
基于测井资料的产能预测
2016-04-28 08:30刘晓军寇苗苗项文钦王历历张秀峰中国石油长庆油田分公司第五采气厂陕西西安7008中国石油长庆油田分公司第一采气厂陕西西安7008中国石油长庆油田分公司第三采气厂陕西西安7008
石油化工应用 2016年3期
李 媛,刘晓军,李 赟,孙 扬,岳 璐,寇苗苗,项文钦,王历历,张秀峰(.中国石油长庆油田分公司第五采气厂,陕西西安 7008;.中国石油长庆油田分公司第一采气厂,陕西西安 7008;.中国石油长庆油田分公司第三采气厂,陕西西安 7008)
基于测井资料的产能预测
李媛1,刘晓军1,李赟2,孙扬3,岳璐1,寇苗苗1,项文钦1,王历历3,张秀峰1
(1.中国石油长庆油田分公司第五采气厂,陕西西安710018;2.中国石油长庆油田分公司第一采气厂,陕西西安710018;3.中国石油长庆油田分公司第三采气厂,陕西西安710018)
摘要:产能预测目前仍处于不完善高风险的阶段,尤其是针对苏里格气田这种低孔隙度、低渗透率、低丰度的三低气藏,而利用测井静态资料预测储层产能,则可以较大程度上优化射孔层段选择,提高射孔效率,预测产能指导合理配产。针对SW区块目前处于评价建产阶段的特点,通过对试气试采资料的分析,基于静态的测井资料对储层的产能进行了预测,选取储能系数、渗流系数作为参数,对数据通过ward法聚为五类,然后用Fisher判别分析法进行回判,最终回判正确率达到94.4 %,在此分类基础上建立了每类的产能预测函数,结果表明基于测井的静态资料在对产能预测方面也可以取得良好的效果,而相对于考虑很多动态的信息指标,为储层的产能预测提供了一种新的思路。
关键词:测井资料;产能预测;Fisher判别
产能是油气储层动态特征的一个综合指标,是油气储层生产潜力和各种影响因素之间在相互制约过程中的一种动态平衡。而在利用测井资料预测产能时有一定的难度,测井资料是一种静态资料,而产能呈现的是一个动态结果。如果不考虑其他因素或者条件近似的情况下,将储层的自身特征认为是对储层的产能起高低作用的决定因素,可以尝试利用测井资料对其进行预测。
