
Salient pairwise spatio-temporal interest points for real-time activity recognition
2016-04-11 00:43:23MengyunLiuHongLiuQinruSunTinweiZhngRunweiDing
Mengyun Liu,Hong Liu,b,*,Qinru Sun,Tinwei Zhng,Runwei Ding
aEngineering Lab on Intelligent Perception for Internet of Things(ELIP),Peking University,Shenzhen Graduate School,518055,China
bKey Laboratory of Machine Perception,Peking University,100871,China
cNakamura-Takano Lab,Department of Mechanoinformatics,The University of Tokyo,113-8685,Japan
Salient pairwise spatio-temporal interest points for real-time activity recognition
Mengyuan Liua,Hong Liua,b,*,Qianru Suna,Tianwei Zhangc,Runwei Dinga
aEngineering Lab on Intelligent Perception for Internet of Things(ELIP),Peking University,Shenzhen Graduate School,518055,China
bKey Laboratory of Machine Perception,Peking University,100871,China
cNakamura-Takano Lab,Department of Mechanoinformatics,The University of Tokyo,113-8685,Japan
Real-time Human action classification in complex scenes has applications in various domains such as visual surveillance,video retrieval and human robot interaction.While,the task is challenging due to computation efficiency,cluttered backgrounds and intro-variability among same type of actions.Spatio-temporal interest point(STIP)based methods have shown promising results to tackle human action classification in complex scenes efficiently.However,the state-of-the-art works typically utilize bag-of-visual words(BoVW)model which only focuses on the word distribution of STIPs and ignore the distinctive character of word structure.In this paper,the distribution of STIPs is organized into a salient directed graph,which reflects salient motions and can be divided into a time salient directed graph and a space salient directed graph, aiming at adding spatio-temporal discriminant to BoVW.Generally speaking,both salient directed graphs are constructed by labeled STIPs in pairs.In detail,the“directional co-occurrence”property of different labeled pairwise STIPs in same frame is utilized to represent the time saliency,and the space saliency is reflected by the“geometric relationships”between same labeled pairwise STIPs across different frames.Then, new statistical features namely the Time Salient Pairwise feature(TSP)and the Space Salient Pairwise feature(SSP)are designed to describe two salient directed graphs,respectively.Experiments are carried out with a homogeneous kernel SVM classifier,on four challenging datasets KTH,ADL and UT-Interaction.Final results confirm the complementary of TSP and SSP,and our multi-cue representation TSP+SSP+BoVW can properly describe human actions with large intro-variability in real-time.
Spatio-temporal interest point;Bag-of-visual words;Co-occurrence
1.Introduction
Recently,human action classification from video sequences plays a significant role in human-computer interaction, content-based video analysis and intelligent surveillance, however it is still challenging due to cluttered backgrounds, occlusion and other common difficulties in video analysis. What's worse,intro-variability among the same type of actions also brings serious ambiguities.To tackle these problems, many human action classification methods based on holistic and local features have been proposed[1,2].Holistic features have been employed in Refs.[3-5],where actions were treated as space-time pattern templates by Blank et al.[3]and the task of human action classification was reduced to 3D object recognition.Prest et al.[4]focused on the actions of human-object interactions,and explicitly represented an action as the tracking trajectories of both the object and the person.Recently,traditional convolutional neural networks (CNNs)which are limited to handle 2D inputs were extended, and a novel 3D CNN model was developed to act directly on raw videos[5].
Comparing with holistic features,local features are robust to shelters which need no pre-processing such as segmentation or tracking.Laptev[6]designed a detector which defines space-time interest points(STIPs)as local structures where the illumination values show big variations in both space and time.Four later local feature detectors namely Harris3D detector,Cuboid detector,Hessian detector and Dense sampling were evaluated in Ref.[7].Recently,dense trajectories suggested by Wang et al.[8]and motion interchange patterns proposed by Kliper-Gross et al.[9]have shown great improvement to describe motions than traditional descriptors though both need extra computing costs.Besides using content of local features,researches only using geometrical distribution of local features also achieve impressive results for action classification.Bregonzio et al.[10]described action using clouds of Space-Time Interest Points,and extracted holistic features from the extracted cloud.Ta et al.[11]concatenated 3D positions of pairwise codewords which are adjacent in space and in time for clustering.A bag of 3D points was employed by Li et al.[12]to characterize a set of salient postures on depth maps.Yuan et al.[13]extended R transform to an extended 3D discrete Radon transform to capture distribution of 3D points.These methods assume that each local feature equals to a 3D point,and all local features have the only difference of location.
Bag-of-visual words(BoVW)introduced from text recognition by Schuldt et al.[14]and Dollar et al.[15]is a common framework to extract action representation from local features. STIPs are firstly extract from training videos and clustered into visual words using clustering methods.BoVW is then adopted to represent original action by a histogram of words distribution,and to train classifiers for classification.Despite its great success,BoVW ignores the spatio-temporal structure information among words and thus leads to misclassification for actions sharing similar words distribution.To make up for above problem of BoVW,the spatio-temporal distribution of words is explored.Words are treated in groups to encode spatio-temporal information in Refs.[16-18].Latent topic models such as the probabilistic Latent Semantic Analysis (pLSA)model are utilized by Niebles et al.[16]to learn the probability distributions of words.Cao et al.[17]applied PCA to STIPs,and then model them with Gaussian Mixture Models (GMMs).A novel spatio-temporal layout of actions,which assigns a weight to each word by its spatio-temporal probability,was brought in Ref.[18].Considering words in pairs is an effective alternative to describe the distribution of words. From one point of view,pairwise words which are adjacent in space and in time were explored by Refs.[11,19,20].Local pairwise co-occurrence statistics of codewords were captured by Banerjee et al.[19],and such relations were reduced using Conditional Random Field(CRF)classifier.Savarese et al. [20]utilized spatial-temporal correlograms to capture the cooccurrences of pairwise words in local spatio-temporal regions.To represent spatio-temporal relationships,Matikainen et al.[21]formulated this problem in a Nave Bayes manner, and augmented quantized local features with relative spatialtemporal relationships betweenpairs of features.From another point of view,both local and global relationships of pairwise words were explored in Refs.[22,23].A spatiotemporal relationship matching method was proposed by Ryoo et al.[22]which explored temporal relationships(e.g. before and during)as well as spatial relationships(e.g.near and far)among pairwise words.In Ref.[23],co-occurrence relationships of pairwise words were encoded in correlograms,which relied on the computation of normalized googlelike distances.
In this work,the directional relationships of pairwise features are explored to make up the problems of BoVW.It is observed that human actions make huge senses in the directional movement of body parts.From one aspect,the spatial relationships among different parts,which are moving at the same time,are directional.Besides,one part keeps directionally moves from one place to another.Here,a“push”action in Fig.1 is used to illustrate observations,where green points denote local features.As shown in Framet+1,the pusher's hands and the receiver's head are moving at the same;meanwhile,the vertical location of hands is lower than the head. The relationship between this type of pairwise motions,which is according to the first observation,is called directional cooccurrence.Crossing from Framet-1 to Framet,the pusher's hands keep moving forward.This type of pairwise motions are also directional and reflect the second observation. The observations both indicate the importance of directional information for action representation.Hence the attribute of mutual directions are assigned to pairwise STIPs to encode structural information from directional pairwise motions, generating new features called Time Salient Pairwise feature (TSP)and Space Salient Pairwise feature(SSP).
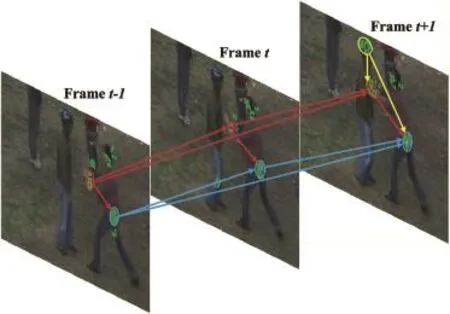
Fig.1.A“push”action performed by a“pusher”and a“receiver”.
1.1.Time Salient Pairwise feature
Time Salient Pairwise feature(TSP)is formed from a pair of STIPs which shows“directional co-occurrence”property.In our previous work,[24]and[25]have already employed this property for action recognition.The TSP mentioned in this paper is a refined and expanded version from the conference proceedings paper[24].TSP is compared with traditionalBoVW and“Co-occur”based methods in Fig.2,where action 1,action 2 are simplified as labeled pointsa,bandti(i=1,…,12)means time stamps.Here,“Co-occur”adopted by Sun et al.[23]means only using co-occurrence feature of pairwise words.BoVW fails in the second and third rows when two actions share the same histogram of words.“Cooccur”can distinguish actions in the second row but also fails when two actions share the same co-occurrence features.TSP adds extra directional information to co-occurrence features, thereby avoiding two failing cases of both BoVW and“Cooccur”.Comparing with[22],our novelty lies in the use of direction instead of distance when describing the pairwise cooccurrence.TSP also differs from Refs.[20]and[23]in the use of both number and direction of pairwise words.
1.2.Space Salient Pairwise feature
Note that TSP only captures the directional information between different labeled pairwise words and ignores the relationships among same labeled words.To encode this relationship,geometrical distribution of local features need to be involved.In this work,any pair of words sharing same labels are linked into a vector,and all vectors are as input instead of local descriptors like Histogram of Gradient(HoG)[26]or Histogram of Flow(HoF)[27]for traditionally BoVW model. This new feature is named Space Salient Pairwise feature (SSP)which is different from Ref.[11]in capturing global distribution of pairwise points.As shown in the fourth row of Fig.2,SSP provides spatial location information for TSP to classify two actions with same co-occurrence properties.
2.Modeling human actions as directed graphs
In graph theory,a directed graph refers to a set of nodes connected by edges,where edges have directions associated with them.In this paper,directed graphs are employed to represent the human action in a video V0,and the main work lies in the determination of nodes,the choice of edges and the assignment of directions between nodes.Some symbols used in following sections are listed in Table 1 with their meanings.

