
一种面向成本驱动的云资源调度策略研究∗
2016-05-16 05:56聂清彬蔡婷张莉萍曹耀钦
新疆大学学报(自然科学版)(中英文) 2016年4期
聂清彬蔡婷张莉萍曹耀钦
(1.重庆邮电大学移通学院,重庆401520;2.四川大学锦江学院,四川锦江620860;3.重庆邮电大学软件工程学院,重庆400065)
0 引言
云计算是通过整合、管理、调配分布在网络各处的计算资源,并以统一的界面同时向大量用户提供服务的新型计算模式.云计算是把具有可伸缩的、动态的、分散的资源进行虚拟化以后以付费的方式提供给用户,用户只需要提交任务给云计算中心,云计算机中心就会分配相应的资源来完成这些任务[1].由于云计算中的任务量巨大,每时每刻都有海量的任务提交给云计算中心,因此对于云计算系统而言,如何采用有效的资源调度算法来合理地分配资源,让整个云计算资源得到充分利用、降低任务执行成本,提高执行效率是研究的重点.
很多学者提出了用改进的蚁群算法来更好的解决云环境下的任务调度,如张秋明[2]提出采用蚂蚁系统的伪随即比例规则进行寻优,防止算法过快收敛到局部最优解,同时结合最大最小蚁群的设计思想完成信息素的更新,有效地解决优化问题,提高了云资源的利用率;魏赟,陈元元[3]提出了一种能改善任务并行性和兼顾任务串行关系的改进蚁群算法DSFACO,把提交的任务细分成能互相制约关系的子任务,根据执行先后次序放到不同优先级的调度队列中,缩短了任务的延迟时间,实现了云环境下任务的最优分配;张焕青,张学平[4]提出了基于虚拟机负载均衡的蚁群优化算法LBACO,通过调整信息素因子,改进信息素更新规则,实现任务调度的负载均衡;华夏渝,郑骏,胡文心[5]提出了一种基于改进蚁群算法的计算资源分配算法,在资源调度之前,首先对可用节点的计算能力进行预测,分析线路质量、带宽的使用情况以及响应时间等因素对资源调度的影响,通过蚁群算法计算出最优的资源,该算法在符合云计算环境配置的前提下,对比以往的网格分配算法,具有更优的调度效果和更短的响应时间.这些算法都不同程度地优化了云计算中资源调度的过程,但是都鲜有考虑到成本因素,就和日常购物一样,消费者购买同样的商品都需要对比不同的价格,往往在同等条件下选择价格更低的商品.云计算任务分配也一样,用户都要考虑任务的执行成本以及负载.因此为了降低任务执行成本,同时使云计算中心负载更加均衡,本文在已有的蚁群算法基础之上提出基于负载均衡的改进蚁群算法(Cost and Load balance Ant Colony Optimization(CLBACO)来实现对子任务的分配.
1 云计算中任务调度问题的描述
目前,云计算环境下任务调度很多都采用Google提出的Map/Reduce的分布式编程模式[6],分成Map(映射)和Reduce(化简)两个阶段:在Map阶段,将用户提交的任务划分成一些小的子任务,然后分配到若干个虚拟机节点上并发地执行,执行结束并输出结果;在Reduce阶段,将Map阶段输出的结果进行汇总处理,并把最终的处理结果交付给用户.在Map/Reduce计算编程模式下,如何对分割的子任务进行高效低成本的调度是算法的关键.