现阶段油气储层的产能评价还是通过试油、试采数据或油藏数值模拟等手段来解决,对于产能预测的工作还没有一套成熟的方法。谭成仟等[1]则从平面径向流产量理论公式出发,通过相对渗透率与含水饱和度的复杂函数关系的分析以及阿尔奇公式,建立了储层油气产能与储层渗透率、孔隙度和电阻率之间的统计关系,采用神经网络技术对其产能进行了预测[2]。
SW区块位于苏里格气田西区北部,主要含气目的层位为古生界二叠系石盒子8段和山西组1段,有效储层主要为岩屑质石英砂岩和岩屑砂岩,储集类型为孔隙型储层,以岩屑溶孔和粒间溶孔为主。利用试气成果数据及测井解释参数,尝试采用SPSS软件判别分析模块中的Fisher判别函数法对研究区内的产能进行了预测分类,建立分类预测函数,取得了良好效果。
1 Fisher判别方法的原理
判别分析是一种常用的统计分析方法[3],是在已知观测对象的分类结果和若干表明观测对象特征变量值的情况下,建立一定的辨别准则,使得利用判别准则对新的观测对象的类别进行判断时,出错概率最低。
SPSS对于分为m类的研究对象,建立m个线性判别函数,当对于每个个体进行判别时,把测试的各个变量值代入判别函数,得到判别分数,从而确定个体属于哪一类。
Fisher判别法为SPSS中的一种判别分类方法,其基本思想就是为了克服高维数造成的复杂运算,而将高维数据点投影到低维空间(如一维直线)上,找到某个最好的方向,使样本投影到这个方向的直线上后,既可以最大限度地缩小同类各样本点之间的差异,又可以最大限度地扩大不同类别样本点之间的差异,从而对数据点进行区分。
(1)各类在d维特征空间里的样本均值向量:
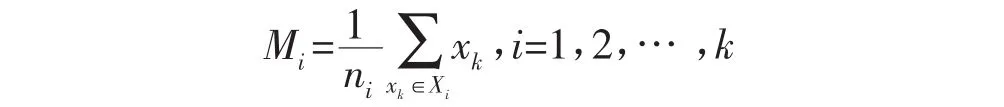
(2)通过变换w映射到一维特征空间后,各类的平均值为:

(3)映射后,各类样本“类内离散度”定义为:
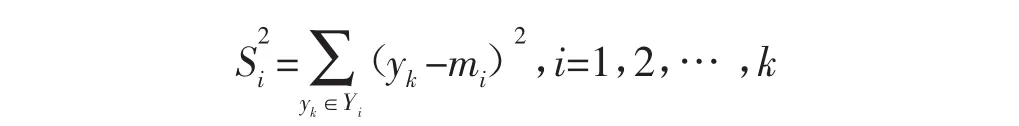
显然,在映射之后,两类的平均值之间的距离越大越好,而各类的样本类内离散度越小越好。因此,定义Fisher准则函数:
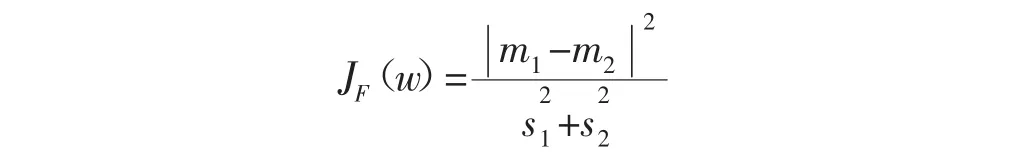
使函数值最大的解就是最佳解向量,也就是Fisher的线性判别式。
2 产能预测函数参数的选取
在油气田开采的过程中,产能一般利用平面径向流渗流模型来进行表述[4],但是由于公式中的流动压力、生产半径及流体黏度等数据在测试之前无法确定,单靠测井资料仅可以得出其静态解释的有效厚度、渗透率、孔隙度、含气饱和度等数据。经过对测井数据的分析,最终采用了储能系数Ch、渗流系数S与存储系数C作为建立产能预测函数中的参数。在建立Fisher判别函数时,选取了其中能反映储层中含气量与渗流好坏的储能系数、渗流系数作为判别函数中的参数。
3 分类判别函数的建立
建立分类判别函数时,采用48口井的125个试采层段无阻流量的数据,使用储能系数、渗流系数两个参数通过ward法聚类,分为五类,然后建立Fisher判别函数[5,6]。将分成的五类数据点分别标记为1、2、3、4、5,同时将储能系数、渗流系数两个参数录入到SPSS软件中,利用其中的判别分析模块,最终得到(见表1)。
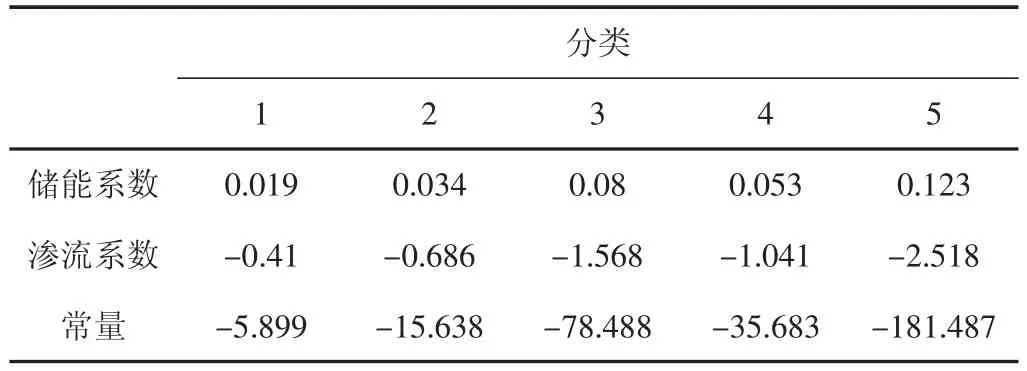
表1 分类函数系数表
由表1分别得到五类的Fisher线性判别函数:
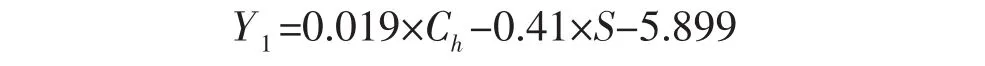
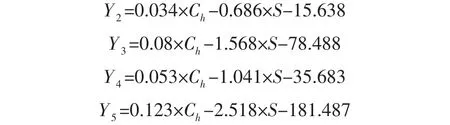
将未知分类的样品点数据代入上述五个判别函数中,得出五个函数值,比较这五个函数值的大小,哪个函数值大就可以判断该组数据属于哪一类别。
4 分类产能预测函数的建立
根据图1可以看出,各类散点在平面图上的分布具有一定的区域性,利用Fisher判别法可以较好的将数据点进行正确区分;从表2中可以看出,其中一类正判率达到91.7 %,二类正判率达到100 %,三类正判率为100 %,四类正判率88.1 %,五类正判率100 %,所有样品点的整体正判率达到了94.4 %。在该分类基础上,利用多元回归分析建立每种类别的产能预测函数。
