约束聚类下的B2C电商物流网络区域聚合
2016-04-22 07:01高宝鑫上海交通大学中美物流研究院上海200030
哈尔滨商业大学学报(自然科学版) 2016年1期
高宝鑫,王 东(上海交通大学 中美物流研究院 上海 200030)
约束聚类下的B2C电商物流网络区域聚合
高宝鑫,王东(上海交通大学 中美物流研究院 上海 200030)
摘要:以城市群理论与引力模型为依托,将城市运输距离与订单量相结合,通过对欧式距离重新定义,以当量距离为约束条件,借助K-中心点聚类算法完成全国物流网络的区域划分,并对划分的结果根据类内差指数进行评估,找出聚类较为合理的方案.以2013年的网购订单量数据对全国86个地级市进行了区域划分,对聚合模型加以验证.
关键词:物流网络优化;B2C电商;区域聚合;K-中心点距离
随着居民消费水平的提升,对质量的关注也越来越成为消费者选择电商的重要参考标准,使得电商之间从“价格战”逐步转向“服务战”.然而“服务战”的竞争归根结底依然是企业占领市场与运营成本间的博弈问题,如何搭建B2C电商全国物流网络,使得在保持高服务标准的前提下,维持较低的运营成本是关系到当前B2C电商企业未来发展的关键性问题.
目前在电商全国物流网络布局方面的研究较少,电商自营物流企业当前的做法,更多的是领导层根据历史同期销售数据以及自身在这个领域摸索的经验进行主观臆断,再根据实际情况作局部的调整.首先这样做缺乏相关理论依据,选址的科学性难以得到保证,局部的合理性很难保证全局网络的最优化,只能暂时解决企业快速扩张所带来的燃眉之急.其次随着企业发展的快速变迁,区域中心的选择是一个动态的过程,每次对于区域配送进行重新规划,势必消耗大量的人力财力.最后由于缺乏对区域数据的量化,看似合理的选址可能带来长期较高的运营费用,由此导致的物流成本高、资源利用率低下、顾客服务周期长以及区域间物流资源分布不均匀问题,对于长期的规划和企业的发展来说非常不利,物流运作的低成本宗旨很难得以体现.
本文以此为契机,以B2C电商自营物流企业为研究方向,运用带约束条件的聚类算法对城市按照多维属性进行聚类从而完成全国物流网络的区域划分,并结合实际数据对该网络进行评估.
1文献综述
1.1城市群理论与引力模型
国内外对城市群理论的研究相对成熟.Megalopolis一词由Jean Gottmann在研究美国东北部沿海地区的城市带时首先提出,旨在对一些不符合通常城市发展的特性做出解释[1].刘智勇[2]对城市群理论的研究历程进行了综述.熊剑平[3]对国外城市群经济与空间之间的联系领域的研究进行了总结.冯垚[4]对城市群理论与都市圈理论进行了对比,指出两种理论的异同点,并强调城市群理论不仅代表了规模经济,更重要的是城市间的交流互动频次增加,使整个区域得到更好的发展.该领域已有大量文献对城市群发展的起源、机制以及对与经济发展之间的影响做了详细的论述,本文对此不一一赘述.
Reilly首次将万有引力定律应用在经济领域中,阐述了两个城市间的零售额与地理距离之间的关系[5].Anderson对于引力模型应用到商品交易市场给出了理论上的解释[6].国内学者将该理论应用到具体城市的区域经济的研究中,徐辉[7]结合经济发展的多项因素,应用引力模型与运筹理论对江西省的11个地区进行经济区域划分.石贤光[8]运用城市经济综合影响因子,以郑州市为中心,划出了该城市群的覆盖范围.吴晓薇[9]在城市区域规划中,对引力模型中的距离参数采用了运输时间参数进行代替,并且考虑了一般道路与高速公路两种情况.
1.2K-means聚类算法
K-means算法最初由Lloyd在解决脉码调制量子化问题时提及[10],该算法在处理大数据集时具有聚类速度快,聚类对象间的相似度高等优势,在数据挖掘领域中被广泛应用.David Arthur[11]在对此基础上提出了K-means++算法,使得算法的时间复杂度从缩短到,同时精确度也得到一定程度的改善.杨善林[12]提出使用距离代价函数来检验聚类的效果,从而对K-means聚类的个数进行有效的评估.谢可[13]在K-means算法的基础上提出距离因素增设了权重,使得在进行聚类时加入其他属性对距离因素的影响成为可能.具体实现相对困难,原因之一是文章仅考虑了如何对节点间权重质心进行迭代,没有很好地给出初始权重的定义以及如何搭建权重与距离间的物理含义.钱小风[14]将有权重的K-means算法应用到邮政网络领域,考虑了影响需求点选址的行驶距离、网点数目等综合因素,目的是实现各地区的运输配载能力尽可能达到均衡.谷炜[15]提出使用K-means算法将大规模车辆路径问题通过一定约束条件进行合理分割,并结合仿真对该方法加以验证.
