
图书馆图书推荐算法的研究
2016-05-14 04:04丁岚
数字技术与应用 2016年5期
丁岚

摘要:图书馆数字化研究对于提高图书馆的服务质量有着非常重要的意义。本文从图书推荐入手,介绍了协同过滤算法可以分为基于模型的协同过滤算法和基于记忆的协同过滤算法,着重介绍了基于记忆的协同过滤算法中的基于项目的协同过滤算法,阐述了算法的原理和基本步骤,为下一步的应用奠定了基础。
关键词:图书推荐 协同过滤 相似度
中图分类号: TP391.3 文献标识码:A 文章编号:1007-9416(2016)05-0000-00
1 引言
数字图书馆逐渐向自动化、智能化、个性化发展。数据资源丰富,属性众多,信息冗杂,但是有效利用率并不高,而且读者接受的服务并不具有针对性。个性化图书推荐可以根据个人图书借阅历史、用户的浏览痕迹和用户的资料,找出学生或者老师可能感兴趣的图书,由此向学生或者老师推荐相关的图书,图书推荐的方式有很多方法,例如基于内容的推荐、基于关联规则的推荐和基于协同过滤的推荐等。
协同过滤是分析用户兴趣,并找出与当前用户有共同喜好的用户,然后根据相似用户对某一项目的喜好度,预测当前用户是否喜欢此项目,由此作出推荐。算法的推荐原理非常的简单。用户的信息与项目在预测部分要事先预处理下,然后输出推荐的结果。
2 协同过滤算法的分类
根据Breese等学者的研究,可将协同过滤算法分为两大类:基于模型的协同过滤算法(Model.Based Collaborative Filtering)和基于记忆的协同过滤算法(Memory—Based Collaborative Filtering)。
基于模型算法的主要思想是根据机器学习或者统计方法对用户的评分信息进行建模,通过建好的模型来预测用户的喜好度,以此来作出推荐。常用的建模算法有潜在语义技术、聚类技术、Bayes算法以及支持向量机等算法。支持向量机算法具有实时性较好,稳定性较高,但是需要建立大量的模型,并且费用较高。
基于记忆的协同过滤算法主要分为基于用户的协同过滤算法(User-based Collaborative Filtering,UBCF)和基于项目的协同过滤算法 (Item-based Collaborative Filtering,IBCF)两类。在本文中,将详细介绍基于项目的协同过滤算法。
3 基于项目的协同过滤算法
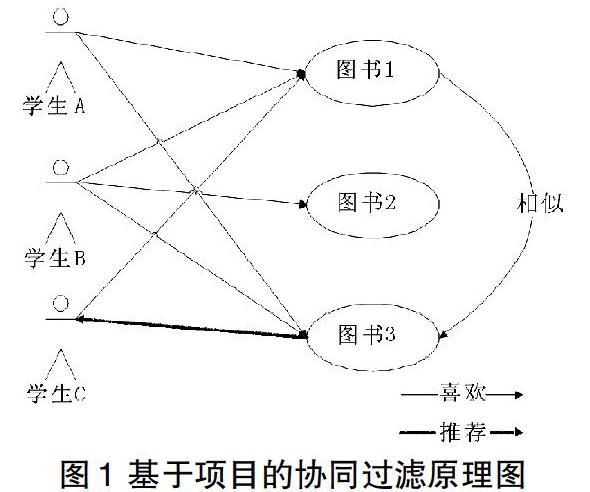
基于用户的协同过滤推荐算法㈣有扩展性和稀疏性问题,在2001年,Sarwar等人提出了基于项目的协同过滤算法[351。其基本原理用户对项目进行喜好评分,根据这些评分计算项目之间的相似度,把相似的项目推荐给用户。原理如图1所示。
从图1中可以看出学生A对图书1和图书,3感兴趣,学生B对图书1、图书2和图书3感兴趣,学生C对图书1感兴趣,可以推出,图书1和图书3是比较相似的,对图书1感兴趣的学生可能也对图书3感兴趣。由此也可以推出学生C对图书3也比较感兴趣,可以考虑将图书3推荐给学生C。
基于项目的协同过滤算法主要有三个步骤,先计算项目之间的相似度,然后选择近邻,最后作出推荐。
(1)项目之间相似度的计算。常见的计算相似度的算法有Pearson相关系数法 (Pearson Correlation Coefficient)、余弦相似度法 (Cosine Similarity)和调整余弦相似度法(Adjustment Cosine Similarity)。例如:Pearson相关系数:计算两个项目之间的线性关系,如式(1)所示
在上式中,表示项目u和v之间的相似度,是用户u对项目i的评分,是用户v对项目i的评分,是用户u在已经评价过的项目上的平均分,是用户v在已经评价过的项目上的平均分。
(2) 寻找相似邻。计算了项目之间的相似度后,寻找相似近邻。最常用的寻找相似近邻有K均值方法和设阈值法。
(3)产生推荐。主要有两种方法:Top-N推荐列表和预测当前用户对项目的评分。考虑到求平均值是不太理想的,有人提出了使用加权平均值方法。主要两种方法,具体如式(2.10)与式(2.11)所示。
其中,为项目间的相似度,项目间的相似度越大,则预测评分的影响就也越大。
4 算法实验验证
本文实验评估仍然基于Book.Crossing数据集,学校图书馆中用户对图书的评分从2003年到2015年的评分有1e10条记录,是由1e6个用户对5e5的评分,这些评分是O~5,0表示用户不喜欢,5表示用户非常的喜欢该本图书。对算法进行测试,测量真实评分与预测评分之间的平均绝对误。算法运行5次,平均误差小于0.5%,因此,说明算法具有很好的推荐效果。
5 结语
阐述了协同过滤推荐算法的相关理论,重点介绍基于项目的协同过滤算法,算法的步骤可以分为项目之间相似度的计算、寻找相似邻和产生推荐三个方面。实验结果表明,该算法具有一定的推荐效果。
参考文献
[1]聂飞霞.高校图书馆个性化图书推荐系统设计[J].情报探索,2014,1(195):115-118.
猜你喜欢
中国新通信(2016年22期)2017-01-13
计算技术与自动化(2016年4期)2017-01-11
软件导刊(2016年11期)2016-12-22
现代情报(2016年11期)2016-12-21
电脑知识与技术(2016年27期)2016-12-15
电脑知识与技术(2016年26期)2016-11-24
电脑知识与技术(2016年21期)2016-10-18
电脑知识与技术(2016年13期)2016-06-29
科技视界(2016年10期)2016-04-26
现代经济信息(2016年3期)2016-03-24
