
基于层叠条件随机场的高棉语分词及词性标注方法
2016-05-03 13:02:03潘华山余正涛郭剑毅
中文信息学报 2016年4期
潘华山,严 馨,周 枫,余正涛,郭剑毅
(昆明理工大学 信息工程与自动化学院和云南省计算机技术应用重点实验室,云南 昆明 650500)
基于层叠条件随机场的高棉语分词及词性标注方法
潘华山,严 馨,周 枫,余正涛,郭剑毅
(昆明理工大学 信息工程与自动化学院和云南省计算机技术应用重点实验室,云南 昆明 650500)
针对高棉语分词及词性标注问题,提出一种基于层叠条件随机场模型的自动分词及词性标注方法。该方法由三层条件随机场模型构成: 第一层是分词模型,该模型以字符簇为粒度,结合上下文信息与高棉语的构词特点构建特征模板,实现对高棉语句子的自动分词;第二层是分词结果修正模型,该模型以词语为粒度,结合上下文信息与高棉语中命名实体的构成特点构建特征模板,实现对第一层分词结果的修正;第三层是词性标注模型,该模型以词语为粒度,结合上下文信息与高棉语丰富的词缀信息构建特征模板,实现对高棉语句子中的词语进行自动标注词性。基于该模型进行开放测试实验,最终准确率为95.44%,结果表明该方法能有效解决高棉语的分词和词性标注问题。
高棉语;层叠条件随机场;分词;词性标注
1 引言
柬埔寨语又称高棉语,属南亚语系孟高棉语族高棉语支,是柬埔寨的官方语言。高棉语是在古高棉语的基础上演变和发展而来的。由于历史上与印度宗教之间的关系,高棉语吸收了许多巴梵语词汇,巴梵语的大量借用对高棉语的构词形态产生了重要影响。近代,由于法国殖民统治和现代科技的发展,高棉语还吸收了英法等多国的语言词汇。因此,高棉语的构词形态非常多样化。高棉语的构词法大致可分为三类: 单纯词构词法、合成词构词法和内部曲折法[1]。高棉语的构成与英语比较类似: 首先由基本字符根据特定规则构成KCC[2](Khmer Character Cluster,字符簇),然后再由KCC构成词素,最后由词素构成词语,进而构成高棉语句子和文本。
近年来,随着自然语言处理工作在各国的展开,高棉语的自然语言处理也受到越来越多研究者的重视。高棉语同许多其他亚洲语言一样是连续书写的,词与词之间没有明显的分隔符,因此对高棉语进行分词和词性标注研究具有重要意义。目前,已有少数机构和个人开展了相关工作: 蒋艳荣等人[3]针对采用最大匹配算法对高棉语进行分词准确率低的问题,提出一种采用改进的Viterbi算法通过最优选择及剪枝操作来改善分词效率,并取得了一定的效果;Chea Sok Huor等人[4]提出基于词语和音节的混合二元文法模型对高棉语进行分词,实验结果显示该方法能获得相对较好的切分效率;Chenda NOU等人[5]针对高棉语词性标注问题,提出一种融合规则和三元文法模型的混合方法对高棉语进行词性标注,在一个小型语料集的开放实验中取得了不错的效果。上述研究均针对分词和词性标注中的单一任务进行研究,并没有考虑将二者统一到一个框架下,且分词和词性标注的效率也有待进一步提高。
