
一种基于主动学习的框架元素标注
2016-05-03 13:11:19屠寒非王智强周铁峰
中文信息学报 2016年4期
屠寒非,李 茹,2,王智强,周铁峰
(1. 山西大学 计算机与信息技术学院,山西 太原 030006;2.计算机智能与中文信息处理教育部重点实验室,山西 太原 030006)
一种基于主动学习的框架元素标注
屠寒非1,李 茹1,2,王智强1,周铁峰1
(1. 山西大学 计算机与信息技术学院,山西 太原 030006;2.计算机智能与中文信息处理教育部重点实验室,山西 太原 030006)
框架元素标注是中文FrameNet众多任务中亟待解决的一个问题,目前仍主要采用有监督的机器学习方法,即依赖大规模人工标注的例句作为训练语料。但例句标注又是一件费时费力的工作,所以为了降低人工标注的代价,该文将主动学习应用到框架元素标注中,优先选择训练模型预测最不准的例句交由人工标注。该文以条件随机场为标注模型,并提出了进行样本选择时所依赖的准则。实验表明,一方面,与随机选择样本进行标注相比,当使用相同数量的例句训练模型时,主动学习使框架元素标注的性能最高提升4.83%;另一方面,主动学习使框架元素标注达到同等F值时只需更少的标注例句,人工标注量最高可减少30%。
主动学习;框架元素标注;条件随机场;不确定性度量
1 引言
传统的监督学习方法直接使用已有的标注数据来训练模型,称为被动学习。而与之对应的主动学习则可以让学习器在一定程度上选择最富含有效信息的数据加入到训练集中。因为选择了对训练模型性能提升最高的数据,所以在等量的数据作训练集时,主动学习可以获得更好的结果。
汉语框架元素标注是以中文FrameNet为语料库的语义角色标注。近年来关于语义角色标注的研究多采用有监督的学习方法,并集中于方法和特征选择上。数据作为有监督学习中的重要一环,在框架元素标注中还没有与之相关的研究。因为标注高质量大规模的语料耗时耗力,所以数据已经成为提高框架元素标注性能的瓶颈问题。本文将主动学习应用到框架元素标注中,旨在解决目前因为中文FrameNet的语料稀疏而导致的框架元素标注性能较低的问题,同时减少对提高框架元素标注性能帮助不大的冗余样本的标注。
本文采用条件随机场(CRFs)作为标注模型,然后根据主动学习的方式,改进了语料标注和模型训练的过程。实验表明,使用相同数量的训练语料时,主动学习的结果比被动学习最高提升了4.83%,而在达到同等结果时,主动学习需要的训练语料可减少30%。
本文组织结构为,第二部分介绍语义角色标注及主动学习的相关工作,第三部分详细讨论了基于主动学习的框架元素标注中的算法、标注模型、样本选择等,第四部分是实验及结果分析,第五部分给出了结论和下一步工作,最后在附录里给出了部分实验结果以作分析*因篇幅有限,所以将全部实验结果及系统相关信息公布在http://115.24.12.89:8080/autoanno/。
2 相关工作
2.1 框架元素标注
汉语框架元素标注是以中文FrameNet为语料库的语义角色标注。语义角色标注按语料库的不同划分,主要有PropBank[1]和FrameNet[2]两种。在基于PropBank的语义角色标注研究方面,Prandhan[3]等将支持向量机的机器学习方法应用于语义角色标注中,获得了84%的准确率和75%的召回率。Cohn[4]等则首次将条件随机场应用到语义角色标注中。刘挺[5]等以句法成分作为语义标注的基本单元,在近四万条例句上使用最大熵分类模型并最终在测试集上取得了75.6%的F值。另一方面,是以FrameNet为语料库的语义角色标注研究,即框架元素标注,Dan Gildea与Dan Jurafsky在完全句法分析的基础上,选取短语类型、词在句中相对目标词的位置、句法功能等作为特征,使用条件概率估计方法,在大约五万条人工标注了语义角色的例句上训练分类器,最终取得了65%的准确率和61%的召回率[6]。李济洪等针对中文FrameNet的框架元素标注,使用条件随机场模型,在25个框架的 6 692个例句上获得了61.62%的F值[7]。
