
基于MongoDB的闽西客家文化数据存储设计与分析
2016-04-11 01:43:16邬群勇唐曙光黄君毅
测绘工程 2016年3期
江 颖,邬群勇,唐曙光,黄君毅
(1.福建省空间信息工程研究中心,福建 福州 350002;2.福州大学 空间数据挖掘与信息共享教育部重点实验室,福建 福州 350002)
基于MongoDB的闽西客家文化数据存储设计与分析
江颖1,邬群勇1,唐曙光2,黄君毅2
(1.福建省空间信息工程研究中心,福建 福州 350002;2.福州大学 空间数据挖掘与信息共享教育部重点实验室,福建 福州 350002)
摘要:针对客家文化数据类型多样、结构复杂的问题,探讨并构建客家文化数据分类体系。结合客家文化数据的分类和MongoDB数据模型,设计客家文化遗产数据存储模型和客家文化基础设施数据模型。探讨基于MongoDB的客家文化遗产数据查询和索引的构建方法和流程。在100 MPs局域网内基于C/S结构分别构建单机和集群测试环境,测试不同客家文化数据单机和集群的存取性能。实验表明,基于MongoDB的客家文化数据模型能够较好地实现类型多样、结构复杂的客家文化数据的管理,便于以增加节点的方式来提高存储能力和读写性能。
关键词:客家文化;MongoDB;数据存储;NoSQL数据库;分布式存储
客家是经过两晋、唐宋、明末以来5次较大规模的从中原地区往南方各省以及国外迁徙形成的汉族民系。闽西客家文化是南迁的中原汉族与当地闽越族人杂居、融合中产生的文化[1-2]。如何保存这些有形无形的文化遗产为中华民族多元文化添彩,是一个亟待解决的问题。
数字化和信息化技术的发展和成熟,为文化遗产的保护提供了新的技术手段和思路。三维地面激光扫描、360全景摄像、卫星和低空遥感、GPS、数字扫描、数字录音录像等设备和技术的应用,采集了大量的客家文化数据。这些数据具有类型多样、数据格式差异大、非结构化、数据量大等特点,需要更灵活的数据库技术来管理和存储数据。
NoSQL[3-4]是基于CAP[5]和BASE[6]发展起来的新型数据库,采用松散的、非结构化或半结构化的数据模型,在类型多样、非结构化数据管理方面提供了一种较好的解决方案。王歆[7]使用非关系型数据库存储海量近地天文望远镜图像数据;范建永等[8]使用Hbase存储矢量空间数据;陈崇成等[9]探讨基于NoSQL的海量空间数据云存储策略与方法。NoSQL数据库在非结构化数据存储上有其独特的优势,而在对多种类型非结构化数据统一管理时,需要更加灵活的存储策略。
论文针对多种类型的客家文化数据统一管理与查询,并满足用户的高效访问、灵活易用的实际需求。尝试使用NoSQL中文档型数据库MongoDB[10-11]存储客家文化数据。
1闽西客家文化数据分类
本文以闽西客家文化数据为背景,在描述过程中将客家文化数据分两大类:一类是用于展示客家文化遗产的客家文化遗产数据;另一类是辅助展示客家文化遗产的基础设施数据。
