
基于网络的中文未登录词译文挖掘方法研究
2016-04-09 06:15梁伍七董露露
安徽开放大学学报 2016年1期
关键词:数据挖掘
李 斌, 梁伍七, 马 宁, 董露露
(1.安徽广播电视大学 安徽成教在线服务中心,合肥 230041;
2.安徽广播电视大学 信息与工程学院,合肥 230022)
基于网络的中文未登录词译文挖掘方法研究
李斌1,梁伍七2,马宁2,董露露1
(1.安徽广播电视大学 安徽成教在线服务中心,合肥 230041;
2.安徽广播电视大学 信息与工程学院,合肥 230022)
摘要:为了获得较高的译文质量,提出了一种基于网络搜索的中文未登录词的翻译方法。该方法首先利用词典对未登录词进行扩展,然后将扩展查询词提交搜索引擎,从获取的中英文混合摘要中采用频度变化信息算法抽取译文候选,最后采用表层模板和频度右距离模型对译文候选进行排序。实验结果表明通过本方法进行中文未登录词译文挖掘是有效可行的。 对信息预处理的工作主要包括以下几个方面:剔除返回页面中的网页标识信息(如,
,等),获取摘要正文部分内容。对网页中的特殊符号进行相关的替换操作(如“&nbmp”换为空格字符串“”,“"”换为反斜线符号“”等)。为了获取一段较完整的英文字符串内容,需对该字符串中的非英文字符进行删除处理。关键词:未登录词翻译;数据挖掘;网络搜索;查询扩展
一、引言
中文未登录词(Out Of Vocabulary,OOV)一词的概念最早孙茂松教授最先提出。[1]它通常是指词典中未收录的词,包括各类专有名词(人名、地名、机构名等)、缩写词、各个领域的术语等,同时包括一些随着社会的发展而出现的新词。对中文未登录词的译文进行挖掘在中文信息处理中有着非常重要的作用,如在跨语言信息检索、问答系统、机器翻译系统中,中文未登录词译文翻译的准确性将对应用系统的性能产生很大的影响。同时,由于这些词的译文无法从词典中直接获得,如采用人工翻译的方法将费时费力。因此,对中文未登录词的译文进行挖掘并提高挖掘的准确率,是非常重要的研究工作。
随着互联网技术的高速发展,研究人员利用网络资源提出了多种方法进行OOV译文资源挖掘。根据所使用的资源不同,主要的翻译方法可分成基于双语语料库的翻译方法和基于网络搜索引擎的翻译方法,基于双语语料库的方法是从双语语料库中抽取翻译对用于查询翻译。根据使用语料库的不同可分为平行网页资源和可比较语料资源,在2002年Chang等利用平行语料来获取中英文翻译对[2]。为了获得更多的平行语料,Smith和Resnik在2003年利用STAND系统从Web页面获取平行网页资源[3], Koehn[4]和Liang[5]等将平行语料库用于统计机器翻译的训练语料,并取得非常好的翻译性能。与平行语料不同,可比较语料是指对同一事件的多种语言的描述,这些描述并非是完全互译的,但可用来进行译文的抽取或其他的自然语言处理方面的工作,Diab等利用可比较语料库提出基于字级别的统计翻译模型[6],Alegria等在可比较语料库的基础上对命名实体的翻译进行了相关研究工作[7],Kaji利用可比较语料将日语中专业术语翻译成英语[8]。