目前,上述所有的语义角色标注方法都是采用被动学习的方法,即通过在事先标注的训练样本上训练模型,然后对未标注数据进行预测。尽管这种被动学习方法取得了较好的效果,但是都建立在大规模高质量的训练语料上,而这些语料的构建需要耗时耗力地人工标注。相比与PropBank、FrameNet的大规模的训练样本,中文FrameNet的训练样本还相对较少,并且由于框架语义角色类型(即框架元素)众多,导致训练样本中的框架元素更加稀疏,这是导致目前基于中文FrameNet的框架元素标注性能较低以及覆盖面较小的一个重要原因。
所以针对上述问题本文将主动学习的方法应用到框架语义角色标注中的语料构建方面。本文利用主动学习的方法选择对训练模型最“有用”的样本,将其进行人工标注。与被动学习不同,这种主动学习的方式由一个效用函数φ(·)来判断哪些样本对训练模型的性能提升最有价值,从而将其加入到训练集中。这样就可以用较少的训练样本取得与使用很大的训练样本集近似的效果[8],从而降低因语料较少而对汉语框架元素标注的性能造成的影响。本文不仅探讨了主动学习和被动学习对框架元素标注性能的影响,并将主动学习应用到汉语框架元素标注的语料构建中,有效解决了因语料稀疏而导致的框架元素标注性能较低和覆盖面小的问题。
2.2 主动学习
目前使用较多的主动学习方法主要有基于委员会投票和不确定性抽样两种[9]。
基于委员会投票的实例选择通常通过构建一组训练模型来完成,这些训练模型可以用不同的训练算法得到(支持向量机,最大熵,CRFs等),也可以用相同的训练算法对实例从不同的特征角度训练得到[10]。基于委员会投票的方法优先选择各分类器投票结果最不一致的样本进行人工标注。McCallum和Nigamy等[11]利用相对熵来度量委员会成员投票差异,但是这种度量漏选了一些委员会成员预测投票不一致的样本,而这些样本正是基于委员会投票原理所要选择的实例。Engelson和Dagan等[12]则利用投票熵来度量委员会成员投票不一致性,它虽然选择了投票不一致的实例,但是并没有考虑委员会成员对样本的预测条件概率值,这同样会导致漏选一些信息量丰富的样本数据。因此,以上这两种度量都会导致最后的学习器性能不高。接下来介绍主动学习中的另一种方法。
不确定性抽样同样是采用评估实例信息量的主动学习方法[13],该方法通过训练模型对预测置信度的高低来选择最不确定如何标注的例子。以框架元素标注为例,实例的预测置信度越低,说明训练模型对该实例不能很好的标注,即训练模型缺乏此实例所含有的信息。此时将该样本进行人工标注并加入训练集会对训练模型性能的提升有很大帮助。而对于预测置信度高的样本,则不再进行人工标注,从而避免了在冗余样本上耗费人力。这类学习算法的重点是构造一种合理有效的不确定性度量机制,并以此来指导样本选择。
在国外主动学习方法已经应用到很多与自然语言处理相关的任务中,最早在1999年Thompson就将主动学习方法应用到了语义分析和信息抽取中,显著降低了需要人工标注的数据量[14]。McCallum将主动学习方法应用到文本分类中[15],Hwa则将主动学习应用到了句法分布中[16]。此外Ngai[17]、Tomanek[18]、Settles[19]等也将主动学习应用到了自然语言处理中的各个相关语料构建方面。在国内,覃刚力、宋鑫颖等将主动学习应用到文本分类上[20-21];苏州大学居胜峰则将主动学习应用到了情感分类任务中[22]。冯冲在基于最大熵的组织机构名识别中采用了主动学习的策略,取得了一定效果[23]。哈尔滨工业大学的车万翔等将主动学习应用于中文依存句法分析,降低了30%的人工标注量[24]。但是目前还没有将主动学习与框架元素标注相结合的研究。
