
多维数据特征融合的用户情绪识别*
2016-05-28 00:51:27史殿习杨若松国防科技大学计算机学院并行与分布处理国防科技重点实验室长沙410073
计算机与生活 2016年6期
陈 茜,史殿习,杨若松国防科技大学 计算机学院 并行与分布处理国防科技重点实验室,长沙 410073
多维数据特征融合的用户情绪识别*
陈茜+,史殿习,杨若松
国防科技大学 计算机学院 并行与分布处理国防科技重点实验室,长沙 410073
Xi,SHI Dianxi,YANG Ruosong.User emotion recognition based on multidimensional data feature fusion.Journal of Frontiers of Computer Science and Technology,2016,10(6):751-760.
摘要:针对目前基于智能手机的情绪识别研究中所用数据较为单一,不能全面反应用户行为模式,进而不能真实反应用户情绪这一问题展开研究,基于智能手机从多个维度全面收集反应用户日常行为的细粒度感知数据,采用多维数据特征融合方法,利用支持向量机(support vector machine,SVM)、随机森林(random forest)等6种分类方法,基于离散情绪模型和环状情绪模型两种情绪分类模型,对12名志愿者的混合数据和个人数据分别进行情绪识别,并进行了对比实验。实验结果表明,该全面反应用户行为的多维数据特征融合方法能够很好地对用户的情绪进行识别,其中使用个人数据进行情绪识别的准确率最高可达到79.78%,而且环状情感模型分类结果明显优于离散分类模型。
关键词:情绪识别;情绪模型;机器学习;智能手机
ISSN 1673-9418CODEN JKYTA8
Journal of Frontiers of Computer Science and Technology
1673-9418/2016/10(06)-0751-10
E-mail:fcst@vip.163.com
http://www.ceaj.org
Tel:+86-10-89056056
1 引言
人类在对外界事物进行探索和认知的过程中,会产生诸如喜悦、悲伤、愤怒、恐惧等主观情感。人们把对客观事物的态度体验以及相对应的行为反应,称为情绪(emotion)[1]。情绪作为一种不同于认识和意识的心理形式,不同程度上影响着人的学习、工作效率以及行为模式,在日常生活中扮演着重要的角色。
情绪识别作为人工智能和普适计算的重要组成部分,受到了业内人士的高度重视,已经成为当下的研究热点,在人机交互、远程教育、医疗保健、心理治疗等多个领域均有广阔的应用前景[2]。因为情绪通常是经由一些外在因素刺激而产生的主观体验(如喜、怒、哀、惧等情感),并伴有外部表现的变化(如面部表情、身体行为和声音语调等)和生理反应的变化(如皮下的特定活动、心率的节奏等),因此可以获得有关情绪状态的一些观测值。假设这些数据的观测值有效可靠,那么就可以根据这些数据把潜在的情绪状态推测出来。
目前,情绪识别领域已经取得了一系列的研究成果,但是绝大多数情绪识别工作都是基于面部表情以及语音语调的分析[3-4]。随着智能手机内嵌传感器的不断增加,通过手机传感器收集人们的日常行为已经变得触手可及。本文采用移动群体感知技术[5-6],并选取智能手机作为传感器数据收集的平台,主要原因如下:首先,智能手机的用户众多,如此大规模的潜在实验数据收集对象是以前的相关研究未能达到的;其次,随身携带手机已经逐渐成为一种习惯,并且随着手机内嵌传感器的增多,捕捉使用者的身体行为变化也变得更加容易;最后,基于智能手机的感知是非干扰式的,用户的参与度低,相较传统的捆绑式传感器基本不会对用户造成困扰。
正是由于智能手机具有上述优点,基于智能手机的情绪识别逐渐成为普适计算领域研究的热点问题,并取得了一系列研究成果,其中最具代表性的工作包括EmotionSense[7]、MoodScope[8]、gottaFeeling[9]等。在此相关工作分析研究基础上,本文针对目前基于智能手机的情绪识别研究中所使用的传感器较为单一,大多数为通讯信息的记录和位置信息,不能全面反应用户行为模式这一问题,使用智能手机从多个维度全面收集反应用户日常行为的细粒度感知数据,采用多维数据特征融合方法,利用支持向量机(support vector machine,SVM)、k-近邻(k-nearest neighbor,kNN)、决策树(decision tree)、AdaBoost、随机森林(random forest)、梯度树提升(gradient tree boosting,GTB)6种分类器以及离散情绪模型和环状情绪模型两种分类方式,对12名志愿者的混合数据和个人数据分别进行情绪识别,并进行了对比实验。实验结果表明,本文提出的全面反应用户行为的多维数据特征融合方法,能够很好地对用户的情绪进行识别。虽然最初使用混合数据训练准确率只有72.73%,但随着对单个用户进行个人数据训练,准确率可以达到79.78%。在情绪分类模型的对比实验中,环状情感模型分类结果明显优于离散分类模型。
