
基于Tri-training与噪声过滤的弱监督关系抽取
2016-05-03 13:11:39冶忠林尹红风何大可
中文信息学报 2016年4期
贾 真,冶忠林,尹红风,何大可
(1. 西南交通大学 信息科学与技术学院, 四川 成都 610031;2. DOCOMO Innovations 公司,美国 帕罗奥图 94304)
基于Tri-training与噪声过滤的弱监督关系抽取
贾 真1,冶忠林1,尹红风2,何大可1
(1. 西南交通大学 信息科学与技术学院, 四川 成都 610031;2.DOCOMOInnovations公司,美国 帕罗奥图 94304)
弱监督关系抽取利用已有关系实体对从文本集中自动获取训练数据,有效解决了训练数据不足的问题。针对弱监督训练数据存在噪声、特征不足和不平衡,导致关系抽取性能不高的问题,文中提出NF-Tri-training(Tri-trainingwithNoiseFiltering)弱监督关系抽取算法。它利用欠采样解决样本不平衡问题,基于Tri-training从未标注数据中迭代学习新的样本,提高分类器的泛化能力,采用数据编辑技术识别并移除初始训练数据和每次迭代产生的错标样本。在互动百科采集数据集上实验结果表明NF-Tri-training算法能够有效提升关系分类器的性能。
关系抽取; 弱监督学习;Tri-training; 数据编辑
1 引言
关系抽取是信息抽取任务之一,其目的是从文本中找出实体对之间的语义关系类别。关系抽取在知识库构建、自动问答、信息检索等多个领域具有重要的应用价值。传统基于有监督机器学习的关系抽取依赖于人工标注的训练语料。然而,随着关系抽取从限定关系类型转向开放领域,数据源从标准语料库转向海量的网络数据,人工标注几乎是不可能的。基于弱监督学习(weakly supervised learning)的关系抽取从知识库中提取结构化的关系实体对,通过对文本集中的句子进行回标自动构建训练数据,再利用机器学习算法训练分类器,对未标注文本集中的实体对进行关系预测。由于弱监督关系抽取能够在较少人工干预下自动获取训练数据而受到广泛的关注。然而,与人工标注的训练数据相比,弱监督关系抽取的训练数据是基于实体对的共现自动获取的,其中含有大量的噪声和错误。此外,由于受到知识库大小和文本集内容的限制,训练数据还存在特征不足[1]和样本不平衡的问题。训练数据的质量对于分类器的性能至关重要,训练数据中含有噪声将影响分类器的精度[2],训练数据特征不足将降低分类器的泛化能力,样本不平衡使分类偏向多样本类别,以上问题导致分类性能急剧下降。
相对于标注数据,未标注数据较易获得。半监督学习方法能够高效的利用少量标注数据和大量未标注数据来提升分类器的性能。Tri-training[3]是一种Co-training模式的半监督学习算法,该算法采用bootstrapping方式训练三个分类器并使它们协同工作,从未标注数据中不断引入新的样本,扩充训练集,从而得到具有良好性能的分类器。Tri-training算法将初始训练数据划分为三个不同的样本集,分别训练三个分类器作为基分类器。然而,由于弱监督训练数据中含有噪声,训练出来的基分类器是弱分类器,而且每次迭代引入的新数据中也含有噪声,噪声的累加最终会导致分类器性能下降。本文提出一种将噪声过滤机制与Tri-training融合的弱监督关系抽取算法NF-Tri-training(Tri-training with Noise Filtering),它使用数据编辑技术对初始训练数据和每轮迭代新加入的样本进行剪辑,去除数据中的噪声;并采用基于聚类的欠采样技术使初始训练数据中各类别的样本数量均衡。实验结果验证了本文方法能够提高弱监督训练数据的质量,提升了弱监督关系抽取的性能。
论文内容安排如下: 第二节介绍相关工作;第三节介绍方法原理;第四节介绍NF-Tri-training弱监督关系抽取算法;第五节是实验与结果分析;最后进行了总结。
2 相关工作
2.1 弱监督学习关系抽取