根据文化遗产的表现形式将客家文化遗产数据分为物质文化遗产数据、非物质文化遗产数据。物质文化遗产数据包括了民居(土楼、围龙屋等)、古桥梁、寺庙、祠堂、文物等有形文化遗产的数据;非物质文化遗产数据包括了历史事件、客家民俗文化数据等无形的文化遗产数据。其中客家民俗文化是客家文化的精髓,囊括了极其丰富的内容,如客家传统医药、客家传统手工艺、客家民间音乐和戏剧、客家民间文学、客家传统节日、客家饮食习惯等。
客家文化基础设施数据主要由一些影像图和相关设施(交通路线、商店等)图构成,辅助文化遗产数据展示。客家文化基础设施数据根据数据格式和展示方式的不同,分为栅格类型的基础设施数据和矢量类型的基础设施数据。栅格类型的基础设施数据包括闽西卫星影像图、客家文化专题图(如客家人口分布图、客家迁徙路线图)、龙岩地区行政区划图等;矢量类型的基础设施数据包括景区、交通路线、商店、停车场等相关设施数据。
2基于MongoDB的客家文化遗产数据存储
2.1MongoDB数据模型
MongoDB是面向文档的开源数据库。MongoDB模式灵活,支持面向文档的查询,可以在任何属性上建立索引,包括建立空间索引和全文索引,同时其可扩展性强、支持复制和故障恢复。
MongoDB的逻辑结构与关系型数据库相似,分为数据库(database)、集合(collection)和文档(document)三层。MongoDB的数据库(database)相当于关系型数据库的数据库,集合(collection)相当于关系型数据库的表,文档(document)相当于关系型数据库的记录。MongoDB使用类似于JSON的BSON动态存储数据,支持数值、字符串、日期数组等多种基本类型的数据,同时可以支持文档嵌套文档等多种复杂的存储方式。
2.2客家文化数据存储模型
根据以上对MongoDB的分析,MongoDB是模式自由的数据库,同一个集合中每一条文档都可以是不同的结构,使用MongoDB可以很容易地更改结构。但为了提高数据库的可操作性,在设计数据库时同一集合一般会使用统一的结构。本文结合MongoDB和客家文化数据的分类信息,构建客家文化遗产数据库和客家文化基础设施数据库。
2.2.1客家文化遗产数据存储结构
基于MongoDB的客家文化遗产数据库按两层结构进行存储,分别为元数据层和具体的数据集。用户通过元数据了解数据库中数据集的描述信息,并根据元数据提供的数据类型进行读取和转换数据格式。
1)元数据,客家文化遗产数据元数据集中,包含客家文化遗产数据集的内容描述、坐标系描述、以及每项数据的类型和含义。
2)数据集,客家文化遗产数据库中包含物质文化遗产数据集和非物质文化遗产数据集,如图1所示。
物质文化遗产数据集中文档由唯一标识符(_id)、物质文化遗产名称(name)、所属类别(category)、介绍信息(info)、物质文化遗产地址(address)、空间位置(location)、图片(picture)、视频(video)、音频(voice)、三维模型(model)、360全景(360panorama)组成。其中物质文化遗产名称、类别、简介、地址是字符串格式的,空间位置数据是GeoJSON格式的点要素数据。图片分两部分存储,缩略图以二进制格式存储在文档中,另一部分图片与视频、音频、三维模型、360全景数据一起存储在GridFS中,文档中只记录相应的字符串格式的文件名数组。GridFS是MongoDB采用的分布式存储文件的机制。
