
信息技术课堂实例:用字典法压缩信息
2016-05-14 16:51方玮聪
中国信息技术教育 2016年8期
方玮聪
所谓压缩,本质上讲就是借助特定的编码,对文件数据进行重新组织,去除信息中的冗余,以实现文件“瘦身”的效果。在教学过程中,学生会对无损压缩的原理产生困惑,归结起来主要有两个方面:①字符信息在无损压缩的过程中究竟是如何处理的呢?②压缩既然是编码方式的调整,那何以说这种调整能够实现去除冗余信息的目的呢?
课堂实验的引入
为了帮助学生进行理解,笔者借鉴了陈凯老师在《中国信息技术教育》杂志上开设的栏目“信息技术课程内容设计集锦”系列文章中《更多信息,更少容量》一文的内容,在课堂上引入了这个实验:先打开附件中的记事本,利用键盘输入并保存一个含有全部不重复英文大小写字母的文本文件,其大小为26个字节(每个字母占一个字节),使用计算机中安装的WinRAR压缩软件对其进行无损压缩,再观察其压缩后文件的大小。学生就会发现,压缩完之后文件所占空间不仅没有缩小,反而增大了许多。其原因学生很容易理解,压缩一个文件不仅是转换一种编码方式,同时文件还被做了一个“加壳”操作,新格式的文件中含有描述自身特性和编码方式的相关内容,而这些必要的信息描述本身则会占去相对较多的文件容量。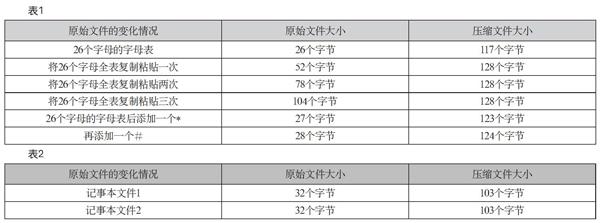
接下来让学生尝试进行若干实验,从观察中发现问题,从而引出他们对压缩编码的一些思考。
按照操作要求,在原始文件内增加字符信息,然后观察文件压缩前与文件压缩后容量的变化情况。尝试的操作有:将某个字母重复多次;添加重复的单词;将整个字母表复制、粘贴多次等。使用WinRAR软件进行压缩,压缩前后文件大小的对比如表1所示(内容仅作参考)。
对比观察后,学生可以得出如下结论:①在一定次数的整体复制后,压缩软件会将重复的字母过滤掉,无论多少次操作,压缩文件的大小基本不变;②若在字母表中添加不重复字符,则压缩软件在压缩时就显得力不从心了。
实验以及现象的解释
为了更深入地了解字符压缩的方法,笔者又让学生继续尝试新的实验。
首先,还是使用记事本文件新建两个纯字符的文本文档,使用键盘在第一个文档中输入一整句英语绕口令“canyoucanacanasacannercancanacan”(你能够像罐头工人一样装罐头吗?),并去掉其中的大小写、空格和标点符号,完成后保存。在第二个文档中输入26个英文小写字母外加“123456”,完成后保存(字符数和第一个文档完全相同)。然后,分别对这两个文件使用WinRAR进行压缩,结果如上页表2所示。
实验结果和学生想象的有很大出入,大家都以为第一个记事本文件压缩后会更小,因为其中存在很多反复出现的单词(即所谓的冗余信息),而第二个记事本文件中未出现一个重复字符,可最终压缩后的文件大小竟然是一样的。若要解释这个问题,就必须对压缩机制作更深入的分析。
其实,压缩软件在对文件进行压缩前,首先会对将要被压缩的文件进行检索。检索过程中压缩软件会将一部分字符挑选出来,放到一个指定的位置,称之为“搜索缓冲区”或者“字典库”。之后在进行字符压缩时,若检索到出现的字符在字典库中已经存在,就用对应关系来替换字符本身,以达到缩小空间的目的。
上述实验中之所以两个文件在压缩后大小都一样,主要是因为两个文件中的内容都被整体当作字典放入了字典库中,也就是说只有当字典库中放入了一定规模的字符信息后,压缩软件才真正开始表现出压缩功能。
字典法压缩实践
初步介绍了压缩软件的工作机制之后,笔者又尝试让学生进行如下小实验:用人脑,而不是用计算机来对文本进行压缩。希望学生能在这个过程中,体会字典法压缩的原理。
