
基于训练样本集扩展的隐式篇章关系分类
2016-05-04 02:43朱珊珊丁思远严为绒姚建民朱巧明
中文信息学报 2016年5期
朱珊珊,洪 宇,丁思远,严为绒,姚建民,朱巧明
(苏州大学 江苏省计算机信息处理技术重点实验室,江苏 苏州 215006)
基于训练样本集扩展的隐式篇章关系分类
朱珊珊,洪 宇,丁思远,严为绒,姚建民,朱巧明
(苏州大学 江苏省计算机信息处理技术重点实验室,江苏 苏州 215006)
隐式篇章关系分类主要任务是在显式关联线索缺失的情况下,自动检测特定论元之间的语义关系类别。前人研究显示,语言学特征能够有效辅助隐式篇章关系的分类。目前,主流检测方法由于缺少足够的已标注隐式训练样本,导致分类器无法准确学习各种分类特征,分类精确率仅约为40%。针对这一问题,该文提出一种基于训练样本集扩展的隐式篇章关系分类方法。该方法首先借助论元向量,以原始训练样本集为种子实例,从外部数据资源中挖掘与其在语义以及关系上一致的“平行训练样本集”;然后将“平行训练样本集”加入原始训练样本集中,形成扩展的训练样本集;最后基于扩展的训练样本集,实现隐式篇章关系的分类。该文在宾州篇章树库(Penn Discourse Treebank, PDTB)上对扩展的训练样本集进行评测,结果显示,相较于原始训练样本集,使用扩展的训练样本集的实验系统整体性能提升8.41%,在四种篇章关系类别上的平均性能提升5.42%。与现有主流分类方法性能对比,识别精确率提升6.36%。
隐式篇章关系;语义向量;训练样本集扩展;篇章分析
1 引言
篇章关系研究任务旨在推理特定文本跨度范围内论元(即具有独立语义的文字片段,包括子句、句子或文本块等)之间的语义连接关系。宾州篇章树库(Penn Discourse Treebank, PDTB)[1-2]根据两个论元(即“论元对”)之间是否存在连接词,将篇章关系分成显式篇章关系(Explicit Discourse Relation)和隐式篇章关系(Implicit Discourse Relation)。此外,PDTB又将具体的篇章关系类型分为三层,第一层包括四种主要篇章关系: Temporal(时序关系)、Expansion(扩展关系)、Comparison(对比关系)和Contingency(偶然关系);第二层和第三层分别针对上一层进行细分。例1给出两种篇章关系实例,其中1(a)为显式篇章关系实例,可直接通过连接词“so”推理“论元对”的篇章关系类型为偶然关系;1(b)为隐式篇章关系实例,论元之间不存在连接词,但结合上下文以及句子结构等信息,可间接推理“论元对”的篇章关系类型为对比关系,因而可在“论元对”中插入连接词“but”用来表示对比关系。
例1 (a) Arg1: I got up late.
<译文: 我起床晚了>
Arg2: 【Explicit=So】I was late for work.
<译文: 【所以】我上班迟到了>
篇章关系 =“Contingency(偶然关系)”
(b) Arg1: He loves cats.
<译文: 他喜欢猫>
Arg2: 【Implicit=But】I hate cats.
<译文: 【但是】我讨厌猫>
篇章关系 = “Comparison(对比关系)”
目前,显式篇章关系的研究已获得较优的分类性能。Pilter等[3]借助“显式连接词—篇章关系”之间的一一映射进行显式篇章关系分类,最终分类性能为93.09%。相对地,隐式篇章关系分类精确率仍然较低。分析原因可知,隐式篇章关系样本中,论元之间缺失连接词, 无法直接判定篇章关系,需通过上下文、语义结构以及句子特征等其他信息间接推理隐式关系。然而,上下文信息的不确定性、语义结构的复杂性以及句子特征的歧义性,往往制约隐式篇章关系的有效判定。
传统的隐式篇章关系检测方法主要采用基于语言学特征的分类方法,通过自然语言处理技术抽取论元中的各种特征(例如,情感词极性,动词短语长度,单词对,句法规则等)。然而,该方法分类性能仍然偏低,究其原因,发现存在如下两个问题。
1) 人工标注的隐式训练样本数量有限,训练语料中包含的特征信息不充分,难以有效学习各篇章关系的语言学特征;
2) 隐式训练样本中各篇章关系类别分布不平衡,导致模型训练出现偏差,在少数类别上分类精度较低,影响了分类器的整体分类性能。