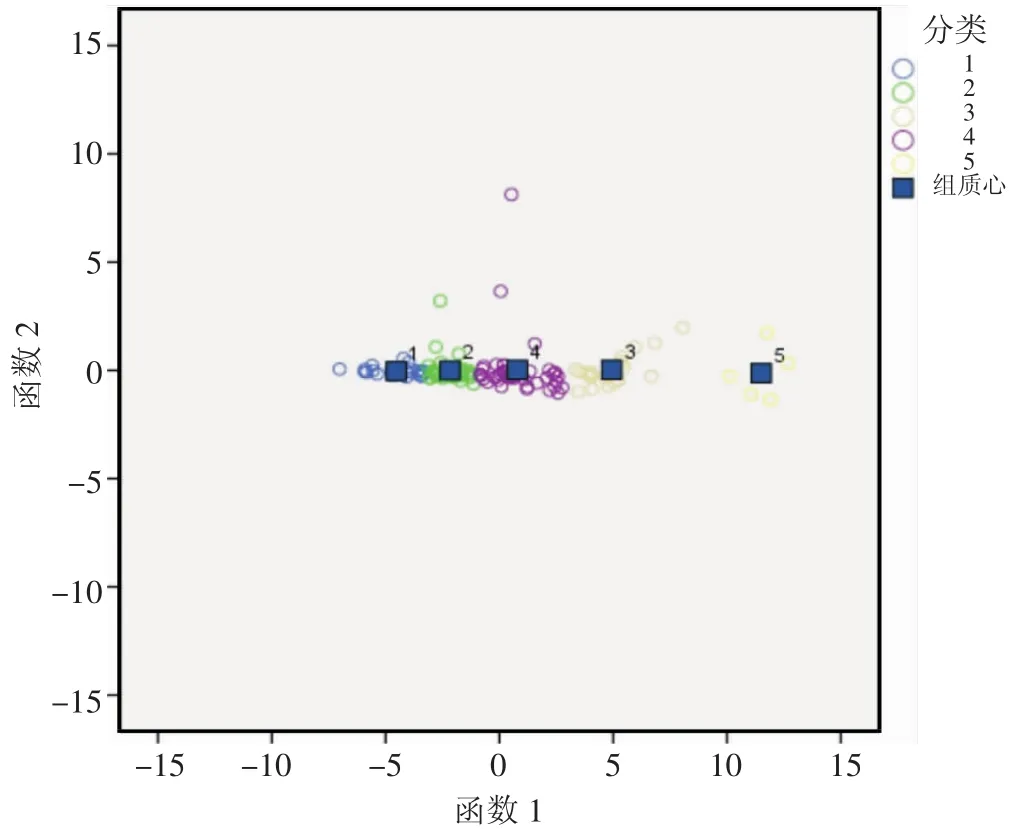
图1 样品散点分布图
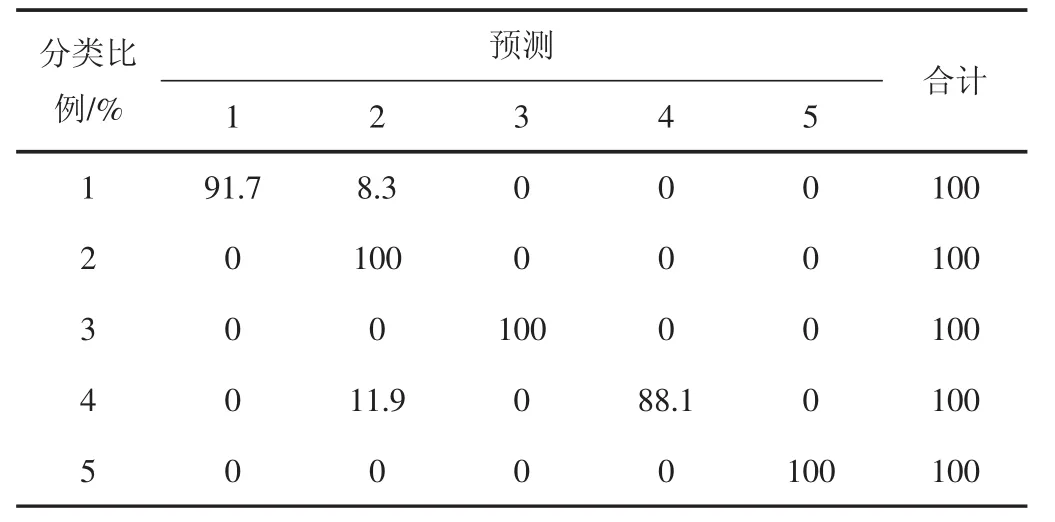
表2 预测结果及正判率
一类:QAOF=0.003×C+1.397×S-0.154,R=0.855
二类:QAOF=0.266×C+1.9×S-2.774,R=0.784
三类:QAOF=-0.121×C+3.697×S+1.492,R=0.815
四类:QAOF=0.143×C+1.484×S-0.18,R=0.824
五类:QAOF=7.294 1×S-11,R=0.954
以二类产能预测函数为例说明分类别的产能预测函数的建立。在判别分类的基础上,在判为二类的样品点中分别做试气无阻流量与存储系数、渗流系数、储能系数的相关性分析(见图2~图4)。
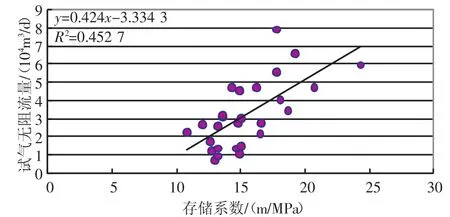
图2 存储系数与试气无阻流量相关分析图
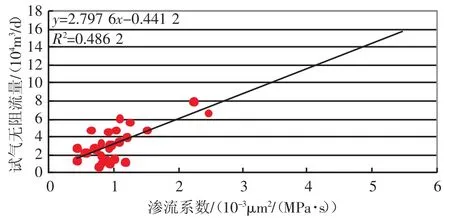
图3 渗流系数与试气无阻流量相关分析图
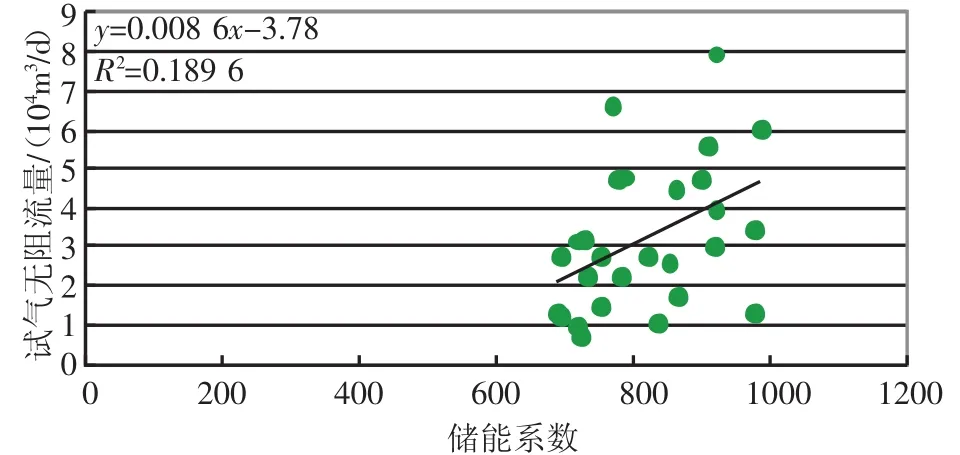
图4 储能系数与试气无阻流量相关分析图
其中存储系数与试气无阻流量的相关系数R达到了0.64,渗流系数与试气无阻流量的相关系数R达到了0.69,而储能系数与试气无阻流量的相关系数只有0.27,存储系数与渗流系数可以较好的反映试气无阻流量大小,因此选择存储系数与渗流系数作为多元回归分析的自变量与试气无阻流量进行回归分析,得到二类QAOF=0.266×C+1.9×S-2.774的预测函数,其相关系数达到了0.784,较之前单变量的相关性有了提高,可以对试气无阻流量进行预测。
5 应用效果及误差分析
利用前文中求得的分类判别函数与分类产能预测函数,对各井射孔层段进行了产能预测,取得了较好的效果。具体操作步骤如下:如苏R井山1段射孔层段有效厚度为4.3 m,平均孔隙度为6.5 %,平均渗透率为0.403×10-3μm2,含气饱和度为69.2 %。