利用网络直接进行挖掘译文的方法是根据同一个网页上存在着两种或多种语言,例如在一个中文网页上可能存在一个术语后面标有原始英文翻译。再如,学术论文中的中文与英文摘要。Cheng利用网络来构建多种语言的翻译词典[9],Shia采用基于混合网络的方法来对专有名词的翻译进行改进[10],Huang等从网络资源中挖掘关键词的译文[11],Lu等根据网络资源对英汉翻译候选进行了消歧研究[12],Denkowski利用网络对机器翻译的结果进行改进[13]。
本文提出了一种基于网络搜索的中文未登录词的翻译方法。该方法不需要利用平行语料或可对比语料库资源作为训练集,而是直接利用互联网上存在的大量多种语言混合的网页,通过设计相关挖掘算法来获取所需要的译文。与上述方法有些不同,没有直接使用那些网页,而是通过搜索引擎的搜索获得返回的包含双语信息的摘录,我们可以从中进行相关的译文挖掘研究。
二、实验设计与算法
(一)实验框架
利用网络搜索引擎进行未登录词译文挖掘流程图如图1所示,我们首先利用词典对要翻译的未登录词的子序列进行翻译,接着将该子序列的翻译和未登录词一起提交搜索引擎,然后根据返回的含有中英文的摘要信息采用改进的频度变化信息算法抽取相关译文候选,最后通过频度-距离模型与表层模板特征相结合的方法对译文候选进行排序。
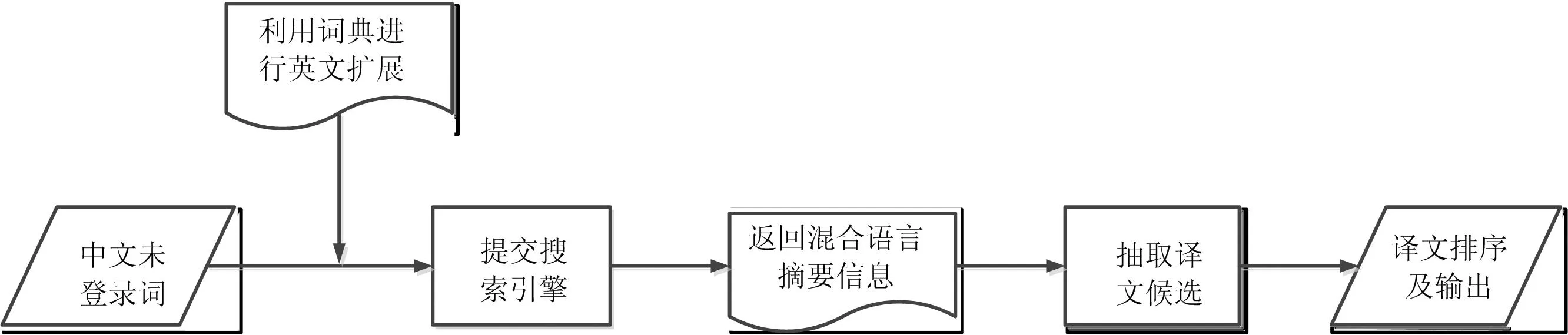
图1利用网络挖掘未登录词译文流程图
(二)未登录词英文扩展
利用搜索引擎进行搜索时,如果提交的查询词是单一语种时,则返回的结果中包含单一语种的链接或页面比较多,如果直接将中文未登录词作为查询词提交到搜索引擎,而返回结果中可能不包含英文,我们也就无法从中挖掘出英文译文。而如果将未登录词译文的一部分连同该词一起(对查询词进行了扩展)提交到搜索引擎,则返回的页面中既包含该词以及其英文翻译的一部分,这样就为我们挖掘其该未登录词的译文提供了来源(如图2)。我们可以从包含该未登录词和部分英文翻译的混合网页摘要中,通过设计算法来获取对应的译文。

图2扩展后查询词提交搜索引擎返回页面图(2015-11-02)
实验采用“逆向最大匹配算法”对输入的中文未登录词进行英文扩展,具体算法如下:
输入:中文未登录词ChQuery
输出:扩展后的关键词(中文关键词+英文扩展)ExpQuery
步骤:
SubSeq=ChQuery//SubSeq为ChQuery子序列
while (SubSeq is Not NULL) {
if (汉英词典中找到SubSeq的译文EnSubSeq) {
ExpQuery=ChQuery+EnSubSeq
returnExpQuery
}
SubSeq=SubSeq减去第一个汉字
}
(三)挖掘译文生成译文候选
针对返回结果进行译文的挖掘需要经过以下三个步骤的处理,首先需要对搜索引擎返回的摘要信息进行预处理。然后筛选出含有英文扩展的译文候选,最后将字符串按表层模板特征和频度-距离模型相结合的算法进行计算并排序。