基于弱监督学习的关系抽取方法最早由Craven和Kumlien[4]提出,用于从学术文献的摘要中抽取蛋白质与基因之间的关系。Wu等[5]利用弱监督学习方法从维基百科文本中抽取属性值,对维基百科信息盒的内容进行补充。Bunescu等[6]分别将关系实体对正例和实体对反例作为查询请求,从搜索引擎查询结果中提取训练数据。Mintz等[7]利用Freebase*www.freebase.com获取关系实体对,从维基百科文本中获取训练数据。Mintz的方法基于以下假设: 如果两个实体之间存在某种关系,那么所有含有实体对的句子都描述了这个关系。Yao等[8]对Mintz提出的方法进行了改进,把关系抽取和实体的种类综合考虑,利用实体的类别来过滤掉部分错误的关系。Riedel等[2]将Mintz的假设放松为: 如果两个实体之间存在某种关系,那么含有实体对的句子中至少有一个句子描述了该关系。Takamatsu等[9]提出了减少弱监督数据错误标注的方法,该方法在标注数据的时候,通过自身隐藏的变量去判断赋予的标注是错误的还是正确的。Surdeanu等[10]基于弱监督学习对TAC-KBP进行属性模板填充。杨宇飞等[11]从互动百科信息盒中抽取<属性,属性值>二元组,从百科文本中提取训练数据,采用自训练方法从未标注数据中获取新的训练数据。陈立玮等[1]针对弱监督学习训练数据质量不高和特征不足问题,提出了利用协同训练方法来对弱监督关系抽取模型进行强化。然而,由于初始训练数据以及新添加数据中存在噪声,该方法在迭代1~2次后,分类器性能就会下降。欧阳丹彤等[12]提出基于本体的样本扩充方法进行弱监督学习下的关系抽取任务,解决弱监督学习样本匮乏的问题。
2.2 Tri-training与数据编辑
Tri-training是由Zhou等[3]人提出的基于协同训练模式的半监督学习算法。协同训练 (Co-training)最早由Blum等提出[13],要求数据集有两个充分冗余的视图(view),在两个视图上分别训练两个分类器,一个分类器产生的新标记数据将会加入到另一分类器的下次迭代训练过程中。然而实际数据集往往难以满足两个充分冗余视图的条件。为此,Goldman等[14]提出了一种不需要充分冗余视图的协同训练算法。他们使用不同的决策树算法,从同一个属性集上训练出两个不同的分类器,每个分类器都可以把示例空间划分为若干个等价类。然后用交叉验证对未标记数据进行标记,并用交叉验证综合两种学习方法形成最终预测。由于大量使用交叉验证,所以算法具有较高的时间复杂度。Tri-training算法[3]既不需要充分冗余视图,也不需要使用不同的学习算法,通过在原始数据集上抽取出的有差异的数据子集上进行训练来保证分类器之间的差异性。由于Tri-training 对属性集和分类器所用学习算法都没有约束, 而且不使用交叉验证,因此适用范围更广、效率更高。
半监督学习算法由于迭代学习引入新的训练数据中含有错误而损害分类器性能的提高[15-16]。数据编辑技术利用数据编辑规则或算法对错误标记的样例进行识别和消除,达到提高数据集质量的目的。将数据剪辑机制集成到Co-training模式半监督学习算法的研究也逐渐成为关注的焦点。Li 等[17]提出的SETRED算法就是在Co-training特例算法Self-training[18]的迭代训练过程中引入数据剪辑技术来过滤样例中的噪声。SETRED所用数据剪辑技术是基于Muhlenbach等[19]提出的邻近图的切割边权重统计法来识别误标记样例。邓超等[20-21]提出将Tri-training与最近邻规则数据编辑技术结合的DE-Tri-training半监督聚类算法,并将其改进为ADE-Tri-training算法,该算法采用自适应策略来确定数据剪辑操作的恰当时机。
3.方法原理
3.1 Tri-training
Tri-training方法大致步骤如下: 从训练集L中选择数据,划分为三个训练集,即Li(i=1,2,3);三个训练集分别用来训练三个分类器Hi(i=1,2,3);从未标注数据U中抽取出大小为P的数据集U’;使用三个分类器Hi(i=1,2,3)对U’中的任意样本x进行标注,如果H2和H3对x的分类标注H2(x)和H3(x)一致,则可将x标注为H2(x)并加入H1的训练集L1’=L1∪{x|∈U’,H2(x)=H3(x)},同样,H2和H3的训练集分别扩充为L2’和L3’;然后重新训练三个分类器,不断迭代,直至没有新的数据加入训练集,训练过程结束。