非物质文化遗产数据集文档结构与物质文化遗产文档结构相似。非物质文化遗产的空间位置(location)包含GeoJSON格式的点要素数据和面要素数据,因为非物质文化遗产是一项区域性的传统或手工艺传承。
2.2.2客家文化基础设施数据存储结构
基于MongoDB的客家文化基础设施数据库,由栅格类型基础设施地图集和矢量类型基础设施地图集组成,如图2所示。栅格类型和矢量类型的基础设施地图集中的每一个图层存储为一个集合。
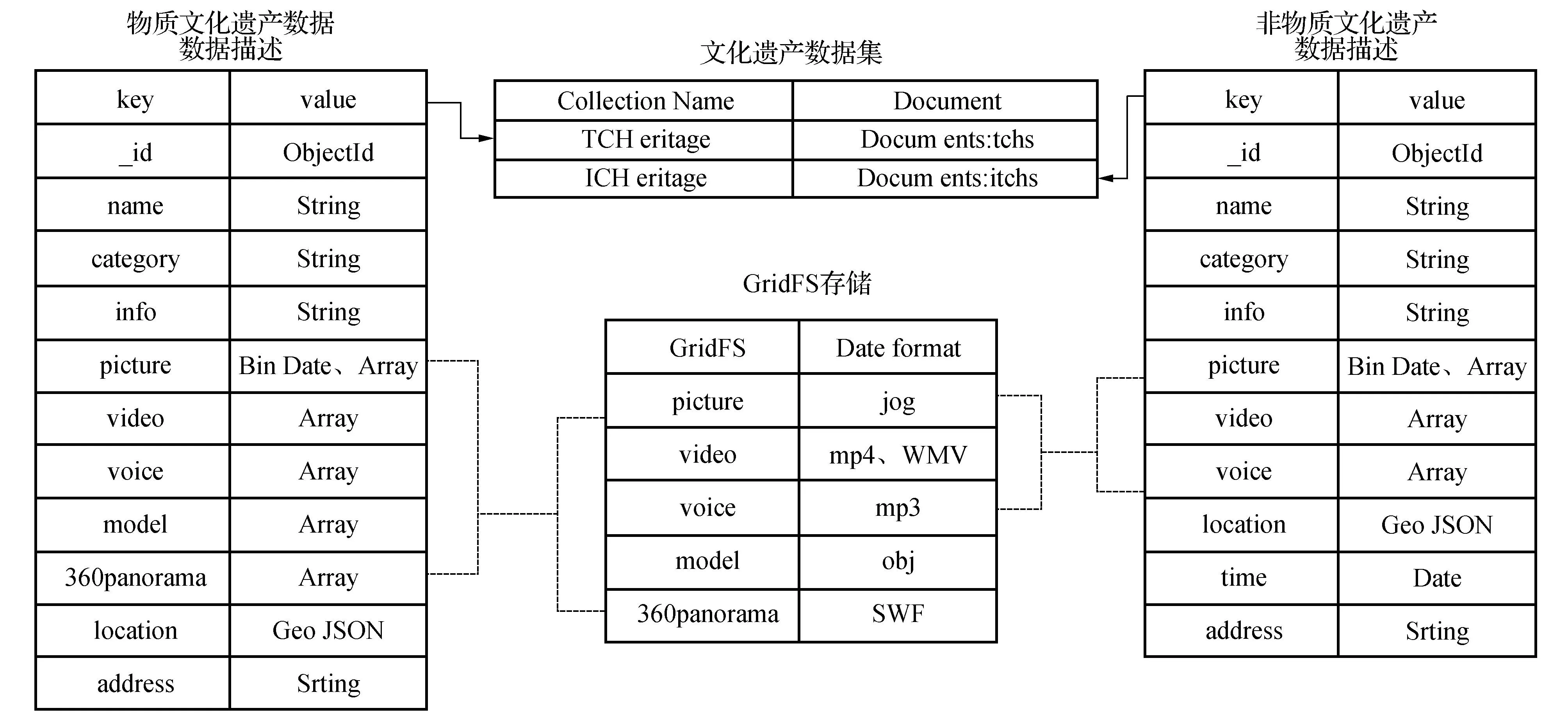
图1 客家文化遗产数据存储结构
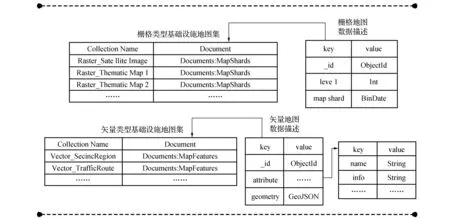
图2 客家文化基础设施数据存储结构
栅格类型基础设施地图集存储的是卫星影像地图和客家文化专题图等栅格数据。按金字塔式划分的地图瓦片数据根据不同内容存储在不同的集合中,而集合中文档内容由瓦片唯一标识符(_id)、瓦片所属层级(level)、以及瓦片二进制数据(mapshard)构成。
矢量类型的基础设施地图集存储的是景区、交通路线、商店等矢量数据。一个集合存储一个图层相应的地理要素数据,每个文档由要素的唯一标识符(_id)、属性数据(attribute)、空间数据(geometry)。其中属性数据根据具体数据而定,包含如名称(name)、简介(info)等,通过一个内嵌文档保存。
3基于MongoDB的客家文化遗产数据查询与索引构建
查询是数据库最基本的功能,而索引可以加快查询速度。根据客家文化遗产数据的特点,最常用的查询一是通过给定客家文化遗产名称进行查询,二是通过给定的位置或范围进行查询。为了优化查询,在客家文化遗产数据集上建立2个索引:name键的索引、location键的索引。location键采用2dsphere索引,2dsphere是MongoDB提供的一种球面索引方式。通过索引可以实现对点、线、面几何图形进行球面检索,实现临近查询、点在面内等空间查询。
客家文化遗产数据查询流程,如图3所示,主要分为以下几个步骤:
1)通过属性信息对客家文化遗产数据进行查询。通过用户输入的名称信息,可以根据已经建立的name键索引对客家文化遗产数据库进行查询。查询到目标数据则读取数据,如未查询到目标数据,要求用户重新输入查询条件。
2)通过空间关系对客家文化遗产数据进行查询。给定要查询的数据类别后选择临近查询或者范围查询,数据类别可以是物质文化遗产数据中的民居、古桥梁等,也可以是非物质文化遗产文化民俗,或者是复合类别。临近查询或者范围查询得到目标数据后读取数据,结束流程。

图3 客家文化遗产数据查询流程
4试验与结果分析
4.1试验环境及数据