Table 1 Illustrating the meanings of symbols.
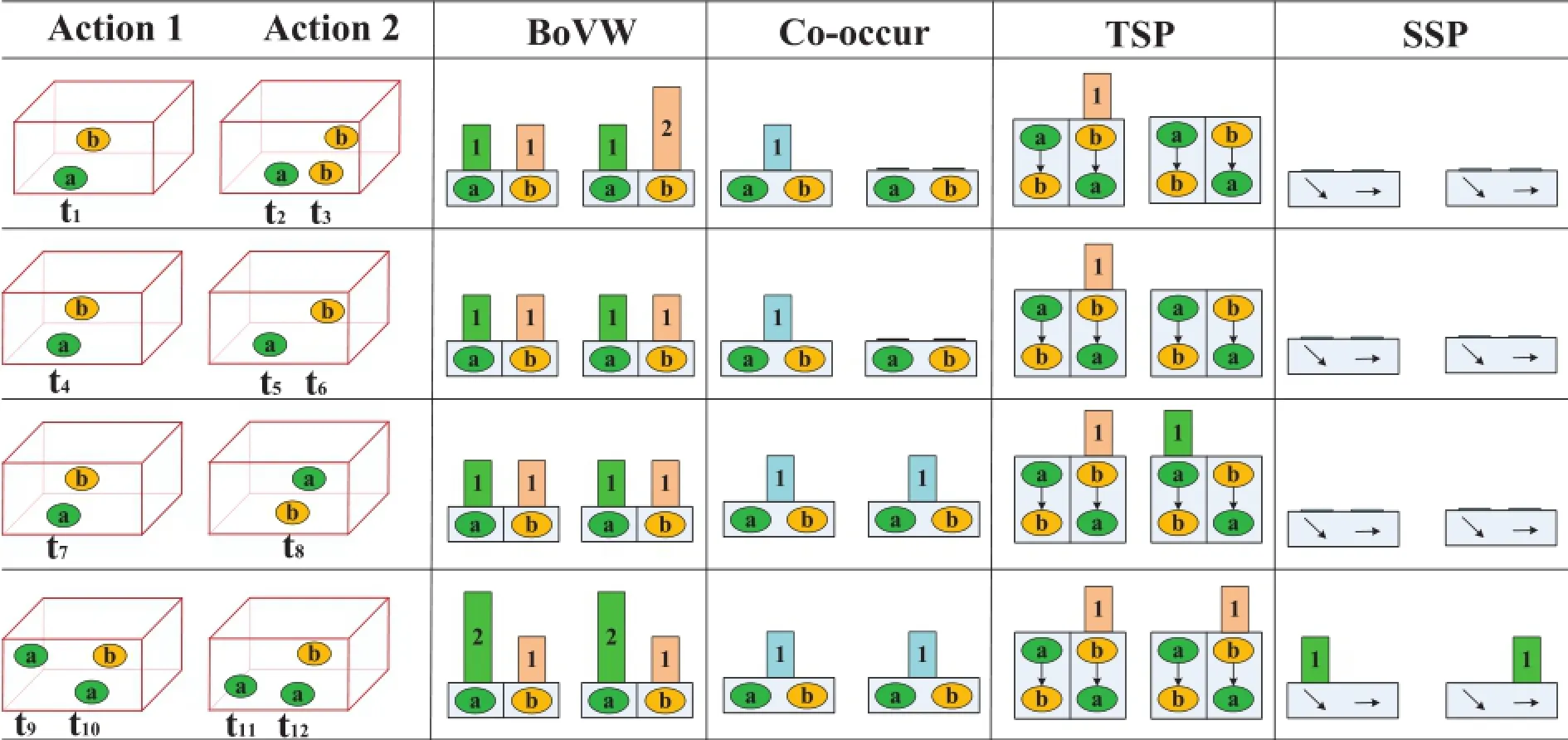
Fig.2.Comparing representations of similar actions by four methods,namely Bag of Visual Words(BoVW),Co-occurrence Feature(Co-occur),Time Salient Pairwise feature(TSP)and Space Salient Pairwise feature(SSP).
An action sequence can be denoted by a cloud of Spatiotemporal interest points(STIPs)in the field of action analysis using local features.By referring to a dictionary D,STIPs are clustered into different labels and each label stands for a kind of movement.Here,all labeled STIPs are defined as nodes of the directed graphs.To construct dictionary D,a setof training videosare needed,whereisthenthvideowithframes.STIPsaredetected from videowherex,yrefer to horizontal and vertical coordinates,tis the index of framedenotes the N-dimensional feature vector of the STIP.Then,alldesfromare clustered intoKclustersusing algorithms like k-means. To label STIPsfrom the videoeachdesinis labeled by finding the nearest center in dictionaryIf the nearest cluster isdesk,thendesis labeledk.Till now,the videois representedbyMlabeledpoints