3 基于主动学习的框架元素标注
3.1 主动学习的算法流程
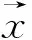
3.2 标注模型

图1 可将框架元素标注作为序列标注的示例图

L:人工标注例句的集合U:未标注的集合(已经过分词和词性标注的句子)C:当前已标注例句训练得到的模型(基于CRF的语义角色标注)φ(x):效用函数,即衡量例子可信度的函数。B:每轮主动学习选择的例子数。初始化: 从U中选出小部分未标注的例句,人工标注,加入到L; C←Train(L);重复: U1←用C预测所有U; N←根据效用函数φ(x),选择不可信度最大的B个例句; U←U—N; 人工标注N后,加入L; C←Train(L);直到: 满足特定条件,即迭代次数或所有预测置信度达到阈值。算法1 主动学习过程

(1)

本文按框架来训练模型,所以152个框架对应的要训练152个模型参数。每个训练模型参数λi的值通过在该框架的例句训练集T上让对数似然函数L取最大值得到, 但如果直接使用对数最大似然估计,可能会导致过度学习的问题,所以引入惩罚函数的方法来解决这一问题,如式(2)所示。
(2)
对L(T)求偏倒数,得式(3)。
(3)
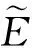
(4)
但是直接计算期望E(fi)比较困难,所以在此引入前向后向算法来解决这个问题[26],通过将归一化后的前向后向值代入式(4)中,从而可以以基于梯度或迭代缩减的方法最优化L(T),最后得到152个框架相对应的参数λi。
3.3 特征选择
本文主要关注主动学习与汉语框架元素标注的结合是否可以有效减少需要标注例句的数量,及在相同数据下是否可以比被动学习的方法得到更好的效果,从而将其应用到汉语框架元素标注的语料构建当中,所以对于特征部分仅采用文献[27]中的T1模板,如表1所示。

表1 T1模板特征选取及模板设置
3.4 样本选择
主动学习的重点在样本选择,即如何选择最富含信息量的数据交给人工标注。图2简洁地显示了主动学习的任务并展示了对于训练模型而言哪些样本是对提升模型性能最好的实例。
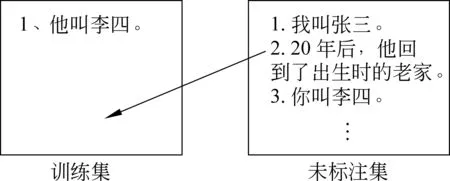
图2 主动学习任务的简要示例图

因此,本文采用以下已被证明最有效的最低置信度方法作为效用函数[24],如式(5)所示。
(5)
(6)
再通过Viterbi算法[26]得到最可能的标注序列。
(7)
4 实验结果
4.1 实验数据及预处理
本文实验语料来自山西大学CFN语料库,实验数据涵盖152个框架,14 829条句子,每个句子均经过人工标注,全部来源于《人民日报》。所用语料的具体统计信息如表2所示。
在进行实验之前,需要对语料进行预处理:
(1) 获取词性信息,本文采用哈尔滨工业大学LTP平台获取词性信息。
(2) 获取标注例句中的标注信息,本文采用与文献[7]中相类似的BIOSE一步策略,标注格式为{B-X,I-X,O,S-X,E-X},B-X代表框架元素标记块的开始,I-X代表框架元素标记块的内部,E-X代表框架元素标记块的结束,S-X代表单独一个框架元素标记块,O表示不属于框架元素。
4.2 实验设置
本实验按框架划分语料,首先将每个框架下所有例句的70%作为训练集,另外30%作为测试集。然后为了进行迭代训练,再将训练集随机均分成十份,每迭代一次后加其中一份到训练集合中为下一次迭代作准备,每次迭代训练好模型都在相同的测试集上测试。
在本实验中,评价指标采用P(Precision)、R(Recall)、F值。
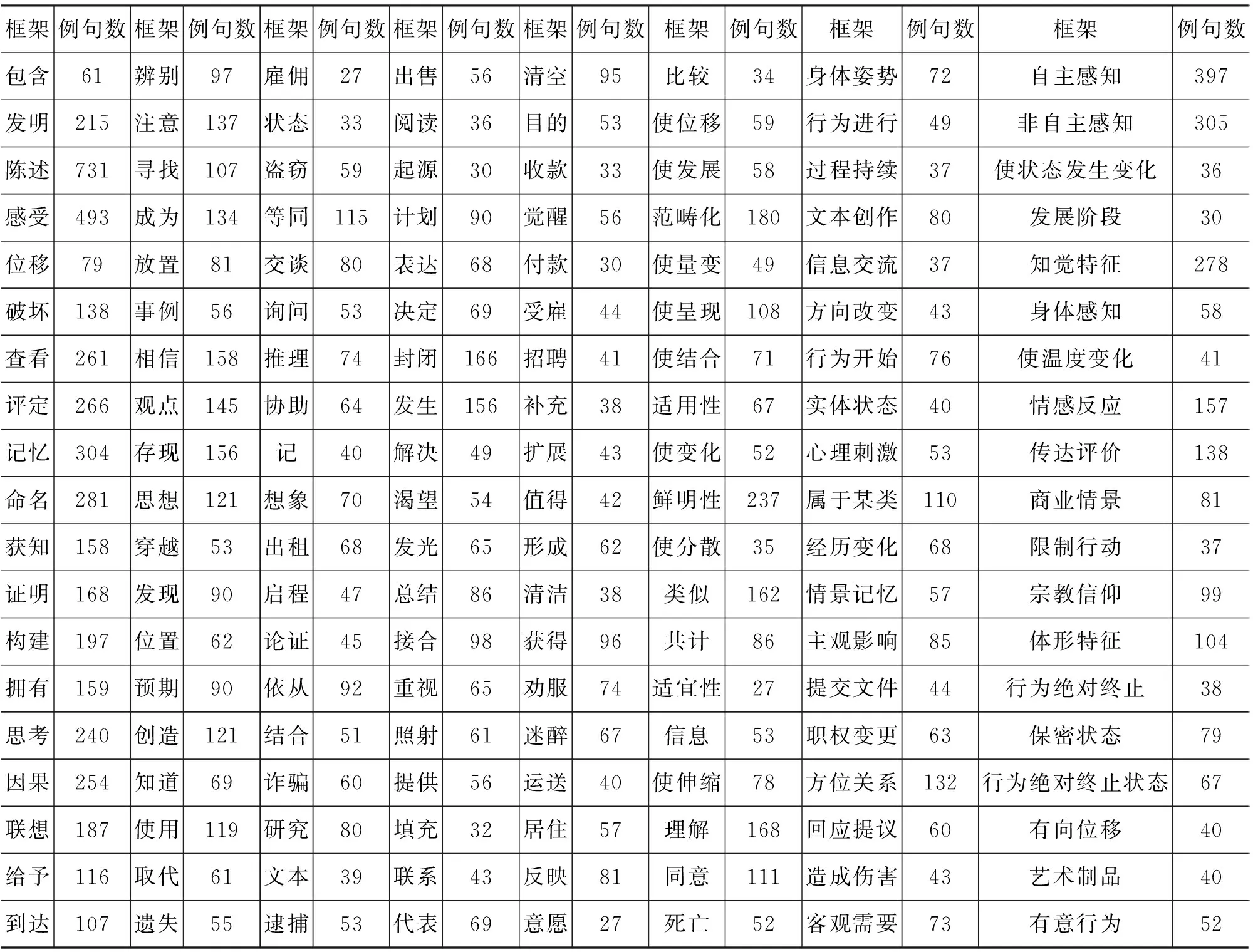
表2 框架例句数统计信息
4.3 实验结果与分析
本文对152个框架分别训练模型并测试得到结果,表3及附录中列出部分结果用来分析主动学习的效果。