1.搜索引擎返回摘要信息预处理
2.筛选出含有英文扩展的译文候选
相对于互信息、局部最大值等方法从语料库中抽取多词候选单元,频度变化信息方法[14]更能有效地从篇幅较短的页面摘要信息中抽取相关信息,该算法主要是基于以下考虑:在一个合法的译文候选中,译文中每个单词出现的次数应该是约为相同的。如果一个合法候选译文中用的是不正确的译文扩展,那么扩展后的单元频度会较低。频度变化信息方法如公式(1)所示:
(1)
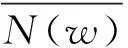
3.译文候选排序
在阅读科技文献时,我们经常会看到作者在第一次使用术语时会将其英文翻译以及缩写标注在括号中,例如:“未登录词(Out Of Vocabulary,OOV)”。在这里“(”可以作为识别后续英文字符串即为前面中文字符串译文的主要特征之一,这些符号信息我们称之为表层模板。实验通过将不同的中英文词对提交搜索引擎获取摘要信息后,然后从这些摘要中自动获取表层模板,我们将几种典型的模板按照出现次数的多少排列如表1。

表1 中文科技文中典型表层模板
表1中L1和L2互为两种不同的语言(如L1为中文,L2则为英文,反之亦可)。如果一个译文候选单元和源查询词匹配了较多的表层模板,那么该译文候选作为正确译文的概率则较大。具体计算如公式(2)所示:
(2)
其中,s是源查询词,即中文未登录词,t为源查询词的某译文候选单元,N为源查询词s和候选单元t匹配的模板总数,maxN为源查询词s与所有候选中匹配次数的最大值。
在获取的所有摘要页面中,如果某一译文候选出现的频度越高,我们认为其为正确译文的概率越大,同时,如果某一译文候选出现在中文未登录词的右边,且它们之间的字符距离越近,则它们互为译文的概率也越大。基于这两点考虑,我们提出了频度右距离模型,如公式(3)所示。
(3)
其中,s为源查询词,t为源查询词的某译文候选单元,rdi(s,t)为译文候选t第i次共同出现在源查询词s与右边的距离,k为s与t共同出现的总次数,max(rd)为t出现在s右边时的最大距离。
译文候选排序最终模型综合考虑表层模板特征和频度右距离模型,模型如公式(4)所示。
(4)
其中,PE(s,t)表示译文候选t是中文未登录词s的最终概率,λ1,λ2分别表示表层模板模型和频度右距离模型的参数。
三、实验结果与分析
(一)网络查询词译文挖掘
实验从NTCIR(网址为ttp://research. nii.ac.jp/ntcir/)选取NTCIR4, NTCIR5中未知中英双语词典中收录100的词条(即未登录词)进行测试。采用TOPN包含率作为评价标准,TOPN的定义如公式(5)所示:
(5)
实验分别表层模板模型,频度右距离模型以及两者结合的方式最终的译文候选进行了选择,实验结果如图3所示。
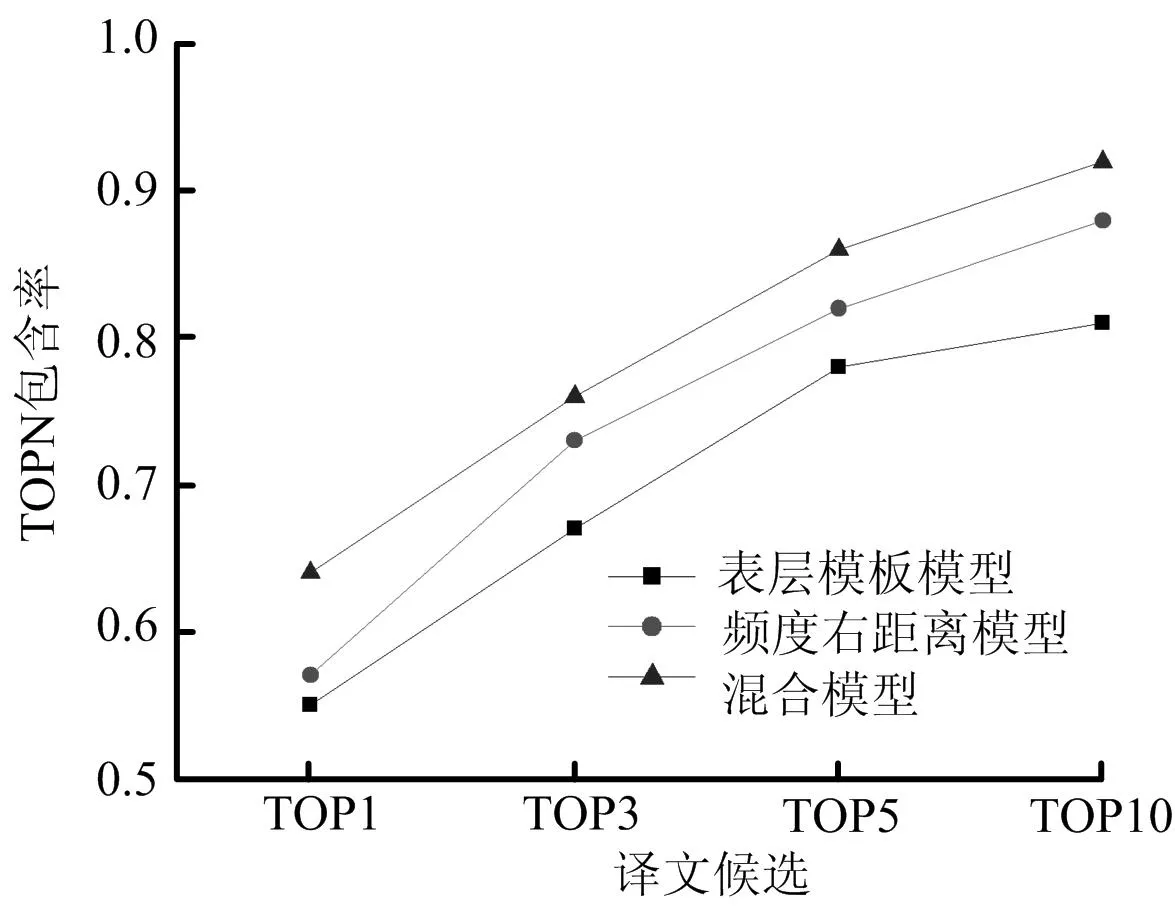