在100 MPs局域网内基于C/S结构分别构建MongoDB数据库集群和单机测试环境。数据库集群上每台计算机分别部署一个MongoDB分片节点(Shard)、一个配置服务器(Config Server)、一个路由器(Router)。计算机配置如下:客户机 CPU为AMD A8-4500M,内存为8GB,操作系统为Windows7,数据库集群由三台CPU为E5300,内存2GB,操作系统Ubuntu12.04计算机组成。单机的读写测试由组成集群的其中一台计算机完成。实验数据由三部分组成:一是由客家文化遗产名称、类别、简介、地址、空间位置数据和缩略图组成客家文化遗产数据;二是客家文化遗产的图片、视频、音频、三维模型、360全景数据;三是龙岩地区地图数据。
4.2客家文化数据入库
本文根据客家文化数据库设计,测试不同类型客家文化数据写入效率,测试结果如下:由客家文化遗产名称、类别、简介、地址、空间位置数据和缩略图组成的大小约为10 KB。写入100万条数据单机和集群所用时间分别为2 068 s,1 212 s。
客家文化遗产的图片、视频、音频、三维模型、360全景等数据存储在GridFS中。这些数据大小并不一致,每个文化遗产描述过程中可能会包含其中一项或者多项(图片1 Mb-10 Mb、视频100 Mb-2 Gb、音频5 Mb-50 Mb、三维模型50 Mb-200 Mb、360全景5 Mb-20 Mb)。集群和单机向GridFS中导入单个客家文化遗产文件,时间相差不大,如表1所示。
按照客家文化基础设施数据库设计的栅格类型基础设施数据存储结构,导入龙岩市由Google Maps切图方案切得的12到16级瓦片地图。切片为10-20 KB的jpg格式图片,12到16级数据大小分别为6.6 MB、45.3 MB、76 MB、230 MB、846 MB。各层级切片地图数据的集群导入时间约为单机导入时间的一半,如表2所示。
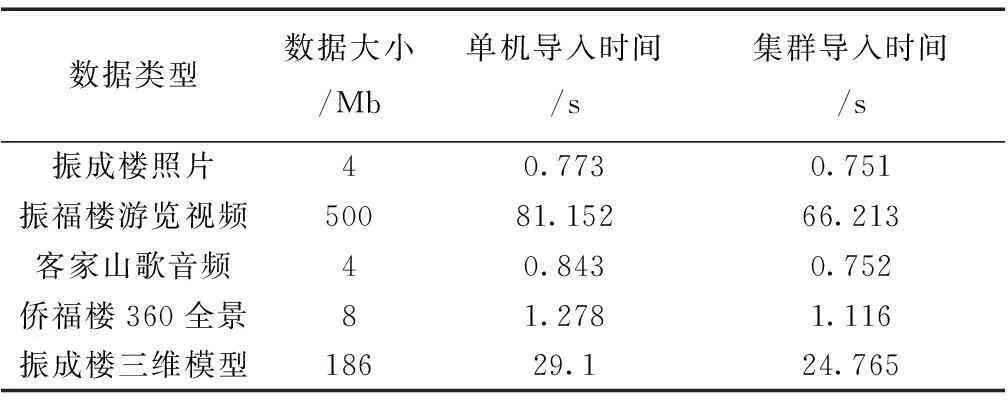
表1 不同类型客家文化遗产数据导入时间

表2 栅格类型基础设施数据导入时间

图4 并发访问测试
4.3客家文化数据查询试验
根据客家文化遗产的类别和名称对数据库中100万条不同的客家文化遗产数据进行查询测试。设计每个并发对客家文化遗产数据库中2 000条不同的数据进行查询,并在测试前对数据进行预热,使数据最大程度读入内存。测试结果如图4所示,图中横轴为并发数,纵轴为每秒总共查询条数。在40并发前单机每秒查询条数高于集群,40并发后集群的每秒查询条数继续提高,而单机不再增加。集群每秒查询条数会有起伏,因为查询的数据不是绝对平均地存储在三台计算机中。在90并发后单机每秒查询数量急剧下降,是由于查询的数据量已经超出单台计算机内存大小。
由以上实验可知,基于MongoDB的客家文化数据模型能够较好地实现类型多样、结构复杂的客家文化数据的管理,并容易通过增加节点的方式来提高数据库存储能力和读写性能。
5结束语
本文利用MongoDB灵活的数据存储方式,对各种不同类型的客家文化数据进行研究,设计不同类型客家文化数据的存储模型以及构建了查询索引方法和流程。最后用实验验证了这些存储模型的有效性,并测试在不同环境下的存取效率,为文化遗产数据高效管理提供解决思路。下一步工作是建立闽西客家文化目录服务系统,实现各种类型闽西客家文化数据的统一展示。
参考文献:
[1]罗香林.客家源流考[M].北京:中国华侨出版公司,1989:13-51.