首先从单个框架下的结果进行分析,从表3中可以看出,基于主动学习的方法在“非自主感知”框架和“命名”框架上的十次迭代过程中大都取得了比随机抽样更好的效果。一方面,在使用相同数量的训练样本时,主动学习能使框架元素标注取得更好的效果: “命名”框架第四次迭代结束时,主动学习比随机抽样提高了4.83个百分点(这也是该框架下两者相差最大的一次)。另一方面,主动学习使框架元素标注取得同样的性能只需人工标注更少量的训练语料。被动学习在“非自主感知”和“命名”框架下第十次迭代时,结果分别达到了51.80%和64.82%的F值,而主动学习在第七次就达到同样的性能,从而减少了近30%的人工标注量。
图3以“非自主感知”框架为例,详细分析主动学习如何通过样本选择来影响框架元素标注的性能。图3中主动学习在第二次迭代和第五次迭代曲线明显变缓,此时迭代选中的样本属于整个样本中的离散点,因而对训练模型的提升影响非常小。尽管如此, 主动学习的方法依然在第七次迭代时结果就达到了和被动学习第十次迭代相同的结果,从而降低了30%的人工标注量。

表3 “非自主感知”和“命名”框架10次迭代的详细结果表
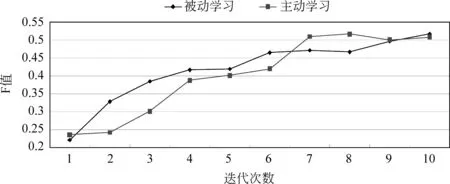
图3 非自主感知框架10次迭代结果图
接下来为了对152个框架的全部结果进行分析,将152个框架在主动学习和被动学习的十次迭代中F值的平均值绘制成如图4所示的折线图。图4可以看出主动学习选取的训练语料比随机选取的语料对训练模型的性能提升的更快。在迭代初期,由于语料较少,数据对结果的影响比较显著,所以主动学习和随机抽样的结果增长都较快,但主动学习的结果在前五次的迭代过程中都比被动学习的要高。由此可见,在相同数量的训练语料下,主动学
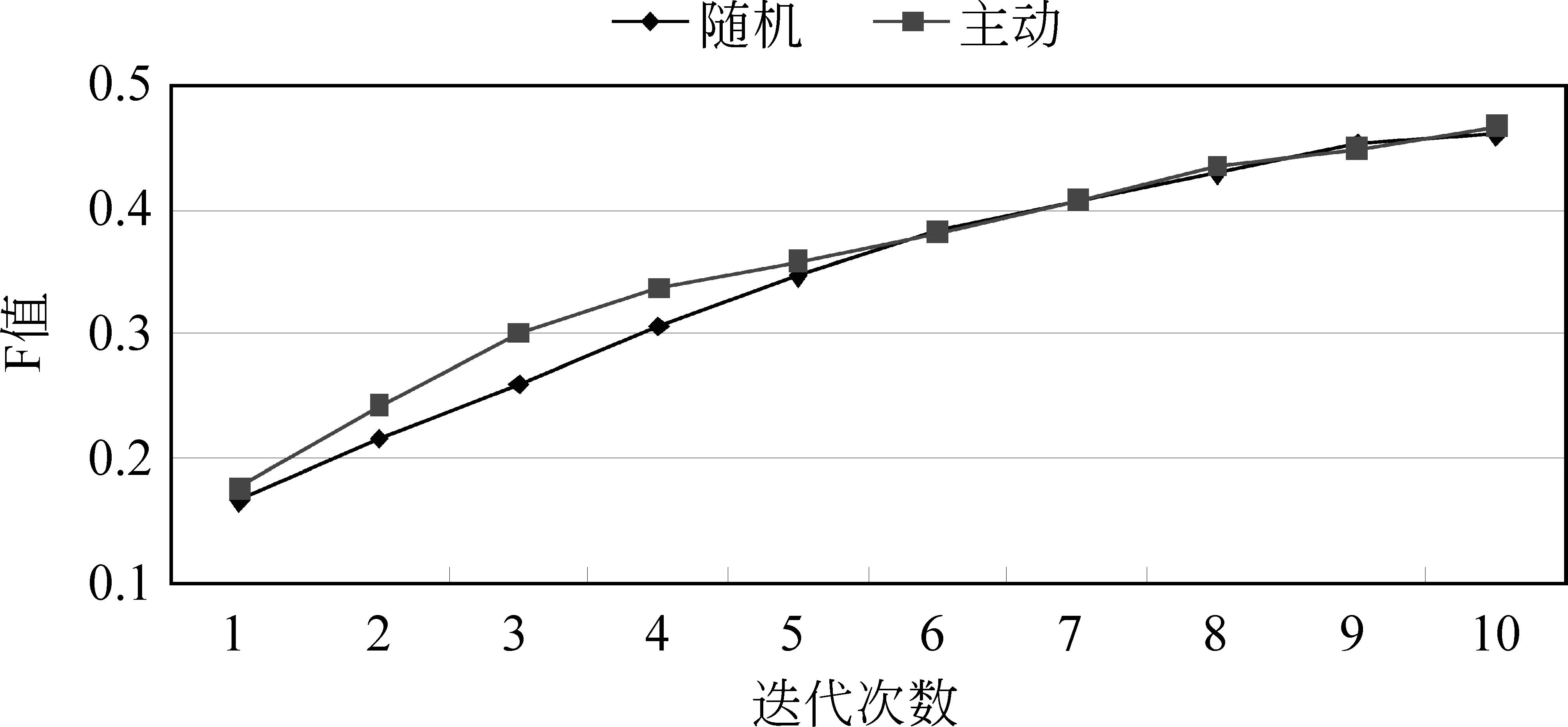
图4 152个框架F值均值结果图
习比随机抽样的结果更高,在第三次迭代时达到最大,相差4.83个百分点。从第六次迭代开始,主动学习和随机抽样的曲线趋于一致,经分析是因为主动学习在迭代后期时未加入到训练集中的标注数据中对提升性能较高的样本数有所降低,导致主动学习和被动学习的学习曲线趋于一致。这也是多数框架下例句较为稀疏导致的,从表2中的数据统计信息便可看出。
上述结果显然是不理想的,因为主动学习方法在总体最终结果上并没有明显优于随机抽样,更没有减少人工标注量。但原因也是显而易见的,即每个框架下例句数的规模相对较小严重影响了主动学习方法的性能。作为反例来验证上述假设,选择十个例句数在100~300之间的框架,将其十次迭代结果的F值绘制成折线图如图5所示。从图5中可以看出,主动学习比被动学习更快的收敛,另一方面,通过图4和图5之间的对比可见数据稀疏问题仍然严重制约着框架元素标注的性能。
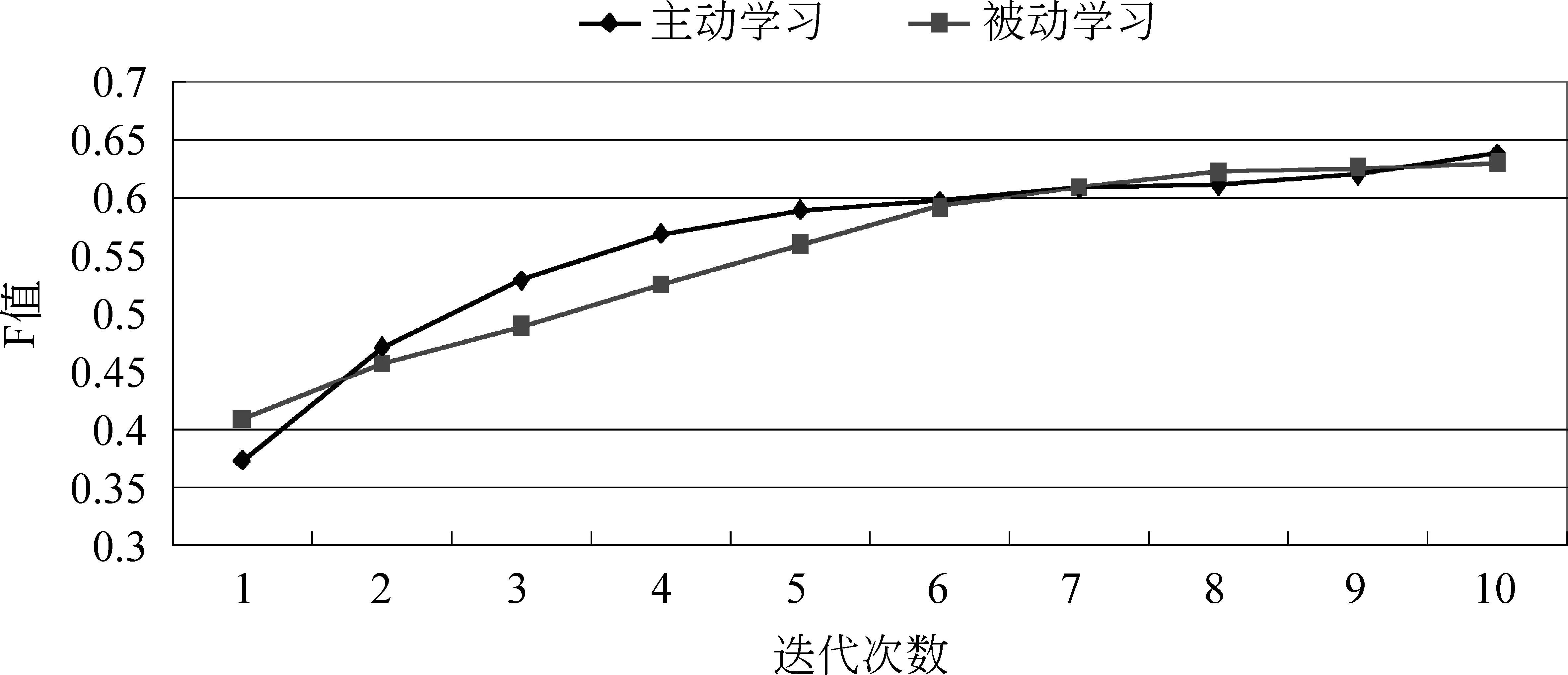
图5 含有一定例句数的框架结果图
接下来从数据与结果的关系的角度进行分析,结合实验所用框架下例句数量的信息和实验结果(这里以主动学习的结果为例),可以得出图5的框架例句数量与框架元素标注结果的相关关系图。
图6下方曲线的极值点代表第一次迭代时(即训练集为 全部训练样本的十分之一)对应框架的F值,上方折线的极值点代表第十次迭代后(训练集包
含全部训练样本)对应框架的F值。为了方便显示,框架名称用数字代替。从图6可以看出数据对目前框架元素标注有关键影响,一方面当前中文FrameNet的数据相比PropBank、FrameNet仍较小,一方面数据对结果增长的影响仍是线性的。所以将主动学习应用于中文FrameNet的例句库构建上,可以从数据的角度快速提高框架元素标注的性能。

图6 框架例句数量与框架元素标注效果的相关关系图

图7 含有一定例句数的框架结果图