在训练集不断扩大过程中,H2和H3共同标记x为H2(x),给H1作训练数据时,如果准确性足够高,会优化H1的训练结果;否则会在H1的训练集中加入噪声,影响训练效果,降低分类性能。为此,Zhou 等[3]证明: 在PAC可学习框架下,如果新标记的训练样本足够多且满足式(1)定义的约束条件,则H1重新训练所得假设的分类性能会迭代提高。
(1)

(2)

3.2 基于邻近图切边权重统计的数据编辑法
本文采用基于邻近图切边权重统计的数据编辑方法。该方法利用数据集中的样本构造相对邻近图,通过分析图中顶点拥有切边的情况识别噪声[19]。
定义1(相对邻近图)V为顶点集合,E为边集合,当两个顶点满足式(3)的条件时,顶点之间存在边。
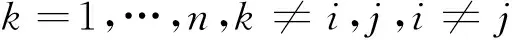
(3)
其中,d(vi,vj)表示两个顶点vi,vj之间的距离。
定义2(切边)如果邻近图中一条边的两个顶点属于不同的类别,该边称为切边。
定义3(边权重)边权重定义为式(4)。
(4)
如果邻近图中的一个点有太多的切边,这就意味着这个点很可能是异常点,可见切边数量是衡量噪声数据的一个极重要的标准。假设ni是顶点i邻居个数,wij是连接两个顶点i和j的边权重,Ji为以i为顶点的切边权重之和表示为式(5)。
(5)
其中:j表示i的邻居;wij表示i和j两顶点间边的权重;Ii(j)是独立同分布的随机变量,且满足参数为(1, 1-p) 的伯努利分布,其中p为类标签为yr(i)的概率。
为了找到异常点,设H0为假设检验命题,即在训练集中每个样本的类标签都是独立标记的,并且满足边缘分布D(Y) ,对于任何样本i,它的邻居的类标签不是y(i)的概率不会超过H0。H0实际上是为j分配了一个类标签 ,在假设下的标准分布,这个分布的期望和方差可以通过式(6)和式(7)计算得到。
(6)
(7)
预先设定的检验水准记作α,统计方法采用Z检验,即利用服从正态分布的统计量Z进行假设检验。根据方差、期望等计算出Z的值,对于给定的检验水准α,查正态分布表得临界值Zα/2,当|Z|>|Zα/2|时,拒绝原假设,即这个样本和假设检验相冲突,也意味着这个样本在邻近图中有较少的切边,是一个好的样本;反之则意味着这个样本可能是噪声,需要移除。
4. NF-Tri-training弱监督关系抽取算法
NF-Tri-training弱监督关系抽取算法框架如图1所示。

图1 NF-Tri-training弱监督关系抽取框架
该框架主要包含以下四个因素。
(1) 知识库和文本集: 该框架依赖于已有知识库和文本集;
(2) 重采样: 采用基于聚类的欠采样方法从多样本类别中采样[22-23],使各类别样本平衡;
(3)Tri-training: 使用Tri-training协同训练三个分类器,从未标注数据中获取新样本扩充训练集;
(4) 噪声过滤: 采用基于切边权重统计的数据编辑技术对初始样本集和每轮迭代新添加样本进行剪辑。
NF-Tri-training弱监督关系抽取分为三个阶段。
(1) 训练数据集自动获取: 从已有知识库中获得关系三元组
(2) 初始样本集获取: 使用数据编辑技术对训练数据进行剪辑,去除训练数据中的噪声,然后采用基于聚类的欠采样方法使各类别样本平衡,再将数据集划分为三个初始样本集S1、S2、S3。
(3) 协同训练多个分类器: 使用带噪声过滤的Tri-training算法协同训练三个分类器。首先使用三个初始样本集S1、S2、S3训练三个基分类器H1、H2、H3,对未标注数据进行标记,然后将两个分类器标记一致的样本分别加入l1、l2和l3,在对l1、l2和l3进行噪声过滤后加入初始样本集形成新的样本集S1’、S2’、S3’,重新训练分类器,反复执行此过程直到没有新样本产生。