针对以上问题,本文提出一种基于层叠条件随机场(Cascaded Conditional Random Fields,CCRFs)模型的高棉语自动分词及词性标注方法,该方法由三层条件随机场模型构成: 第一层为分词模型,该模型融合KCC的上下文信息和高棉语的构词特点,实现高棉语自动分词;第二层为分词结果修正模型,该模型融合分词结果的上下文信息和高棉语命名实体的构成特点,实现对分词结果的修正;第三层为词性标注模型,该模型融合词语的上下文信息和高棉语的词缀等信息,实现高棉语词性自动标注。该层叠模型不仅可将高棉语的分词和词性标注统一在一个框架下,而且还可利用层级信息来改善处理效率。
2 基于层叠条件随机场的高棉语分词及词性标注方法
2.1 层叠条件随机场模型
高棉语的分词和词性标注都属于序列标注问题,而条件随机场[6]在解决序列标注问题上具有许多优势,它克服了隐马尔可夫模型的独立性假设及最大熵模型的标记偏置等缺陷,能获得全局最优解,为当前解决序列标注问题的最佳方案,且已在多个任务中获得迄今为止的最佳性能,因此本文将条件随机场模型作为解决高棉语分词和词性标注的基础模型。
由于分词结果的上下文信息和高棉语丰富的词缀信息都能为词性标注提供有效的特征,因此需要引入多层的条件随机场模型用于高棉语的分词和词性标注。本文所提出的层叠模型共包含三层: 第一层是分词模型。输入经过分解KCC之后的KCC序列,利用条件随机场模型融合KCC序列的上下文信息与高棉语的构词特征,实现高棉语的自动分词;第二层是分词结果修正模型。该模型以上层分词结果作为输入,利用条件随机场模型融合分词结果的上下文信息和高棉语命名实体的构成特征,实现对上层分词结果的自动修正;第三层是词性标注模型,输入为修正后的分词结果,利用条件随机场模型融合分词结果的上下文信息与高棉语丰富的词缀信息等特征,实现高棉语的自动词性标注。整个层叠模型的架构图如图1所示。

图1 基于层叠条件随机场的高棉语分词及词性标注模型架构图
2.2 分词模型
高棉语由基本的元音符号、辅音符号和一些其他符号构成,这些符号按照特定规则构成具有固定读音的KCC,该规则满足式(1)[2]。
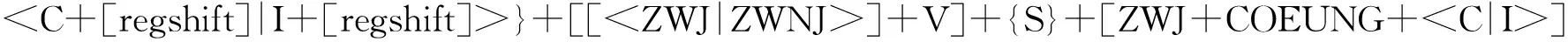
(1)
其中,{}表示包含在其中的内容可出现0-2次,[]表示包含在其中的内容可出现0-1次,

表1 表达式-Unicode码对应表
除式(1)能匹配的KCC之外,将高棉语中出现的其他字符串,如国际标点符号、高棉语标点符号、阿拉伯数字串、高棉语数字串及英文字符串等都同等视作KCC,将制定单独的正则表达式进行匹配识别。