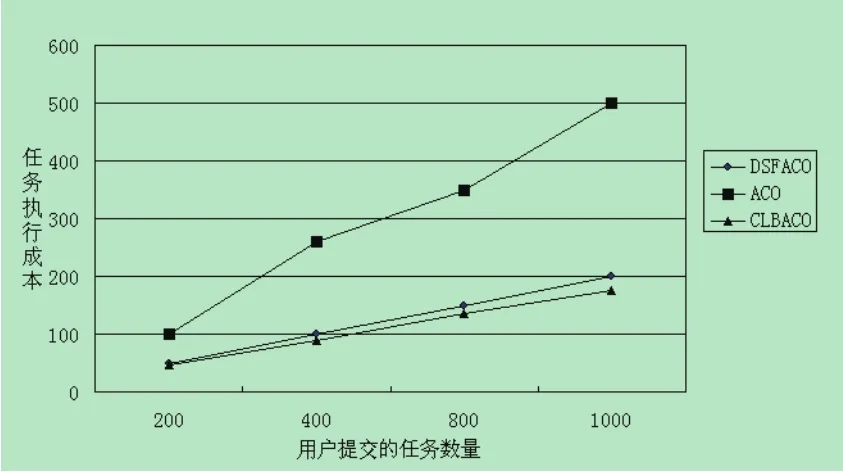
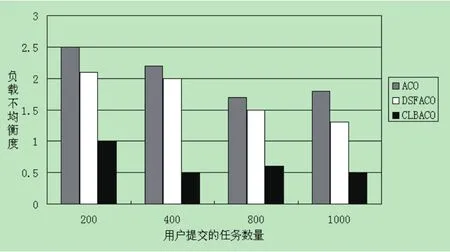
在云环境中,将n个分别独立的子任务分配到m个虚拟机上并行执行(m 虚拟机vmj上执行的任务成本之和 执行完所有任务云计算中心所需的总成本为 云计算中心的平均成本为 蚁群算法是由M.Dorigo等人在20世纪90年代提出的一种启发式仿生算法[7],它模拟蚂蚁群体觅食过程.在蚂蚁寻找食物过程中,在其经过的每一条路经上遗留下一种信息,叫信息素(pheromone).这些路径上已经留下的信息素的浓度大小对后续蚂蚁选择自己下一步的走哪条路径具有很大的影响.一般情况下,蚂蚁都会选择信息素浓度更高的路径.如果有更多的蚂蚁倾向选择某一条路径,则在该路径上留下的信息素浓度也就越高,这样后续的蚂蚁选择该路径的概率也就越大.大量蚂蚁选择信息浓度高的路径的行为就体现出蚁群的整体运动机制.最终搜索到一条较短的觅食路径,该算法具有正反馈鲁棒性、并行性、可扩展性以及高求解精度,并且易与其他方法结合的优点.能在海量的解空间中最大限度地寻找全局最优解,特别是在解决组合优化问题方面,根据状态转移概率来搜索解的空间,结合信息素的更新,找到最优解.本文提出基于执行成本的改进蚁群算法,在标准蚁群算法的基础上为降低任务执行成本对云计算任务分配算法进行改进,提出信息素改进因子PIF,改进信息素的更新规则,使得在执行同等任务的情况下,任务的执行成本最低,虚拟机的利用率最高. 结合蚁群算法公式(5)计算出任务ti被分配到虚拟机vmj的概率值 其中τij(t)表示在t时刻路径(i,j)上的信息素浓度;ηij(t)表示在t时刻路径(i,j)上的启发信息;α为期望启发因子,表示蚂蚁在任务调度过程中的启发信息对任务选择的相对重要程度;β为信息素启发因子,表示路径上的残留信息素浓度对任务选择的影响程度;tabuk(k=1,2···n),记录蚂蚁已经走过的城市,被访问过的城市会加入禁忌表;allowedk表示第k只蚂蚁允许访问的下一个城市的节点,是禁忌表之外蚂蚁还没走过的城市.设置蚂蚁的迭代次数为nc,最大迭代次数为ncmax. 在蚁群算法中,信息素τij(t)和启发函数ηij(t)是最重要的参数.由于云计算的动态性和异构性,本文通过虚拟机的计算能力、网络带宽和执行成本对启发函数和信息素进行初始化, 其中表示虚拟机vmj的处理器数量,表示虚拟机vmj处理器运算速度,表示虚拟机vmj网络带宽,表示虚拟机内存. 在进行任务分配选择虚拟机过程中,可以通过轮盘赌算法来决定某一个任务分配到哪个虚拟机上去执行.首先通过概率转移公式(5)计算出任务ti分配到虚拟机vmj的概率,这就相当于构造出赌盘上的一个扇区,赌盘上的扇区分区面积越大,指针指向该分区的概率也就越大.任务分配到该虚拟机的概率值对应每个分区的大小,则任务分配到该虚拟机的转移概率值越大,更有可能被选中来执行下一个任务. 当蚂蚁将任务分配到虚拟机上以后,随着迭代次数的增加,原有的信息素就会随之增加.