NF-Tri-training弱监督关系抽取算法步骤如下。
算法 NF-Tri-training弱监督关系抽取算法
输入: 知识库K,文本集T
输出: 关系实体对集
算法的执行过程:
Step1 获取训练数据集和未标注数据集
(1) 从知识库K中提取关系三元组
(2) 对文本集T进行分句、分词、词性标注、实体标注以及去停用词等自然语言预处理;
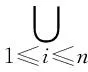

Step2 对训练集L进行噪声过滤L′←NoiseFilter(Ф,L)
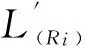
Step4 将训练集L″划分为三个初始训练集Sk,k=1,2,3
Step5 执行带噪声过滤的Tri-training算法对初始训练集Sk进行扩充
(1) 使用三个训练集Sk,k=1,2,3训练得到三个分类器H1、H2、H3;
(2) 对每个Hi(i=1,2,3),重复以下步骤直到没有新数据产生。
a.新加样本集li为空
b.在L″上估计Hj和Hk的联合错误率ei
c.对每个x∈U,如果x的类别Hj(x)=Hk(x),则li←(x,Hj(x))
d.对li进行噪声过滤li←NoiseFilter(Si,li)
e.从li中采样提取满足式(2)判别条件的子集si
f.Si←Si∪si
Step6 用投票法判定每一个新加样本的类别
Step7 从新加样本集中抽取关系实体对
NoiseFilter(s,l)的功能是识别并过滤l中的噪声数据,具体步骤如下。
1. 计算样本集s∪l中所有样本之间的距离d(xi,xj)i,j=1, …,n,i≠j,距离采用余弦相似度;

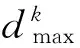
4. 计算l中每个样本的Z值,判断|Z|是否大于|Zα/2|,若大于则保留,否则该样本为噪声。
Sampling(l,q)的功能是从样本集l中提取q个样本,具体步骤如下。
1. 对l中的样本进行层次聚类,样本之间的相似度采用余弦相似度;

3. 从最大簇开始依次从每个簇中提取样本,直到提取的样本数量达到q为止。
在Tri-training算法中,判断将新样本添加至训练集的条件是需满足式(2)的要求。由于未标注数据的错误率统计非常困难,基于未标记数据集U和训练数据集L具有相同分布的假设[3],因此错误率在L上被两个分类器标注一致的子集上进行估计。
5.实验与结果分析
5.1 数据集与预处理
本文利用互动百科构建知识库。互动百科是由网络用户创建的,是最大的中文网络百科之一,目前互动百科条目数量超过700万。互动百科一些人物条目页面上具有人物关系编辑框,其中含有与该人物有关的其他人名和关系名称,构成结构化的人物关系知识。我们从人物关系编辑框中抽取结构化关系三元组<人名1,关系,人名2>作为知识库。由于互动百科人物关系是由网络用户编辑的,存在关系名称众多、用词不统一、以及含有噪声等问题。我们选择出现频次较高的关系名称,并将相似的关系整合为一种关系,例如,将关系“父母”、“次子”、“儿子”、“女儿”、“长子”、“子女”、“母亲”等合并为“父母子女”关系,将“哥哥”、“弟弟”、“兄弟”、“妹妹”等合并为“兄弟姊妹”关系。最终确定“父母子女”、 “弟兄姊妹”、“配偶”、“师徒”四种关系进行实验。
抽取出结构化的关系三元组数量共有约15万个。使用互动百科条目文章作为文本集,利用关系三元组中的实体对在文本集中进行回标,含有实体对的句子数量约为1万个。我们从中人工标注500个句子作为测试数据(每个类别100个句子,包括一个NULL类别,即含有人名实体对但没有表达指定的关系)。其余数据按照2:1比例划分为无标记数据集U和训练数据集L。使用西南交通大学中文分词平台[24]进行分词、词性标注和实体标注预处理。
我们设计了三个实验验证本文方法的有效性: 1)去噪前后分类器性能比较实验;2)重采样前后分类器性能比较实验;3)不同协同训练算法下分类器性能比较实验。
5.2 去噪前后分类器性能比较实验
