
基于引文分析的古籍文献影响力评估
2016-04-11 07:53马创新陈小荷
大学图书馆学报 2016年1期
马创新 陈小荷

摘要 介绍注疏文献的引用特点,并对注疏文献的引用情况进行分类。分析注疏文献引文分析的流程,提出利用学科本体和XML表示的注疏文献,解决引文分析中的难点。通过对《十三经注疏》中各部注疏文献之间的耦合分析,以及被引文献的同被引分析,尝试对古籍文献的影响力进行评估。
关键词 古籍文献 XML 本体 引文分析 评估
分类号 G255.1
DOI 10.16603/j.issn1002—1027.2016.01.002
1引言
中华文化源远流长,在这漫长的历史时期,产生了大量古籍文献。这些著作是中华民族精神文明的结晶,具有重要的文学价值、科学价值和历史价值。在当今时代,如何科学地评估古籍文献在中华文化中所处的地位和影响力,成为亟需解决的重大问题。
知识具有传承性、累积性、扩散性和创新性,任何新知识都不是凭空产生的,都是在前人研究的基础上创造出来的。文献作为知识的主要物质载体,它们显然都不是孤立存在的,而是具有密切联系的,它们之间的联系就表现在文献的相互引用上。因此,文献的相互引用是知识传承规律的表现,也是科学活动中普遍存在的一种必然现象。
引文分析就是建立在文献的引用与被引用关系基础上,运用数学、统计学和逻辑学等方法,对期刊、论文、专著等研究对象的引用和被引用现象进行计量分析,揭示出研究对象所具有的规律和特征,以及对象之间的关系,从而探寻科学发展的动态规律、评价科学现象和预测领域热点。
国外很早就在科学史、科学结构和科技管理等研究领域应用引文分析的方法。从二十世纪八十年代起,国内逐渐重视引文分析的研究,并且研制了多个用于科学管理的期刊引文索引数据库。当前国内外的引文分析在研究范围方面更加宽广,并且逐步增加研究深度,探索出了一些新的引文分析方法。
2古籍文献引文分析的相关研究
对于一般研究者来说,在阅读和理解古籍文献时会比较困难,所以对古籍文献做引文分析的多是文献学或者语言学的专家,他们的研究目的、关注的重点以及所采用的方法与当代图书情报学界的引文分析研究有较大区别。
1930年,洪业主持创办了我国第一个大型索引编纂机构——哈佛燕京学社引得编纂处,致力于编纂古籍索引,出版了《汉学引得丛刊》,共计64种81册。洪业等人的引得编制因书而异,对于先秦诸子和儒家重要经典,就编为逐字引得;对于考证名物的古籍,编作综合引得;对于注疏类文献,则编为引书引得。洪业等人编制的“注疏引书引得”有《春秋经传注疏引得》、《礼记注疏引书引得》、《周礼引得附注疏引书引得》、《尔雅注疏引书引得》等共计14种。他们编制这些引得的主要目的在于为研究者提供检索工具和辑佚线索。
何希淳在其1966年的硕士论文《礼记正义引佚书考》中,考证《礼记正义》引书中已经亡佚文献的作者生平、各书内容和前人辑存情况。叶程义在其1969年的硕士论文《<礼记正义>引书考》中,列举了《礼记正义》的引书种类,并且按照礼类、书类、易类、诗类等进行归类,把《礼记正义》引书的方式归纳为工5种,引书作用归纳为“申郑注”、“申经义”、“证郑注”、“证经义”、“存异说”等5种。王忠林的硕士论文《周易正义引书考》介绍了《周易正义》引书的种类、作用和方式,考证每种书的作者和流传情况,并且列出具体引书加以疏证。