按照以上方法可以将高棉语原始文本分解为KCC序列。根据KCC序列所包含的上下文信息以及高棉语的构词特点,将分词模型训练时的特征模板定义如表2所示。
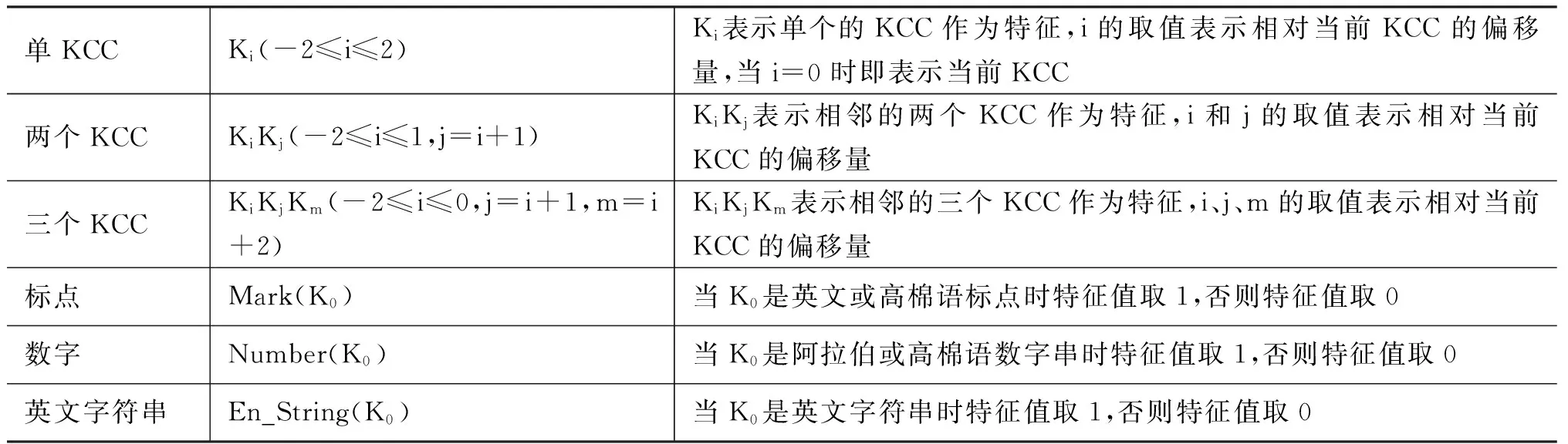
表2 分词特征模板
训练语料来源于PLC(PAN Localization Cambodia)*http://www.panl10n.net/发布的公开语料集Khmer Tagged Corpus*http:/www.panl10n.net/english/Outputs%20Phase%202/CCs/Cambodia/MoEYS/Software/2009/ KhmerCorpus.zip(简称KCorpus,下同),KCorpus是一个经过分词和词性标注处理的高棉语语料集,其中词性标签集参照Khmer Part of Speech description*http://www.PANL10n.net/wiki/PartOfSpeech。训练时,首先需要将语料集中的每个词语进行KCC分解,并
采用{B,M,E,S}四标记法对每个KCC进行标注;然后按照表2准备好分词特征模板;最后调用CRF++工具包[8],以分解过KCC的语料集和分词特征模板为输入,通过训练学习即可获得分词模型。构建分词模型的流程图如图2所示。
图2 分词模型构建流程图
2.3 分词结果修正模型
对获得的分词模型进行开放测试, 随机从分词结果中选取40 000词进行统计,结果如表3所示。其中,未登录词(Out of vocabulary)[9]切分错误约占错误总数的34%。分词错误会直接传递到词性标
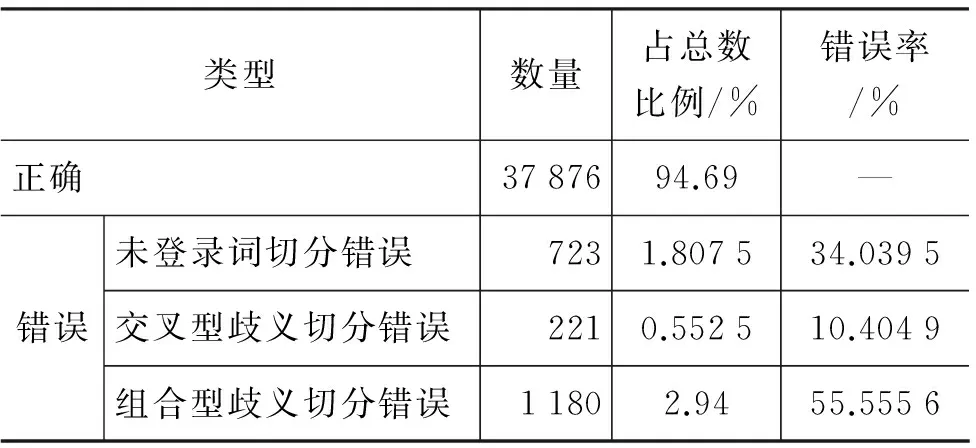
表3 分词错误统计
注,从而导致词性标注也发生错误,进而影响分词及词性标注的整体性能。若能对未登录词切分错误进行有效的修正,不仅可以提高分词精度,同时还可以降低部分因错误传递而出现的词性标注错误,可以从整体上提高高棉语分词以及词性标注的性能。基于上述考虑,增加分词结果修正模型。
进一步对未登录词切分错误进行分析,发现其中大部分错误是人名、组织机构名、地名等命名实体的切分错误,故分词结果修正模型主要针对分词中的命名实体进行建模。总结高棉语命名实体的特点,发现当某些特殊前缀或后缀出现时,连续出现的几个词成为命名实体的概率非常大,同时考虑分词结果的上下文信息,分词结果修正模型训练时的特征模板定义如表4所示。

表4 分词结果修正模型的特征模板
训练语料同样采用KCorpus。由于KCorpus没有标注命名实体,所以需要对KCorpus中的命名实体进行手工标注,标注时以三名高棉语语言学研究人员的投票结果作为最终结果,当投票结果存在异议时参考English-Vietnamese Named Entity Guidelines[10]进行标注。因为此处的命名实体识别只是为了修正分词模型的切分错误,所以无需对实体的类别进行区分。因此,可以直接采用{B,M,E,S}四标记法对实体进行标注。