图3 不同译文候选方法实验结果比较图
从图3我们可以看出,利用表层模板模型和频度右距离模型都取得了较高的包含率,其中TOP1的包含率分别为55%和57%,随着译文候选数量N的增加,包含率不断提高,其中TOP10的包含率分别达到了81%和87%。将这两种模型进行有效混合后,正确译文的包含率有所提高,其中TOP1和TOP10的包含率相对于频度右距离模型提高了19%和11%;相对于表层模板模型提高了7%和4%。虽然仍有部分词未能在TOP10译文候选中找到正确的译文,这主要是由于这些词在网络中使用较少,导致获取的摘要资源基本为单一中文语种,从而不能获取有效的英文译文候选。
(二)命名实体译文挖掘
命名实体作为未登录词的一部分,通常包括人名、地名和组织机构名等。实验过程中,我们也对命名实体中的组织机构名的译文进行了挖掘。实验的语料是教育部直属的前100所学校中文名称,我们通过实验挖掘它们的英文名称,然后与它们的实际英文名称相对比来判断挖掘结果是否正确。实验结果如表2所示。

表2 不同译文候选对应TOPN包含率表
从表2中我们可以看出,随着译文候选数量的增加,TOPN包含率不断提高,当译文候选TOPN的个数为3时,获得的TOPN包含率就达到了90%以上,而当TOPN为5时,包含率达到了96%。对于结果中未能正确翻译的未登录词主要原因包括以下几个方面:(1)在翻译过程中中文名称与英文名称不完全对应,英文名称中可能会增加或减少单词。(2)在翻译过程中部分词的音译情况未能很好地解决。(3)网页中存在错误的译文也可能造成不能未能获取正确的译文等。
四、总结与展望
本文提出了一种基于网络的未登录词的译文挖掘方法,实验利用词典对要翻译的未登录词采用“逆向最大匹配法”的方法进行英文扩展,然后将扩展的查询词提交搜索引擎,根据返回的含有中英文的摘要信息采用频度变化信息算法抽取相关译文候选,并结合表层模块特征和频度右距离算法对译文候选进行排序。从实验的结果来看,本文的译文挖掘方法取得了较好的效果。
同时,在今后的研究中我们可以从以下几个方面对实验进行改进:(1)扩充本地词典包含的双语词汇数量,从而使未登录词能获得更好的扩展。(2)探索算法解决未登录中的音译问题。(3)尝试改进算法更有效的获取译文候选以及对译文的排序。
参考文献:
[1]孙茂松,邹嘉彦.汉语自动分词研究评述[J]. 当代语言学, 2001(1): 22-32.
[2]CHANH B, DANIELSSON P,TEUBERT W.Extraction of Translation Unit from Chinese-English Parallel Corpora[C]// Proceedings of the first SIGHAN workshop on Chinese language processing, Morristown, NJ, USA:Association for Computational Linguistics, 2002:1-5.
