
基于机器学习的邮件信息处理技术的研究
2016-05-14 22:34薛益定刘杨圣
网络空间安全 2016年4期
薛益定 刘杨圣
【 摘 要 】 针对当前网络上垃圾邮件无法识别的问题,论文设计出邮件信息处理系统来分析邮件。首先,对机器学习进行详细的描述;其次,对电子邮件的数字信息处理的流程和关键算法进行分析;最后,给出了邮件信息处理系统的分类器的模型及功能实现。论文对于办公人员和人工智能研究人员都具有一定的积极意义。
【 关键词 】 机器学习;邮件;信息处理
【 Abstract 】 Aiming at the problem that the spam can not be identified on the current network, this paper designs the mail information processing system to analyze mail. Firstly, to describe the machine learning; secondly to e-mail the digital information processing process and key algorithms are analyzed. In the end, the model and function realization of the classifier of mail information processing system are presented. This paper has a certain positive significance for the office staff and the artificial intelligence researchers.
【 Keywords 】 machine learning; mail; information processing
1 引言
随着信息技术的不断提高,电子邮件信息的传递已经不仅仅局限于文字的描述,图片、动画、视频、音频等表现形式越来越多地出现在邮件中,传统的信息处理技术已经不能满足当前邮件信息处理的需要。机器学习是通过数字信息处理的经验不断进行在我学习的智能信息处理技术,利用机器学习可以有效解决当前邮件中各类信息的处理难题。
2 机器学习
2.1 机器学习概况
用机器代替人类,一直是IT行业研究和关注的热点话题,人类除了会主动自觉劳作以外,最主要是人类具有学习,而机器只会按照预先设定步骤进行工作。人工智能研究的重点就是使机器具有一定的学习能力,这样可以使得机器不断自我完善,进而获得知识,这使得机器学习在智能研究中占据着非常重要的地位。