为了进一步分析数据与框架元素标注性能的关系以及应用主动学习的意义,这里将框架例句数对训练模型的影响以图示体现出来,将每个框架例句数取以1 000为底的对数,从而得到图7中的上方曲线。可以看出框架例句数和其结果成正相关关系,而且曲线振幅较大,说明各个框架下例句数相差较多,这是被动学习的方式所必然的结果,一方面产生过多的冗余数据,耗费了人力标注,一方面又导致一些框架例句过少,降低了框架元素标注的性能。
通过对主动学习结果和被动学习的对比,可以看出应用了主动学习的框架元素标注能有效解决上述问题。
5 结论及下一步工作
本文提出一种基于主动学习的框架元素标注方法。该方法从大规模未标注语料中选取不确定性最大,也即当前标注模型预测可信度最低的句子交由人工标注,随后将其加入训练集进行迭代训练,直到满足停止准则。其中,主动学习使用了不确定性度量的方法来进行样本选择。实验证明,在训练集数量相同时,主动学习使框架元素标注最高提升4.83个百分点;另一方面,主动学习使框架元素标注在较少的样本下便可达到和被动学习相同的F值,人工标注量最多可减少30%,有效降低了框架元素标注中数据标注的人力成本。同时,基于本文主动学习方法的汉语框架例句辅助标注系统以及框架元素自动标注系统,已发布在互联网上,并已经应用到中文FrameNet语料库的构建中。
下一步工作主要是继续探索减少框架元素标注中数据稀疏问题的有效方法,一方面从训练语料的多样性出发,先聚类然后从簇中抽样标注,减少因数据中的离散点而导致的标注性能降低;另一方面从特征的角度,基于Word Embedding进行词聚类,减少因数据稀疏导致的模型特征稀疏,从而提高框架元素标注的性能。
[1] Palmer M,Gildea D, Kingsbury P. The proposition bank: An annotated corpus of semantic roles[J]. Computational linguistics, 2005, 31(1): 71-106.
[2] Baker C F, Fillmore C J, Lowe J B. The berkeley framenet project[C]//Proceedings of the 17th international conference on Computational linguistics-Volume 1. Association for Computational Linguistics, 1998: 86-90.
[3] Pradhan S, Hacioglu K, Krugler V, et al. Support vector learning for semantic argument classification[J]. Machine Learning, 2005, 60(1-3): 11-39.
[4] Cohn T, Blunsom P. Semantic role labelling with tree conditional random fields[C]//Proceedings of the Ninth Conference on Computational Natural Language Learning. Association for Computational Linguistics, 2005: 169-172.
[5] 刘挺, 车万翔, 李生. 基于最大熵分类器的语义角色标注[J]. 软件学报,2007,(03): 565-573.
[6] Gildea D, Jurafsky D. Automatic labeling of semantic roles[J]. Computational linguistics, 2002, 28(3): 245-288.