Fig.3.Representing a human action as a directed graph with salient edges.
To describe the spatio-temporal distribution ofpoints are considered in pairs for simplicity and efficiency.By connecting any pair of points froman undirected graphis defined to model videoandIt is noting thatis the edge betweenSince directly using G to representis not time efficient,a new undirected graphwith less edges is defined by splittinginto salient edgesand non-salient edgesMoreover,salient edges is split into time salient edgesand space salient edgesThe time saliency refers to two different labeled nodes appearing at the same time,which is also called co-occurrence,and the space saliency denotes two same labeled nodes appearing cross different frames.The saliency of an edgeis formulated as follows,

3.Time salient directed graph
It is observed that pairwise different movements appearing at the same time are a good feature to distinguish an action. For example,an action“Blow Dry Hair”from UCF101 dataset [28]usually refers one person moves his hand and hair simultaneously.When an action is denoted as a cloud of labeled STIPs,this observation can be represented by the cooccurrence of different labeled pairs,which is captured by time salient graphTo describedirections are assigned to all edges and a directed graphis formed.In this part,a simple direction assignment criteria is established to convertThen,a new descriptor called Time Salient Pairwise feature(TSP)is introduced,involving not only nodes but also the directional edges inFinally,the statistics of TSP is utilized to represent
3.1.Time Salient Pairwise feature
The criteria of direction assignment between STIPs are introduced before defining TSP.Suppose STIPs of a given sequence are clustered intoKwords.Sketch in Fig.4 shows how to assign direction for word A and word B.Although the vector formed by A and B provides exact spatial information, it considers little about the noise tolerance.Instead,whether the direction is from A to B or B to A is a more robust feature. Vertical or horizontal relationship is utilized to figure out the direction between A and B with two reference directions defined fromup to downandleft to rightrespectively.It is noted that human actions like waving right hand and waving left hand are usually symmetric.Their directions are opposite in horizontal direction but same in vertical direction.Thus,we consider the vertical relationship priority to the horizontal oneto eliminate the ambiguities of symmetric actions.Let Δxand Δyrepresent projector distances andTx,Tystand for threshold values(in Fig.4).If A and B are far in vertical direction (Δx≥Tx),the reference direction is set from up to down.In contrast(Δx<Tx),the relationship in the vertical direction is not stable and thus discarded.The horizontal relationship is checked in the same way.As for A and B in Fig.4,since Δx≥Txand B is on the top of A,the vertical relationship is selected and the direction is assigned from B to A,which is in accordance with the reference direction.This criteria ignores same labeled pairs like E and F in Fig.4,and also discards any pair of points like C and D that are too close to each other. Summarily speaking,the criteria to assign direction for pointspti=(xi,yi,ti,labeli)andptj=(xj,yj,tj,labelj)are as follows, established,which records both labels and the direction information between two labels.