本文组织结构如下:第2章对国内外相关工作进行分析和研究;第3章对本文选取的情绪分类模型进行简要描述;第4章描述了总体框架结构;第5章描述了用户问卷调查过程以及统计分析结果,同时对手机数据收集平台以及所收集的多维数据进行了描述;第6章详细阐述了特征提取过程,并设计了多个实验对所提取的特征进行验证;第7章进行了相关工作的比较;第8章对全文进行了归纳总结。
2 基本的情绪识别方法
自从1997年麻省理工学院媒体实验室的Picard教授提出“情感计算”(affective computing)[10]这个概念之后,越来越多的学者对情绪识别展开研究,分别从面部表情、语音语调、生理信号和身体动作与姿势等多种角度对情绪进行识别。
通过面部表情识别情绪的依据在于不同情绪状态下人们的面部表情有显著差异[11],会产生特定的表情模式。美国的心理学家Ekman等人[3]开发了面部运动编码系统(facial action coding system,FACS),并建立了几千幅不同的表情图像库来对面部表情进行研究。随后,研究人员又在FACS的基础上相继采用MPEG-4脸部参数运动法、主分量分析法等多种算法进行识别,但在基于图像的情绪识别中实验样本大多与实际生活中的自然表情有不一致的地方,这种问题带来的影响并不能很好地消除,因此导致识别率低,算法复杂度高等问题。
语音语调作为人类表达自己情感的一种重要方式,早在20世纪80年代就开始了系统性的研究[4]。但是语音信号的情绪识别需要建立庞大的情绪语音数据库,并且个体差异比较明显,而且还需要考虑说话人的内容,因此识别起来难度很大。
生理信号的变化很少受到人们主观意识的控制,因而使用生理信号进行情绪识别相对来说更为客观。但是生理信号存在着信号十分微弱以及干扰源多,噪声大等各种问题[12],并且实验条件苛刻,因此这类方法大多局限于实验室研究。
身体动作与姿势的情绪识别也具有较大的局限性,以往的研究大多是针对各种情绪下的身体姿势提取特征并建立特征库[13]。但很多动作或姿势并不具备明显的情绪特征,因而在识别过程中并不能准确地分辨出结果。
对面部表情和语音进行情绪识别由来已久,但基于身体行为变化的研究则远远滞后于前者,原因在于后者大多是以身体动作与姿态作为研究对象,实验难度相对更大,准确率也更低;而现今智能手机的发展与普及让人们看到了基于身体行为研究情绪识别的一丝曙光。LiKamWa等人建立了心情传感器MoodScope[8,14],他们将用户的通话记录、短信记录、邮件、上网历史、应用程序使用情况以及位置的历史数据进行收集,采用多元线性回归的方法来进行心情的推测。Bogomolov等人[15]也利用手机作为数据采集终端来对用户的幸福感进行识别,以通话记录、短信记录和蓝牙信息作为采集数据辅佐以天气因素和人格测试,采用随机森林的方法进行训练。这些已有的基于智能手机的情绪识别方法研究所使用的传感器较为单一,大多数为通讯信息的记录和位置信息,不能全面地记录用户的行为模式,因此本文在已有研究的基础上进行了相应的拓展,使用数据收集工具在后台对以加速度计、陀螺仪、磁力计为代表的运动传感器数据,以光传感器和GPS为代表的环境传感器数据,还有各种社交信息、手机使用信息和手机状态信息(例如联网状态、充电状态等)采用机会式感知的方式[6]进行收集,以求更全面地感知用户行为,使得对用户情绪的识别更加准确。
3 情绪分类模型
进行情绪识别面临的首要问题是建立情绪分类模型,即如何对情绪进行划分。通常讲,采用一个国际通用的标准便于对不同的研究结果进行比较,虽然学术界关于如何有效地划分情绪状态一直存在争议,但其共同点是都认为情绪与生理反应之间存在一定的映射关系。目前使用较多的分类模型有两种:一种是将情绪以离散的模式划分为几种基本情绪[16-17],如喜、怒、哀、惧;另一种则是认为情绪是连续的,使用维度空间模型进行划分[18]。
3.1基本情绪模型
基本情绪模型认为情绪是离散可分的,由数种基本情绪类型组成。迄今为止,已经有许多研究者对情绪进行了不同精度的划分。其中,在情绪图书馆(emotion library)[19]中定义了14种情绪,但这些情绪中很多具有一定的相似性,区分起来难度很高。因此,本文采取了被社会心理学家广泛使用的一种划分方式,即将情绪图书馆中所有种类的情绪通过聚类的方式划分到5种标准情绪库中,分别为高兴(happy)、悲伤(sad)、害怕(fear)、生气(anger)、中性(neutral)。这5种广义情绪区分度明显,辨识度较高,因此将其作为基本情绪模型中的具体分类进行研究。