本文针对篇章关系语料分布不平衡,及其引起的关系检测模型训练存在偏见的问题,提出一种基于论元向量的隐式训练样本集扩展方法。该方法首先将所有实例表示成固定长度且具有实值的向量,然后以PDTB标注的隐式篇章关系实例(即原始训练样本集)为种子实例,从大规模同领域数据资源中挖掘与其内容近似且关系相同的隐式“论元对”(简称为平行“论元对”),将平行“论元对”加入到原始训练样本集中,获得扩展的训练样本集(即原始训练样本集+所有平行“论元对”)。基于扩展的训练样本集,本文在前人基于语言学特征的隐式篇章关系分类方法的基础上,借助自然语言处理技术,抽取所有实例的动词、单词对、产生式规则以及依存规则特征,使用LIBSVM分类器训练特征分类模型,最终在测试样本上进行性能评测,实现隐式篇章关系的分类。
本文的组织结构如下: 第二节概述相关工作;第三节介绍篇章检测任务定义及数据分析;第四节介绍本文基于论元向量的隐式训练样本集扩展方法;第五节介绍基于扩展的训练样本集的隐式篇章关系分类方法;第六节给出实验结果及相关分析;第七节总结全文。
2 相关工作
Pitler等[4]首次单独针对PDTB中隐式篇章关系进行分类,采用全监督的篇章关系分类方法训练分类器,使用情感词极性、动词短语长度、动词类型、句子首尾单词和上下文等特征进行关系分类,最终分类结果优于随机分类的性能。Lin等[5]继承了Pitler等的方法体系,细化了上下文特征的采集技术,使用了句法树的结构特征与依存特征;同时,结合Soricut等[6]提出的论元内部结构特征,在PDTB第二层隐式关系分类上获得了40.20%的精确率。随后,Wang等[7]基于卷积树核函数提升了句法结构特征的区分能力,但性能并没有显著的提升(精确率约40.00%),仅略优于以浅层句法树为特征的关系分类性能。Zhou等[8]使用三元文法模型搜索与隐式“论元对”一致的表达模式,在相邻论元间插入合适的连接词,借助显式关系预测隐式关系,相比于Saito等,该方法不局限于语法的规范,满足了词特征相互组合的连贯性和灵活性,但是其性能仅在偶然和时序关系上有所提升,对扩展和比较关系的分类性能仍然偏低。Park等[9]提出特征集合优化的方法,通过前向选择算法使用情感词极性、句子首尾单词、产生式规则等特征进行特征融合,最终分类性能在四种篇章关系类别上获得显著提升。Lan等[10]提出多任务学习的隐式篇章关系分类方法,在交互结构优化(ASO)多任务学习框架下,抽取论元的动词、极性等语言学特征,基于不同类型的训练样本,训练主分类器及辅助分类器,最终推理性能达到42.30%。近期Li等[11]通过挖掘中英文之间的篇章结构关系,借助已有的英文篇章关系语言学资源,有效地提升了中文隐式篇章关系的分类性能。
上述各隐式篇章关系分类系统均是通过挖掘有效的语言学特征,利用分类器进行隐式篇章关系分类,使用的语料均为PDTB隐式数据集。但并未有效提升隐式篇章关系的分类性能,整体分类性能仍维持在40%左右。究其原因,可发现上述研究均是以基于全监督或者半监督的方法学研究为基础,通过抽取各种有效的语言学特征,探索特征与具体类别之间的关系来提升分类性能,而忽略了对PDTB数据集的分析。由于PDTB数据集中各篇章关系分布不平衡(例如,Temporal关系实例仅占实例总数的5.36%),训练过程中,在少数类上缺少足够的隐式训练样本,分类器无法准确学习各种有效特征,导致分类模型出现偏差,影响最终的分类性能。此外,Wang等[12]进一步通过实验证明,PDTB标注的隐式篇章关系实例中只有小部分“典型(typical)”的关系实例能够有效地提升隐式篇章关系的分类性能,而其他实例对最终的分类性能影响较小甚至会降低分类器的分类性能。在此情况下,能够实际使用的隐式篇章关系实例则进一步减少。
针对数据不充分问题,早期的研究主要是使用显式数据集资源,通过移除显式“论元对”中的连接词,构造出大量的隐式“论元对”,对隐式训练样本进行扩展。在此基础上,基于构造的隐式“论元对”样本,通过分类器训练获得隐式篇章关系分类模型(Marcu 等[13];Sporleder 等[14])。虽然通过此方法可以快速的获得大量隐式训练样本,然而直接移除“论元对”的连接词,构造出的隐式“论元对”会出现语义不连贯、表意不清的问题,最终实验分类性能仍然较低。如何快速有效地对隐式训练样本进行扩展,从而提升隐式篇章关系的分类性能仍是一个亟待解决的问题。对此,本文提出了一种基于论元向量的隐式训练样本集扩展方法,辅助推理隐式篇章关系。
3 任务定义及数据分析
3.1 任务定义
本文的主要研究任务是对隐式训练样本集进行扩展,推理论元之间的隐式篇章关系,即在没有显式连接词作为直接线索的情况下,对第一层的四种篇章关系予以判定。图1为隐式篇章关系分类任务框架图,输入为隐式“论元对”,输出则为具体的篇章关系类别。