Fig.4.Direction assignment criterion for pairwise STIPs in the same frame.
3.2.Time salient directed graph


wherei→jindicates the direction.
After direction assignment,the reserved directions are discriminative to represent directional co-occurrent movements.Each direction with two linked nodes construct a new descriptor called Time Salient Pairwise feature(TSP).Taking A and B in Fig.4 as an example,two assumptions are made.a) A and B satisfy the direction assignment criteria in Formula (2);b)thedirectionisfromBtoA.ThenaTSPis

Co-occurrence literally means happening on the same frame.While,in an action sequence,movements constituting the whole action last several sequential frames.To encode this temporal relationship,we treat adjacent several frames as a whole to extract co-occurrence features.Thus,is reformulated as,


The distribution map N is most related to the co-occurrent map[23]which records the number of co-occurrence between STIPs labeledmandnfor location(m,n).In order to intuitively show the difference,a simple action“eating a banana”is used.Two result maps namely distribution map and cooccurrent map are shown in Fig.5.It is shown that element values in(m,n)and(n,m)are the same in co-occurrent map while different in the distribution map,and element value in (m,n)from co-occurrent map equals the average value between element values in(m,n)and(n,m)from distribution map. Therefore,distribution map encodes more information than co-occurrent map.

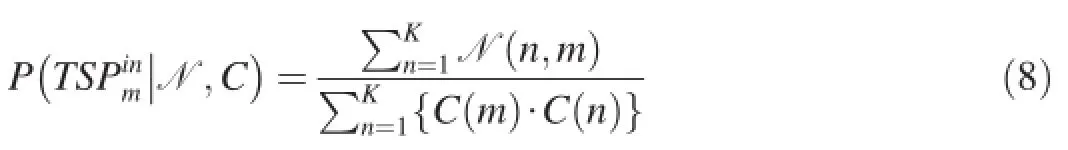
Above two probability values are combined in Formula(9) to construct video representationHTSPwithK×2 dimension. UsingHTSPinstead of histogramN,the video representation is compressed at a ratio ofK/2.

In this section,we focus on pairwise features and extracting directional information from them to reflect the natural structure of human actions that our motion parts are directional.Time Salient Pairwise feature(TSP)is proposed to describe the relationships between pairwise STIPs on the same frame,and only the pairs with different labels are considered. Obviously,TSP ignores the relationships between pairwise STIPs with same labels inand brings ambiguous to distinguish actions with similarThus,this paper proposes another descriptor called Space Salient Pairwise feature(SSP) to describe
4.Space salient directed graph

Fig.5.Distribution map of TSP and co-occurrent map are respectively shown in(a)(b).To facilitate observation,STIPs are extracted and clustered to 30 labels.
To describe an action sequence,a cloud of STIPs are extractedandorganizedinadirectionalgraphA feature called TSP is proposed tocaptures directional information inAs foranother feature called Space Salient Pairwise feature(SSP)is introduced to encode the relationships between pairwise STIPs sharing same labels.And the histogram of quantized SSP is simply utilized as the representation ofFor an action constructed by some main movements,labeled STIPs are dominated by a minor group of labels.Therefore,relationships among same labeled STIPs are important to describe this kind of actions.Take action“boxing”from KTH dataset[14]as an example,which means stretch out a hand and then withdraw it rapidly and periodicity.This action is dominated by the“clenched fist”which appears repeatedly.Obviously,the distribution of the“clenched fist”encoded by SSP is vital to represent“boxing”.
病理检查:选择80iNIKON正置荧光显微镜、LEICA 2145轮转石蜡切片机、Shandon Pathcentre全封闭脱水机、LEICAST5030染色封片工作站。

Fig.6.Extracting statistics from distribution map N of TSP.
4.1.Space Salient Pairwise feature
For same labeled STIPs appearing on different frames, Space Salient Pairwise feature is defined.Given two labeled STIPsa SSPis established ifwhere

4.2.Space salient directed graph

UsingHSSPto describeis inspired by traditional BoVW model,which utilizes the number histogram of STIPs and has achieved markable results in human action recognition.Specifically,thismethod referstoobeythe BoVWmodelandtouse pairwise features instead of traditional HOG-HOF features for clustering and quantization.Detailed steps for computingHSSPareillustrated inFig.7.STIPsare firstly extractedfrom aninput action sequence and assigned labels.All STIPs are divided into different channels by their labels.In each channel,a vector is formed between any pair of STIPs from different frames.Then vectors are collected from all channels to construct a vectors bank,which refers to the edges ofFinally,vectors in the bank are clustered and a histogram is formed to represent

Fig.7.Flowchart of extracting SSP feature from pairwise points.