我们将训练数据L进行剪辑、去除噪声数据后,得到新的训练数据L′。样本之间的相似性度量采用余弦相似度。通过比较样本点之间的相似度构造相对邻近图,然后计算边权重和切边权重和。判断样本是否为噪声的假设检验显著水平值为0.01。识别为噪声的句子示例如表1所示。

表1 噪声示例
从表1中看出,数据编辑能够识别某些未表达指定关系的句子。然而,某些正确的样本也被识别为噪声。例如,以下样本被识别为噪声。
“配偶”关系: “虽然阎文清对自己的家庭一直不愿多谈,但他早和我省著名的特级象棋大师胡明组成了一个幸福的家庭。”
“弟兄姊妹”关系: “黄伟哲的家庭属于深绿家庭,而其胞妹黄智贤却是深蓝的作家。”
虽然这两个样本表达了指定的关系,但由于与其他类别样本之间的相似性较高,被识别为噪声移除。通过实验发现比较长的文本容易被识别为噪声,原因在于长文本含有的词语较多,往往与其他类别的文本之间相似度较高。
我们用去噪前、后的训练集分别训练分类器,对测试数据进行标注,学习算法采用最大熵模型,采用词袋特征。分类性能结果比较如表2所示。性能提高百分比I是去噪后F值较去噪前F值的提高比例。
从表2看出,去噪后四种关系的分类准确率、召回率和F值均有提高。其中,父母子女关系的准确率提升较大,弟兄姊妹和师徒关系的召回率提升较大。实验结果说明,噪声去除能够提升分类器的性能。尽管某些好样本被误判为噪声,但是数据编辑仍对分类器性能提升起到了较大的作用。
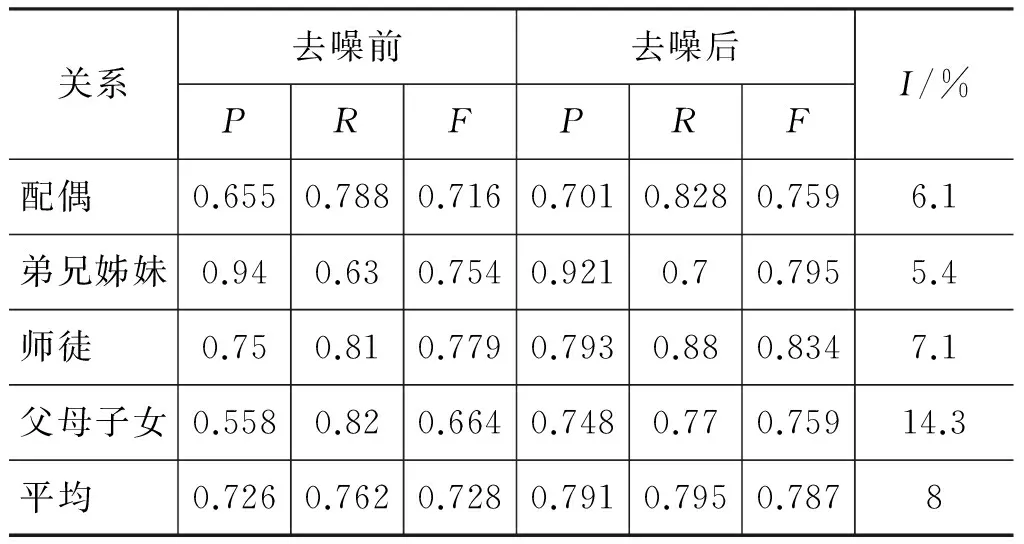
表2 去噪前后分类器性能比较
5.3 重采样前后分类器性能比较实验
去噪后的训练数据存在不平衡问题。样本分布的不平衡往往会使传统的机器学习分类方法在分类过程中严重偏向多样本类别,从而使分类的性能急剧下降[23]。为使不同关系的训练数据数量平衡,我们对训练数据进行重采样。我们采用基于聚类的欠采样方法分别从每种关系的训练数据中抽取300个样本,每种类别重采样前、后的样本数量如表3所示。
为了验证样本平衡有助于提高分类器的性能,我们分别使用重采样前、后的训练数据训练关系分类器,并对测试数据进行关系预测。分类器性能变化情况如表4所示。性能提高百分比I是重采样后F值较重采样前F值的提高比例。实验结果表明样本平衡有助于提升分类器的性能。
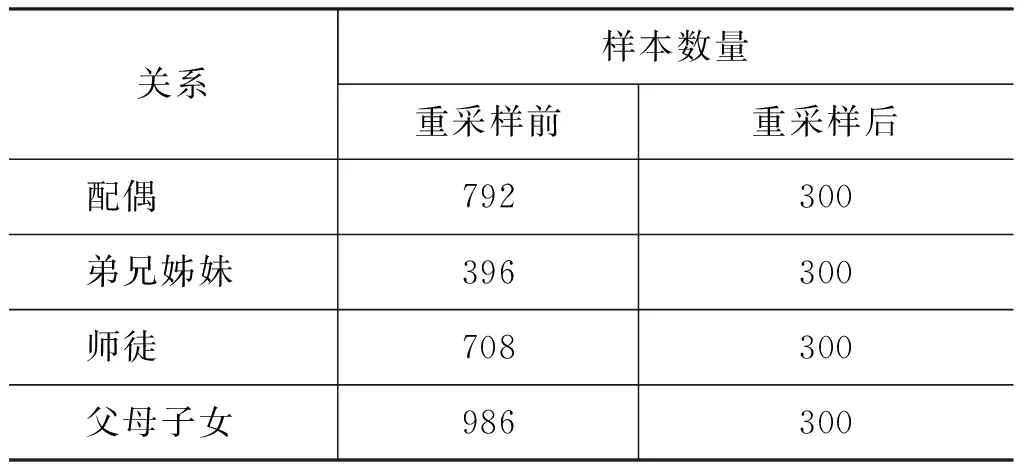
表3 重采样前后样本数量

表4 重采样前后分类器性能比较
5.4 不同协同训练算法下分类器性能比较实验
为了比较验证,我们使用四种方法进行对比实验。方法1为本文提出的NF-Tri-training方法;方法2为基于Tri-training的方法;方法3为基于Co-training的方法;方法4为带噪声过滤的Co-training方法,该方法对每轮预测结果进行去噪后再添加新样本到训练集中。训练分类器的监督学习算法采
用最大熵模型。四种方法采用的初始训练数据集相同,该数据集都经过了去噪和重采样处理。方法1和方法2将初始训练数据集划分为三个初始样本集S1、S2、S3,训练三个基分类器,分别用三个基分类器和迭代后训练的三个分类器对测试数据进行标注,样本类别采用多数投票法确定(至少两个分类器预测的关系类别一致为最终结果)。方法3和方法4采用词和词性两种不同的特征作为两个视图训练两个基分类器,分别用两个基分类器和迭代后训练的两个分类器对测试数据进行标注,样本类别采用投票法确定(两个分类器预测的关系类别一致为最终结果)。
Co-training方法需要确定三个参数[1]: 数据池大小p,每个视图每次迭代新加样本数量n和迭代次数t。本文参数确定方法如下: 从{500,1 000,1 500}中选取数据池大小p,从{20,40,60}中选取新加样本的数量n,迭代次数t从1~20。通过实验发现方法3在迭代1~2次时F值达到最高,其中在p=500,n=20时,t=1时F值最高(0.889);方法4在迭代2~15次时F值达到最高,其中在p=1 500,n=40时,t=6时F值最高(0.893)。随着迭代次数的增加,方法3和方法4分类器性能均呈无规律性波动且逐渐下降,其中方法3在迭代20次时F值下降至0.78,方法4在迭代20次时F值下降至0.81。本文分别使用最优参数下以及迭代后分类器性能与基于Tri-training的方法进行比较,分类器性能变化情况如表5所示。性能提高百分比I是迭代终止后最终F值较初始F值的提高比例。