如果不对路径上残留的信息素进行更新,算法将会陷入局部收敛的状态,因此在每只蚂蚁完成任务分配时,就利用公式(8)进行信息素更新 其中:ρ是信息挥发因子,表示信息素在单位时间内的挥发程度;1−ρ表示信息素浓度残留程度,ρ∈(0,1],如果ρ越大,说明信息素挥发越快,则过去搜素过的路径对现在的选择影响也就越小;∆τij表示信息素浓度的增量,用执行成本costij对信息素增量∆τij进行改进,改进的信息素更新分为局部更新和全局更新. (1)当一只蚂蚁通过路径搜素,也就是任务被分配到某一个虚拟机上,找到了相应的分配方案以后,路径上所有的虚拟机都将进行一次局部信息素更新,此时∆τij定义如下: 其中D1表示常量,costij表示第i只蚂蚁在vmj上的执行成本. (2)当所有蚂蚁完成路径搜素后,找到本次迭代中最优的路径,然后对路径上的所有虚拟机进行全局信息素更新,此时∆τij定义如下: 其中costtotal−best表示在第本次最优分配方案中为任务搜素到的最低执行成本,D2为常量. 在虚拟机vmj负载不均衡度定义Lj如下: costj表示虚拟机vmj上的执行所有任务所需成本,costavg表示所有虚拟机执行任务的平均成本. 在实际云环境中,由于云计算资源存在动态性和异构性,每个虚拟机的网络带宽、计算能力、内存大小等差异较大,单位时间内执行任务的成本有较大差别;有的虚拟机性能较差,有的虚拟机性能明显较好,这样就容易造成大量任务聚集到一部分性能高的虚拟机上执行,而且容易造成等待的任务增多,同时另外性能较差的虚拟机资源却处于闲置的状态,使得整个云计算中的资源利用率很低[8].为了解决这个问题,本文提出改变信息素更新规则,信息素中一方面要考虑虚拟机执行任务成本,另一方面可以通过成本改变虚拟机的负载不均衡度,通过改进信息素更新规则可以让闲置的虚拟机分配更多的任务,为分配过多任务的虚拟机减轻负载,改进信息素因子PIF定义为: 如果虚拟机vmj在之前迭代过程中负载过重,执行同样的任务,执行时间会更长.根据公式(1)计算,执行任务的成本就会比其他虚拟机完成该任务的成本更大,则虚拟机vmj的信息素调整因子PIF和其他虚拟机因子相比,PIF更大,则τij(t+1)变小,根据公式(5)进行任务分配时,虚拟机vmj被分配到任务的概率变小,经过算法多次迭代以后,改进后的算法最终能实现云计算中心虚拟机的负载平衡. 第1步:初始化云计算机中所有虚拟机的信息素的值,信息素启发因子α和挥发因子ρ,期望启发因子β,蚂蚁个数m,设置迭代次数nc=0以及最大迭代次数ncmax; 第2步:将蚂蚁随机地选择任务; 第3步:根据公式(5)计算每个虚拟机被选中的概率,通过轮盘赌算法确定最终执行任务的虚拟机; 第4步:如果完成本次任务分配,根据公式(9)进行局部信息素的更新,否则跳转到步骤2; 第5步:如果所有蚂蚁完成了本次任务的分配,根据分配情况找出本次任务分配中最优的分配方案,根据公式(10),通过本次的最优解进行全局信息素更新; 第6步:判定当前迭代次数是否达到最大迭代次数,如果是,结束算法流程;如果没有,跳转到步骤2继续执行. 为验证算法的有效性和可行性,选择云计算仿真平台CloudSim3.0进行仿真实验,利用CloudSim里面的Cloudlet,DataCenter,VM以及一些辅助类来模拟云计算环境及网络资源,创建任务和虚拟机,并重写DataCenterBroker,Cloudlet类来构造CLBACO算法;模拟云计算的真实环境,并在基于同样配置和参数设置的条件下与标准的蚁群算法以及文献[3]中的云计算中改进任务调度算法DSFACO进行对比. 