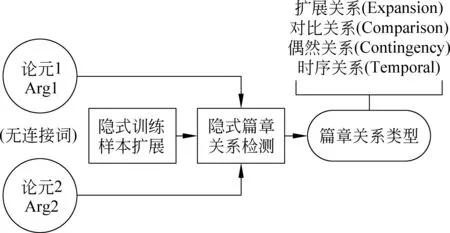
图1 隐式篇章关系分类任务框架图
3.2 训练样本集数据分析
PDTB语料库是2008年发布并标注具体篇章关系的语言学资源,共标注29 655个篇章关系实例,主要分为两大类: 显式篇章关系实例和隐式篇章关系实例。PDTB语料采用人工标注的方法,标注的“论元对”符合自然语言规律,语义信息较为明确,歧义性较小。近期的隐式篇章分类研究主要是基于该语料进行展开。然而其标注的隐式篇章关系实例数量有限(隐式篇章关系实例为13 815个),且人工标注耗时耗力,仍不足以解决隐式训练样本不充分的问题。针对该问题,本文提出一种基于论元向量的方法实现对隐式训练样本集的扩展。具体实现细节将在第四节进行描述。
本文选用PDTB 隐式数据集Section 00-20作为原始训练样本集。表1为该训练样本集中四种篇章关系类别的分布情况,从表1的统计结果发现: 四种篇章关系类别分布严重不平衡,相较于Expansion类别,Comparison、Contingency、Temporal 三种类别的实例数量较少,实例总数仅占样本的45.47%。在分类过程中,这种不平衡现象,容易导致分类器出现偏差,影响分类性能。基于此,本文对实例数量较少的三种类别: Comparison、Contingency以及Temporal进行样本扩展,使得扩展后的训练样本集的四种篇章关系比例达到平衡。
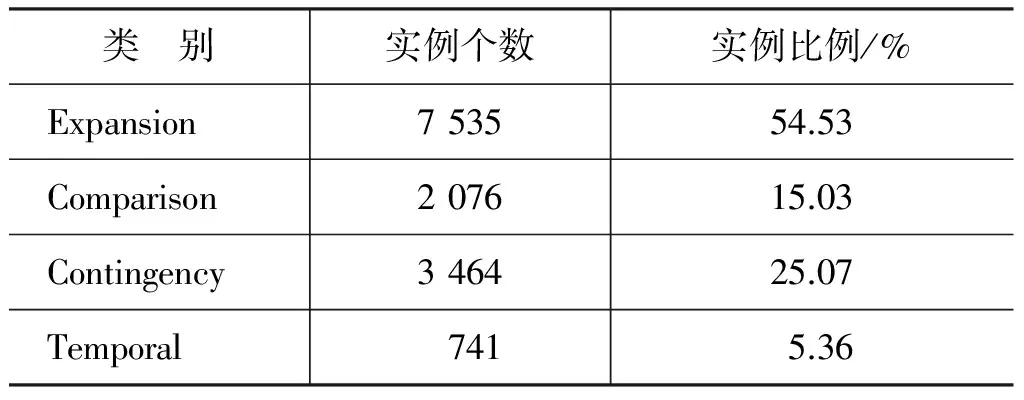
表1 PDTB 隐式数据集00-20章节四种篇章关系分布
此外,分析PDTB 隐式数据集发现,有部分实例标注了两种篇章关系类别,本文将这些实例定义为歧义“论元对”。虽然歧义“论元对”在数据集中所占比例较小,但如果对这些歧义“论元对”进行实例扩展,则会进一步增加不确定样本在整个训练样本集中的比重,势必会影响分类性能,所以应将歧义“论元对”从训练样本集中删除,并对歧义“论元对”也不进行实例扩展。本文接下来介绍的训练样本集扩展方法,均默认已从原始训练样本集中删除歧义“论元对”。
4 基于论元向量的隐式训练样本集扩展方法
针对隐式篇章关系分类任务,本文提出一种基于论元向量的隐式训练样本集扩展方法。本节首先概述论元向量的生成方法,然后给出具体的隐式训练样本集扩展方法。
4.1 基于词向量的论元向量生成方法
词向量(Distributed representation,通常被称为“Word Representation”或“Word Embedding”)是目前深度学习领域最热门的研究任务之一,最早由Hinton[15]提出。词向量模型旨在将单词转化成具有实值的语义向量,通过语义向量获取文本的句法结构、上下文信息等,目前已在多个领域广泛应用,例如,文本分类、问答系统、信息检索、命名题识别以及句法分析等。Bengio等[16]基于词向量,利用神经网络来构建语言模型,相较于传统的N-gram算法,模型性能提升10%~20%,奠定了词向量研究的基础。在此基础上,Richard Socher等[17]提出基于半监督递归自动译码器(Recursive auto-encoder,RAE)的语义向量生成方法,该方法基于神经网络语言模型训练获得每个单词的词向量,通过句法树将任意长度的文本片段转化成固定维度的语义向量,并将该语义向量表示应用于情感分类上,实验结果显示,相较于传统基于规则的方法以及基于词包模型(bag-of-words)的方法,情感分类性能获得显著提升。本文借助该语义向量生成方法实现论元的向量表示。
图2为递归自动译码器的句子语义向量生成示意图。其输入为长度为4的句子
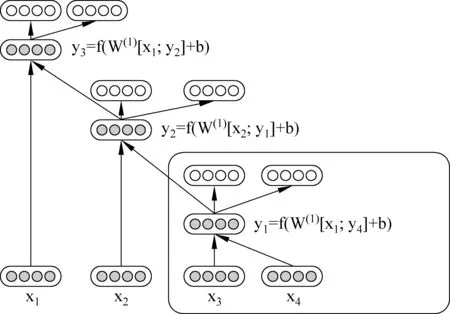
图2 递归自动译码器标注示例
在单词表示成词向量的基础上,递归自动译码器首先对输入的句子进行句法分析,将每个句子表示成句法树的形式,然后自右向左遍历句法树中的每个叶子节点,每两个叶子节点
p=f(W(1)[c1;c2]+b(1))
(1)
按照上述计算方法,遍历整个句法树直到根节点,即获得整个句子的语义向量。例2给出两个实例的语义向量标注结果,因篇幅有限,只列出部分标注结果。
例2 Arg1 Mr. Tom avoided jail.
<译文: 汤姆先生免受牢狱之灾>
Arg2 【Implicit = Instead】He was sentenced to 500 hours of community service.