[7] 李济洪, 王瑞波, 王蔚林, 李国臣. 汉语框架语义角色的自动标注[J]. 软件学报,2010,(04): 597-611.
[8] Tang M,Luo X, Roukos S. Active learning for statistical natural language parsing[C]//Proceedings of the 40th Annual Meeting on Association for Computational Linguistics. Association for Computational Linguistics, 2002: 120-127.
[9] Olsson F. A literature survey of active machine learning in the context of natural language processing[J]. Swedish Institute of Computer Science,2009: 1-55.
[10] Muslea I, Minton S, Knoblock C A. Active learning with multiple views[J]. Journal of Artificial Intelligence Research, 2006: 203-233.
[11] McCallumzy A K, Nigamy K. Employing EM and pool-based active learning for text classification[C]//Proceedings of the Fifteenth International Conference, ICML. 1998.
[12] Engelson S P, Dagan I. Minimizing manual annotation cost in supervised training from corpora[C]//Proceedings of the 34th annual meeting on Association for Computational Linguistics. Association for Computational Linguistics, 1996: 319-326.
[13] Lewis D D, Catlett J. Heterogeneous uncertainty sampling for supervised learning[C]//Proceedings of the eleventh international conference on machine learning. 1994: 148-156.
[14] Thompson C A, Califf M E, Mooney R J. Active learning for natural language parsing and information extraction[C]//Proceedings of the ICML. 1999: 406-414.
[15] McCallum A, Nigam K. A comparison of event models for naive bayes text classification[C]//Proceedings of the AAAI-98 workshop on learning for text categorization. 1998, 752: 41-48.
[16] Hwa R. Sample selection for statistical parsing[J]. Computational linguistics, 2004, 30(3): 253-276.