?
TSP and SSP are naturally combined for their ability of capturing structural relationships of different kinds of STIPs. On one hand,TSP only focus on different labeled pairwise STIPs,while it ignores the spatial temporal constraints which are brought in by same labeled pairs.Additionally,SSP provides extra relationships among same labeled pairs,and thus is compatible with TSP.Letstand for the combination form of both methods.Moreover,The combination form ofHand traditional BoVW,which provides general statistical information of STIPs,is also constructed.
To improve the speed of calculating TSP and SSP,we convert main calculation into several matrix operations which is suitable for MATLAB in the experiments.The main computation shared by TSP and SSP is to compute all pairwise distances among a set of pointsdenotes the coordinate of pointi.Letwhichdenotes a matrix with one row andMcolumns.We form a matrixwhere all elements inequals one.Then the distance matrix equalswhose element inrow and incolumn records the distance between pointandComparing with Algorithm 1 which directly compares any pair of points and thus costtimes of computation,only three matrix operations are needed here to obtain the distance matrix by
5.Experiments and discussions
The proposed descriptors are evaluated on four challenging datasets:KTH dataset in Ref.[14],ADL dataset in Ref.[31] and UT-Interaction dataset in Ref.[22].KTH dataset contains 600 videos of 25 persons performing 6 actions:“walking”,“jogging”,“running”,“boxing”,“handwaving”and“hand clapping”.Each action is repeated 4 times with homogeneous indoor/outdoor backgrounds.ADL dataset contains 150 videos of five actors performing ten actions:“answer a phone”,“chop a banana”,“dial a phone”,“drink water”,“eat a banana”,“eat snacks”,“look up a phone number in a phone book”,“peel a banana”,“eat food with silverware”and“write on a white board”.Each action is repeated three times in the same scenario.Segmented version of UT-Interaction is utilized whichcontainssixcategories:“hug”,“kick”,“point”,“punch”,“push”and“shake-hands”.“Point”is performed by single actor and other actions are performed by actors in pairs. All actions are repeated ten times in two scenes resulting in 120 videos.Scene-1 is taken in a parking lot with little camera jitter and slightly zoom rates.In scene-2,the backgrounds are cluttered with moving trees,camera jitters and passers-by.
Several action snaps from above datasets are shown in Fig.8,where inter-similarity among different types of actions are observed.Actions like“walking”,“jogging”and“running”are similar in KTH dataset,and actions like“answer a phone” and“dial a phone”are alike in ADL dataset.Besides the similaritybetweenaction“kick”and“punch”inUTInteraction dataset,the complex filming scenes in UTInteraction scene-2 also brings difficulty for classification.In following,KTH,ADL and UT datasets are utilized to evaluate our method against inter-similarity among different types of actions,and to evaluate the efficiency of proposed algorithm.“UT”involves both scenes in UT-Interaction dataset.
This work applies Laptev's detector in Ref.[14]obeying original parameter setting to detect STIPs and uses HOG-HOF in Ref.[32]to generate 162 dimension descriptors(90 dimension for HOG and 72 dimension for HOF).After extracting 800 points from each video,k-means clustering is applied to generate visual vocabularies.In order to obtain maximum average recognition rates,the number of clusters for DPF,BPF and BoVW on different datasets are set in Table 2. Recognition was conducted using a non-linear SVM with a homogeneous kernel in Ref.[33].In order to keep the reported results consistent with other works,we obey the same crossvalidation method with[14,31]and[22].Since random initialization is involved in clustering method,all confusion matrices are average values over 10 times running results.
5.1.TSP evaluation
Different parametersTtandTfor TSP are tested on KTH, ADL and UT datasets,with one parameter changing and the other parameter in default values:Tt=0,T=0.ParameterTtis the number of adjacent frames.In other words,each frame with its adjacentTtframes are considered as a whole to extract TSP for current frame.In Formula(3),TxandTyare both set toT,which is the threshold value both for the horizontal and vertical directions.

Fig.8.Human action snaps from four datasets:KTH,ADL and UT-Interaction.
As shown in Fig.10,Ttranges from 0 to 4 at 2 intervals, andTranges from 0 to 10 at 5 intervals.Taking UT datasetwhich contains clustered backgrounds and moving disruptors as an example,the recognition rate slightly improves whenTtgrows,and keeps quite still whenTchanges.This phenomenon shows that the performance of TSP is not sensitive to the changes of parametersTt,Tin a large range.In this work,all following experiments are conducted withTt=0,T=0.
Representation TSP and BoVWare separately compared on KTH dataset(Fig.9(a)),ADL dataset(Fig.9(b))and UT dataset(Fig.9(c))using confusion matrices.Generally speaking,TSP achieves less average recognition rates than BoVW.Meanwhile,TSP+BoVW works better than both TSP and BoVW,which shows the complementary property of TSP to traditional BoVW.The method of TSP+BoVW shows 0.67%higher than BoVW on KTH dataset,1.34%higher on ADL dataset and 0.83%higher on UT dataset.