班吉庆对刘宝楠的《论语正义》中引用《说文解字》阐述经义时的训诂特点进行了归纳和总结。马萃泽辑录了《五经正义》孔颖达疏中引用《说文解字》的全部引文内容,把引用体例归纳为全引、节引和叙引三类,并且把所辑录的引文内容与通行大徐本《说文》进行比对,考证其中存有差异的条目。安敏统计了孔颖达的《左传正义》的引书情况,将引书按经、史、子、集分类,统计出引书的书名和引用次数,分析了《左传正义》的引书形式和注疏重点。
综观上述古籍文献的引文分析研究,我们发现这些研究基本上都深入到引文内容层面进行统计、溯源、归类和比较,具有一定的研究深度。但是,当前古籍文献的引文研究总体上聚焦在微观层面的考证与辨析,没有明确地从技术角度人手做引文耦合及共被引分析,很少有利用引文分析探索科学史以及揭示科学结构等方面的宏观研究。
笔者以某一类古籍——“注疏文献”为研究对象,借助学科本体和结构化表示的注疏文献,通过引文分析,探索注疏文献中文献引用的规律和特点,从宏观层面挖掘引文分析在探索科学史和评估古籍文献影响力方面的价值。
3注疏文献的文献引用特点和分类
对比当代的论文和图书等文献的引用情况,我们认为,注疏文献的文献引用有三个特点:
(1)古籍文献是封闭性的信息资源。所谓封闭性资源,是指信息规模有限,不再随时间而增加,处于静止状态的信息资源。因为古籍文献的封闭性,它们的引文耦合、同被引等数据都已经固定不变,不像当代的期刊文献具备开放性,引文分析的各项数据还在不断变化之中。
(2)引用方式都是内容引用,没有列出参考文献。古籍文献并没有在文献末尾列出参考文献的惯例,其所引用的文献种类和引用次数只能到施引文献的内容中查找和统计。
(3)施引文献和被引文献都是图书,而没有论文。古代没有定期出版的刊物,还没有出现论文这种记录学术成果、并且能够快捷地提供给读者阅读的知识载体,所引用的文献都是书籍。
我们考察了《十三经注疏》的引用情况,对十三部注疏文献中的引用情况进行了综合、比较、分析和归纳,按照两个标准对注疏文献的文献引用情况进行分类。
(1)根据所引用对象的类型,可以把引用情况分为“典籍引用”和“其他引用”两大类。注疏文献中的典籍引用是指引用《论语》、《庄子》、《史记》、《汉书》、《说文》、《方言》等文献。除了引用典籍外,注疏文献中还大量引用训诂学家的看法和说解,这些说解没有按照原创作者的不同分别辑录成书,而是散录在多部注疏文献中。此外,还大量引用了散传的诗歌曲词等。
(2)根据引用方式,可以把引用情况分为“标明出处的引用”和“未标明出处的引用”。在注疏文献中,大部分引用都是标明了出处的,只有少部分没有标明。
4注疏文献引文分析的流程、难点和解决方法
4.1注疏文献引文分析的流程
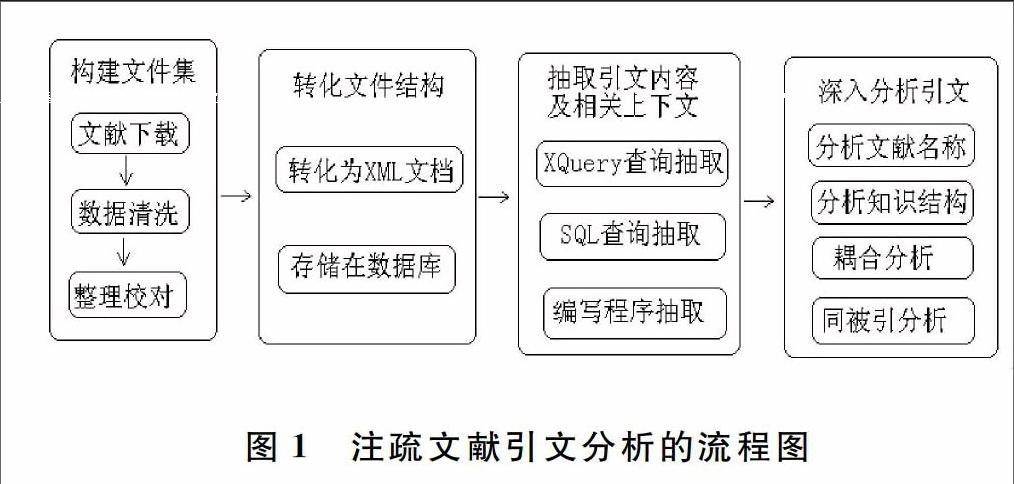