1.3K-中心点聚类算法
Kaufman在《数据分析》一书中首次提及PAM和CLARA的两种K-中心点聚类算法[16],PAM对K-means的主要改进在于基于实际对象进行聚类,降低对孤立噪声点的敏感性.CLARA通过抽取样本的方式有效地降低了K-中心点算法在处理较大数据量时时间复杂度较高的问题.在此基础上,相关学者对PAM算法的聚类效果不断进行改进.白旭[17]通过对数据集转换成单位度量空间的方式,对数据对象进行聚类前预处理,找到较优的初始中心,提升聚类的效率.张雪萍[18]在传统PAM基础上考虑了障碍约束条件,使得聚类算法能够更好地应用于解决实际问题.
综上所述,作为研究较为成熟的聚类算法,学者们将K-means和K-中心聚类算法应用到多个领域,然而根据实际问题的不同,不同的约束条件以及对聚类簇内对象的相似度衡量不同,对算法指标的要求也不尽相同.而目前缺乏较完备的理论对聚类结果进行分析和评估,也是数据挖掘领域未来需要重点研究开拓的.
2模型综述
2.1模型的目标和优势
K-means算法作为研究中相对成熟的聚类方法之一,在数据挖掘领域中被广泛应用.K-中心点算法作为对K-means算法的改进,很好地处理了噪声点对聚类结果的影响.本文在传统K中心点算法的基础上,重新定义对象间相似性度量的距离因子,不仅考虑各城市的地理位置,将电子商务的综合发展水平一并加入到模型中考虑.
1) 基于相似性度量约束条件的K中心点聚类模型实现的目标
①多维度:实现多维属性的聚类,并且通过归一化或设计相关指标对各维属性之间的关系进行衡量比较.
②导向性:实现聚类的结果之间以距离属性为导向,其他的属性对聚类结果有辅助影响的效果.
③合理性:实现地理因素与各城市电子商务发展水平的对聚类结果的综合影响,即需要重新定义测量对象之间相似度的距离因子,并使得聚成的类具有相当的合理性.
2) 基于约束条件K中心点聚类模型的优势
①综合性:在传统区域选址问题只考虑地理位置属性聚类的基础上增加了电子商务发展水平等综合因素对于城市聚类的影响,与单纯地理属性聚类的方法相比的优势是显著的.
②紧密性:基于聚类理论实现类内差最小和类间差最大的思想,用聚类算法进行物流网络区域的划分能够使得同一个聚类内的对象相似程度高,区域内各对象间关联程度大.城市之间的发展具有联动效应,相似的属性使得企业在考虑仓储、分拣和配送的过程中更容易实现规模效益,因而更加符合电商企业的实际需求.
③鲁棒性:在处理此类问题时,如果对城市间距离施加约束,以经济引力为目标函数建立运筹模型进行求解同样具有上述两点优势.而相比于经济引力模型,K-中心点聚类对噪声点更具有抗扰动性,不需要对噪声点进行预处理,通过较少的约束条件使聚类的结果能够更好地呈现.
2.2基于经济引力模型对聚类距离的定义
城市群理论与经济引力模型相结合,以实现区域内城市间的经济引力最大为目标,使得各城市之间的发展具备更好地协同作用.曾有学者将城市经济引力模型应用于物流网络区域聚合,文章以订单量作为衡量城市间的经济引力因子,交通运输时间作为衡量城市间的距离因子,相应的目标函数如下:
(1)
聚类算法实现的结果是使得聚类后的类内差最小,类间差尽可能的大.我们这里借助订单引力模型的思想,对聚类算法中的欧式距离进行重新定义,运用K-中心点聚类算法加以实现.
设地级市的数据集为X={x1,x2,x3,…,xi,…,xn},其中xi∈Rd,d表示数据的维度,这里考虑d=3,即xi=(αi,βi,γi).αi、βi代表城市i的位置属性,γi代表城市i电子商务发展的综合水平,这里使用网购订单量的概念对其进行描述.相应的公式如(2)所示:
(2)
式(2)通过在聚类算法中增设权重,实现了地理位置因素与电商发展水平间的互相关联.当几个城市之间的距离属性接近时,电商发展水平越高的地方,在该地区设立区域配送中心所产生的集聚效应与规模效应越强,相应的该城市与其他城市间的当量距离就会被弱化,使得空间距离相对减小;同理,电商发展水平低的城市,与其他城市间的当量距离就会被增加.预期效果是使电商发展水平高、城市间距离较近的沿海地区能够聚成若干类,形成规模效应,同时电商发展稍微落后的内陆城市能够覆盖较大的范围,从而对全国电商物流网络实现整体优化布局.