表5 不同方法分类器初始性能和最终性能比较
从表中看出,方法1(NF-Tri-training)迭代后准确率和召回率均有提高,分类器总体性能F值提高了10.1%;方法2(Tri-training)迭代后准确率略有下降,召回率提高,F值上升了8%;方法3(Co-training)和方法4(带噪声过滤的Co-training)在最优参数下准确率均有所下降,召回率上升,总体性能F值分别上升了7.2%和7.7%,在迭代20次后F值分别下降了5%和2%。实验结果说明,Tri-training和Co-training方法(最优参数下)都能够提升分类器的性能,与噪声过滤融合后分类器性能提升更大。Co-training方法的初始分类器性能和最优参数下分类器性能均优于Tri-training方法,说明初始训练数据数量较多以及两种视图有助于提高分类器的性能(Co-training使用全部初始训练数据训练基分类器,Tri-training将初始训练数据划分为三份训练基分类器)。然而,在迭代一定轮次后,Co-training方法的性能下降较大,这是由于Co-training每次迭代添加的样本中含有噪声,虽然噪声过滤能够缓解噪声问题,但随着迭代轮次的增加,错误的关系实例仍会增加,损害分类器性能。Tri-training的方法分类器性能比较稳定,且分类器性能提升更大。
6 结论
弱监督关系抽取的训练数据是自动获取的,其中含有大量的噪声,并存在不平衡、特征不足等问题。本文提出NF-Tri-training弱监督关系抽取算法。它利用数据编辑和重采样技术提高训练数据的质量。此外,它基于Tri-training半监督学习算法,利用未标注数据扩充训练集,提升分类器的泛化能力。由于Tri-training每次迭代对未标注数据进行标记的过程中可能会出现错标,若将错标的样本再次加到训练集中,在下一次迭代训练中将会使分类器的性能降低。本文利用数据编辑技术将每次迭代产生的新标记数据进行剪辑。实验结果说明,本文提出的方法能够提高训练数据的质量,提升分类器的性能。由于NF-Tri-Training算法要求不满足样本更新条件时迭代停止,通常在迭代4-5次后就会停止,导致获取的新加样本数量和关系实体对数量较少,因此本文下一步工作研究如何既能提高分类器的性能又能够不断从未标注数据中获取更多的新样本和关系实例。
[1] 陈立玮, 冯岩松, 赵东岩. 基于弱监督学习的海量网络数据关系抽取[J]. 计算机研究与发展. 2013, 50(9): 1825-1835.
[2] Riedel S, Yao Limin, Mccallum A. Modeling relations and their mentions without labeled text[J]. Machine Learning and Knowledge Discovery in Databases. 2010, 6323: 148-163.
[3] Zhou Z H, Li M. Tri-training: exploiting unlabeled data using three classifiers[J]. IEEE Transactions on Knowledge and Data Engineering, 2005, 17(11):1529-1541.
[4] Craven M, Kumlien J. Constructing biological knowledgebases by extracting information from text sources[C]//Proceedings of the Seventh International Conference on Intelligent Systems for Molecular Biology (ISMB1999). Palo Alto, USA. 1999: 77-86.