在实验中,对CloudSim模拟器参数进行设置,设置数据中心为20个,每个数据中心设置10个虚拟机.虚拟机性能参数设置为500∼2000MIPS,内存为512-2048MB,带宽为5000∼10000b/s,任务指令长度为300∼3600 MI(Million Instruction),任务数量为200∼1000个任务,虚拟机单位时间运行所消耗成本rcu(vmj)值为20$,最大迭代次数ncmax为50次,在资源中心执行时间共享和空间共享的策略,调度算法中的参数设置为:α=1,β=3,ρ=0.02,CloudSim仿真步骤如下: 步骤一:初始化CloudSim包;步骤二:创建数据中心;步骤三:创建数据代理中心;步骤四:创建虚拟机;步骤五:创建云任务;步骤六:调用任务调度策略,分配任务到虚拟机;步骤七:启动仿真;步骤八:仿真结束后分析结果. 试验中在同等条件下将标准的蚁群算法ACO,文献[2]中的DSFACO算法和本文的CLBACO算法进行试验仿真,对比任务的执行成本以及虚拟机的负载率状况,具体实验数据如图1所示,图中任务执行成本单位为美元($),执行时间单位为s(second). 图1 任务执行成本比较 图2 负载均衡率比较 从图1可以看出,当任务量较少时,CLBACO和DSFACO算法执行成本差别不大;随着任务数量的增加,执行同样多数量的任务,CLBACO算法的执行成本明显降低.说明通过本算法改进信息素的局部更新和全局更新,可以达到让任务执行成本降低的目的. 图2反映了虚拟机的负载不均衡度对比.从图中可以看出:标准的蚁群算法ACO负载不均衡度是最高的,说明负载不平衡;DSFACO算法负载有所改进,但是算法改进不够明显;CLBACO算法相比前面两种算法将负载不均衡度降低了0.5-1.2左右,在有效降低成本的同时,也很好的实现了负载均衡. 本文提出了基于成本约束函数、负载均衡的改进蚁群优化算法CLBACO,用来改进云计算中的资源调度.实验结果表明,CLBACO算法性能明显优于DSFACO算法,有效优化了资源的调度,降低了任务执行成本,提高了系统执行任务效率,让云计算系统始终保持在一个负载均衡的状态. 参考文献: [1]李依桐,林燕.基于混合粒子群算法的云计算任务调度研究[J].计算技术与自动化,2014,33(1):73-77. [2]张秋明.基于改进蚁群算法的云计算任务调度[J].电子技术应用,2015.41(2):120-126. [3]魏赟,陈元元.基于改进蚁群算法的云计算任务调度模型[J].计算机工程,2015,41(1):12-16. [4]张焕青,张学平,等.基于负载均衡蚁群优化算法的云计算任务调度[J].微电子学与计算机,2015,5(5):31-40. [5]华夏渝,郑骏,胡文心.基于云计算环境的蚁群优化计算资源分配算法[J].华东师范大学学报,2010,2(1):127-134. [6]查英华,杨静丽.改进蚁群算法在云计算任务调度中的应用[J].计算机工程与设计,2013,34(5):1716-1816. [7]董云红,高志栋,等.基于蚁群算法的云计算资源调度研究[J].中国西部科技,2013,12(4):29-31. [8]董丽丽,黄贲,介军.云计算中基于差分进化算法的任务调度研究[J].计算机工程与应用,2014,50(5):90-95.