在准备好训练语料和特征模板之后,利用CRF++工具包即可实现对KCorpus中的命名实体进行学习从而获取分词结果修正模型。构建分词结果修正模型的流程图如图3所示。

图3 分词结果修正模型构建流程图
2.4 词性标注模型
经过修正会得到更好的分词结果,接下来需要对分词结果进行词性标注。由高棉语的构词特点可知,高棉语词汇包含丰富的词缀信息[11],如果能对词缀信息加以利用,设计适合高棉语构词特性的特征模板,可有效提高高棉语词性标注的性能。高棉语词缀既有表示语义(词性)的辅助词素,又有表示词义的辅助词素,且同一词缀可以表示多种词性。若采用规则的方法,不仅需要手工构建规则库,还需要考虑规则库的覆盖率和处理效率, 而且规则方法都有主观性,难以保证一致性,适应性较差。
本文利用条件随机场模型的多特征融合能力,充分融合分词结果的上下文信息和高棉语的词
缀信息,从而解决高棉语的词性标注问题。其中,词干的词性将结合上下文信息从高棉语词典Chuon Nath Khmer Dictionary[12]中提取,词性标记采用Khmer Part-of-Speech Tagger[13]中发布的词性标记集。词性标注模型训练时的特征模板定义如表5所示。
训练语料仍然采用KCorpus。在准备好训练语料和特征模板后,调用CRF++工具包即可对KCorpus中的词性标注结果进行学习,从而获取词性标注模型。构建词性标注模型的流程图如图4所示。
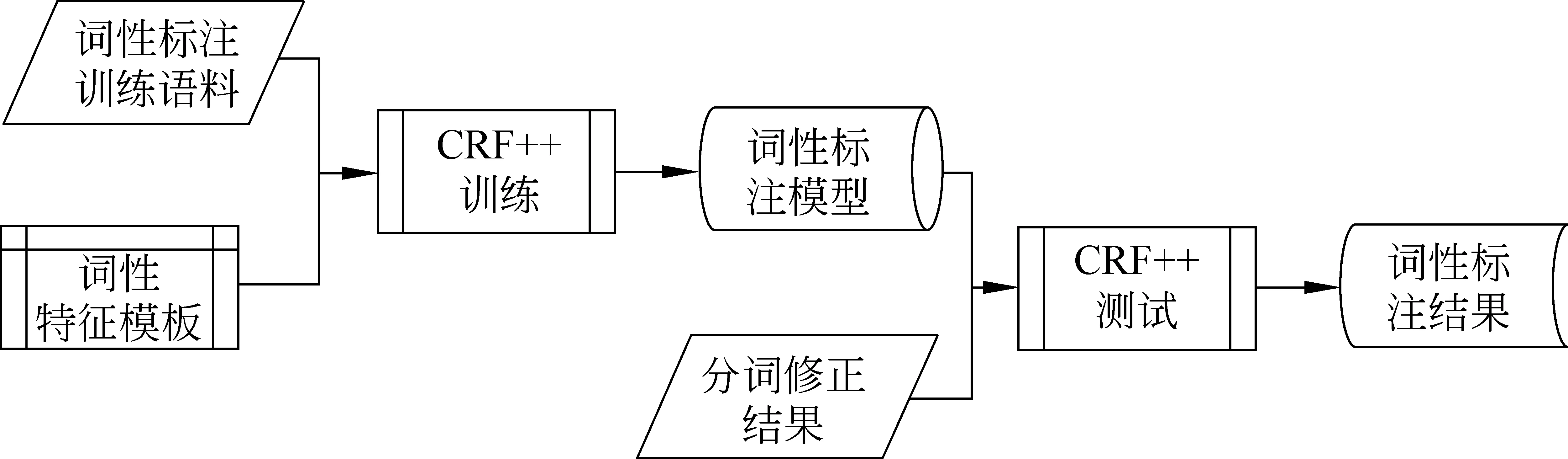
图4 词性标注模型构建流程图
3 实验结果与分析
为了客观评价本文方法的效果,分别针对高棉语的分词和词性标注做了两组对比实验。第一组实验是高棉语分词的性能对比,用单层模型(CRFs,分词模型)、两层模型(CCRFs,分词模型+分词结果修正模型)与最大匹配算法[3]、MViterbi算法[3]以及二元文法模型[4]进行开放测试对比实验;第二组实验是高棉语词性标注的性能对比,用三层模型(CCRFs,分词模型+分词结果修正模型+词性标注模型)与基于变换的方法[5]进行开放测试对比实验。本文开放测试的语料来源于从柬埔寨新闻网*http://www.dap-news.com上收集的自2012年10月至2013年7月的新闻文本,涵盖艺术、娱乐、体育、健康、经济、国内以及国际等七大新闻板块,约10M(50万词)。


采用准确率、召回率和F值对实验结果进行评价。结果如表6、表7所示。
表6 最大匹配算法、MViterbi算法、二元文法模型、单层模型(CRFs)、两层模型(CCRFs)的高棉语分词实验结果比较