[5] Wu F, Daniel Sw. Autonomously semantifying Wikipedia[C]//Proceedings of the Sixteenth ACM Conference on Information and Knowledge Management (CIKM2007). Lisbon, Portugal. 2007: 41-50.
[6] Bunescu R, Mooney R. Learning to extract relations from the Web using minimal supervision[C]//Proceedings of the 45th Annual Meeting of the Association for Computational Linguistics. Stroudsburg (ACL2007), USA. 2007, 45(1): 567-583.
[7] Mintz M, Bills S, Snow R, et al. Distant supervision for relation extraction without labeled data[C]//Proceedings of the 47thAnnual Meeting of the Association for Computational Linguistics (ACL2009). Singapore. 2009: 1003-1011.
[8] Yao L M, Riedel S, Mccallum A. Collective cross document relation extraction without labeled data[C]//Proceedings of 2010 Conference on Empirical Methods in Natural Language Processing (EMNLP 2010). Massachusetts, USA. 2010: 1013-1023.
[9] Takamatsu S, Sato I, Nakagawa H. Reducing wrong labels in distant supervision for relation extraction[C]//Proceedings of the 50th Annual Meeting of the Association for Computational Linguistics (ACL2012). Jeju Island, Korea. 2012: 721-729.
[10] Surdanu M, Mcclosky D, Tibshirani J, et al. A simple distant supervision approach for the TAC-KBP slot filling task [C]//Proceedings of the TAC-KBP 2010 Workshop, USA, 2010:1-5.
[11] 杨宇飞, 戴齐, 贾真,等. 基于弱监督的属性关系抽取方法[J]. 计算机应用, 2014,34(1): 64-68.
[12] 欧阳丹彤, 瞿剑峰, 叶育鑫.关系抽取中基于本体的远监督样本扩充[J]. 软件学报. 2014, 25(9): 2088-2101.
[13] Blum A, Mitchell T. Combining labeled and unlabeled data with co-training[C]//Proceedings of the 11th annual conference on Computational Learning Theory(COLT1998).Wisconsin,USA,1998: 92-100.