3.2维度空间模型
维度空间论则认为,情绪之间不是独立存在的,而是存在着一种连续、渐变的关系。本文采取了较为经典的环状情感模型(circumplex model of affect)[18],如图1所示。这个模型由愉悦(pleasure)维度和活跃(activeness)维度两部分组成。其中愉悦维度用来衡量一个人的感觉是积极还是消极,活跃维度则用来表示一个人在某种情绪下的行为是主动或是被动。图1中,每种基本情绪都可以通过被分解为愉悦度和活跃度从而在环状模型中大致定位。
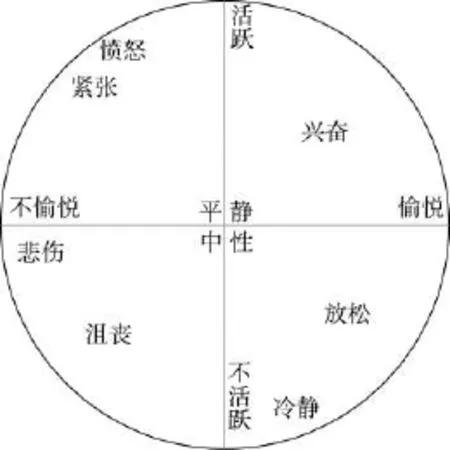
Fig.1 Circumplex emotion model图1 环状情感模型
虽然两种分类模型之间并没有一种精准的转换方法,但也能从中看出它们并不是互相排斥的。因此,本文分别使用这两种分类模型进行了对比实验,以寻求更合适的分类方法,得到更高的准确率。
4 情绪识别的框架流程

Fig.2 Framework process of emotion recognition图2 情绪识别的框架流程
本文所采用的情绪识别框架流程如图2所示。在数据收集前,首先对情绪如何影响人的行为模式进行预调查(采用网上问卷的形式),并以调查结果作为手机数据采集的依据;其次,采用一个基于Android平台的数据收集工具实时采集手机数据,同时开发一个情绪记录工具供用户每天记录;然后,对所采集的多维数据进行预处理、特征提取以及进行多维数据的特征融合;最后,设计多组实验,基于多维数据的融合特征,采用支持向量机等6种分类器以及基本情绪模型和环状情绪模型两种分类方式,对多个人的混合数据和个人数据分别进行情绪识别和对比验证。
5 用户调查和数据收集
作为前期准备,首先设计并在线发布了一份主题为“情绪变化对行为影响”的问卷调查;然后根据问卷调查的统计结果,筛选出需要采集的数据,并且确定用户手动记录情绪的频率。
5.1预调查——网上问卷调查
在数据采集前,首先需要确定收集哪些数据,即情绪的变化可能导致哪些行为发生变化,需要确定可以反映出用户行为变化的手机数据,然后通过这些数据识别用户的情绪。为了获取到最可能反映个人行为变化的传感器数据,设计了一张问卷调查,部分内容如图3所示(完整部分请参考文献[20])。
本次问卷调查从在网上发布到最终回收历时10天,总共有117名参与者匿名参与了问卷调查的填写。经过统计,发现男女人数比例大概维持在1.2:1,即人数大致平等,且超过85%的人处于18岁至30岁,这部分参与者随身携带手机的比例超过90%,因此本文选择智能手机作为传感器数据收集的平台完全合理。结果显示,46.7%的参与者每天使用手机的时间在2小时至4小时之间,33.4%的参与者每天使用手机的时间超过4小时,只有不足20%的参与者使用手机时间少于2小时。另外,大部分参与者认为包括正在使用的应用程序、通话记录、短信、微信、运动情况等在内的多项数据都可以反映出使用者的行为。为此,根据问卷调查的结果选择出需要收集的数据项以及用户手动记录心情的频率,实现准确率高且干扰性低的预期目标。

Fig.3 Questionnaire:effect of emotion changes on behaviors图3 问卷调查:情绪变化对行为的影响
5.2数据收集
本文使用StarLog作为数据收集工具。StarLog是根据需要对UbiqLog[21]进行扩展和改进的一款安卓平台数据收集软件,其主界面如图4所示。根据5.1节统计分析后得到的结果,确定收集以下种类的数据:(1)运动类感知数据,包括加速计、陀螺仪、磁力计以及活动状态(可判定用户处在静止、低速或高速状态);(2)环境类感知数据,包括光传感器和GPS信息;(3)手机使用数据,包括通话、短信、微信、QQ以及蓝牙记录等社交记录,WiFi、App使用、屏幕解锁和锁屏、拍照等使用记录以及手机状态记录(手机模式、是否联网、是否充电)。因为当用户睡觉后手机会处于闲置状态,并且根据实验开始前对志愿者的询问,大多数人会在早上7点至7点半起床,晚上10点半至11点睡觉,且睡觉有关机或者使用飞行模式的习惯,因此文中数据收集时间是每天从早上7点半到晚上10点半,总计15个小时。

Fig.4 Main interface of data collection framework图4 数据收集框架主界面
5.3情绪记录