(1)分别计算其储能系数Ch=1 934.14,存储系数C=27.95,渗流系数S=1.732 9。
(2)将储能系数与渗流系数值分别代入五类Fisher判别函数中。求得Y1=36.038,Y2=48.934,Y3=73.526,Y4=65.022,Y5=52.049,其中Y3函数值最大,判断此段砂体为三类。
(3)将存储系数、渗流系数代入三类的产能预测函数QAOF=-0.121×C+3.697×S+1.492中,求得预测无阻流量为4.52×104m3/d。
对单井的各射孔层段进行了产能预测,其中苏R井中,山1段钻遇砂岩厚度19.5 m,有效厚度4.3 m,视电阻率76.47 Ω·m,声波时差218.96 μs/m,平均孔隙度6.5%,平均渗透率0.403×10-3μm2,含气饱和度69.2%;山2段钻遇砂岩厚度8.7 m,有效厚度2.2 m,视电阻率55.17 Ω·m,声波时差226.01 μs/m,平均孔隙度6.8%,平均渗透率0.232×10-3μm2,含气饱和度48.8%。两段试气无阻流量7.319 9×104m3/d,经计算预测无阻流量6.71×104m3/d,误差较小,效果良好。
但由于预测函数的建立是基于测井解释成果之上,因此受测井解释参数影响也较大。如苏R井,两层段试气无阻流量为2.942×104m3/d,经计算预测无阻流量为11.9×104m3/d,误差较大。
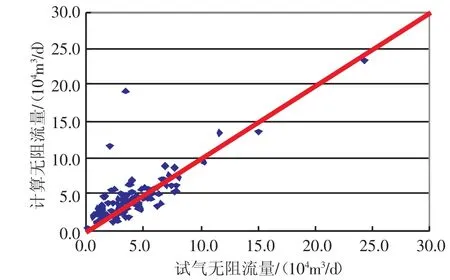
图5 试气无阻流量与计算无阻流量误差分析
对各井的预测无阻流量与试气无阻流量进行了误差分析(见图5)。平均绝对误差为1.54×104m3/d,主要取决于各类的预测函数相关性大小,平均相对误差变化范围较大,受实际试气无阻流量大小影响。
实际应用中,可以对射孔层段进行优选,选择出潜力较大的层段进行射孔(见表3),射孔层段选择在了具有较高预测产能的层段。同时还可以对未试气的井进行产能预测,指导合理配产,结合静态分类指标与无阻流量合理指导配产。经过对射孔层段的产能预测,计算出其无阻流量(见表4)。