注疏文献的引文分析,实质上就是对注疏文献的引用内容、以及相关上下文进行分析。注疏文献引文分析的具体流程如图1所示,它主要包括四个步骤:
(1)构建文献集。构建文献集是进行引文分析的前提,主要包括文献下载、数据清洗和整理校对等工作。文献在下载和清洗之后,要进行相应地整理,包括修改文件名和合并文件等。另外,还要利用纸质古籍善本对文献做人工校对,以此来保证文献集具有可靠的质量。
(2)转化文件结构。转化文件结构是进行引文分析的基础,主要是把文献由非结构化或半结构化转化为结构化,以便于进行文本分析和知识挖掘。当前主流的结构化文件存储方式是使用数据库,或者以XML格式存储。由于XML技术能够把文献内容与表示结构信息的标签分离开来,不会影响文献在阅读方面的连续性,并且文献内容独立于显示方式,针对同一文献内容可以定义多种显示方式,所以XML比数据库更适合存储结构化的文献资料。
(3)抽取引文内容及相关上下文。这一步是进行引文分析的关键环节。在把文献由非结构化或半结构化转化为结构化表示后,如果文献是存储在关系型数据库中,能够使用SQL查询和抽取引文内容及相关上下文。如果文献存储为XML格式,可以利用XQuery检索和抽取,也可以自编程序实施抽取,编写程序前,首先要对文献中引文上下文的形式特征进行分析和总结,根据其区别特征编写抽取规则。
(4)深入分析引文。这一环节是进行引文分析的核心和重点,主要包括①区分各个引文内容是属于哪部文献,由于所引文献名称的具体写法存在多种方式,所以很难直接区分;②对所引文献按照不同的分类标准进行归类,以此来探索施引文献的知识结构;③对施引文献和被引文献进行文献耦合分析、同被引分析,探索它们之间的相互关系、共同特点和区别特征。
4.2注疏文献引文分析的主要难点
主要难点有以下两个方面:
(1)把注疏文献由普通文本转化为结构化的XML文档时,需要分析各部注疏文献的行文结构和内部知识单元,定义的XML架构要能够适应于所有的注疏文献,并且充分地表示出重要的知识,具有高度的结构化和模块性。另外,需要转化的文献规模很大,如果完全使用人工方式转化,成本会很高。
在抽取引文内容及其上下文时,首先要分析表示注疏文献知识结构的XML架构,总结文献中引文上下文的形式特征,然后根据区别特征定义规则进行抽取测试,并且分析抽取结果,改进抽取规则。要循环此流程,直至达到最佳的抽取效果。
(2)注疏文献中所引文献的名称存在多种写法,比如:《尔雅》、《释言》、《汉书。天文志》、《大雅·抑篇》、《诗.小雅.出车》等。还存在书名的异名同指现象,比如常称《周易》为《易》或《易经》、称《尚书》为《书》等。只有解决这个问题,才能正确区分出各个引文内容究竟是属于哪部文献。
4.3解决方法
4.3.1把注疏文献转化为结构化XML格式,以便于抽取引文内容
注疏文献的传统知识表示方法是面向人的理解的,使用计算机难以对其做检索和分析。而XML是表示结构化数据的行业标准,是万维网联盟定义的一种元数据,也是可以用来创建标记语言的元语言。近些年来,XML被广泛应用于古籍知识表示研究中。