根据问卷调查统计结果,被调查者选择愿意每4小时或每6小时记录一次的结果总和超过90%,因此,以此作为参考,同时本着对参与者干扰最少的原则,本文最终选择每隔5个小时记录一次用户情绪状态,即每天记录3次,分别代表当日上午、下午和晚上的情绪。为了方便参与者对其情绪状况进行记录,设计并开发情绪记录收集工具,如图5所示。其中,图5(a)上部分有两行滑动条,分别代表愉悦度和活跃度,取值范围为1~5,分别代表非常不愉悦(非常不活跃)、不愉悦(不活跃)、中性(平静)、愉悦(活跃)、非常愉悦(非常活跃);图5(a)下部分是一个离散的基本情绪输入对话框。因此用户需要在图5(a)中采用两种情绪模型分别进行记录,如前文所述,完成记录后需要点击下方保存情绪按钮。图5(b)是一个展示历史情绪记录的界面,用户可以对已记录的情绪进行查看、删除等操作。图5(c)则为文件导出界面,可以将情绪记录数据导出为txt文档或sql数据库格式,并具有清除数据的功能。

Fig.5 Emotion recordApp图5 情绪记录App
6 实验验证和结果分析
6.1实验数据来源
为了验证本文所提出的采用多维数据特征融合方法进行情绪识别的有效性,招募了12名研究生作为志愿者(7名男性和5名女性)进行连续一个月的数据收集工作(全部使用安卓手机)。在数据开始收集前为这12名志愿者进行了数据收集软件和情绪记录软件的安装与使用培训,以确保每个人收到的数据有效、可利用。作为对这12名志愿者的回报,在实验开始时给每人发放了一个容量为32 GB的手机存储卡。
6.2预处理和特征提取
6.2.1运动类感知数据的预处理和特征提取
运动感知数据包括加速度计、陀螺仪、磁力计和活动状态等4类数据。其中,加速度计、陀螺仪和磁力计的数据收集信息包括时间以及相应的三轴数据;活动状态的数据收集信息包括开始时间、结束时间以及这段时间内的状态(静止、慢速或快速)。
进行预处理时,采用了具有50%重叠的滑动窗口对加速度计、陀螺仪和磁力计的数据进行分割,分割后的窗口时间长度一般为5 s;然后再对分割后的数据窗口分别提取最大值、最小值、均值、标准差、波形个数、波峰均值、波谷均值、波峰与波谷差值的最大值、波峰与波谷差值的最小值这9个特征值;又因为这3种传感器都是三轴传感器,所以每种传感器可以提取27个特征。而且,可以根据活动状态的数据(根据加速度计等传感器计算得出)来判断用户每天处于静止、慢速和快速的时间占总时间的比例,可以提取3个特征值,因此运动传感器总共提取出了84个特征。
6.2.2环境类感知数据的预处理和特征提取
环境感知数据包括光传感器数据和GPS数据两类。其中,光传感器数据收集信息包括时间以及相应的光强度;GPS的数据收集信息包括时间、经度、纬度、高度和精度。
将光传感器数据绘制成图后,可以发现其数据数值大小差异明显,当手机放置在衣物口袋或包中时,数值较小,大多集中在0~100之间;当在室内时,大多数是受到灯光照射的情况,数值多集中在100~1 000之间;当处于户外时,受到太阳直射,采集到的数值很大,多集中在1 000~20 000之间。根据这些特点,将光传感器数据进行分类,并提取出3个特征,分别为手机未被使用、在室内使用以及在户外使用的比例。

GPS采用高频进行采集(每30 s记录一次),然后使用K-means聚类算法[22]对数据进行聚类分析,得到用户每天去过的位置个数,为了衡量不同用户在不同位置停留时间长短的比例,采用式(1)进行计算:其中,pi为用户在第i个位置记录的数据占总记录数据的比例。信息熵H(u)表示信息出现的概率或不确定性,可以看作是对信息有序化度量。也就是说当采集的位置越多,熵越大,数据越混乱;采集的位置越少,熵越小,数据越有序。假如某个用户一天都在家中,经过聚类后只有一个位置,那么熵就是0,表示处于一种有序状态。因此,GPS数据的特征值有两个,分别为经过聚类的位置个数以及熵值。
6.2.3手机使用记录相关数据的预处理和特征提取
手机使用记录的数据可以分为社交信息、手机使用信息和手机状态信息3类。
社交信息包括通话记录、短信记录、微信、QQ消息和蓝牙。其中,通话的数据收集信息包括时间、经过加密处理的通话号码、通话时长和通话类别;短信、微信、QQ的数据收集信息包括时间和经过加密处理的通信号码;蓝牙的数据收集信息包括时间、蓝牙地址和连接状态。对此,统计了通话个数,通话时长,最频繁通话时长占总时长的比例,接收短信、微信、QQ消息的条数以及最频繁联系人发送消息总数占总条数的比例,检测到的蓝牙个数以及其中连接过的个数,总共11个特征。
手机使用信息包括WiFi、App使用、屏幕锁屏和解锁以及拍照情况。其中,WiFi的数据收集信息包括时间、SSID、BSSID以及连接状态;App使用的数据收集信息包括开始时间、结束时间以及进程名;屏幕锁屏和解锁的数据收集信息包括屏幕点亮时间、屏幕解锁时间、屏幕暗时间;拍照的数据收集信息包括时间以及相应的经纬度。对此,统计了手机周边WiFi个数以及连接过的个数;统计App使用时间需要对安卓系统或是手机系统软件运行时间进行过滤,即只对前台非系统程序的使用情况进行计算;统计屏幕相关数据时需要对屏幕亮、屏幕暗的时间分别做计算并记录解锁次数;照相情况只需要简单统计次数。因此这部分可以提取7个特征。