测试类型准确率/%召回率/%F值/%最大匹配算法72.26——MViterbi算法88.17——二元文法模型91.56292.13891.849单层模型(CRFs)94.6995.0694.87两层模型(CCRFs)96.0296.4996.25
由表6可知,两层模型(CCRFs)的分词效果相对于单层模型(CRFs)以及其他方法,其正确率、召回率均有提升。尤其是相对于前三种方法中效果最好的二元文法模型来说,两层模型的准确率提高了近4.5个百分点,说明本文方法对解决高棉语的分词问题是非常有效的。另外,相对于单层模型(CRFs),两层模型(CCRFs)的准确率和召回率都得到了小幅提升,说明加入分词结果修正模型是有必要的。
表7 基于变换的方法与三层模型(CCRFs)的词性标注实验结果比较
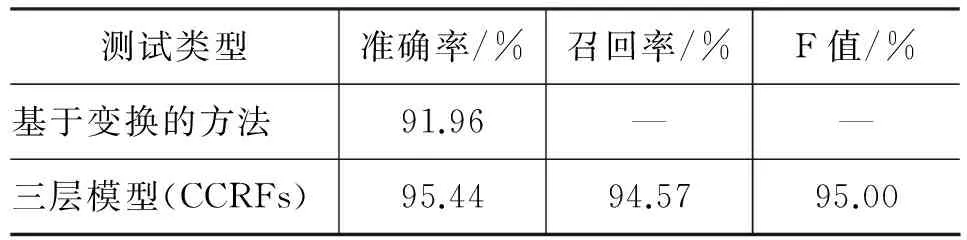
测试类型准确率/%召回率/%F值/%基于变换的方法91.96——三层模型(CCRFs)95.4494.5795.00
由表7可知,三层模型(CCRFs,分词模型+分词结果修正模型+词性标注模型)的词性标注效果相对于基于变换的方法,正确率提高了近3.5个百分点,同时还获得了94.57%的召回率,说明利用层叠条件随机场模型来解决高棉语分词及词性标注问题是行之有效的。
4 结论
本文针对高棉语的分词和词性标注问题,提出一种基于层叠条件随机场模型的高棉语分词和词性标注方法。该方法不仅考虑上下文信息对高棉语分词和词性的影响,还通过对大量高棉语文本进行总结归纳,得到一些可利用的语言特征,并将其设计成有效的特征模板。实验结果表明本文方法不仅能有效地解决高棉语的分词和词性标注问题,而且还能将高棉语分词和词性标注统一在一个框架中解决。
在实验中发现两个问题有待进一步解决: 一是对分词模型的开放测试结果进行统计后发现,组合型歧义切分错误占错误总数的55.56%,比未登录词切分错误还多,虽然对未登录词中的命名实体切分错误进行了修正,但结果显示效果提高并不是太大,若能有效解决组合型歧义切分错误,将能进一步提高高棉语分词及词性标注的性能;二是由于高棉语构词的特殊性,分词之前需要先分解KCC,这个过程增加了系统的资源和时间开销,经统计,层叠模型的处理速度约为32.65kb/s,仍有提升空间。
[1] 莫源源. 高棉语的构词方式及其语法功能[J]. 教法研究, 2012(10):45-46.
[2] Huor C S, Rithy T, Hemy R P, et al. Detection and Correction of Homophonous Error in Khmer Language[J]. PAN Localization Working Papers, 2006:243-248.