其中参数μ称作衰减因子,来调节电商全国物流网络区域划分时受地区电子商务综合发展水平影响的程度.μ值越大,说明在考虑全国物流网络区域划分时,各地区电商发展水平的“引力性”与主导性越强,相应的城市间距离因素被弱化程度越大;μ越小,说明各地区电商发展水平的主导性越弱,相应的城市间的地理因素占据主导位置;当μ=0时,即是标准的欧式距离公式,等同于现有学者仅考虑距离因素对物流区域进行划分的方法.
2.3带约束条件的K-中心点聚类算法实现
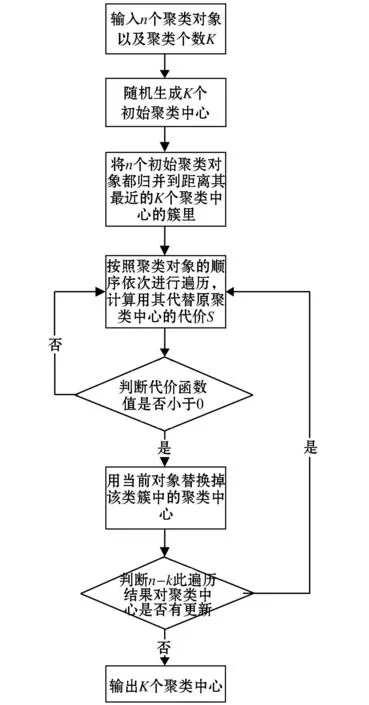
由于K-means算法每次迭代使用的是新类生成的质心,缺乏可操作性和合理性,而K-中心点算法使用实际的对象作为每次迭代的聚类中心,因而这里在对B2C电商全国物流网络进行区域聚合时,通过基于改进的K-中心点算法对全国若干地级市根据相关的实际运输距离、网购订单量等指标进行聚类,完成城市间的聚合与区域划分.具体改进算法如下:
1)给定聚类的数值K,对初始的n个数据对象随机生成k个初始聚类中心:ck(p0)={c1,c2,c3,…,ck},p=0,cj∈R2.
2)对数据集中的每个数据对象xi依次遍历并计算其与初始聚类中心ck(p0)的两两距离,此处对传统K-中心点聚类中的距离参数设置如公式(3)所示,其中Dij代表实际运输距离:
(3)
3)如果满足D′(xi(p0),cj(pi))=min{D′(xi(pi),ck(pi)),j=1,2,3,…,k,k>2},则xi(pi)∈qj(pi).此步的含义为:对数据集中的每个点进行遍历,寻找在当前p0阶段与之距离最近的第j个聚类中心,并将该数据点归入第j类,形成若干聚类集合q1(pi),q2(pi),…,qn(pi).