[17] Ngai G, Yarowsky D. Rule writing or annotation: Cost-efficient resource usage for base noun phrase chunking[C]//Proceedings of the 38th Annual Meeting on Association for Computational Linguistics. Association for Computational Linguistics, 2000: 117-125.
[18] Tomanek K, Wermter J, Hahn U. An Approach to Text Corpus Construction which Cuts Annotation Costs and Maintains Reusability of Annotated Data[C]//Proceedings of the EMNLP-CoNLL. 2007: 486-495.
[19] Settles B, Craven M,Friedland L. Active learning with real annotation costs[C]//Proceedings of the NIPS workshop on cost-sensitive learning. 2008: 1-10.
[20] 覃刚力, 黄科, 杨家本. 基于主动学习的文档分类[J]. 计算机科学,2003,(10):45-48.
[21] 宋鑫颖, 周志逵. 一种基于SVM的主动学习文本分类方法[J]. 计算机科学,2006, 33(11):288-290.
[22] 居胜峰, 王中卿, 李寿山, 等. 情感分类中不同主动学习策略比较研究[J]. 中国计算语言学研究前沿进展 (2009-2011), 2011:506-511.
[23] 冯冲, 陈肇雄, 黄河燕. 采用主动学习策略的组织机构名识别[J]. 小型微型计算机系统, 2006, 27(4): 710-714.
[24] 车万翔, 张梅山, 刘挺. 基于主动学习的中文依存句法分析[J]. 中文信息学报, 2012, 26(2): 18-22.
[25] Lafferty J D, Mccallum A, Pereira F C N. Conditional Random Fields: Probabilistic Models For Segmenting And Labeling Sequence Data[C]//Proceedings of the Eighteenth International Conference on Machine Learning(ICML). 2001:282-289.
[26] Rabiner L. A tutorial on hidden Markov models and selected applications in speech recognition[J]. Proceedings of the IEEE, 1989, 77(2): 257-286.
[27] 王智强, 李茹, 阴志洲等. 基于依存特征的汉语框架语义角色自动标注[J]. 中文信息学报, 2013,27(2): 34-40.
[28] Settles B, Craven M. An analysis of active learning strategies for sequence labeling tasks[C]//Proceedings of the Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 2008: 1070-1079.
Active Learning for Frame Element Labeling
TU Hanfei1,LI Ru1,2,WANG Zhiqiang1,ZHOU Tiefeng1
(1. School of Computer & Information Technology,Shanxi University,Taiyuan,Shanxi 030006,China;2. Key Laboratory of Ministry of Education for Computation Intelligence & Chinese Information Processing,Taiyuan,Shanxi 030006,China)
The frame element labeling still mainly adopts supervised machine learning methods, which rely on examples of large-scale artificial marked as the training corpus, in order to reduce the cost of manual annotation, this paper presentan active learning aproach, which selects the most uncertain samples for annotation instead of the whole training corpus. Experimental results show that the frame elements labeling F values rise about 4.83 percent by active learning when using the same amount of training samples. In other words, for about the same labeling performance, we only need annotate 70% of the samples as compared to the usual random selection method.