[14] Goldman S, Zhou Y. Enhancing supervised learning with un-labeled data[C]//Proceedings of the 17th International Conference on Machine Learning(ICML2000). California, USA, 2000: 327-334.
[15] Nigam K, Mccallum Ak, Thrun S, et al. Text classification from labeled and unlabeled documents using EM[J].Machine Learning,2000, 39(223): 103-134.
[16] Blum A, Chawla S. Learning from labeled and unlabeled data using graph min cuts[C]//Proceedings of the 18th International Conference on Machine Learning(ICML2001). Williamstown, MA, 2001: 19-26.
[17] Li M, Zhou ZH. SETRED: Self-training with editing[C]//Proceedings of the 9th Pacific-Asia Conference on Knowledge Discovery and Data Mining(PAKDD2005). Hanoi, Vietnam, 2005: 611-621
[18] Nigam K, Ghani R. Analyzing the effectiveness and applicability of co-training[C]//Proceedings of the ACM 9th Conference on Information and Knowledge Management(CIKM2000). Washington, DC, 2000: 86-93
[19] Muhlenbach F, Lallich S, Zighed Da. Identifying and handling mislabeled instances[J]. Journal of Intelligent Information Systems, 2004, 22(1) : 89-109.
[20] 邓超, 郭茂祖. 基于Tri-Training 和数据剪辑的半监督聚类算法[J]. 软件学报. 2008, 19(3): 663-673.
[21] 邓超, 郭茂祖. 基于自适应数据剪辑策略的Tri-training算法[J]. 计算机学报. 2007, 30(8):1213-1226.
[22] Yen S, Lee Y. Cluster-based under-sampling approaches for imbalanced data distributions[J]. Expert Systems with Applications, 2009, 36: 5718-5727.
[23] 王中卿, 李寿山, 朱巧明, 等. 基于不平衡数据的中文情感分类[J]. 中文信息学报. 2012, 26(3):33-37, 64.
[24] 尹红风, 贾真, 李天瑞, 等. 西南交通大学中文分词[OL]. http://ics.swjtu.edu.cn
Weakly Supervised Relation Extraction Based on Tri-training and Noise Filtering
JIA Zhen1, YE Zhonglin1, YIN Hongfeng2, HE Dake1
(1. School of Information and Science Technology, Southwest Jiaotong University, Chengdu, Sichuan 610031, China;2. DOCOMO Innovations Inc.,Palo Alto 94304, USA)
Weakly supervised relation extraction utilizes entity pairs to obtain training data from texts automatically, which can effectively deal with the problem of inadequate training data. However, there are many problems in the weakly supervised training data such as noise, inadequate features, and imbalance samples, leading to low performance of relation extraction. In this paper, a weakly supervised relation extraction algorithm named NF-Tri-training (Tri-training with Noise Filtering) is proposed. NF-Tri-training employs an under-sampling approach to solve the problem of imbalance samples, learns new samples iteratively from unlabeled data and uses a data editing technique to identify and discard possible mislabeled samples both in initial training data and in new samples generating at each iteration. The experiment on dataset of Hudong encyclopedia indicates the proposed method can improve the performance of relation classifiers.
relation extraction; weakly supervised learning; Tri-training; data editing

贾真(1975—),博士,讲师,主要研究领域为信息抽取与知识获取。E-mail:zjia@home.swjtu.edu.cn冶忠林(1989—),硕士研究生,主要研究领域为自然语言处理与智能问答。E-mail:zhonglin_ye@foxmail.com尹红风(1964—),博士,教授,主要研究领域为自然语言处理与智能问答。E-mail:hongfeng_yin@yahoo.com
1003-0077(2016)04-0142-08
2014-09-25 定稿日期: 2015-04-07
国家自然科学基金(61170111, 61202043, 61262058)
TP
A
猜你喜欢
中学生数理化·高一版(2021年2期)2021-03-19 08:32:00
数学年刊A辑(中文版)(2020年3期)2020-10-27 02:44:16
知识经济·中国直销(2018年8期)2018-08-23 09:16:16
电子测试(2018年1期)2018-04-18 11:52:35
中学生数理化·八年级物理人教版(2017年9期)2017-12-20 08:11:30
数学学习与研究(2017年3期)2017-03-09 18:12:42
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
中国老区建设(2016年1期)2016-02-28 09:32:00
噪声与振动控制(2015年4期)2015-01-01 07:08:05