<译文: 【相反】他被判处执行500小时的社区服务工作>
篇章关系 =“Expansion(扩展关系)”
通过递归自动译码器,可将输入的句子转换成语义向量,该语义向量涵盖句子的句法结构以及上下文信息等,可直接利用该语义向量进行文本分析,从而降低对句子进行直接分析的复杂度。本文利用语义向量这一优势,将递归自动译码器生成的语义向量应用于隐式样本集扩展任务中,通过探索论元的语义向量(简称为论元向量)之间的关系,对隐式训练样本集进行扩展,辅助推理论元之间的隐式篇章关系。
4.2 隐式训练样本集扩展方法
本节将详细介绍基于语义向量进行隐式训练样本集的扩展方法。本文使用的外部语言学资源为GIGAWORD(LDC2003T05),其中包含了4 111 240篇新闻文本,来自四个不同的国际英语新闻专线,分别为: 法国新闻社、美国联社、纽约时报以及新华通讯社。为了保证在外部数据资源中扩展的隐式实例与原始训练样本集的格式一致(在原始训练样本集中,每个训练实例由“论元对”及其对应的篇章关系类别组成),在进行训练样本集扩展之前,对GIGAWORD语料中的每篇文本进行切分,切分后的文本须符合以下规则:
1) 以“论元对”为单元,且每个论元符合自然语言规律(通过句法分析判定);
2) 两个论元之间不包含连接词*PDTB语料中定义的134个连接词,即它们之间为隐式关系。
图3为基于论元向量的训练样本集扩展方法流程图。本文从GIGAWORD语料中抽取出所有符合上述两项要求的 “论元对”,将这些“论元对”加入到外部数据资源列表中。由于切分后获取的“论元对”实例数量庞大,本文最终从该列表中随机抽取一百万个“论元对”实例,作为外部隐式“论元对”样本集。基于此样本集,利用4.1节介绍的递归自动译码器标注程序进行论元向量标注,并通过连接两个论元向量,获得“论元对”整体的向量表示。图3中X和Y分别表示获得的外部隐式“论元对”样本集以及原始训练样本集的语义向量标注集合。
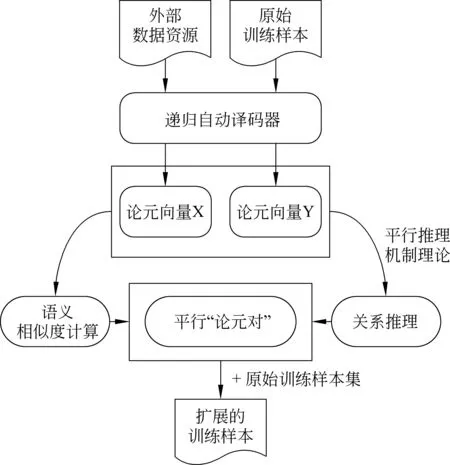
图3 基于论元向量的训练样本集扩充方法流程图
以原始训练样本集的每个“论元对”为种子实例,依据“平行推理机制”理论(Hong等[19])*平行推理机制: 如果两个“论元对”在语义上以及结构上具有一致性,则它们的关系也平行,即它们具有相同的篇章关系。,计算论元向量之间的语义相似度。依据计算结果,从外部隐式“论元对”样本集中抽取与种子实例在语义上和关系上相似的隐式“论元对”(简称为平行“论元对”)。实验过程中,针对每个种子实例,本文选择语义最相似的TopN个隐式“论元对”作为平行“论元对”,其中,语义相似度度量采用欧式距离;N的取值与具体的关系类别有关,如式(2)所示。
(2)
其中,Nr表示篇章关系类别为r的种子实例关于TopN的参数N,CExpansion表示训练样本中关系类别为Expansion的实例总数,Cr表示训练样本中关系类类别为r的实例总数,r∈{Comparison, Contingency, Temporal}。
通过以上方法,本文计算获得所有种子实例的平行“论元对”,形成“平行训练样本集”,并将原始训练样本集与平行训练样本集组合,实现隐式训练样本集的扩展。表2为隐式训练样本集扩展的算法伪代码。
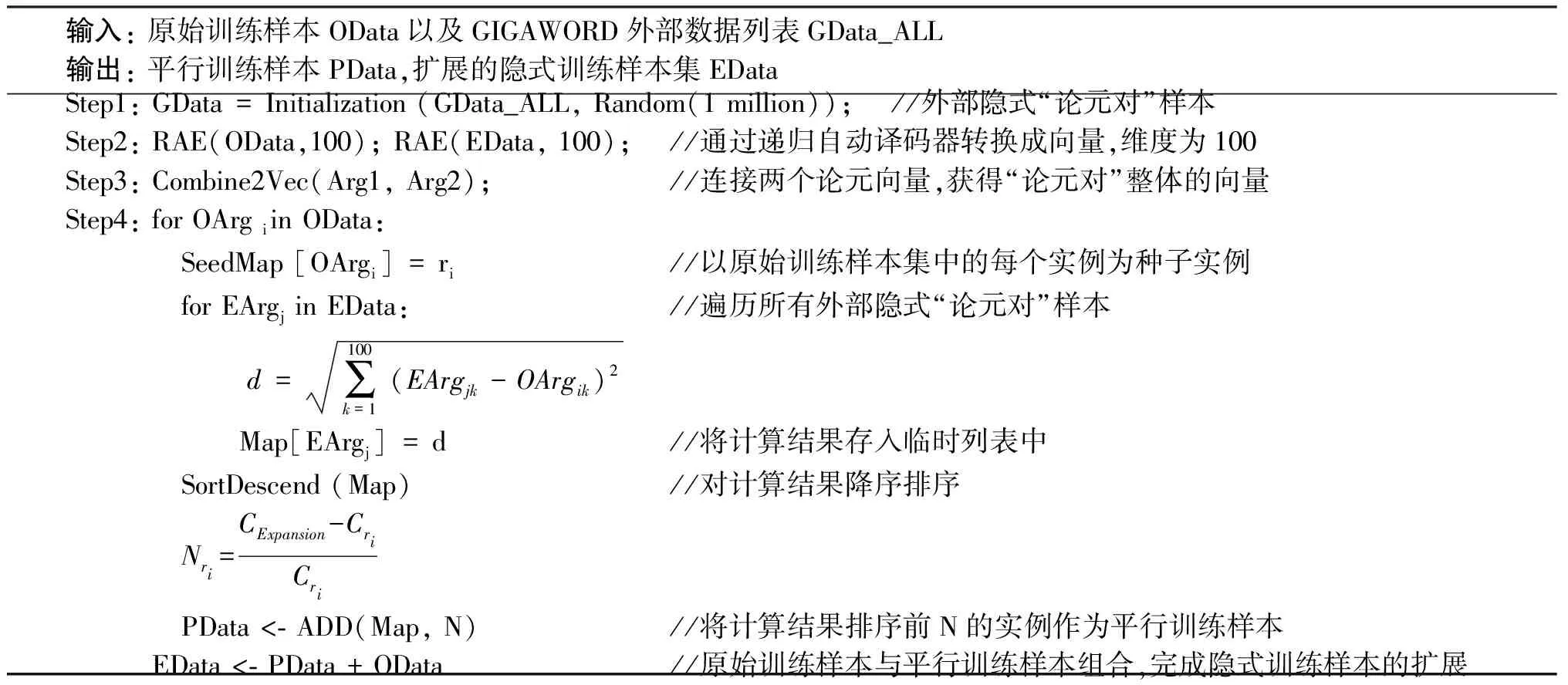
表2 隐式训练样本集扩展算法伪代码
5 基于扩展的训练样本集的隐式篇章关系分类
在扩展的训练样本集上,本文采用传统的基于语言学特征的隐式篇章关系分类方法进行实验。本节首先概述实验分类特征,然后介绍实验分类器。
5.1 分类特征
前人研究表明[4-5,9-10],动词、单词对、产生式规则以及依存规则等四种语言学特征在隐式篇章关系的分类问题中具有明显的优势。因此,本文采用这四种分类特征进行实验。下面对这四种分类特征进行描述。
动词(Verbs) 论元Arg1和论元Arg2中的所有动词。每个动词表示成三个二元特征,分别表示该特征是否出现在Arg1、Arg2以及整个“论元对”中。