手机状态信息对包括时间,铃声模式(铃声开、铃声关),飞行模式(飞行模式开、飞行模式关),网络连接模式(数据流量连接、WiFi连接或者未连接),充电状态(充电、未充电)在内的5种数据进行记录,根据各类数据处于不同模式的比例,提取了9个特征。
6.3实验和结果分析
6.3.1数据筛选和分类实验
实验使用StarLog数据收集平台采集每天上午7:30至夜间22:30总计15个小时的数据,同时将每天记录的3次情绪分别与上午、下午和晚上的数据相对应,作为已提取特征的标签,便于后期进行学习与训练。
本文采用12名志愿者连续一个月的数据总计1 080条(每5个小时采集的数据整体作为一条记录)作为实验数据,但完成收集实验后,经过统计发现数据存在缺少和丢失的现象。调查发现,数据收集过程中存在以下问题:首先,WiFi、蓝牙和GPS需要每天开启15个小时,以及数据收集软件的持续收集造成了耗电量高的现象,因此当不能及时充电时,部分用户会选择暂时停止数据的收集,就造成了传感器数据的缺失;其次,用户并没有对记录情绪这一行为形成习惯,可能有时忘记记录,造成情绪标签的缺失。这两个原因造成了部分数据的不完整,经过筛选,最终选出743条有效数据作为数据样例,其中每条数据样例将各部分特征以等权重进行特征拼接并融合成为一个116维的新特征;然后采用交叉验证的方法对数据进行划分,其中80%作为训练数据,20%作为测试数据。
最终,本实验采用支持向量机、k-近邻、决策树、AdaBoost、随机森林、梯度树提升6种分类器,并基本情绪模型和环状情绪模型两种分类方式对混合数据(全部12人)和个人数据进行对比实验。
另外,对环状情绪模型中愉悦度和活跃度的相关性进行了统计分析,如表1所示。表中P1~P5分别代表非常不愉悦、不愉悦、中性、愉悦、非常愉悦,A1~ A5分别代表非常不活跃、不活跃、平静、活跃、非常活跃。根据统计结果,发现用户情绪处于(P3,A3)的概率最大,其次是(P4,A3)和(P4,A4),这表明用户大多数处于平静状态,并且高兴的概率要远远大于悲伤的概率。其中(P1,A4)、(P1,A5)、(P5,A1)、(P5,A4)的概率为0,充分表明愉悦度和活跃度的统一,二者呈正相关关系。因为本文主要探讨用户的情绪,所以后文中如无特殊提及,环状情绪模型的准确率都是指愉悦度的准确率。
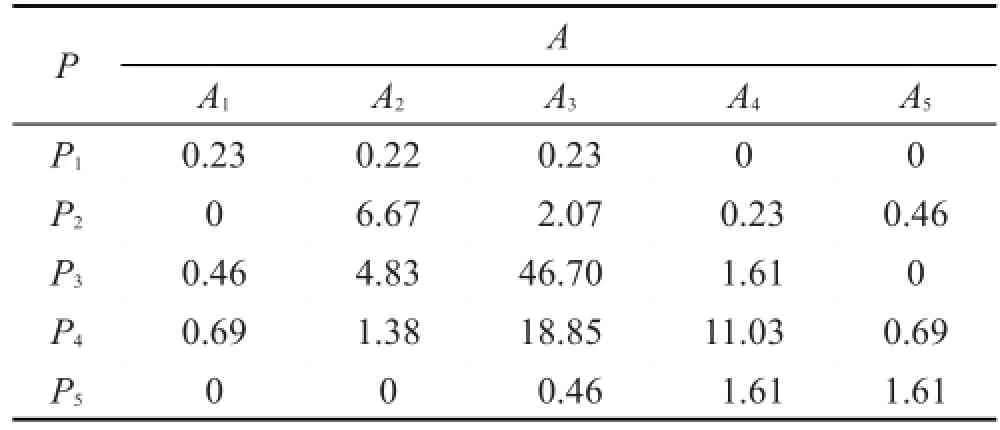
Table 1 Correlation analysis of pleasure and activeness表1 愉悦度和活跃度相关性分析 %
6.3.2实验结果分析
首先,使用混合数据进行分类,实验结果如图6所示。可以看出,当采用基本情绪模型作为情绪分类标准时,随机森林分类器识别的准确率最高,可以达到65.91%;采用环状情绪模型作为情绪分类标准时,也是随机森林的识别率排在首位,可以达到72.73%。
对比两种分类模型准确率,发现在混合数据实验中6种分类器使用环状情绪模型识别的结果都要比基本情绪模型准确率更高。对此实验结果,可以认为连续的情绪比离散的情绪识别度更高的原因在于连续的情绪是一种模糊的衡量方式,它比具体地将情绪划分到某一类更人性化,便于用户选择。在后期回访中,一部分志愿者也曾经表示有时需要记录的情绪并不在备选的5种离散情绪中,不知道该如何选择。关于如何划分类型才能更全面衡量情绪的问题是学术界争论的焦点,这同时也是离散情绪识别过程中需要克服的一个难题。
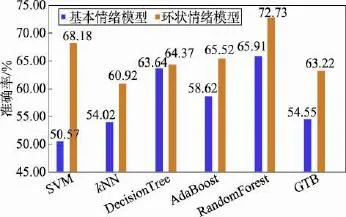
Fig.6 Recognition accuracy rate of hybrid data图6 混合数据情绪识别准确率
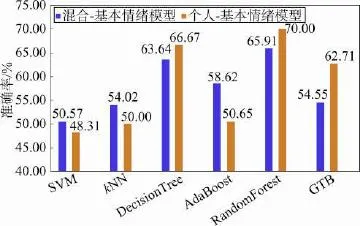
Fig.8 Comparison of discrete emotional model of hybriddata and personal data图8 混合数据和个人数据的基本情绪模型对比
接下来使用个人数据进行分类,将12名志愿者的全部个人数据进行训练后发现,每名志愿者最多有30天的数据量,部分数据缺失对实验结果造成的影响较大,因此选取其中一名数据量最完整的志愿者进行分析。该名志愿者连续30天共计90条450小时的数据记录完整,是参与实验的12名志愿者中数据最多的一人(共计2.65 GB数据),实验结果如图7所示。结果表明,随机森林依然是识别率最高的分类器,对基本情绪模型和环状情绪模型的识别率可以达到70.00%和79.78%;并且使用环状情绪模型识别的结果也比基本情绪模型准确率更高。