2 基于成本改进的蚁群调度算法
2.1 虚拟机的选择
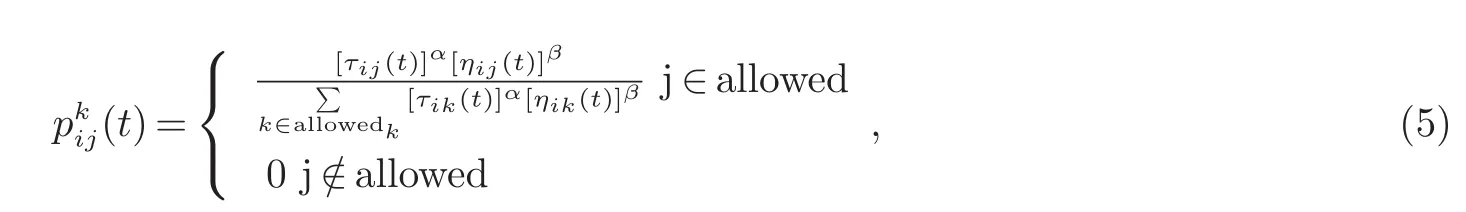
2.2 初始化信息素和启发信息
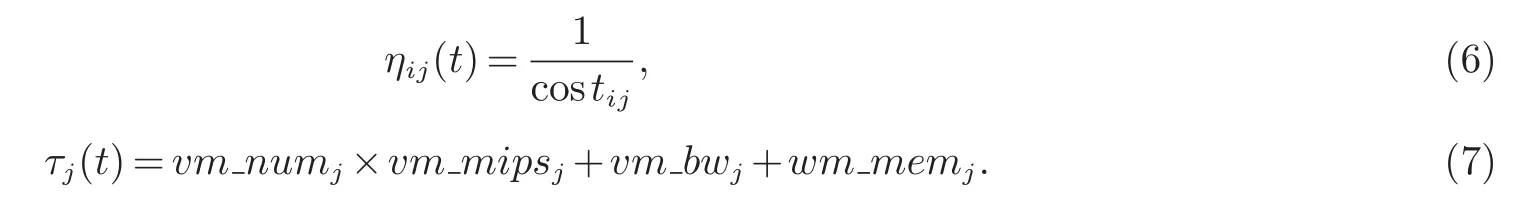
2.3 信息素的更新



2.4 负载不均衡度的定义

2.5 信息素改进因子的建立
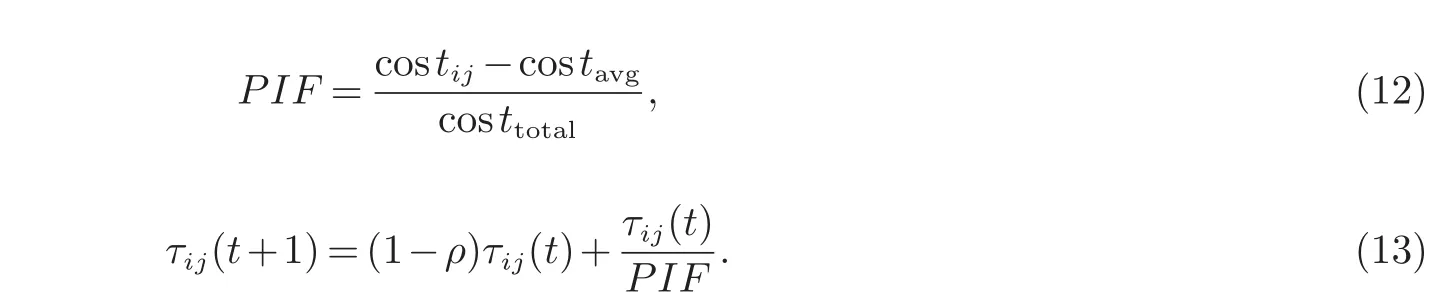
3 算法流程
4 仿真实验结果与分析
5 结束语
猜你喜欢
现代装饰(2020年8期)2020-08-24
数字通信世界(2020年3期)2020-04-06
创新作文(3-4年级)(2019年5期)2019-11-22
制造技术与机床(2019年4期)2019-04-04
现代电子技术(2018年22期)2018-11-13
少儿科学周刊·儿童版(2017年5期)2017-06-29
学苑创造·A版(2017年3期)2017-04-27
现代防御技术(2016年1期)2016-06-01
计算技术与自动化(2014年1期)2014-12-12
学苑创造·A版(2014年6期)2014-08-04