单词对(WordPairs) 论元Arg1和论元Arg2的向量积——即两个论元中的所有单词(非停用词)的交叉组合,对于任意一个特征(Wi,Wj),单词Wi来自于Arg1中,单词Wj则来自于Arg2中。
产生式规则(Production Rules) 论元Arg1、论元Arg2以及整个“论元对”的句法规则特征。基于斯坦福句法标注工具(version 3.5.0)*http://nlp.stanford.edu/software/lex-parser.shtml(下载地址),对所有实例进行句法规则标注,按照“parent-children”的格式抽取出句法树中所有符合要求的产生式规则。每个产生式规则表示成三个二元特征,分别代表该特征是否出现在Arg1、Arg2以及整个“论元对”中。
依存规则(Dependency Rules) 论元Arg1、论元Arg2以及整个“论元对”的依存规则特征。同样基于斯坦福句法标注工具,获得所有实例的依存分析树,对每个依存树,抽取每个单词及其相关的依存类型。每个依存特征表示成三个二元特征,分别代表该特征是否出现在Arg1、Arg2以及整个“论元对”中。
对于动词、单词对、产生式规则以及依存规则特征,本文在实验中设定的频率阈值为5,即如果某一特征在语料中出现的总频数小于5,则舍弃该特征。
5.2 分类器
针对所有训练样本,本文抽取上述四种分类特征,并将每个训练实例表示成特征向量,采用Chang 等[20]开发设计的LIBSVM作为分类器,核函数使用线性核。针对每种篇章关系,分别构建一个二元分类器;同时,针对四种篇章关系类别,构建一个多类分类器(分类类别为四种)。
6 实验设计与结果分析
6.1 实验设计
本文使用PDTB 2.0版本中Section 00-20作为原始训练样本集,共包含13 502个实例(本文删除具有两种关系类型的歧义“论元对”,共313个);Section 21-22作为测试样本集,包含1 046个实例;Section 23-24作为验证集,包含1 192个实例。所有样本使用第一层的四种篇章关系类型: 扩展关系(Expansion)、对比关系(Comparison)、偶然关系(Contingency)以及时序关系(Temporal),其中实体关系类型(EntRel)以及无关系类型(NoRel)均不包含在训练样本集、验证样本集以及测试样本集中。此外,本文对外部数据资源GIGAWORD语料中的所有文本进行切分,切分后的文本以“论元对”为单元且两个论元之间的关系为隐式关系。通过生成随机数的方式从该文本中抽取一百万个“论元对”作为外部隐式“论元对”样本。基于此样本,进行后续平行隐式“论元对”的挖掘。
为了检验不同特征的分类性能,针对不同的分类特征,本文在四种篇章关系类别下分别训练一个二元分类器,以检验该特征在当前篇章关系类型上的单一分类性能,评价标准采用F值;同时本文也针对每个特征(动词、单词对、产生式规则以及依存规则特征)分别训练一个整体分类器,用来检验该特征在四种篇章关系类型上的整体分类性能,评价标准采用精确率(Accuracy),如式(3)所示。
(3)
其中TruePositive表示被正确分为正例的个数;TrueNegative表示被正确分为 负 例 的 个 数,N
为待测“论元对”总数。实际上在表示整体分类性能时,TrueNegative值为0,TruePositive为四种篇章关系类别中被正确分为正例的总数。
6.2 实验结果与分析