[3]SMITH N A, RESNIK P.The web as a parallel corpus[J]. Computational Linguistics, 2003, 29(3):349-380.
[4]KOEHN P.A parallel corpus for statistical machine translation[J]. Proceedings of the Third Workshop on Statistical Machine Translation, 2004(1):3-4.
[5]TIAN L, WONG D, CHAO L, et al. UM-corpus: A Large English-chinese Parallel Corpus for Statistical Machine Translation[C]// Proceedings of the 9th International Conference on LanguageResources and Evaluation,2014:1837-1842.
[6]DIAB M, FINCH S. A Statistical Word-Level Translation Model for Comparable Corpora[C]// Proceedings of the Conference on Content-based Multimedia Information Access RIAO,2000.
[7]ALEGRIA I,EZEIZA N,FERNANDEZ I.Named Entities Translation Based on Comparable Corpora[C]//Proceedings of the 11th Conference of the European Chapter of the Association for Computational Linguistics,Workshop on Multi-word Expressions in a Multilingual Context,Trento,Italy,2006:1-8.
[8]KAJI H,TSUNAKAWA T,KOMATSUBARA Y.Improving Compositional Translation with Comparable Corpora[C]//Proceedings of the 5th Workshop on Building and Using Comparable Corpora,2012:134-42.
[9]CHENG P J, PAN Y C, LU W H, CHEN L F. Creating Multilingual Translation Lexicons with Regional Variations Using Web Corpora[C]//Proc. Of ACL,2004:535-542.
[10]SHIA M S, LIN J H, YU S, et al. Improving translation of unknown proper names using a hybrid web-based translation extraction method[J]. Rocling,2005.
[11]HUANG F, ZHANG Y, VOGEL S. Mining key phrase translations from web corpora[J]. IEEE Journal on Selected Areas in Communications, 2005:483-490.
[12]LU C, XU Y, GEVA S, et al. Translation disambiguation in web-based translation extraction for English-Chinese CLIR[J]. Clir, 2007:819-823.
[13]DENKOWSKI M, LAVIE A. TransCenter: Web-Based Translation Research Suite. In Workshop on Post-Editing Technology and Practice Demo Session. San Diego, 2012. Retrieved from http://www.cs.cmu.edu/~ mdenkows/transcenter/
[14]葛运东.跨语言信息检索查询翻译技术研究[D].苏州:苏州大学,2010:26-41.
[责任编辑李潜生]
The Translation of Chinese OOV Based on Web
LI Bin1,LIANG Wu-qi2,MA Ning2,DONG Lu-lu1
(1.Center of Anhui Continuing Education Online, Anhui Open University, Hefei 230041, China;2.College of Information Science and Engineering, Anhui Open University, Hefei 230022, China)
Abstract:Translation of Chinese out of vocabulary (OOV) is very important in the research of cross-language information retrieval and machine translation and so on. In order to obtain the high quality of translation, an approach of OOV translation based on the web has proposed. The expanded query terms which has been extended by dictionary should be submit to search engine together, and the candidates of translation would be extracted by frequency change algorithm, the models of surface template and frequency right distance are used to sort those candidates in the end. Experimental results show that the method of translation of OOV by web corpus is feasible.
Key words:translation of OOV; data mining; web search; query expand
中图分类号:TP391
文献标识码:A
文章编号:1008-6021(2016)01-0116-05
作者简介:李斌(1983-),男,安徽怀宁人,硕士,讲师。研究方向:数据挖掘,自然语言处理。
基金项目:安徽省教育厅自然科学基金重点项目“基于翻译模型和网络挖掘相结合的命名实体翻译方法研究”(项目编号:KJ2014A081);安徽广播电视大学优秀青年基金项目“基于网络的未登录词译文挖掘研究”(项目编号:qn11-19)。
收稿日期:2015-11-03
猜你喜欢
九江学院学报(自然科学版)(2022年2期)2022-07-02
大众投资指南(2021年35期)2021-02-16
北京航空航天大学学报(2020年10期)2020-11-14
中国交通信息化(2020年1期)2020-07-27
新疆大学学报(自然科学版)(中英文)(2020年2期)2020-07-25
电力与能源(2017年6期)2017-05-14
电子技术与软件工程(2016年24期)2017-02-23
现代电子技术(2016年15期)2016-12-01
信息通信技术(2015年6期)2015-12-26
西安工程大学学报(2014年2期)2014-02-28