XML没有预先定义的标记系统,允许开发者根据需要定义自己的标记系统。在使用XML标注语料时,标注者可以根据需要设计标记体系,详尽地标注出语料中的信息。当语料规模不断扩充,或者应用逐步深入时,XML能够适应需求的变化,很方便地扩展标记系统。为了能够使所定义的XML架构与表示对象的知识结构基本一致,我们从注疏文献的外部关联事物、内部体例结构和知识结构三个方面,对注疏文献的典型代表——《十三经注疏》做全面分析。在此基础上,设计了表示注疏文献的XML架构。这个XML架构简洁而又清晰,表现出了注疏文献的核心知识结构,能够根据需要进行扩展,具有较强的可扩展性。
把注疏文献由普通格式的文献转化为符合XML架构规范的XML文档的过程,也就是把它们的知识结构由半结构化转变为结构化的过程。要实现这种知识结构的转化,有多种方法可供选择,比如:手工方法、自动化方法、半自动方法等。我们在实施这项转化工作时,采用计算语言学方法,充分利用注疏文献的半结构化特征,依据人工制订的规则,编写程序实现注疏文献的半自动转化,提高了知识结构转化的工作效率。图2是用XML表示《论语集注》的样例。
注疏文献原本是半结构化的,现在由于转化成了结构化的XML格式,在原文中添加了有意义的标签信息,这就使得注疏文献更加便利于利用计算机进行分析和处理。在此基础上,能够开展多方面的研究。例如:设计更加智能、具有更高查准率的检索系统,实现多种类型、复杂条件的检索;在注疏引文与其经典原文的知识点之间自动设置锚点和链接,实现古籍文献的超文本阅读;等等。
4.3.2利用训诂学本体解决文献名称的异名同指问题
对于标明出处的文献引用,在所引文献名称的具体写法上,存在着多种方式。古代的刘炫做了总结,他认为“夫子叙经,申述先王之道。《诗》、《书》之语,事有当其义者,则引而证之,示言不虚发也。七章不引者,或事义相违,或文势自足,则不引也。五经唯《传》引《诗》,而《礼》则杂引,《诗》、《书》及《易》并意及则引。若泛指,则云‘《诗》曰、‘《诗》云;若指四始之名,即云《国风》、《大雅》、《小雅》、《鲁颂》、《商颂》;若指篇名,即言‘《勺》曰、‘《武》曰;皆随所便而引之,无定例也。”我们分析了《十三经注疏》的文献引用情况,归纳出注疏文献在标明所引用文献名称时的六种常用写法:
(1)给出文献名称,如《方言》、《尔雅》、《左传》、《庄子》等,即刘炫所说的泛指。
(2)给出章节名称,如《释言》、《释诂》、《大雅》、《泰誓》、《大宗伯》等,即刘炫所说的指四始之名。
(3)给出篇名,如《关雎》、《勺》、《武》、《多方》等。
(4)给出“文献名称+章节名称”或者“文献名称十篇名”,如《尔雅·释天》、《汉书·天文志》、《周礼·司服》、《周礼·司勋》、《史记·弟子传》、《史记·世家》、《礼记·少仪》、《诗·大雅》、《诗·唐风》等。
(5)给出“文献名称+章节名称+篇名”,如《诗·邶风·雄雉》、《诗·小雅·出车》、《诗·大雅。皇矣》、《周易·既济·象辞》、《周易·遁卦·象辞》等。