图4为使用四种不同分类特征的实验结果,图4(a)、4(b)、4(c)以及4(d)分别表示使用动词特征、单词对特征、产生式规则特征以及依存规则特征的实验分类性能(度量标准为F值)。从实验结果可以看出,使用扩展的训练样本集进行模型训练,分类器在保证Expansion关系类别分类精度的同时,有效地提升了Comparison、Contingency以及Temporal 三个关系类别上的分类性能,在四种分类特征上性能分别提升11.21%、7.67%、4.46%和11.53%。由于本文只对Comparison、Contingency以及Temporal三种关系类别进行训练样本扩展,从实验结果还可以看出,实验性能在这三种类别上提升较为明显,而在Expansion类别上的性能基本保持不变,这说明本文基于论元向量获取的“平行训练样本集”具有一定的准确性,在Comparison、Contingency以及Temporal三种关系类别上加入更多的有效实例,有效地提升了分类器在这三种类别上的分类性能,而在Expansion关系类别上,由于没有加入更多的训练实例,分类性能则基本保持不变。

图4 分类器在四种不同特征下的实验性能对比注: Expansion, Comparison, Contingency, Temporal分别简写为Exp., Com., Con., Temp.
为进一步验证基于论元向量扩展的“平行训练样本集”的准确性。实验过程中,对于Comparison、Contingency以及Temporal三种关系类别,本文从外部隐式“论元对”样本中随机选择与“平行训练样本集”相同数量的“论元对”,将该样本集称为“伪平行训练样本集”。由于“伪平行训练样本集”中可能含有较多噪音信息,通过该样本集训练得出的分类器可靠性不强,可将其作为实验的对比系统,以检验“平行训练样本集”的实验性能。因此,本文设置了以下五个实验系统: 其中Baseline实验系统使用原始训练样本集;SYS1实验系统使用“伪平行训练样本集”;SYS2实验系统使用“平行训练样本集”;SYS3实验系统使用加入“伪平行训练样本集”的扩展训练样本集;SYS4实验系统使用加入“平行训练样本集”的扩展训练样本集。图5为各实验系统在四种分类特征上的实验性能对比。
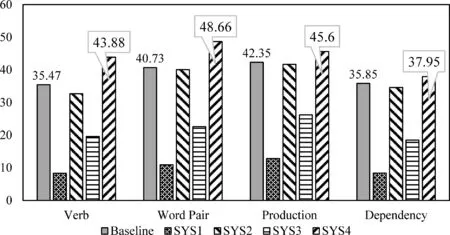
图5 各实验系统性能对比图
从图5分类性能对比图可以看出,加入“平行训练样本集”后,系统SYS4的分类性能明显优于基准系统(仅使用原始训练样本),且在每种特征上分类性能分别提升为8.41%、7.93%、3.25%和2.10%,最优分类性能达到48.66%(特征: 单词对)。进一步观察发现,实验系统SYS2仅使用扩展的“平行训练样本集”进行实验,获得的实验分类性能仅略低于基准系统,而实验系统SYS3使用“伪平行训练样本集”获得的实验性能明显偏低,从而证明本文基于论元向量扩展的“平行训练样本集”与原始训练样本具有较高的相似性,在一定程度上可辅助实现隐式篇章关系的分类。
此外,本文将实验性能最优的分类系统SYS4与基准系统以及各主流分类系统进行对比。本文选取的两个对比系统为WANG_SYS和LAN_SYS。其中,WANG_SYS采用基于树核函数的方法实现隐式篇章关系分类,使用的分类器及评价标准与本文一致,最终分类器的整体分类性能为40.00%;LAN_SYS采用基于多任务学习框架的方法实现隐式篇章关系分类,通过不同的训练样本训练主分类器和辅助分类器,最终整体分类性能达到42.30%。表3列出各个系统的分类性能,从各实验系统分类性能可以看出,本文加入“平行训练样本”的实验系统SYS4的分类性能相较于两个对比系统WANG_SYS以及LAN_SYS均有显著提升,分类精确率分别提高8.66%和6.36%,这也进一步验证本文基于训练样本集扩展的隐式篇章关系分类方法具有一定的有效性和可行性。
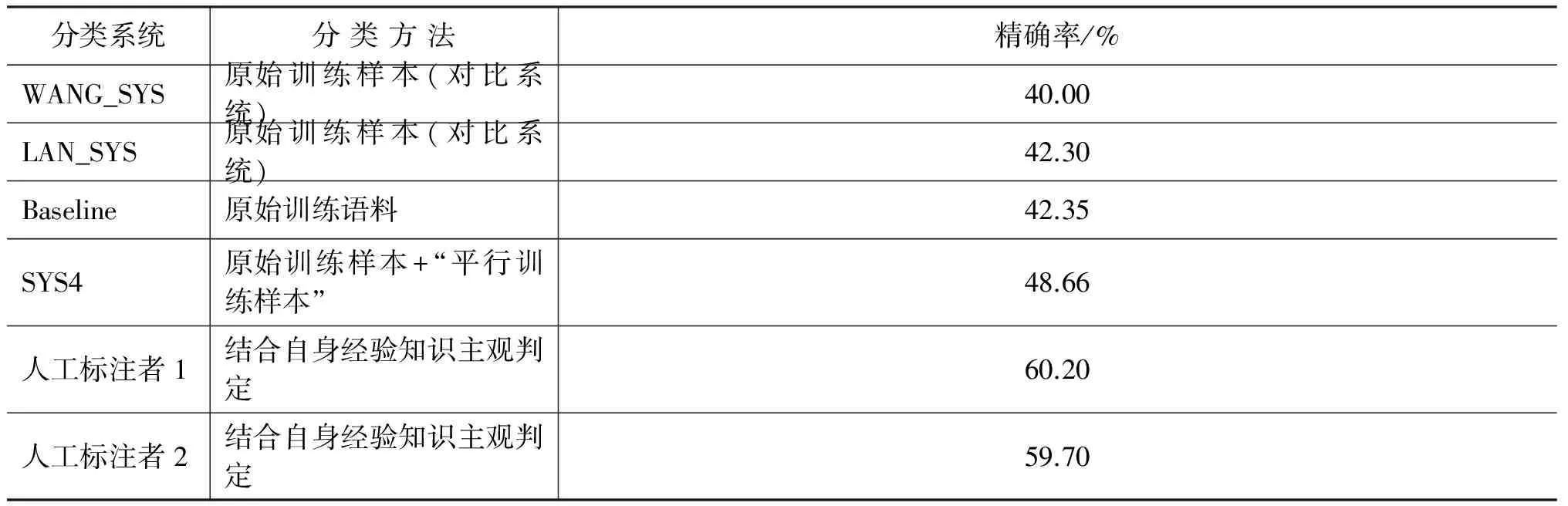
表3 各隐式篇章关系推理系统性能
表3中还给出两位人工标注者的分类精确率(来自徐凡等[21]),针对同一测试集,两者仅取得60%左右的精确率。虽然与人工标注者的实验结果相比,本文的最优性能仍然偏低,但现有系统和人工标注的性能均不高,这种现象从侧面反映隐式篇章关系分类难度较大,在篇章分析领域仍是一个具有挑战性的研究任务。
7 总结