Table 2 Number of clusters for different datasets.
In Fig.9(a3),TSP improves the discrimination between“jogging”and“running”in KTH dataset.TSP also reduced the errors among“answer a phone”and“dial a phone”in Rochester since extra spatial information is encoded.In UT dataset,most errors happens between“kick”and“punch”in Fig.9(c1).These two actions appear similar to BoVW which focus on describing local features,since they share similar basic movement“stretch out one part of body(hand or leg) quickly towards others”.Seeing from human's view,“punch”refers to leg and“kick”refers to hand.Thus,their spatial distribution of movements,which are captured by spatial temporal layout of STIPs,are different.Based on this observation,TSP improves the discrimination between these two actions by adding directional spatial information to BoVW. This may account for the better performance of distinguish“punch”and“kick”in Fig.9(c1,c3).
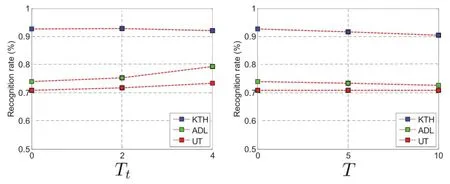
Fig.10.Classification precisions using TSP with different parameter settings.
As can be seen in Fig.9(c3),the recognition rate of“punch”drops when compared with BoVW.The reason lies in that TSP brings some ambiguities to BoVW to distinguish“punch”and“shake-hands”.To solve this problem,SSP is utilized to make up the limitations of TSP.The effect of SSP to improve the recognition precisions of“punch”and“shakehands”are detailed in next section.
5.2.SSP evaluation
Obeying procedures in Algorithm 1,we firstly set cluster numberKthe same as Section 5.1 to cluster STIPs into labels. After obtaining vectors from all channels,these vectors are then clustered intoK2clusters.The value ofK2with best recognition rates are shown in Table 2.
Representation SSP and BoVWare separately compared on KTH dataset(Fig.11(a)),ADL dataset(Fig.11(b))and UT dataset(Fig.11(c))using colored histograms.Generally speaking,SSP achieves less average recognition rates than BoVW.Meanwhile,SSP+BoVW works better than both SSP and BoVW,which shows the complementary property of SSP to traditional BoVW.The method of SSP+BoVW shows 1.84%higher than BoVW on KTH dataset,3.34%higher on ADL dataset and 5.00%higher on UT dataset.
As shown in the UT dataset of Fig.11,the recognition precisions of“punch”and“shake-hands”are improved when comparing with traditional BoVW.The reason lies in that SSP encodes the movements of same types of movements,which are neglected by BoVW.In next section,SSP is combined with TSP and BoVW,and the final representation outperforms SSP, TSP and BoVW.
5.3.Comparison with related works
Tables 3-5 compares the performances of proposed method with state-of-the-arts and cluster numberKis marked with classification rate.Since parameters like the numberKof k-means clustering method differs in different algorithms,the accuracy refers the classification rate with optimal parameters.
KTH dataset is originally utilized by Ref.[14],and the cited paper is marked in italic in Table 3.Our results on KTH dataset are most directly comparable to the method in Refs. [14]and[27],which both utilize the laptev's local feature detector and the BoVW framework.Our BoVW shows much higher than[14]since Laptev's HOG/HOF descriptor and a non-linear SVM with a homogeneous kernel in Ref.[33]are adopted.TSP+BoVW,SSP+BoVW achieves average accuracies of 94.50%and 95.67%.Improvements of 2.70%and 3.87%are respectively achieved over[27],which can be attributed to our addition of spatial temporal distribution information.TSP+SSP+BoVWachieves average accuracy of 95.83%,which is respectively 1.03%and 0.83%higher than state-of-the-art works[34]and[35].
ADL dataset is originally utilized by Ref.[31],which main focus on people's interaction with objects in the kitchen.In the dataset,actions like“answer a phone”and“dial a phone”looks similar in motions,which leads to an average accuracy of only 67.00%using“Velocity Histories”feature in Ref.[31]. It is noted that the background in ADL keeps still,and an“Augmented Velocity Histories”is proposed in Ref.[31] which achieves an average accuracy of 89.00%.Without using structural information from the still background,our methods all performs better than[31],shown in Table 4. What's more,TSP+SSP+BoVW achieves average accuracy of 95.33%,which is 3.33%higher than state-of-the-art work [36].Comparing with our previous work[25],additional 4.00%accuracy is gained,which shows the importance of SSP to TSP and BoVW.
UT dataset is originally utilized by Ref.[22],which main focus on people's interaction with others.Since moving trees and not related persons are also included in the scenes,this dataset can be used to evaluate method's robustness to cluttered backgrounds.As shown in Table 5,our best result achieves 92.50%accuracy,which is 4.9%higher than recent work [38].Since[39]mainly focus on the speed of the algorithm, the local feature detector and clustering steps are implemented using more fast method like V-FAST interest point detector and semantic texton forests.To ensure a fair comparison withour method,we compare the time cost of extracting features with[39]in next section.

Fig.11.Comparing BoVW,SSP and BoVW+SSP on different datasets.
Recently,dense trajectory[8]are widely used in off-line human action recognition,and achieves better accuracy than HOG/HOF features.However,methods in Ref.[8]requires longer time to extract dense trajectories and to form the BoVW features,which are not suitable for real-time applications.Thus,we detect the sparse Harris3D points and extractHOG/HOF features using Laptev's detector and descriptor instead of using dense trajectory.The computation efficiency of proposed features TSP and SSP are evaluated in next part.

Table 3 Comparing with related works on KTH.

Table 4 Comparing with related works on ADL.

Table 5 Comparing with related works on UT.
Final recognition rates using multi-cue representation are shown in Fig.12,and there still exists ambiguities among similar actions.In ADL dataset,“answer a phone”and“dial a phone”are similar naturally since they contains same movements like picking up a phone and bring it to the ear.“Peel a banana”and turning pages in“look up a phone a number”also look similar in having same hand motions.
In Fig.13(a),the detected STIPs are too sparse for same actions,whichalsoresponseforimperfectresults.In Fig.13(b,c),cluster backgrounds and passers-by bring in extra STIPs,which result in more ambiguities for representation and classification.Despite these difficulties,our method obtains remarkable results by adding extra spatial structural information to traditionally BoVW method,e.g.,better discriminative results between“answer a phone”and“dial a phone”are shown in Fig.12(b).
5.4.Computation efficiency and potential applications
The efficiency of calculating TSP and SSP on different datasets are evaluated in Fig.14,where parameterKis in default for both SSP and TSP.Meanwhile,TSP is evaluated with different parametersFandT.The computation time was estimated with MATLAB R2011a(The MathWorks,Natick, MA)on a PC laptop with a 3.00 GHz Intel Core i5-2320 CPU and 4 GB of RAM.Two indicators namelyTdandTfare utilized for evaluation,which mean the time cost of extracting feature TSP or SSP for whole dataset and for each frame.
Since the values ofTdandTfare related to the number of STIPs,the more STIPs cost the longer time.On KTH dataset,Tdnearly equals 12sfor extracting TSP and 60sfor calculating SSP.Since KTH contains more number of STIPs for whole dataset,Tdon KTH is bigger than ADL and UT,which is shown in Fig.14(a1,b1).On UT dataset,Tfnearly equals 0.3 ms for extracting TSP and 1.8 ms for calculating SSP.As the complex background of UT brings more STIPs for each frame,Tfon UT is larger than KTH and ADL,which is illustrated in Fig.14(a2,b2).

Fig.12.Recognition result on KTH(a),ADL(b),UT(c)combining three methods BoVW,TSP and SSP.
The TSP and SSP can be generated efficiently,thus expands the usage of proposed algorithm in many applications likerealtime human action classification and video retrieval,activity prediction and human robot interaction:

Fig.13.Key frames of three actions from ADL and UT are illustrated to show misclassification.