通过对比混合数据、个人数据在基本情绪模型以及环状情绪模型下的识别率(如图8和图9所示),可以发现虽然个人数据的最高识别率比混合数据高,但少数分类器也有混合数据识别准确率更高的情况出现。从而可以认为每个用户使用手机的模式都存在差异性,用个人的数据进行训练更容易得到适合用户本身的模型,这样比混合数据更具有针对性,因此得到的准确率更高。然而本实验中,个人数据量相对较少,某些分类器对较少数据的分类结果可能并不理想,有时会出现混合模型准确率更高的情况。
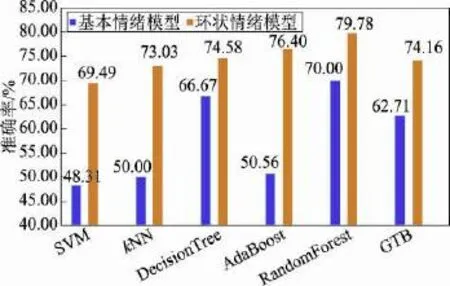
Fig.7 Recognition accuracy rate of personal data图7 个人数据情绪识别准确率
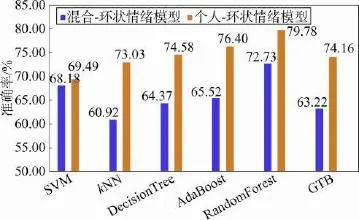
Fig.9 Comparison of circumplex emotional model ofhybrid data and personal data图9 混合数据和个人数据的环状情绪模型对比
7 相关工作比较
gottaFeeling[9]是一个iOS平台上用户记录和分享自己情绪的应用,通过使用这个应用可以增加朋友间互动,提高彼此的亲密度。虽然这个应用并没有进行情绪的推测,但是它为本文的研究提供了值得研究的动机。
EmotionSense[7]选取专业演员进行多种情绪的音频录制,并使用高斯混合模型进行训练,将训练后的声音情绪识别模型装载到手机上,并对高兴、悲伤、恐惧、生气和中性5类情绪进行识别。因为Emotion-Sense中请专业演员进行录制,并且准备了相等数据量的各种情绪数据,所以作为均衡样本,可以分别对每种情绪进行识别,准确率依次达到58.67%、60.00%、60.00%、64.00%、84.66%。但是日常生活中大多数人的情绪是以中性和高兴居多[8],且本文实验采集到的数据也大多集中在中性和高兴两类,与前文所述一致,更具有真实意义。本文的情绪识别准确率指的是各种情绪识别率的平均值,并没有计算单类情绪的识别率,将在下一步工作中针对单类情绪识别做进一步研究。
MoodScope[8]是和本文较为类似的研究,它通过对社交记录(电话、短信和邮件)和日常活动记录(浏览器历史、应用使用记录和历史位置)这两类数据的数据集训练用户的心情模型,最终可以达到93.00%的准确率。本文在数据收集前使用问卷调查的形式充分了解用户使用智能手机的习惯,并最终选择收集3大类共计15种数据,提取了116维特征进行训练。本文采集的数据几乎包括了用户使用手机的各种习惯,提取的数据特征相较来说类型丰富,更有价值性。MoodScope提取特征维数较低,因此同等数据量下准确率更高;随着提取的特征维数的增高,在高维空间下样本分布越来越稀疏,要避免过拟合的出现,就要持续增加样本数量。为了进一步提高情绪识别的准确率,将继续进行数据的收集工作。
8 结束语
本文对用户的情绪进行识别时,分别使用了6种分类器对两种不同情绪分类方式进行识别,结果表明采用随机森林分类器明显优于其他分类器,并且环状情绪模型的识别率较高。每名用户都有自己的手机使用习惯和行为模式,因此使用个人数据将比混合数据更合适。下一步需要持续进行数据的收集工作,并为每个用户建立属于自己的情绪模型,识别出单类情绪,完成一个情绪实时推送平台。
References:
[1]Meng Shaolan.Human emotion[M].Shanghai:Shanghai People’s Publishing House,1989.
[2]Calvo R A,D'Mello S.Affect detection:an interdisciplinary review of models,methods,and their applications[J].IEEE Transactions onAffective Computing,2010,1(1):18-37.
[3]Ekman P,Friesen W V,Hager J C.Facial action coding system[M].Salt Lake City,USA:AHuman Face,2002.
[4]Lee C M,Narayanan S S.Toward detecting emotions in spoken dialogs[J].IEEE Transactions on Speech and Audio Processing,2005,13(2):293-303.