针对隐式训练样本不足以及篇章关系类别不平衡的问题,本文提出一种基于训练样本扩展的隐式篇章关系分类方法。该方法借助论元向量,以原始训练样本为集种子实例,从外部数据资源中挖掘所有种子实例的平行隐式“论元对”,并将所有平行隐式“论元对”加入到原始训练样本集中,对训练样本集进行扩展。基于扩展的训练样本集,在PDTB数据集上进行性能测试。相较于直接使用原始训练样本集的实验系统,分类性能提升最优达到8.41%,相较于两个主流对比实验系统,分类性能分别提升8.66%和6.36%。
然而,本文提出的基于训练样本集扩展的隐式篇章关系分类方法性能仍偏低,原因在于,隐式“论元对”本身具有较强的主观性和歧义性,从不同的角度考虑具有不同的语义关系。例如, “He worked all night yesterday”和“He slept all day today”两论元之间既可表示偶然关系也可表示时序关系。针对这一问题,未来工作中,我们将对本文方法深入和细化: 在训练样本集扩展方面,尝试借助LDA模型以及篇章上下文信息选择歧义性较小的实例作为种子实例;在论元向量计算方面,采用更多的相似度计算方法,例如,余弦相似度、Jaccard相似度等;在特征表示方面,尝试采用特征选择、特征融合等方法。此外,将现有的篇章关系分类方法扩展至第二层的篇章关系识别,实现更细粒度的篇章关系分类。
[1] R Prasad, N Dinesh, A Lee, et al. The Penn Discourse TreeBank 2.0[C]//Proceedings of the 6th International Conference on Language Resources and Evaluation (LREC), 2008: 2961-2968.
[2] E Miltsakaki, L Robaldo, A Lee, et al. Sense Annotation in the Penn Discourse Treebank[C]//Proceedings of the Computational Linguistics and Intelligent Text Processing. Springer Berlin Heidelberg, 2008: 275-286.
[3] E Pitler, M Raghupathy, H Mehta, et al. Joshi. Easily Identifiable Discourse Relations[R]. Technical Reports (CIS), 2008: 87-90.
[4] E Pitler, A Louis, A Nenkova. AutomaticSense Prediction for Implicit Discourse Relations in Text[C]//Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP (ACL-AFNLP), 2009, 2: 683-691.
[5] Z H Lin, M Y Kan, H T Ng. Recognizing Implicit Discourse Relations in the Penn Discourse Treebank[C]//Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), 2009, 1: 343-351.
[6] R Soricut, D Marcu. Sentence Level Discourse Parsing Using Syntactic and Lexical Information[C]//Proceedings of the Human Language Technology and North American Association for Computational Linguistics Conference (HLT-NAACL), 2003: 149-156.