active learning; role labeling; CRFs; measure of uncertainty
附录

框架12345678910发明主动随机P68.2976.4782.1681.3579.1283.0280.8085.6583.7677.19R16.8326.0530.4631.4628.8635.2736.2735.8739.2840.68F27.0138.8644.4445.3842.2949.5150.0750.5653.4853.28P95.7095.2988.3385.7184.3285.1983.6681.0879.5777.38R17.8416.2321.2427.6631.2632.2633.8736.0736.6739.08F30.0727.7434.2541.8245.6146.8048.2249.9350.2151.93自主感知主动随机P87.3286.5985.7178.9279.8984.2483.6783.5783.9877.78R16.6030.2532.1339.0939.3641.5039.0938.8237.8844.04F27.9044.8446.7452.2852.7455.6153.2853.0252.2156.24P84.6785.0682.9481.0478.4381.7980.2277.7579.4078.71R17.0019.8123.4329.1832.1335.4838.5540.7042.8442.57F28.3232.1436.5342.9145.5849.4952.0853.4355.6555.26感受主动随机P88.2786.6483.2785.6187.1283.1185.9083.0783.8582.21R38.6349.1454.7759.6662.8461.3765.5364.7966.0165.53F53.7462.7166.0870.3273.0170.6074.3472.8073.8772.93P83.8483.6382.6880.9580.4981.3180.7181.1782.1082.10R40.5946.2151.3454.0356.4860.6461.3764.3065.0465.04F54.7059.5363.3564.8166.3869.4769.7271.7672.5872.58查看主动随机P95.5992.8688.0480.1777.2773.5373.1872.6874.3875.48R11.3613.6414.1616.9617.8321.8522.9023.2526.4027.45F20.3123.7824.4027.9928.9833.6934.8935.2338.9740.26P78.9586.2588.3084.7684.2176.7777.9777.4274.5074.27R7.8712.0614.5115.5616.7820.8024.1325.1726.0526.75F14.3121.1724.9226.2927.9932.7436.8537.9938.6039.33
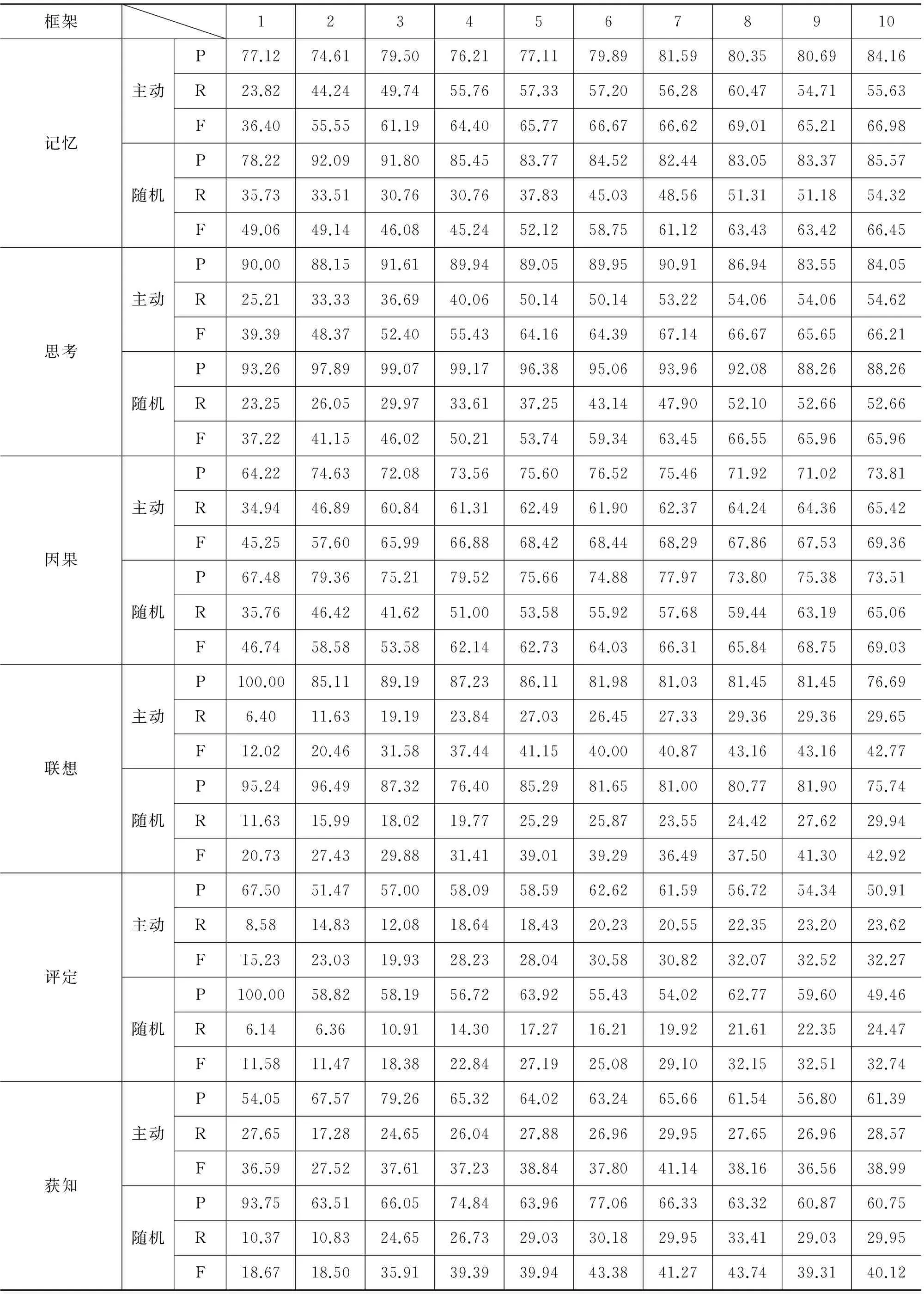
续表

续表

屠寒非(1990—),硕士研究生,主要研究领域为中文信息处理。E-mail:330958032@qq.com李茹(1963—),通信作者,博士,教授,主要研究领域为自然语言处理、信息检索。E-mail:liru@sxu.edu.cn王智强(1987—),博士研究生,主要研究领域为中文信息处理、社会媒体数据挖掘。E-mail:zhiq.wang@163.com
1003-0077(2016)04-0044-12
2015-08-09 定稿日期: 2016-03-06
国家自然科学基金(61373082);山西省科技基础条件平台建设项目(2014091004-0103);山西省回国留学人员科研资助项目(2013-015);国家863计划项目(2015AA015407);中国民航大学信息安全测评中心开放课题基金(CAAC-ISECCA-201402)
TP391
A
猜你喜欢
开放教育研究(2020年2期)2020-03-31 01:54:14
少年博览·初中版(2018年12期)2018-01-18 09:17:58
海外华文教育(2016年1期)2017-01-20 08:21:58
小天使·一年级语数英综合(2016年4期)2016-11-19 10:22:17
现代语文(2016年21期)2016-05-25 13:13:44
小天使·一年级语数英综合(2016年6期)2016-05-14 12:21:05
当代教育理论与实践(2015年9期)2015-12-16 16:26:05
小天使·一年级语数英综合(2015年10期)2015-10-14 06:30:06
大连民族大学学报(2015年2期)2015-02-27 08:28:11
民族古籍研究(2014年0期)2014-10-27 08:24:34
