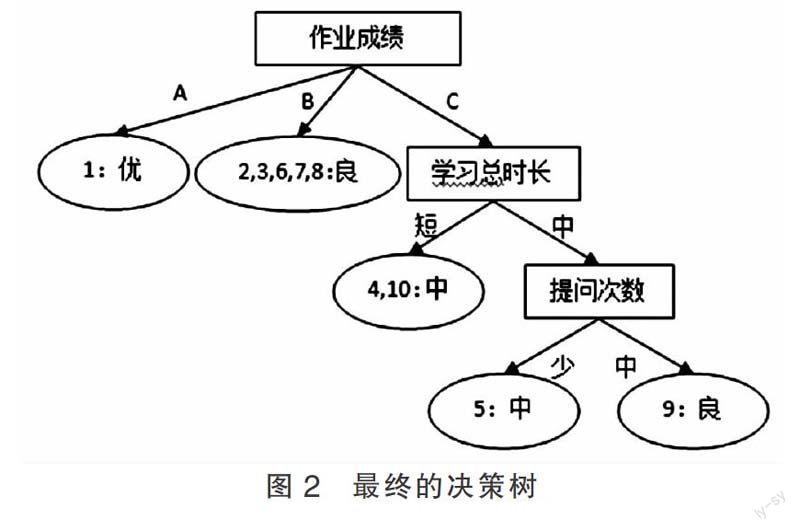
根据最终构建的决策树,可以描述相应的规则,以此作为新数据分类的依据。图2所示的决策树,规则如下:
(1)作业成绩为A,类别为优;
(2)作业成绩为B,类别为良;
(3)作业成绩为C,且学习时长为短,类别为中;
(4)作业成绩为C,学习时长为中,且提问次数为中,类别为良。
(5)作业成绩为C,学习时长为中,且提问次数为少,类别为中。
当有新的学生数据时,可以根据相关的规则推断学生所属的类别。比如一个新的学生数据,学习时长200 min,提问次数3次,资料下载8次,作业成绩A,根据分类得出的规则,该生的作业成绩为A,类别为优。以上结论是由例子中的10条训练数据得出的,当训练样本数据达到一定数据量,所得的规则是有意义和有价值的,可以用来预测新数据所属的类别。
3 结束语
网络远程教育是建立在现代信息技术平台上的一种教学模式,是传统教育的补充。随着计算机技术、网络技术等的不断发展,网络教育也逐渐展现了它的优势。将信息熵理论用于网络教学的学生分类,可以帮助教师为每个群组学生制定不同教学策略,因材施教。
参考文献:
[1] 李青,刘洪沛. 网络课程的设计模式[J]. 北京邮电大学学报(社会科学版),2009,11(1):96-100.
[2] SOMAN K P,SHYAM D,AJAY V. Insight into Data Mining Theory and Practice[M]. 北京:机械工业出版社,2009:4-23.
[3] HU Q H,GUO M Z,YU D R,et al. Information entropy for ordinal classification[J]. 2010,53(6):1188-1200.
[4] Potharst R,Bioch J C. Decision trees for ordinal classification[J]. Intell Data Anal,2000,4:97-111.
[5] 刘红岩,陈剑,陈国青. 数据挖掘中的数据分类算法综述[J]. 清华大学学报(自然科学版),2002,42(6):727-730.
[6] BRESLOW L A,AHA W. Dayid simplifying decision tree:a survey[J]. KnowledgeEngineering Review,1997,12(1):1-40.
[7] 吕晓铃,谢邦昌. 数据挖掘方法与应用[M]. 北京:中国人民大学出版社,2009:77-86.
Abstract: According to the students classification in the network courses teaching, teachers can make corresponding teaching strategies for different kind of students and improve teaching quality. The paper classifies students based on the information entropy theory, constructs decision tree based on information gain by using ID3 algorithm on thedata after preprocessing and generate the corresponding decision rules, which are the basis for the new input data.
Keywords: network course; information entropy; decision tree; information gain
(责任编辑:徐兴华)
猜你喜欢
军民两用技术与产品(2022年1期)2022-06-01
成都信息工程大学学报(2019年3期)2019-09-25
电子制作(2018年16期)2018-09-26
电子测试(2017年12期)2017-12-18
雷达学报(2017年6期)2017-03-26
科教导刊·电子版(2016年26期)2016-11-21
文教资料(2016年19期)2016-11-07
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
池州学院学报(2015年3期)2016-01-05
郑州大学学报(医学版)(2015年1期)2015-02-27