Fig.14.Comparing computation efficiency of TSP and SSP with different parameters.
·The pipeline of performing real-time human action classification is as follows.Given a video containing an action, STIPs are extracted quickly using Laptev's detector in Ref. [14].Then BoVW,TSP and SSP features are calculated in real-time using offline trained models.Finally,non-linear SVM with homogeneous kernel generates the type of action efficiently.Since the proposed algorithm are not limited to human actions,it can be utilized to improve the performance of content based video retrieval.
·Recently,many researches focus on the prediction of ongoing activities[40-42],whose objective is to predict potential actions and alarm person to prevent dangers like“fighting”from happening.Treating an ongoing activity as small segments of videos,our algorithm can be applied to intelligent systems to predict some activities by transforming the task of prediction to classify early video segments.For example,when an early action named“one person stretch out his fist quickly towards another person”is observed,it's likely to be a later action named“fighting”afterwards.
·A mobile robot designed by our lab with a camera and a human-machine interface are shown in Fig.15.We adopt the PHILIPS SPC900NC/97 camera and place it on the head of the robot with a height of 1.8 m.Additionally,a curve mirror is utilized to change the camera into a 360 degree panoramic camera.The mobile robot works in a hall,semi-door environment,with a size of 8 m×8 m.We defined three types of actions namely“Waving”,“Clapping”and“Boxing”,which refer to three orders“moving forward”,“circling”and“moving backward”.As shown in the pipeline of Fig.15,human actions are captured as input for our real-time human action recognition system after preprocessing.Action models are trained based on the KTH dataset[14],and also as input for the system.The output of the action type“Waving”serves as a command“Moving forward”for the robot.Especially in noisy environments,our proposed action recognition method can clearly deliver orders in real-time than using sounds or traditional BoVW method.