(6)给出“章节名称斗篇名”,如《大雅·抑篇》、《小雅·蓼莪》、《小雅·隰桑》、《乾卦·文言》、《夏官·司弓矢》、《地官·遂人职》、《卫风·硕人》等。
另外,注疏文献中在标明所引用文献名称时,经常出现异名同指现象,比如常称《周易》为《易》或《易经》、称《尚书》为《书》、称《诗经》为《诗》、称《春秋左氏传》为《左传》或<<左氏传》、称<<春秋公羊传》为《公羊》等等。
注疏文献在给出所引用文献名称时的六种常用写法中,第一、四、五种名称写法都含有文献名称,而第二、三、六种写法只有章节名称或篇名,却没有文献名称。除此之外,还存在文献名称的异名同指问题。
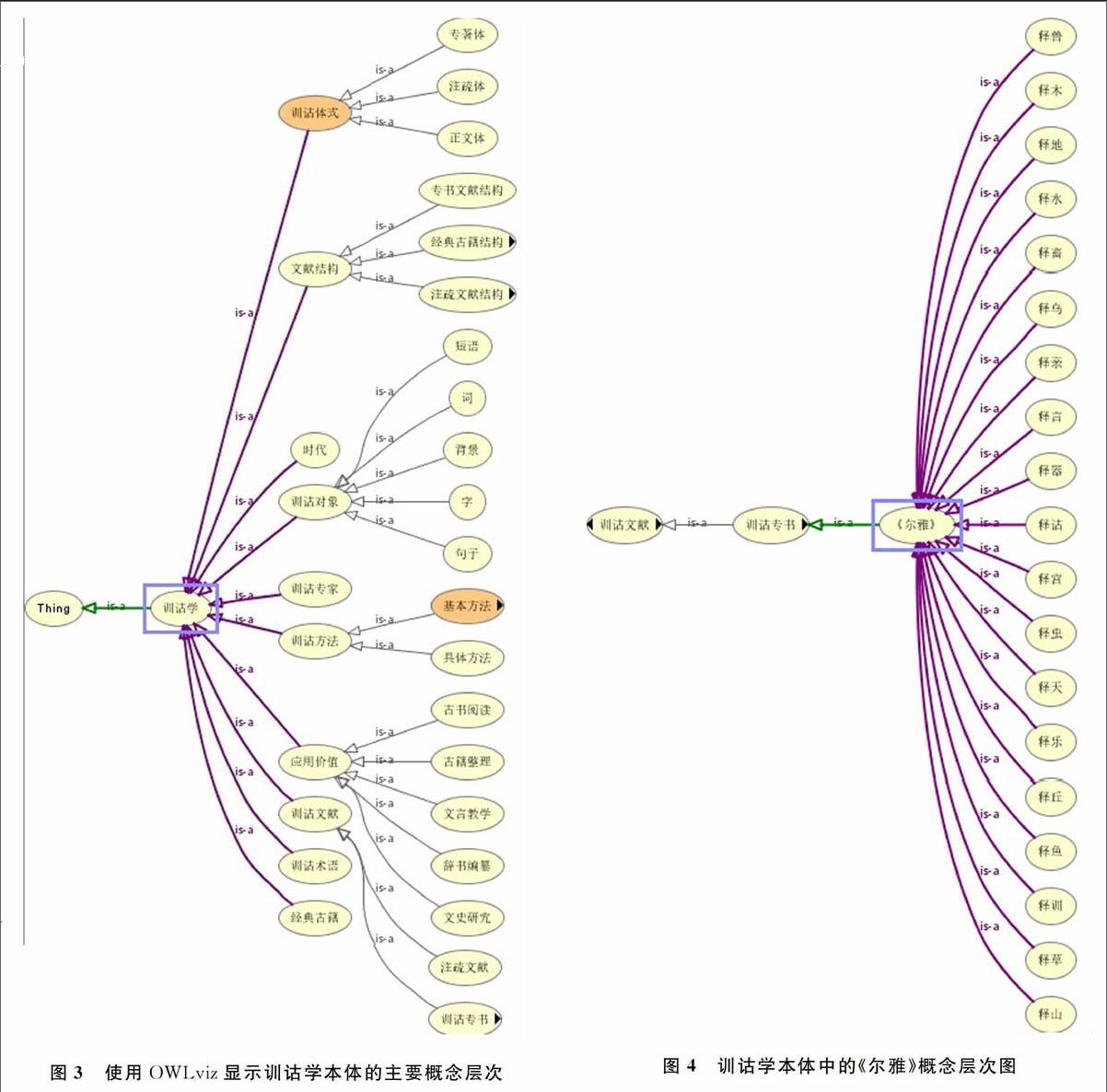
对于这些问题,我们使用“古籍文献名称知识库”来解决,该知识库不需要重新构建,它存在于“训诂学本体”中。为了用形式化方式表示训诂学领域的知识体系,利用本体思想重新检查和审视传统的训诂学知识体系,构建了“训诂学本体知识库”,它包含10个顶层概念、25个一级子概念、216个二级子概念以及众多的下级概念。使用Protege4.2编辑器,对训诂学本体进行编辑,生成OWL文件保存。图3就是使用Protege的图形插件OWLviz显示的训诂学本体的主要概念层次。
在训诂学本体的“经典古籍”和“训诂文献”两个顶层概念下,列出多部古籍文献的名称,以及各部古籍的章节名称和篇名。图4的是训诂学本体中的《尔雅》概念层次图。
在做注疏文献的文献引用自动分析时,如果发现使用书名号括起来的字符串,当不能确定它是指哪部文献时,甚至不能确定它是文献名、章节名,还是篇名时,就到“训诂学本体”的“经典古籍”和“训诂文献”两个顶层概念下进行检索和分析,以确定它究竟指的是哪部文献或者属于哪部文献。
5利用引文分析评估古籍文献的知识结构和影响力
《十三经注疏》包含了十三部注疏文献,所引用的文献种类极多,引用次数庞大,引用情况复杂。在注疏文献的各种引用类型中,“其他引用”所引用的内容主要是训诂学家说解,以及散传的诗歌曲词等。“典籍引用”所引用内容的来源复杂,包括多种类型的文献。“未标明出处的引用”所引用的内容一般字数较少,或者只是含义引用,而非原文引用,引用者在很大程度上对原文作了改写。“标明出处的引用”所引用的内容一般是原文引用,并且引用字数较多。所以,“标明出处的典籍引用”是注疏文献中的主要引用类型。
我们编写程序分析结构化表示的《十三经注疏》。为了能够在有限条件下得到较为精确的结果,我们的实验没有对《十三经注疏》中所有的引用情况做穷尽式统计,只统计和分析“标明出处的典籍引用”,对于仅仅提及而没引用其内容的典籍也不做分析。
5.1文献引用的总体情况和文献特点分析
《十三经注疏》中共有65045次提及文献名称、图画名称、舞蹈名称和乐曲名称等可以用书名号标注的名称,其中《周易正义》提及1565次;《尚书正义》提及3839次;《毛诗正义》提及13574次;《周礼注疏》提及8809次;《仪礼注疏》提及6363次;《礼记正义》提及11460次;《春秋左传正义》提及8528次;《春秋公羊传注疏》提及1951次;《春秋穀梁传注疏》提及1373次;《论语注疏》提及1255次;《孟子注疏》提及1467次;《孝经注疏》提及836次;《尔雅注疏》提及4025次。