[7] W T Wang, J Su, C L Tan. KernelBased Discourse Relation Recognition with Temporal Ordering Information[C]//Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics (ACL), 2010: 710-719.
[8] Z M Zhou, Y Xu, Z Y Niu, et al. Predicting Discourse Connectives for Implicit Discourse Relation Recognition[C]//Proceedings of the 23rd International Conference on Computational Linguistics (CL): Posters, 2010: 1507-1514.
[9] J Park, C Cardie. Improving Implicit Discourse Relation Recognition Through Feature Set Optimization[C]//Proceedings of the 13th Annual Meeting of the Special Interest Group on Discourse and Dialogue (SIGDIAL), 2012: 108-112.
[10] M Lan, Y Xu, Z Y Niu. Leveraging Synthetic Discourse Data via Multi-task Learning for Implicit Discourse Relation Recognition[C]//Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics (ACL), 2013: 476-485.
[11] J J Li, M Carpuat, A Nenkova. Cross-lingual Discourse Relation Analysis: A corpus study and a semi-supervised classification system[C]//Proceedings of the 25th International Conference on Computational Linguistics (COLING), 2014: 577-587.
[12] X Wang, S J Li, J Li, et al. Implicit Discourse Relation Recognition by Selecting Typical Training Examples[C]//Proceedings of the 22nd International Conference on Computational Linguistics (COLING), 2012: 2757-2772.
[13] D Marcu, A Echihabi. AnUnsupervised Approach to Recognizing Discourse Relations[C]//Proceedings of the 40th Annual Meeting on Association for Computational Linguistics (ACL), 2002: 368-375.
[14] C Sporleder, A Lascarides. Using automatically labelled examples to classify rhetorical relations: An assessment[J].Natural Language Engineering, 2008, 14(03): 369-416.
[15] G E Hinton. Learning distributed representations of concepts[C]//Proceedings of the eighth annual conference of the cognitive science society (COGSCI).1986: 1-12.
[16] Y Bengio, R Ducharme, P Vincent, et al. A neural probabilistic language model[J]. The Journal of Machine Learning Research, 2003, 3: 1137-1155.
[17] R Socher, J Pennington, E H Huang, et al. Semi-supervised recursive autoencoders for predicting sentiment distributions[C]//Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP), 2011: 151-161.
[18] J Turian, L Ratinov, Y Bengio. Word representations: a simple and general method for semi-supervised learning[C]//Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics (ACL), 2010: 384-394.
[19] Y Hong, X P Zhou, T T Che, et al. Cross-argument inference for implicit discourse relation recognition[C]//Proceedings of the 21st ACM International Conference on Information and Knowledge Management (CIKM), 2012: 295-304.
[20] C C Chang, C J Lin. LIBSVM: a library for support vector machines[J]. ACM Transactions on Intelligent Systems and Technology (TIST), 2001, 2(3): 389-396.
[21] 徐凡, 朱巧明, 周国栋. 基于树核的隐式篇章关系识别[J]. 软件学报, 2013, 24(5): 1022-1035.
Implicit Discourse Relation Classification Method Based on the Training Data Expansion
ZHU Shanshan, HONG Yu, DING Siyuan, YAN Weirong,YAO Jianmin, ZHU Qiaoming
(Key Lab of Computer Information Processing Technology of Jiangsu Province, Soochow University, Suzhou, Jiangsu 215006, China)
The implicit discourse relation recognition is to automatically detect the relationships between two arguments without explicit connectives. Previous studies show that linguistic features are effective for implicit discourse relation recognition. However, the state-of-the-art accuracy is merely 40% for the lack of enough training data. For the problem, this paper presents a novel implicit discourse relation recognition method based on the training data expansion. Firstly, we take some origin training data as seed samples, and then use them to mine semantically and relationally parallel data from the external data resources by using “arguments vectors”. Secondly, we augment origin training data with the mined parallel training data. Finally, we experiment the implicit discourse relation classification using the expanded data. Experiment results on the Penn Discourse Treebank (PDTB) show that our method outperforms the baseline system with a gain of 8.41% on the whole, and 5.42% on average in classification accuracy respectively. Compared with the state-of-the-art system, we further acquire 6.36% improvements.
implicit discourse relation; semantic vector; training data expansion; discourse analysis

朱珊珊(1992—),硕士研究生,主要研究领域为篇章分析。E⁃mail:zhushanshan063@gmail.com洪宇(1978—),通信作者,副教授,主要研究领域为信息抽取,信息检索,事件关系检测等。E⁃mail:tianxianer@gmail.com丁思远(1992—),硕士研究生,主要研究领域为事件关系检测。E⁃mail:dsy.ever@gmail.com
1003-0077(2016)05-0111-10
2014-12-25 定稿日期: 2015-03-27
国家自然科学基金(61373097, 61272259, 61272260, 90920004);教育部博士学科点专项基金(2009321110006, 20103201110021);江苏省自然科学基金(BK2011282);江苏省高校自然科学基金(11KJA520003);苏州市自然科学基金(SH201212)
TP
A
猜你喜欢
科技创新与应用(2020年6期)2020-02-29
现代电子技术(2016年23期)2017-01-12
北京理工大学学报(2016年6期)2016-11-22
高中生学习·高三版(2014年3期)2014-04-29
高中生学习·高三版(2014年3期)2014-04-29
中文信息学报(2012年2期)2012-06-29