Fig.15.Applying human action recognition method to interact with robot named“Pengpeng”in a noisy environment.
6.Conclusions and future work
In this work,a video of human action is referred to a cloud of STIPs,which are modeled by a saliet directed graph.To describe the salient directed graph,a Time Salient Pairwise feature(TSP)and a Space Salient Pairwise feature(SSP)are proposed.Different from BoVW and related works in capturing structural information,TSP involves the words'cooccurrence statistic as well as their directional information. Since richer information of spatial-temporal distribution is involved,TSP outperforms baseline BoVW.Additionally,a Space Salient Pairwise feature(SSP)is designed to describe geometric distribution of STIPs which is ignored by TSP.The SSP achieves compatible results with BoVW model on different datasets which proves the effect of spatio-temporal distribution for action classification without lying on content ofSTIPs.Finally,amulti-cuerepresentationcalled“TSP+SSP+BoVW”is evaluated.This united form outperforms the state-of-the-arts proving the inherent complementary nature of these three methods.Experimental results on four challenging datasets show that salient motions are robustness against distracted motions and efficient to distinguish similar actions.Future work focus on how to model geometric distribution of STIPs more accurately.As only STIPs are involved in current work,high level models and features like explicit models of human-object[4]and dense tracklets in Ref.[43]can be considered.Additionally,more real-time applications will be designed to apply our algorithm.
Acknowledgment
This work is supported by the National Natural Science Foundation of China(NSFC,nos.61340046),the National High Technology Research and Development Programme of China(863 Programme,no.2006AA04Z247),the Scientific and Technical Innovation Commission of Shenzhen Municipality(nos.JCYJ20130331144631730),and the Specialized Research Fund for the Doctoral Programme of Higher Education(SRFDP,no.20130001110011).
[1]A.A.Efros,A.C.Berg,G.Mori,Recognizing action at a distance,in: ICCV,2003,pp.726-733.
[2]J.Aggarwal,M.S.Ryoo,ACM Comput.Surv.(CSUR)43(3)(2011)16.
[3]M.Blank,L.Gorelick,E.Shechtman,M.Irani,R.Basri,Actions as space-time shapes,in:ICCV,2005,pp.1395-1402.
[4]A.Prest,V.Ferrari,C.Schmid,PAMI 35(4)(2013)835-848.
[5]S.Ji,W.Xu,M.Yang,K.Yu,PAMI 35(1)(2013)221-231.
[6]I.Laptev,IJCV 64(2-3)(2005)107-123.
[7]H.Wang,M.M.Ullah,A.Klaser,I.Laptev,C.Schmid,Evaluation of local spatio-temporal features for action recognition,in:BMVC,2009, pp.124.1-124.11.
[8]H.Wang,A.Klaser,C.Schmid,C.L.Liu,IJCV 103(1)(2013)60-79.
[9]O.Kliper-Gross,Y.Gurovich,T.Hassner,L.Wolf,Motion interchange patterns for action recognition in unconstrained videos,in:ECCV,2012, pp.256-269.
[10]M.Bregonzio,S.Gong,T.Xiang,Recognising action as clouds of spacetime interest points,in:CVPR,2009,pp.1948-1955.
[11]A.P.Ta,C.Wolf,G.Lavoue,A.Baskurt,J.Jolion,Pairwise features for human action recognition,in:ICPR,2010,pp.3224-3227.
[12]W.Li,Z.Zhang,Z.Liu,Action recognition based on a bag of 3d points, in:CVPRW,2010,pp.9-14.
[13]C.Yuan,X.Li,W.Hu,H.Ling,S.Maybank,3D R transform on spatiotemporal interest points for action recognition,in:CVPR,2013,pp. 724-730.
[14]C.Schuldt,I.Laptev,B.Caputo,Recognizing human actions:a local svm approach,in:ICPR,2004,pp.32-36.
[15]P.Doll′ar,V.Rabaud,G.Cottrell,S.Belongie,Behavior recognition via sparse spatio-temporal features,in:VS-PETS,2005,pp.65-72.
[16]J.C.Niebles,H.Wang,L.Fei-Fei,IJCV 79(3)(2008)299-318.
[17]L.Cao,Z.Liu,T.S.Huang,Cross-dataset action detection,in:CVPR, 2010,pp.1998-2005.
[18]G.J.Burghouts,K.Schutte,PRL 34(15)(2013)1861-1869.
[19]P.Banerjee,R.Nevatia,Learning neighborhood cooccurrence statistics of sparse features for human activity recognition,in:AVSS,2011,pp. 212-217.
[20]S.Savarese,A.DelPozo,J.C.Niebles,L.Fei-Fei,Spatial-temporal correlatons for unsupervised action classification,in:WMVC,2008,pp. 1-8.
[21]P.Matikainen,M.Hebert,R.Sukthankar,Representing pairwise spatial and temporal relations for action recognition,in:ECCV,2010,pp. 508-521.
[22]M.S.Ryoo,J.K.Aggarwal,Spatio-temporal relationship match:video structure comparison for recognition of complex human activities,in: ICCV,2009,pp.1593-1600.
[23]Q.Sun,H.Liu,Action disambiguation analysis using normalized googlelike distance correlogram,in:ACCV,2012,pp.425-437.
[24]H.Liu,M.Liu,Q.Sun,Learning directional co-occurrence for human action classification,in:ICASSP,2014,pp.1235-1239.
[25]M.Liu,H.Liu,Q.Sun,Action classification by exploring directional cooccurrence of weighted STIPS,in:ICIP,2014.
[26]N.Dalal,B.Triggs,Histograms of oriented gradients for human detection,in:CVPR,2005,pp.886-893.
[27]I.Laptev,M.Marszalek,C.Schmid,B.Rozenfeld,Learning realistic human actions from movies,in:CVPR,IEEE,2008,pp.1-8.
[28]K.Soomro,A.R.Zamir,M.Shah,Ucf101:A Dataset of 101 Human Actions Classes from Videos in the Wild,2012 arXiv preprint arXiv: 1212.0402.
[29]A.Gilbert,J.Illingworth,R.Bowden,Fast realistic multi-action recognition using mined dense spatio-temporal features,in:ICCV,2009,pp. 925-931.
[30]J.Liu,J.Luo,M.Shah,Recognizing realistic actions from videos in the wild,in:CVPR,2009,pp.1996-2003.
[31]R.Messing,C.Pal,H.Kautz,Activity recognition using the velocity histories of tracked keypoints,in:ICCV,2009,pp.104-111.
[32]P.F.Felzenszwalb,R.B.Girshick,D.McAllester,PAMI 32(9)(2010) 1627-1645.
[33]A.Vedaldi,A.Zisserman,PAMI 34(3)(2012)480-492.
[34]H.Zhang,W.Zhou,C.Reardon,L.E.Parker,Simplex-based 3d spatiotemporal feature description for action recognition,in:CVPR,IEEE, 2014,pp.2067-2074.
[35]L.Shao,X.Zhen,D.Tao,X.Li,Cybern.IEEE Trans.44(6)(2014) 817-827.
[36]O.Oshin,A.Gilbert,R.Bowden,CVIU 125(2014)155-171.
[37]P.Banerjee,R.Nevatia,Pose filter based hidden-crf models for activity detection,in:ECCV,Springer,2014,pp.711-726.
[38]V.Kantorov,I.Laptev,Efficient feature extraction,encoding,and classification for action recognition,in:CVPR,IEEE,2014,pp.2593-2600.
[39]T.-H.Yu,T.-K.Kim,R.Cipolla,Real-time action recognition by spatiotemporal semantic and structural forests,in:BMVC vol.2,2010,p. 6.
[40]M.S.Ryoo,Human activity prediction:early recognition of ongoing activities from streaming videos,in:ICCV,2011,pp.1036-1043.
[41]Q.Sun,H.Liu,Inferring ongoing human activities based on recurrent self-organizing map trajectory,in:BMVC,2013,pp.11.1-11.11.
[42]K.Li,Y.Fu,PAMI 36(8)(2014)1644-1657.
[43]P.Bilinski,E.Corvee,S.Bak,F.Bremond,Relative dense tracklets for human action recognition,in:FG,2013,pp.1-7.
Available online 8 March 2016
*Corresponding author.G102-105,School of Computer&Information Engineering Peking University,Shenzhen University Town,Xili,Nanshan District,Shenzhen,Guangdong Province,China.Tel.:+86(0755)2603 5553.
E-mail addresses:liumengyuan@pku.edu.cn(M.Liu),hongliu@pku.edu. cn(H.Liu),qianrusun@sz.pku.edu.cn(Q.Sun),zhangtianwei5@gmail.com (T.Zhang),dingrunwei@pkusz.edu.cn(R.Ding).
Peer review under responsibility of Chongqing University of Technology.
http://dx.doi.org/10.1016/j.trit.2016.03.001
2468-2322/Copyright©2016,Chongqing University of Technology.Production and hosting by Elsevier B.V.This is an open access article under the CC BY-NCND license(http://creativecommons.org/licenses/by-nc-nd/4.0/).
Copyright©2016,Chongqing University of Technology.Production and hosting by Elsevier B.V.This is an open access article under the CC BY-NC-ND license(http://creativecommons.org/licenses/by-nc-nd/4.0/).
猜你喜欢
煤气与热力(2022年2期)2022-03-09 06:29:16
橡塑技术与装备(2021年8期)2021-04-23 07:59:58
选煤技术(2021年6期)2021-04-19 12:22:06
临床与实验病理学杂志(2020年1期)2020-03-05 05:44:16
新型建筑材料(2018年11期)2018-11-23 09:55:58
现代工业经济和信息化(2018年10期)2018-02-21 04:48:06
北京航空航天大学学报(2017年5期)2017-11-23 05:54:11
电力科技与环保(2015年3期)2015-04-11 01:40:54
机械工程师(2015年9期)2015-02-26 08:38:12
山东工业技术(2014年14期)2014-11-30 07:12:12
 CAAI Transactions on Intelligence Technology2016年1期
CAAI Transactions on Intelligence Technology2016年1期
- CAAI Transactions on Intelligence Technology的其它文章
- An efficient shortest path approach for social networks based on community structure☆
- Multi-LeapMotion sensor based demonstration for robotic refine tabletop object manipulation task☆
- A framework for multi-session RGBD SLAM in low dynamic workspace environment
- RPK-table based efficient algorithm for join-aggregate query on MapReduce
- Frame interpolation with pixel-level motion vector field and mesh based hole filling
- Exploiting structural similarity of log files in fault diagnosis for Web service composition