我们对《十三经注疏》中“标明出处的典籍引用”情况做了统计,结果显示:引用文献总次数为27403次,被引文献达400多种。其中,被引次数排在前10位的文献是《礼记》、《周礼》、《诗经》、《尔雅》、《仪礼》、《尚书》、《周易》、《左传》、《说文》、《史记》。在这10部被引次数较多的文献中,除了十三经中的八部经书之外,还有一部训诂专书《说文》和一部史书《史记》名列其中,这说明了《说文》和《史记》分别在训诂专书和史书中的重要地位。
通过分析表1中各部注疏文献所引用的文献类型,我们能够对各部注疏文献所具有的知识结构特点有一个基本的了解。
《十三经注疏》各部注疏文献引用文献次数和种数如表2所示。《礼记正义>>引用的文献次数最多,达到5070次,同时它也是引用的文献种数最多的文献,引用了182种文献。《春秋穀梁传注疏》引用文献次数最少,只引用265次;而《周易正义》引用的文献种类最少,只有24部。
各部注疏文献引用文献次数和种数的多少,除了与其自身的篇幅大小有关之外,还与其各自的训诂特点有关。各部注疏文献在引用文献的类型、次数和种数等方面差别很大,通过分析它们的文献引用情况,可以基本判断出它们在训诂方式上的特点。接下来,以《春秋经》的三部注疏文献为例加以说明。
《春秋左传正义》引用文献次数和种数都比较多,并且大量引用《说文》的释义,《说文》在其所引用的133种文献中,按引用次数排在第八位,由此可以看出《春秋左传正义》注重对词语意义的解释,它通过解释词义来疏通句义和文意。相对而言,《春秋穀梁传注疏》引用史书的次数比较多,《史记》和《世本》在其所引用的50种文献中,按引用次数分别排名第九位和第十位,由此可见《春秋穀梁传注疏>>更偏重于介绍历史事件背景。《春秋公羊传注疏》引用文献61种,共引用文献383次,在引用次数较多的前十种文献中,既没有史书也没有字书,它的训诂特点是重视阐述句义。
5.2文献的耦合情况和知识结构相似度分析
我们分析了《十三经注疏》中各部文献之间的耦合情况,使用传统的耦合强度计算方法计算注疏文献之间的耦合强度,即:两部文献A与B之间的耦合强度就是它们引用相同文献的数量,如果A与B同时引用了m种文献,那么A、B之间的耦合强度就定为m。由此可见,耦合强度的高低,取决于施引文献之间引用相同文献的数量。反之,文献之间的耦合强度越高,说明它们引用的相同文献越多,在知识结构上的相同之处也越多。
在表3中,列出了在《十三经注疏》中各部文献之间的引文耦合矩阵。可以看出,在《十三经注疏》中,耦合强度最高的两部文献是《周礼注疏》和《礼记正义》,它们之间的耦合强度是97;而耦合强度最低的两部文献是《周易正义》和《孝经注疏》,它们之间的耦合强度是13。《十三经注疏》中各部文献之间的平均耦合强度是44.5。