[2]林晓平.客家文化特质探析[J].西南民族大学学报(人文社科版),2005,26(12):72-75.
[3]申德荣,于戈,王习特,等.支持大数据管理的NoSQL系统研究综述[J].软件学报,2013,24(8):1786-1803.
[4]杜晋博,杨君君.基于NoSQL和云存储的非结构化存储服务[J].武汉大学学报(理学版),2012,58(10):99-101.
[5]GILBERT S,LYNCH N.Brewer’s conjecture and the feasibility of consistent,available,partition-tolerant web services[J].ACM SIGACT News,2002,33(2):51-59.
[6]PRITCHETT D.Base:An ACID alternative[J].Queue,2008,6(3):48-55.
[7]王歆.基于非关系型数据库系统的近地天体望远镜图像数据库的设计与实现[J].天文学报,2013,54(4):382-391.
[8]范建永,龙明,熊伟.基于HBase的矢量空间数据分布式存储研究[J].地理与地理信息科学,2012,28(5):39-42.
[9]陈崇成,林剑峰,吴小竹,等.基于NoSQL的海量空间数据云存储与服务方法[J].地球信息科学学报,2013,15(2):166-174.
[10] CHODOROW K.MongoDB:the definitive guide[M].“O’Reilly Media,Inc.”,2013.
[11] ZENG Wei-ping,LI Ming-Xin,CHEN Huan.Using MongoDB to implement textbook management system instead of MySQL[C]//Communication Software and Networks (ICCSN),2011 IEEE 3rd International Conference on.IEEE,2011:303-305.
[责任编辑:张德福]
Design and analysis for the storage of Western Fujian Hakka culture data based on MongoDB
JIANG Ying1,WU Qunyong1,TANG Shuguang2,HUANG Junyi2
(1.Spatial Information Research Center of Fujian Province,Fuzhou 350002, China; 2.Key Laboratory of Spatial Data Mining and Information Sharing Ministry of Education(Fuzhou University), Fuzhou 350002, China)
Abstract:Considering the enriched types and the complicate structures of Hakka culture data,this paper investigates and develops the relevant data classification system.Combining the Hakka culture data classification system and the MongoDB data model,the storage model for Hakka cultural heritage data and the data model for infrastructure of Hakka culture are developed.Meanwhile,construction methods and processes of query and index for the Hakka cultural heritage data,based on MongoDB,are discussed.In a 100 MPs LAN,single-machine and cluster testing environments based on C/S structure are constructed,and the read/write performances of different Hakka culture data in the corresponding environments are tested.The experiments show the model based on MongoDB can smoothly manage the enrich-typed and complicate-structured Hakka culture data,of which the storage capacity and read/write performance can be improved by adding nodes.
Key words:Hakka culture;MongoDB;data storage;NoSQL database;distributed storage
中图分类号:TP311
文献标识码:A
文章编号:1006-7949(2016)03-0056-05
作者简介:江颖(1990-),女,硕士研究生.
基金项目:国家科技支撑计划资助项目(2013BAH28F00)
收稿日期:2014-12-05
猜你喜欢
鄱阳湖学刊(2016年6期)2017-01-16 13:01:29
办公室业务(2016年11期)2017-01-09 18:02:44
中国科技博览(2016年24期)2016-12-28 23:25:48
电子技术与软件工程(2016年20期)2016-12-21 11:11:51
电脑知识与技术(2016年28期)2016-12-21 10:13:14
电脑知识与技术(2016年27期)2016-12-15 20:33:05
人民论坛(2016年26期)2016-10-12 17:35:08
北方文学·中旬(2016年5期)2016-06-30 15:45:41
戏剧之家(2016年12期)2016-06-30 13:16:23
考试周刊(2016年27期)2016-05-26 19:11:11