先打开记事本文件,输入一段英语绕口令(A writer writes:Dont write write as rite.),保存并查看文件大小(42个字节,其中包含空格和标点符号)。然后取其中若干个字符作为字典,以字典法来进行信息的压缩,将压缩后的信息内容保存到另外一个记事本文件中,并观察对比文件大小的变化。压缩时,以前面的几个字符作为字典,具体字典信息如表3所示。
若在压缩时,绕口令中有连续两个字符与字典库中所存在的字符相符,那就用两位数字表示从第几个字符开始取几个字符,如35表示write。如果字符并没有在字典中出现过,则要标注上0,如0s就表示s这个字符不在字典中,以免解压缩时产生混淆。另外,有些字符虽然出现在字典中,但只有一个字符与字典相符,这样也就未必需要使用到字典。
根据规则,压缩后的信息如表4所示。
通过对比,发现压缩前后文件缩小了1个字节,字典法在压缩过程中起了一定的作用。
以此作为基础,笔者又让学生尝试对之前使用过的英语绕口令(加入空格字符)使用字典法进行压缩(如表5),让学生先讨论并寻找适合的字典放入字典库中,然后根据自己所选择的字典进行相应的压缩。
如表6、下页表7所示,是学生讨论探究后尝试使用的部分字典以及使用该字典进行压缩后的信息及信息大小,针对不同的字典笔者发现有很多值得和学生探究的地方。
使用这个字典后,学生发现压缩率的高低与字典有很密切的关系,如果使用了不合理的字典,字符在压缩后,空间不仅不会缩小,反而会变大。
使用这个字典后,学生会发现压缩后文件的大小明显减小了。因此,笔者又提出问题:压缩后信息中的“126”代表什么意思?还原时是否会出现问题?学生会发现其中有歧义:是从12位置取6个字符,还是从1位置取26个字符。所以如果使用字典内容过多需要用两位来标识的话,那么压缩时所有涉及的内容都应用两位来标识。于是,为了能够压缩信息,字典选取和编码方式都要有所调整,这一次,不仅扩大了字典,而且规定用2个字符来索引字典的位置,用2个字符来存放字符的长度(如表8)。
学生尝试以后发现,如果文件中数据本来就不多,想要对它进行压缩,是相当困难的事情。
在探索的过程中,有部分学生尝试使用“can a”或“can a can”作为字典进行压缩,所得文本大小相较原文本也有所减小。然而,对这种方法笔者又提出了质疑:在编码过程中是否遗漏了什么因素?学生思考后提出了问题:这两个字典本身并不处在压缩语句的首部,而是从中间开始节选的,除非在编码过程中另外补充信息说明,否则不能简单拿来使用,如果要使用文件中间的内容来作为字典,则在压缩时还需要考虑字典本身的偏移量,这样一来,又需要额外增加压缩后文件的大小。讨论到这里,笔者引出当前很流行的LZ压缩编码,建议有兴趣的学生可以研究一下:编码的设计者是如何将字典本身所占容量尽可能减少的?这又是一个值得自主学习探索的好课题。
带领学生研究字典法压缩的过程,实际上是一个不断完善细节的过程,只有亲自实验,学生才能体会到将一个看上去简单的理论落实为可应用的实际方案,过程中需要克服很多困难!
猜你喜欢
电脑报(2021年41期)2021-11-04
电脑知识与技术(2019年29期)2019-12-16
电脑爱好者(2019年8期)2019-10-30
小学阅读指南·低年级版(2019年11期)2019-07-01
小天使·一年级语数英综合(2017年11期)2017-12-05
好孩子画报(2017年4期)2017-04-13
小学阅读指南·低年级版(2016年10期)2016-09-10
中国信息技术教育(2016年1期)2016-09-10
读者(2016年14期)2016-06-29
农机使用与维修(2014年10期)2014-10-23