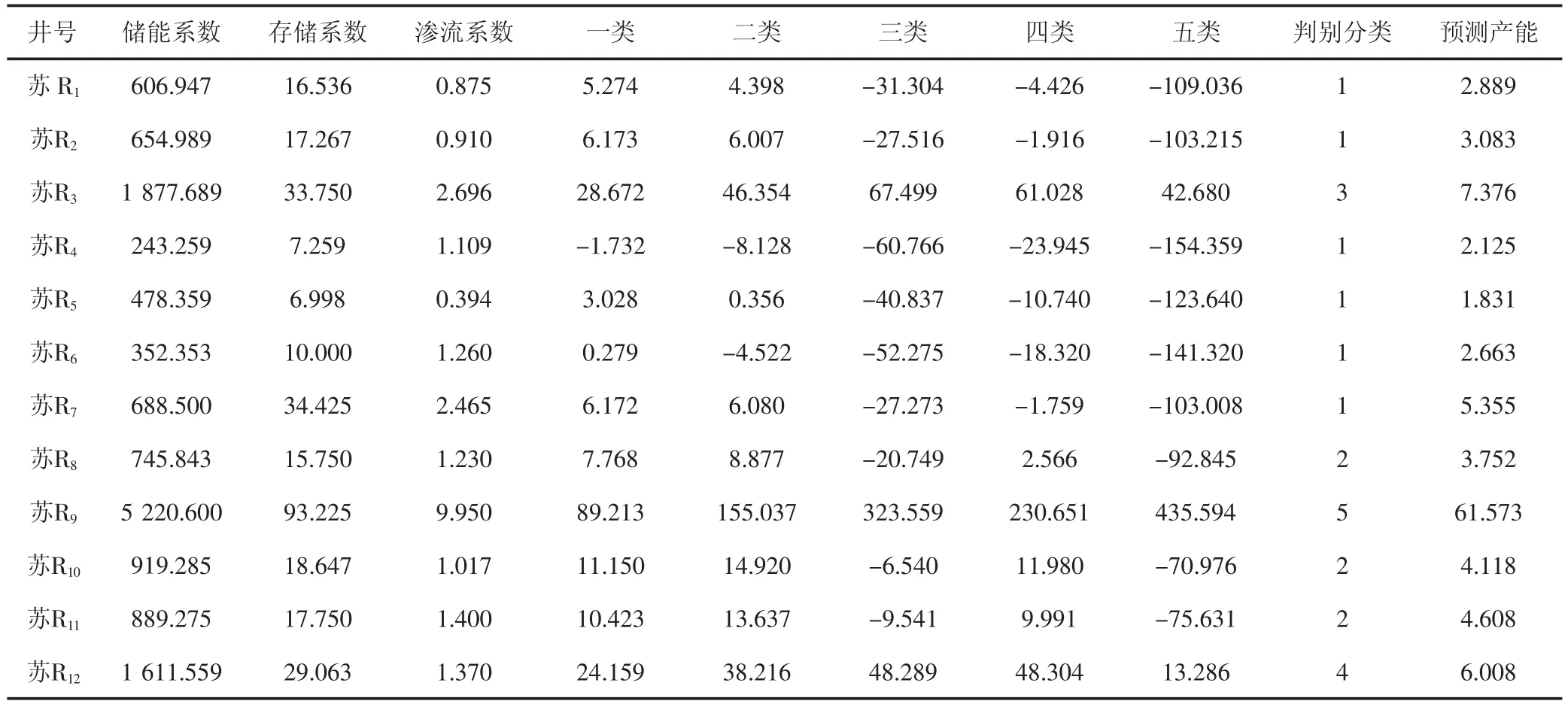
表3 示例优选射孔层段参数表

表4 示例指导合理配产参数表
6 结论
本文在测井解释资料的基础上,合理选取了储能系数、渗流系数,聚类后利用Fisher判别法对样品进行了回判,给出了五类判别函数,同时建立了每个类别中的无阻流量预测函数,主要取得以下几点认识:
(1)基于测井资料,利用Fisher判别法对SW区块的产能进行分类预测,效果良好。选取判别参数时,要优选出对研究区影响最大的参数,以便最终的判别公式具有较高的正判率。
(2)在Fisher判别分类函数的基础上,回归得到的预测函数可以较好的预测产能,可以对未进行射孔的井段进行分析,以提高射孔效率;同时可以对未进行试气的井进行产能预测,以便于合理配产。
(3)预测函数的建立主要受测井解释成果的精确度与现场试气无阻流量的影响。
(4)用该方法计算直井I+II类井比例为81.5 %,直井已建产能2.4×108m3/a,预测钻/建直井238口,可建产能10.5×108m3/a。
参考文献:
[1]谭成仟,马娜蕊,苏超,等.储层油气产能的预测模型和方法[J].地球科学与环境学报,2004,26(2):42-45.
[2]赵军,侯克均,蒋智格,等.低孔低渗透储层产能预测新方法[J].油气地质与采收率,2009,16(1):72-74.
[3]熊琦华,陈亮,聂昌谋,等.地质统计学在储层表征中的应用[J].断块油气田,1997,(4):21-28.
[4]毛志强,李进福.油气层产能预测方法及模型[J].石油学报,2009,21(5):58-61.
[5]赵丽娜.Fisher判别法的研究及应用[D].哈尔滨:东北林业大学,2013.
[6]陈希镇,曹慧珍.判别分析和SPSS的使用[J].科学技术与工程,2008,(13):3567-3571.
*收稿日期:2016-02-02
DOI:10.3969/j.issn.1673-5285.2016.03.009
中图分类号:TE328
文献标识码:A
文章编号:1673-5285(2016)03-0033-04