[5]Khan W Z,Xiang Y,Aalsalem M Y,et al.Mobile phone sensing systems:a survey[J].IEEE Communications Surveys&Tutorials,2013,15(1):402-427.
[6]Xiong Ying,Shi Dianxi,Ding Bo,et al.Survey of mobile sensing[J].Chinese Journal of Computer Science,2014,41 (4):1-8.
[7]Rachuri K K,Musolesi M,Mascolo C,et al.EmotionSense: a mobile phones based adaptive platform for experimental social psychology research[C]//Proceedings of the 12th ACM International Conference on Ubiquitous Computing, Copenhagen,Denmark,Sep 26-29,2010.New York,USA: ACM,2010:281-290.
[8]LiKamWa R,Liu Yunxin,Lane N D,et al.MoodScope:building a mood sensor from smartphone usage patterns[C]//Proceedings of the 11th Annual International Conference on Mobile Systems,Applications,and Services,Taipei,China, Jun 25-28,2013.New York,USA:ACM,2013:389-402.
[9]The gottaFeeling application[EB/OL].[2015-06-29].http:// gottafeeling.com/.
[10]Picard R W.Affective computing[M].Cambridge,USA:MIT Press,1997.
[11]Ma Fei,Liu Hongjuan,Cheng Ronghua.Research of facial expression recognization based on facial features[J].Chinese Journal of Computer and Digital Engineering,2011,39 (9):111-113.
[12]Dang Hongshe,Guo Chujia,Zhang Na.Research progress of emotion recognition in information fusion[J].Chinese Journal ofApplicationResearchofComputers,2013,30(12):3536-3539.
[13]de Gelder B.Towards the neurobiology of emotional body language[J].Nature Reviews Neuroscience,2006,7(3): 242-249.
[14]LiKamWa R,Liu Yunxin,Lane N D,et al.Can your smartphone infer your mood?[C]//Proceedings of the 2nd International Workshop on Sensing Applications on Mobile Phones,Seattle,USA,Nov 1,2011.
[15]Bogomolov A,Lepri B,Pianesi F.Happiness recognition from mobile phone data[C]//Proceedings of the 2013 International Conference on Social Computing,Alexandria,USA, Sep 8-14,2013.Piscataway,USA:IEEE,2013:790-795.
[16]Ekman P.Universal and cultural differences in facial expressions of emotion[M]//Nebraska Symposium on Motivation. Lincoln,USA:Nebraska University Press,1971:207-283.