4)判断如果i=n,则令i=i-n,p=p+1;如果i 5)判断xi是不是聚类中心,如果是,返回步骤(4);如果不是,则继续. 6)依次遍历余下的n-k-i个对象.当遍历到第i个数据对象时(xi∉ck(pi-1),xi∈qj(pi-1)),计算用xi代替cj总的代价函数Sij(pm-1),代价函数的表达形式如公式(4)所示: (4) 如果Sij(pi)<0,说明在pi阶段用xi代替作cj为第j类新的聚类中心对于聚类效果有改善,此时对ck(pi)进行更新,令xi替换掉cj(pi),返回步骤(3); 如果Sij(pi)>0,说明聚类效果没有提升,令ck(pi+1)=ck(pi),判断如果对于任意i 图1 该约束聚类算法的流程图 该算法的时间复杂度为O(k(n-k)2),当n较小时,运算时间可以接受,能够保证聚类结果趋于收敛,聚类效果较好.具体如何评价当K给定时的聚类效果,我们将在2.4节提到. 算法的简要流程图如图1所示. 2.4评估方法 当K取一般正整数时,K-中心点聚类算法为NP困难的,这时候需要通过启发式算法进行求解.通常启发式算法普遍存在容易陷入局部最优的问题,本文在算法改进的基础上使用类间差函数和这一指标对聚类结果进行评估. 聚类算法的思想是实现同类之间的差值最小,类与类之间的差异度最大.关于后者国内外学者对此研究不多,获得的结论普适性较差.而对于前者,当K给定时,可以使用式(5)对每次聚类的结果进行评估. 设聚类的结果为cm={cm1,cm2,…,cnk},xi∈cmj,j=1,2,…,k,则类内差的衡量标准为: (5) 式(5)分别计算了每个聚的类里面的聚类中心到各聚类对象之间的距离的和,该值越小,说明聚类对象之间的相似度越高,聚类的效果越好. 而对于所聚的类的个数K,我们可以依照式(6)对类内差的和的均值设定一个阈值,当小于该阈值时,我们即可认为类内的对象之间的相似度达到一个比较满意的结果,也即所聚的区域内的城市内之间,能够实现相当的城市群效应. (6) 3实例分析 本节在前面模型研究的基础上,以国内某大型B2C电商作为参考,结合2013年的中国统计年鉴、中国互联网信息中心(CNNIC)、艾瑞咨询公司、阿里研究院等权威企业发布的数据对此加以验证,详细探讨电商自营物流企业在进行全国物流网络优化时的网络拓扑结构应该如何进行选择与搭建,该结果对这一领域的学术研究与物流中心的选址决策给出一定的参考建议. 图2 当k=5~9时B2C电商全国物流网络区域划分 参数μ用来衡量订单量与城市距离的引力权重,当μ=0.1时,订单量与运输距离处于一个数量级,相应的聚类效果比较理想. 当k=5、6时,类内差均值较大,分别为1 856和1 423.从地理位置上来看,北京RDC覆盖华北和东北两个地区,考虑到东三省人口总量以及运输效率的综合因素,聚类数目不能满足现有B2C电商企业对物流配送时效的要求. 当k=7时,聚类的效果按照我国地理分布可以分成东北、华北、西北、华东、华中、西南和华南,按照此种方法进行区域划分更加接近于京东目前全国物流网络区域配送中心局部,详细的城市聚类效果如表1所示. 当k=8时,华中、华南和西南区进行了重新聚类,武汉城市群被分散到重庆、广州、福州城市群,这样选址的合理性在于沿海城市电子商务发展水平要高于内陆城市,RDC分布于沿海地区有利于对客户订单做出快速响应,不合理性在于尽管中部地区城市平均订单水平较低,但是存在像武汉、长沙这样的网购密集点,需要RDC对其做出快速响应. 当k=9时,华东区按照江苏和浙江进行划分,也说明这两个省在全国范围来看的订单量较高.而上海RDC到连云港的干线运输距离为450 km,完全可以满足快速响应的需求,设立9个区域配送中心超出了实际的需求. 表1 k=7时区域配送中心选址与覆盖城市 从目前京东全国物流网络布局来看,分别在沈阳、北京、西安、上海、武汉广州、成都七个城市设立了RDC,本文所使用的聚类方法在聚类结果上有4座城市的RDC选址是一致的.对于三个有差异的区域配送中心我们从订单量层面分析. 2013年长春、吉林、大庆、哈尔滨预测订单量与沈阳、大连的订单量均为9 000万单,然后考虑到在我国供应商供货主要是由沿海城市向内陆城市进行配送,因而将沈阳设为RDC具有现实意义. 武汉地区的订单量预测值为1亿单,长沙地区为6 000万单,长沙周边三个地级市的订单量与武汉地区相仿,从覆盖用户需求的角度上看,武汉地区作为区域配送中心更加合理. 对于重庆城市群,模型给出的结果是重庆覆盖云南和广西大部分城市,根据京东的网络布局,依靠成都对云南、广西、重庆三座城市进行覆盖.尽管成都的电子商务发展水平较高、但是与三个省之间的地理距离相对较远,会影响到服务响应与用户体验,进而我们需要企业更详尽的数据加以计算来对两种方案进行比较,在此我们对聚类结果进行保留. 同时我们分别计算了k=2~9时的类内差的和的均值,其曲线呈现一定的特性,当聚类的个数超出真实类的结果时,曲线趋于平缓[19],根据转折点的位置,也证明了对全国地级市聚类个数为7~8较为合理,曲线图如图3所示. 图3 当k=3~11聚类类内差均值曲线 本文后续研究将基于k=7时的聚类结果,同时选择华东区作为前端物流中心选址的研究对象. 4结 语 结合城市群理论与经济引力模型在城市间经济发展相互作用的理论基础,通过将有约束条件的K-中心点聚类算法与经济引力模型相结合,以城市网购订单量这一衡量城市电商发展水平的关键性指标为经济质量,以城市间实际运输距离为距离因子,通过对经济引力模型的倒置、在聚类算法中对欧式距离重新定义、引入权重等方法,对全国电商物流网络城市节点间的区域聚合模型进行了设计,利用Java工具实现该算法,并对聚类结果设计参数加以分析和评估,从而完成城市间区域聚合. 虽然自营物流高效的满足了消费者的需求,但带来了高昂的成本,这显然不是物流行业的宗旨.与国外相比,主要是我国三方物流的基础设施、信息化不完善,导致物流配送整体水平不高,而电商与物流公司相结合,降低企业整体运营成本,将是一个必然的趋势.