机器学习是研究让机器模拟人类自我学习的一门学科,具有学习能力的机器可以在不断的重复工作中根据情况的变化而使得自身的适应能力不断加强和改进,进而提高了工作的效率。机器学习是建立在一定的环境之上,不断进行学习,并将学习的内容加入到知识库中,为以后的工作提供参考,在工作的过程中,根据知识库提供的经验和要求,去执行相对应的步骤。
机器学习主要有两个任务:一是对数据进行分类,如文字识别、图像处理、语音信号等;二是获得控制分析、解决问题的能力,通过分类的精度和分析的正确与否来对学习的性能进行评价。
2.2 机器学习方法
机器学习自诞生以来,就受到了业内的欢迎,特别是近20年来,机器学习随着网络技术的发展,得到了迅猛的发展,机器学习的相关学术探讨活动日益活路,越来越多的机器学习方法得以在实践中应用。当前,机器学习的方法主要有几种。
(1)贝叶斯分类,通过对样本的属性概率进行计算,进而得出待解决问题样本隶属类的概率大小,该方法是统计学分类的范畴。
(2)K-最邻近分类,通过搜索数据空间,查找出与未知样本最相似的K个样本进行计算分析,进而预测推出未知样本的输出值。
(3)遗传算法,该方法是模拟生物进化的过程,首先随机的方式创建一个群体,根据生物学中“适者生存、优胜劣汰”的原则,通过制定合适的规则产生新的群体,并利用变异和交叉等遗传操作来不断进化,直至达到合适的阈值为止。
(4)回归分析,通过对客观事物进行大量的观察和实验,分析变量间的统计关系,找到隐含在变量之中的规则。
(5)判定树归纳分类,将众多样本生成树结构,分析每个树上节点的属性,分支代表测试的输出,而节点表示类。通过判定树来确定待分析样本的具体分类。
(6)人工神经网络,将一组相互有联系的输入和输出样本进行学习,不断调整彼此联系的权值,进而得到预测值。
3 邮件数字信息特征提取方法
电子邮件以速度快、内容量大的优点给人们带来了巨大的便利,但是随着信息技术的不断发展,人们对于电子邮件的利用越来越广泛,同时也产生了大量的垃圾邮件,给人们的生活带来了巨大的不便,影响了企事业单位的日常办公。通过机器学习技术对邮件进行处理,分析电子邮件的特征,划分正常邮件和垃圾邮件,将垃圾邮件剔除,可以极大地提高个人的办公效率。
3.1 邮件数字信息处理的流程
首先对电子邮件的数字信息进行分词,将一个完整的电子邮件信息分解成由若干分词组成的数据信息集合空间;然后对邮件的数据空间进行处理,降低数据空间的维度,进而缩小数据空间向量的规模,使得机器学习算法更容易去处理,减少系统计算的时间;其次针对数字信息的特征进行选择,计算数字信息特征项在整个电子邮件中的比重,得出邮件数字信息特征向量;最后将邮件信息中的分词与特征项进行计算比对,对于不符合要求的电子邮件进行剔除,从而保留了正常邮件。
对于邮件的分词数据空间进行降维操作,其主要是电子邮件的数据信息量非常庞大复杂,其分词空间的维数一般情况下都非常高,甚至可能达到几万维,这使得机器学习算法在对样本进行处理时,完全超出了计算的范畴。