[17]Tomkins S S.Affect,imagery,consciousness[M].Berlin: Springer,1962.
[18]Russell J A.A circumplex model of affect[J].Journal of Personality and Social Psychology,1980,39(6):1161-1178.
[19]Feldman Barrett L,Russell J A.Independence and bipolarity in the structure of current affect[J].Journal of Personality and Social Psychology,1998,74(4):967-984.
[20]The influence of emotion changes in behavior[EB/OL]. [2015-06-29].http://www.sojump.com/jq/4414533.aspx.
[21]Rawassizadeh R,Tomitsch M,Wac K,et al.UbiqLog:a generic mobile phone-based life-log framework[J].Personal and Ubiquitous Computing,2013,17(4):621-637.
[22]Hartigan J A,Wong M A.Algorithm AS 136:a k-means clustering algorithm[J].Journal of the Royal Statistical Society:Series CApplied Statistics,1979,28(1):100-108.
附中文参考文献:
[1]孟昭兰.人类情绪[M].上海:上海人民出版社,1989.
[6]熊英,史殿习,丁博,等.移动群体感知技术研究[J].计算机科学,2014,41(4):1-8.
[11]马飞,刘红娟,程荣花.基于人脸五官结构特征的表情识别研究[J].计算机与数字工程,2011,39(9):111-113.
[12]党宏社,郭楚佳,张娜.信息融合技术在情绪识别领域的研究展望[J].计算机应用研究,2013,30(12):3536-3539.
[20]情绪变化对行为的影响[EB/OL].[2015-06-29].http:// www.sojump.com/jq/4-414533.aspx.

CHEN Xi was born in 1991.She is an M.S.candidate at National University of Defense Technology.Her research interests include distributed computation and mobile sensing.
陈茜(1991—),女,天津塘沽人,国防科技大学计算机学院硕士研究生,主要研究领域为分布式计算技术,移动感知。

SHI Dianxi was born in 1966.He received the Ph.D.degree in computer science from National University of Defense Technology.Now he is a professor and M.S supervisor at National University of Defense Technology,and the member of CCF.His research interests include distributed computing,pervasive computing and software engineering.
史殿习(1966—),男,山东龙口人,国防科技大学博士,现为国防科技大学教授、硕士生导师,CCF会员,主要研究领域为分布式计算,普适计算,软件工程。

YANG Ruosong was born in 1991.He is an M.S.candidate at National University of Defense Technology.His research interests include distributed computation and mobile sensing.
杨若松(1991—),男,陕西咸阳人,国防科技大学计算机学院硕士研究生,主要研究领域为分布式计算技术,移动感知。
*The National Natural Science Foundation of China under grant No.61202117(国家自然科学基金).
Received 2015-07,Accepted 2015-09.
CNKI网络优先出版:2015-10-09,http://www.cnki.net/kcms/detail/11.5602.TP.20151009.1541.002.html
+Corresponding author:E-mail:476330186@qq.comCHEN
文献标志码:A
中图分类号:TP399
doi:10.3778/j.issn.1673-9418.1509014
User Emotion Recognition Based on Multidimensional Data Feature Fusionƽ
CHEN Xi+,SHI Dianxi,YANG Ruosong
National Laboratory for Parallel and Distributed Processing,College of Computer,National University of Defense Technology,Changsha 410073,China
Abstract:This paper studies the problem how to recognize the user emotion based on smartphone data more really. With single data used in the previous research,it cannot make a comprehensive response of user behavior patterns.So this paper collects fine-grained sensing data which can reflect user daily behavior fully from multiple dimensions based on smartphone,and then uses multidimensional data feature fusion method and six classification methods such as support vector machine(SVM)and random forest.Finally,this paper carries out contrast experiments with twelve volunteers’hybrid data and personal data respectively to recognize user emotion based on discrete emotion model and circumplex emotion model.The results show that the multidimensional data feature fusion method can reflect user behavior comprehensively and presents high accuracy.After personal data training,the accuracy rate of emotion recognition can reach 79.78%.In the experiments of different emotion models,the circumplex emotion model is better than discrete emotion model.
Key words:emotion recognition;emotion model;machine learning;smartphone
猜你喜欢
红领巾·萌芽(2022年9期)2022-11-24 05:55:58
英语文摘(2020年5期)2020-09-21 09:26:30
趣味(语文)(2018年8期)2018-11-15 08:53:00
电子技术与软件工程(2016年22期)2016-12-26 21:36:42
科技创新与应用(2016年31期)2016-12-03 03:33:48
海外星云(2016年7期)2016-12-01 04:18:00
时代金融(2016年27期)2016-11-25 17:51:36
科教导刊(2016年26期)2016-11-15 20:19:33
科学与财富(2016年28期)2016-10-14 21:19:17
科教导刊·电子版(2016年10期)2016-06-02 18:04:11