如何能将自营电商当前的物流网络与第三方物流公司的网络高效的叠加到一起,在满足高效服务的同时,将成本降到较低的水平,也是未来值得研究的领域之一. 参考文献: [1]GOTTMANN J. Megalopolis or the urbanization of the northeastern seaboard [J]. Economic Geography,1957(33):189-200. [2]刘智勇. 城市群理论研究综述[J]. 湖南商学院学报,2008,8,4(15):35-39. [3]熊剑平,刘承良,袁俊. 国外城市群经济联系空间研究进展[J]. 世界地理研究, 2006, 3(15): 63-70. [4]冯垚. 城市群理论与都市圈理论比较[J]. 经济与社会发展, 2006(3): 96-98. [5]REILLY W J. The law of retail gravitation: Second Edition [M]. New York: 953: 5-6. [6]ANDERSON E A . A theoretical foundation for the gravity equation [J]. American Economic Review, 1979,69:106-116. [7]徐辉, 彭萍. 基于引力模型的江西省经济区划与协调发展研究[J]. 地理科学, 2008, 28(4): 169-172. [8]石贤光. 基于引力模型的中原城市群空间发展模式研究[D]. 南京: 南京航空航天大学, 2008. [9]吴晓薇. 基于引力模型的中原经济区经济空间联系和空间结构研究[J]. 绍兴文理学院学报, 2012,32(3): 98-102. [10]LLOYD S P. Least squares quantization in PCM [J]. IEEE Trans. Information Theory, 1982,28:129-137. [11]D ARTHUR, VASSILVITSKII S.k-means++: The advantages of careful seeding[C]//PA: SODA '07 Proceedings of the Eighteenth Annual ACM-SIAM Symposium, 2007. [12]杨善林, 李永森, 胡笑旋, 等.K-means算法中的k值优化问题研究[J]. 系统工程理论与实践, 2006(2): 97-101. [13]谢可. 物流配送系统中聚类算法的研究与应用[D]. 杭州: 浙江大学, 2009. [14]钱小凤, 林国龙. 基于邮政网络的社区物流多中心m-TSP问题[J]. 大连交通大学学报, 2012, 33(4): 44-46. [15]谷炜, 张群, 胡睿. 基于改进K-means聚类的物流配送区域划分方法研究[J]. 中国管理信息化, 2010, 24(13): 60-61. [16]L KAUFMAN, ROUSSEEUW P J. Finding groups in data: an introduction to cluster analysis[M]. Wiley Series in Probability and Statistics, 1990. [17]白旭,靳志军.K-中心点聚类算法优化模型的仿真研究[J]. 计算进仿真, 2011, 28(1): 218-220. [18]张雪萍, 王家耀. 带障碍约束的遗传K中心空间聚类分析[J]. 计算机工程, 2007, 33(2): 168-170. [19]RAJARAMAN A, ULLMAN J D. Mining of massive datasets [DB/CD]. England: Cambridge University Press, 2012. [20]李晓文,王东.针对B2C电离自营物流的城市群分布模型[J].哈尔滨商业大学学报:自然科学版,2015,31(2):125-128. Logistics network optimization of B2C e-commerce based on constrained clustering algorithm GAO Bao-xin, WANG Dong (Sino-US Global Logistics Institute, Shanghai JiaoTong University, Shanghai 200030, China) Abstract:Based on the city-agglomeration and the gravity model, combining the transport distance and order quantity, redefining the Euclidean distance, considering the equivalent distance as the constraint condition, this paper completed the region division of the national logistics network through the K-center clustering algorithm. Evaluated the result by the inner class difference index and find the reasonable solution. Key words:logistics network optimization; B2C E-commerce;area aggregation; K-center clustering 中图分类号:F724 文献标识码:A 文章编号:1672-0946(2016)01-0071-06 作者简介:高宝鑫(1989-),男,硕士,研究方向:复杂网络优化. 收稿日期:2015-12-20.