经过分析,我们发现“耦合强度”与“知识结构的相似度”之间确有着正相关。《十三经注疏》中每部注疏文献都有两位或两位以上的注疏人,比如:《周易正义》是王弼、韩康伯注、孔颖达等正义;《礼记正义》是郑玄注、孔颖达等人疏。我们发现在这十三部注疏文献中,当两部文献有一个相同的注疏人时,这两部文献的耦合强度就会相对较高。以《周礼注疏》为例,与《周礼注疏》之间耦合强度最高的文献是《礼记正义》,我们发现这两部文献引用的文献种数都比较多,并且都是由郑玄作注;《孟子注疏》共引用文献59种,它与《周礼注疏》的耦合强度是34,《仪礼注疏》共引用文献57种,与《孟子注疏》引用文献种数相差不大,但它与《周礼注疏》的耦合强度就达到52,原因就在于《仪礼注疏》与《周礼注疏》这两部文献有着两个相同的注疏人,都是由郑玄注、贾公彦疏。
5.3文献的同被引情况和学术地位分析
对《十三经注疏》中“标明出处的典籍引用”情况做统计,结果显示:被引次数排在前25位被引文献是:《礼记》、《周礼》、《诗经》、《尔雅》、《仪礼》、《尚书》、《周易》、《左传》、《说文》、《史记》、《论语》、《释例》、《公羊传》、《汉书》、《春秋》、《穀梁传》、《世本>>、《孝经》、《方言》、《孟子》、《白虎通》、《广雅》、《国语》、《韩诗》、《字林》。
在十三部注疏文献中都被引用了的文献有10部,它们是:《礼记》、《周礼》、《诗经》、《尔雅》、《仪礼》、《尚书》、《周易》、《左传》、《说文》、《论语》。这十部文献的被引用次数也很多,在《十三经注疏》中共被引用了20261次,这十部文献均排在按照被引次数排名的前11位被引文献中。
把被引文献按照经、史、子、集等进行分类,我们发现在史书类文献中被引次数排在前四位的是:《史记》、《汉书》、《世本》和《国语》,可见这四部史书在训诂研究中有着重要价值。在小学类工具书中被引次数排在前四位的文献是:《说文》、《方言》、《广雅》和《字林》,由此可以看出,这四部训诂专书在中国训诂学研究中具有重要作用和地位。
6总结
利用结构化的注疏文献和训诂学本体解决了引文分析研究中的两个主要难点,顺利完成了引文分析,总结出《十三经注疏》中文献引用的总体情况,探讨了注疏文献之间的引文耦合情况,并且论述了文献的同被引情况。
引文分析能够揭示古籍文献的知识结构特点,估测古籍文献之间在知识结构方面的相似程度,评估被引文献在其所属类别文献中的地位。将传统人文学科与当代信息科学、文献计量学结合起来,不仅传承了古籍文献研究的历史成果,而且产生了一些新的研究思路和方法,能够为古籍文献的同类研究提供参考借鉴。
猜你喜欢
哲学分析(2023年4期)2023-12-21
中国音乐学(2020年4期)2020-12-25
文学教育(2016年27期)2016-02-28
质量与标准化(2015年9期)2015-07-10
浙江人大(2014年5期)2014-03-20
卷宗(2013年6期)2013-10-21
世界科学(2013年11期)2013-03-11
中国合理用药探索(2011年9期)2011-03-20