3.2 邮件信息处理算法
4 基于机器学习的邮件信息处理系统的实现
4.1 系统的分类器模型
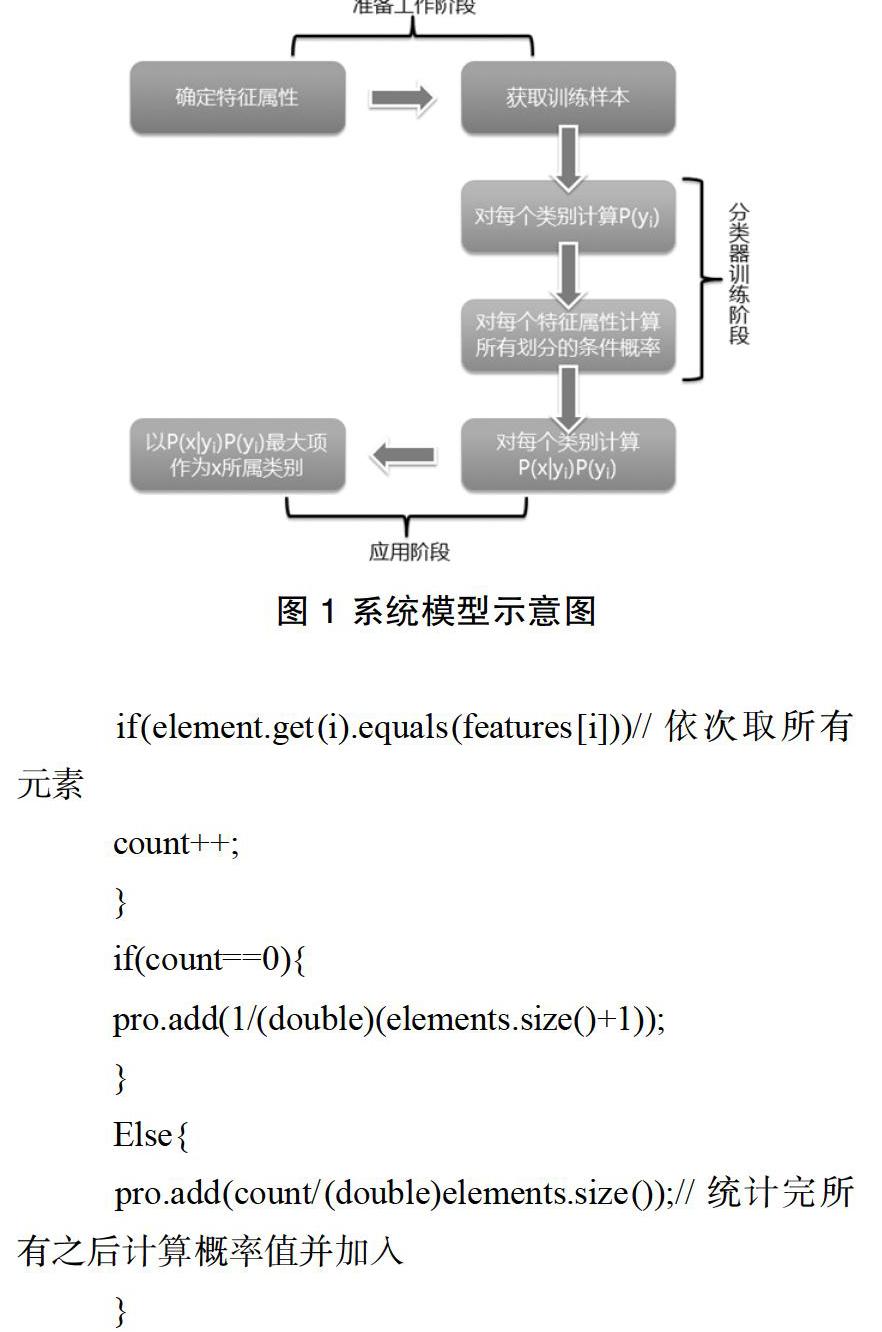
接收的新邮件是正常邮件还是垃圾邮件,通过贝叶斯算法为核心的分类器得出。整个系统由训练模块和分类识别模块两部分组成,训练模块主要进行新邮件的数字信息预处理、对分词进行特征选择、分类器组成;分类识破析模块主要由邮件决策判断过程组成。分类器是整个系统的核心,分类器如图2所示。
由朴素贝叶斯算法设计的分类器由三个阶段完成。
(1)准备工作阶备。根据电子邮件的特性,设置分词空间的特征属性,并从样本空间中获取一部分分类项作为训练样本。
(2)分类器训练阶段。根据每个类别在训练样本中的出现的频率计算其概率P(yi),并根据每个特征属性计算所有划分的条件概率。
(3)应用阶段。计算每个类别P(x/yi)P(yi),其中最大项就是样本所属的类别。进而判断邮件属于正常邮件还是垃圾邮件。
4.2 功能模块实现
5 结束语
基于机器学习的邮件信息处理技术可以有效地判断正常邮件和垃圾邮件,帮助人们提高日常的工作效率,使之不受垃圾邮件的干扰。本文对机器学习中的朴素贝叶斯算法进行分析,并作为邮件处理系统的核心算法,由于本文的篇幅所限,对于系统的其他代码无法具体给出。
参考文献
[1] 纪思捷,胡豪杰.基于机器学习算法的大数据处理[J].电子技术与软件工程,2015,23,202.
[2] 苏翔.基于机器学习方法实现购物网站用户反馈信息聚类[J].信息与电脑,2015,8,42-44.
[3] 吴启晖,邱俊飞,丁国如.面向频谱大数据处理的机器学习方法[J].数据采集与处理,2015,4,703-713.
[4] 贾慧星,章毓晋.智能视频监控中基于机器学习的自动人数统计[J].电视技术,2009,4,78-81.
[5] 谷强,汪叔淳.智能制造系统中机器学习的研究[J].计算机工程与科学,2000,1, 59-62.
作者简介:
薛益定(1991-),男,浙江苍南人,硕士研究生;主要研究方向和关注领域:机器学习、文本挖掘、文本情感分析。
刘杨圣 (1992-),男,贵州贵阳人,本科;主要研究方向和关注领域:数据额挖掘。
猜你喜欢
中学生学习报(2022年35期)2022-07-07
疯狂英语·新阅版(2020年11期)2020-12-21
时代金融(2016年27期)2016-11-25
艺术科技(2016年9期)2016-11-18
科教导刊(2016年26期)2016-11-15
数字技术与应用(2016年9期)2016-11-09
科学与财富(2016年28期)2016-10-14
电脑爱好者(2012年22期)2012-11-19
信息化建设(2009年7期)2009-09-19