[3] 蒋艳荣,刘习文,陈耿涛.基于Viterbi改进算法的高棉语分词研究[J].计算机工程, 2011,37(15):174-176.
[4] Huor C S, Rithy T, Hemy R P, et al. Word Bigram Vs Orthographic Syllable Bigram in Khmer Word Segmentation[J]. PAN Localization Working Papers, 2004:249-253.
[5] Nou C, Kameyama W. Khmer POS Tagger: A Transformation-based Approach with Hybrid Unknown Word Handling[C]//Proceedings of the International Conference on Semantic Computing, 2007:482-492.
[6] Lafferty J, McCallum A, Pereira F C N. Conditional random fields: Probabilistic models for segmenting and labeling sequence data[C]//Proceedings of the Eighteenth International Conference on Machine Learning, 2001:282-289.
[7] The Unicode Consortium. The Unicode Standard, Version 6.2.0[S]. Unicode Consortium, 2012.
[8] TakuKudo. CRF++ toolkit[CP]. 2005, http://crfpp.sourceforge.net/
[9] Bazzi I, Glass J. Modelling out-of-vocabulary words for robust speech recognition[D]. Proc Icslp, 2002.
[10] Ngo Q H, Dien D, Winiwarter W. Building English-Vietnamese Named Entity Corpus with Aligned Bilingual News Articles[C]//Proceedings of The Workshop on South & Southeast Asian Natural Language Processing,2014:85-93.
[11] 肯素(柬埔寨).高棉语法[M].柬埔寨皇家科学院出版社,2007.5.
[12] Nath C. Dictionnaire cambodgien[M]. Phnom Penh,1967.
[13] Nou C, Kameyama W. Khmer POS Tagger: A Transformation-based Approach with Hybrid Unknown Word Handling[C]//Proceedings of International Conference on Semantic Computing, 2007:482-492.
A Khmer Word Segmentation and Part-of-Speech Tagging Method Based on Cascaded Conditional Random Fields
PAN Huashan, YAN Xin, ZHOU Feng, YU Zhengtao, GUO Jianyi
(School of Information Engineering and Automation, Kunming University of Science and Technology and Key Lab of Computer Technologies Application of Yunnan Province, Kunming, Yunnan 650500,China)
This paper presents a Khmer automatic word segmentation and POS tagging method based on Cascaded Conditional Random Fields(CCRFs) model. The approach consists of three layers of Conditional Random Fields(CRFs) models: the first layer is the word segmentation model in Khmer character cluster(KCC) granularity, integrating the word formation characteristics of Khmer into the feature template; the second layer is the word segmentation correction model in word granularity, integrating the characteristic of Khmer named entities into the feature template; the third layer is the POS tagging model, integrating the rich affixes information into the feature template, and achieved the Khmer POS tagging. We experimented on an open corpus and obtained a final accuracy rate of 95.44%, indicating that the proposed method can effectively solve the Khmer word segmentation and POS tagging problems.
Khmer;cascaded conditional random fields;word segmentation;POS tagging

潘华山(1987—),硕士,主要研究领域为自然语言处理。E-mail:panhuashan2008@126.com严馨(1969—),通信作者,副教授,主要研究领域为自然语言处理。E-mail:kg_yanxin@sina.com周枫(1958—),副教授,主要研究领域为自然语言处理。E-mail:zf158@sina.com
1003-0077(2016)04-0110-07
2014-03-20 定稿日期: 2015-06-09
国家自然科学基金(61462055)
TP391
A
猜你喜欢
Journal of Palaeogeography(2022年1期)2022-03-25 04:17:00
快乐语文(2021年35期)2022-01-18 06:05:30
法律方法(2019年4期)2019-11-16 01:07:28
智富时代(2019年6期)2019-07-24 10:33:16
摄影之友(影像视觉)(2017年1期)2017-07-18 11:12:16
海外华文教育(2016年1期)2017-01-20 08:21:58
高中生·天天向上(2016年9期)2016-11-22 09:10:34
当代教育理论与实践(2015年9期)2015-12-16 16:26:05
民族古籍研究(2014年0期)2014-10-27 08:24:34
外语教学理论与实践(2014年2期)2014-06-21 08:34:20
