
音频哼唱检索技术的设计与实现
2016-04-09 02:03:30天津广播电视台石家瑞
电子世界 2016年5期
天津广播电视台 石家瑞
音频哼唱检索技术的设计与实现
天津广播电视台 石家瑞
【摘要】通过文字输入音频属性信息进行音频检索无法满足通过音乐的旋律进行检索的需求,因此基于内容的音频检索应运而生。研究、设计并实现一套基于内容的音频哼唱检索技术,对音频进行分割处理,基音提取,旋律编码和旋律匹配,完成音频搜索。在实验中,通过对输入语音的处理、匹配,以85.5%的相似度成功检索出目标音频,为今后音频哼唱检索技术的实际应用提供依据和保证。
【关键词】音频;哼唱;检索技术
0 引言
随着数字化和网络化的快速发展,音频的检索已经随着大众的需要从一维扩展到多维。传统的音频检索需要用户输入音频的属性信息,包括名称、演唱者、年代等文本信息进行检索,然而用户熟悉某些歌曲的旋律和风格,但是并不知道名称和主唱,运用传统的属性信息进行检索无法满足他们的需求。因此,通过音频内容进行检索的方法应运而生。哼唱检索作为基于内容的音频检索的一种,需要用户哼唱某一段音乐,这段音乐作为一种非语义符号表示且非结构化的二进制码流输入到计算机中,通过搜索引擎去寻找一些歌曲,并将歌曲中包含用户所哼唱的旋律和风格的歌曲反馈给用户。
本文详细研究并介绍了哼唱检索的流程和所用方法,并通过程序演示,以实验形式完成了哼唱检索过程。
1 哼唱检索流程
哼唱检索的流程是:用户通过一个麦克风哼唱一段音乐,这段音乐以音频数据的方式被采集到了计算机里面,被分割成一个个片段,这些片段又分别对应了一个个的音符[1]。之后就能找出这些片段的基因频率,获得哼唱片段的旋律信息,将哼唱的旋律信息与音乐库中音乐的旋律信息进行匹配比较,并将相关度最高的一首或几首乐曲作为检索结果返回给用户,流程如图1-1所示:
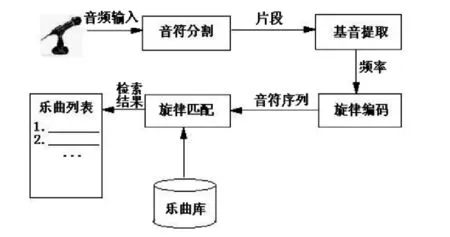
图1-1 哼唱检索流程
2 哼唱检索方法
2.1音频切割
音频分割的方法是:在得到输入信号的对数能量曲线之后,对其进行平滑处理,再由曲线的极值求出有声区的能量阈值,接着就能根据音符的对应关系将输入信号分割成小片段,图2-1所示。
这种分割方法要求用户在每个音符直接按留出一定的空隙,但这种要求不一定都会满足,因为用户发音不准或者哼唱的很连贯,各个音符之间没有停顿,就无法在能量上来区别各个音符,这都会导致这种方法的失效或者不理想。但是人们通过实验发现,音频的倒谱的峰值随着时间也有起伏,而且能够反映出静音和非静音的边界,如图2-2所示,所以在进行音频分割时一般综合考虑能量曲线和倒谱峰值曲线,这样能够得到最好的分割效果[2],如图2-3所示。

图2-1 能量曲线以及音符分割结果

图2-2 倒谱峰值曲线

图2-3 能量曲线和倒谱曲线综合考虑的结果
2.2基音提取
音符分割完成以后,就要进行基音的提取了。人类声音的频率一般大于60Hz,而小于1000Hz,所以可以利用哼唱信号良好的周期性特性,采用时域的自相关方法,来求取每一帧哼唱信号的基频信息,然后再将其转换成半音单位[3]:
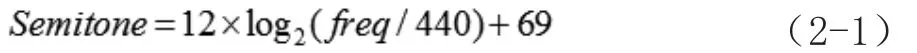
其中,freq是以Hz为单位的基频值。
半音是音乐中常用的表示音高的单位,MIDI中所采用的音高表示也与此相同。接下来的计算方法所采用的音高单位都是半音。
一般一个音符都包含若干个帧,在得到每一帧的音高之后,可以采用加权求特征值的办法来求得每个音符的特征值,比如一个音符由n帧组成,这些帧的编号为,则每一帧的权重系数为[4]:

采用自相关算法对哼唱信号进行基音提取的流程如图2-4所示。

图2-4 基音提取流程
一般情况下是用固定长度的窗来对语音信号进行分帧的,然后再计算每一帧的基音周期。但是汉语的语调会发生变化,因而基音周期的变化范围也很大,如果用固定窗长来进行计算,得不到良好的短时特性。鉴于此,可以采用长度可变的窗来进行计算,因为相邻帧的基音周期变化不大,所以可以把每一帧的窗长设为前一帧窗长的3倍。
2.3旋律编码
在得到哼唱数据的基音信息之后,就需要根据各个音符的音高来进行旋律编码了。旋律编码是指在进行音乐检索时,把输入音频以及音频库中的音频的乐曲旋律用一种中间形式来表示出来,比如音符序列。旋律编码完成之后,就可以采用这种中间形式的数据来进行匹配计算了[5]。
为了降低检索的难度,在进行旋律编码时,可以在音高这个检索特征之外再加上一个节奏特征,也即每个音符的时间信息,这样一来使用双特征来进行检索,效率更高,困难程度也降低了。根据一般人的哼唱特点,在采用节奏信息时,只考虑每个音符的出现时间,而不考虑它们的结束时间。
2.4旋律匹配
旋律编码完成之后,就可以进行旋律匹配了,线性对齐匹配法的具体思路是[6]:先把两段旋律在时间轴上伸展到相同的长度,然后把它们发声时刻接近的音符对齐,分析旋律在节奏上的相似性之后,继续比较两段等长旋律在每个时间点上音高频率的距离。因为采用的是音高差值来作为检索特征的,所以就可以忽略哼唱者的音调高低问题。然后把节奏和音高两方面的信息综合考虑就能够很容易得到相似度的匹配结果了。
因为检索特征是节奏和音高的组合,假设为(P,T),经过旋律编码得到的旋律序列为,而音频库中的旋律为。其中,P和Q表示音高差,T和U表示音符发声时刻,而且:

(2-3)中第一个式子可以通过前面的说明很容易的得出,第二个约束条件规定了两段旋律的音符数不能相差过多。
2.4.1节奏匹配
在进行节奏匹配时,首先要将(P,T)在时间上进行线性变换,和(Q,U)对齐,然后通过对齐的音符总数占总音符数的比例来确定两段旋律在节奏上的相似度。假设变换后的音符序列为(R,V),其算法如下[7]:
①初始化:

②线性变换:
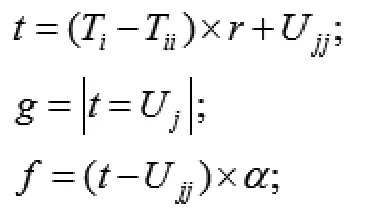
③对齐判断:

跳转到④,否则跳转到⑤。
④将(P,T)的第i个音符与(Q,U)的第j个音符对齐。

跳转到⑥。
⑦计算节奏相似度,结束。

对齐的音符数占总音符数的比例就是节奏上的相似度。一般情况下旋律的首尾音符都是对齐的,所以计算时把首尾的4个音符去掉。其中的a表示对齐误差,经验值为0.3。也就是说如果两个音符在时间上的距离小于其音符延时的30%,就可以认为它们是对齐的[8]。
2.4.2高音匹配
节奏匹配完成后,就可以进行音高的匹配了。经过上面的运算,(P,T)转换成(R,V),其中(R,V)和(Q,U)在时间上完全等长。音高的匹配过程就是比较(R,V)与(Q,U)在对应时刻上的音高差值。和节奏相似度一样,音高的相似度也是根据音高接近的旋律片段占总旋律的比例得到的。其计算过程如下:

表3-1 输入音频的特征序列表
①初始化。
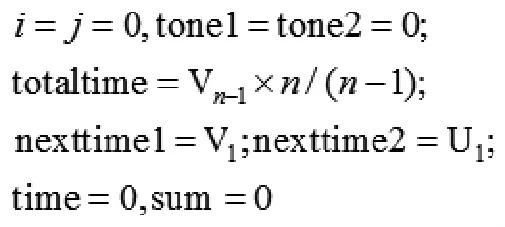
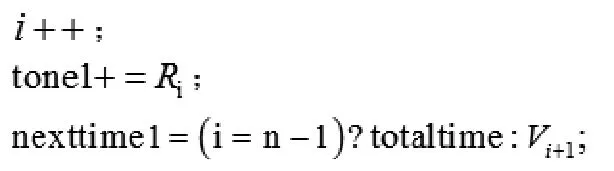
跳转到②;

跳转到②;
⑤计算音高相似度,结束。

旋律的节奏信息只是记录了音符的开始时间,并没有记录它的持续时间或结束时间,因此最后一个音符的长度一般设定为前面音符的长度的平均值。其中函数的定义如下:

节奏匹配和音高匹配完成之后,把它们的数值相加,就能得到两段旋律的总匹配度:
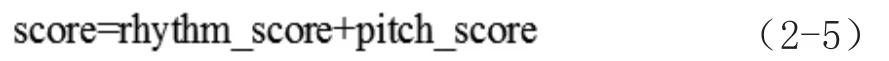
至此,哼唱检索的所有算法都已完成,只要将哼唱输入的旋律信息与音频库中的音频的旋律信息进行匹配比较,并将其中匹配程度最高的几首音频作为最终结果反馈给用户,就完成了了一次完整的哼唱检索。
3 实验分析
3.1实验准备
音频检索程序是在Microsoft Visual Studio平台下用C++语言开发的一套对输入音频特征序列提取、特征值比对的程序,通过该程序可检索出与输入音频特征匹配的目标音频,以完成搜索任务。
测试音频均为WAV格式。从话筒哼唱一段音乐并保存,记录音频为test-fragment.wav,该音频作为音频检索的输入数据源。乐曲库中保存了大量WAV格式的乐曲和音频,作为检索库中的被检索数据源。
3.2实验过程
从输入音频提取特征值,整理成特征值序列表,与乐曲库中的各个乐曲特征序列表比对,找到相似度最高的乐曲,即为检索结果。
首先,对输入音频进行分割,以512Byte为一个片段,输入音频被分割成1347个片段,计算512bit×1347≈689kB,实际的输入音频为674KB,略小,原因是在切割过程中每个片段加入了相应的校验和序号信息,便于后续处理。
3.3实验结果
经过FFT变换和转码等一系列过程,提取出输入音频的特征值如表3-1所示。
表3-1列出了输入音频的特征值序列。其中,“帧序列”表示提取特征值所在的片段,位数从1至1347;“字节位”表示在该帧序列中所在的字节位,位数从1至512;“特征值”表示相应的能量特征值。
从乐曲库中每条歌曲对应的特征序列表,与输入序列按照指定的帧序列的字节位进行比对,找到与相应字节位特征值差异最小的特征序列,该特征序列所对应的乐曲即为检索结果。图3-1列出了检索音频帧序列误差分布。大部分误差集中在20%以内,少数误差高达50%,出现误差的原因是由于哼唱音频的音调、音色、节奏因个人嗓音的不同和节奏的把控而产生差异。误差平均值为14.5%,即音频相似度达85.5%。而音频的检索结果也正是哼唱者所要查找的音频。

图3-1 音频帧序列误差分布图
4 结束语
基于内容的音频哼唱检索,实现了将音符分割成若干片段,对每个片段进行基音提取,对提取出的频率进行旋律编码形成特征值序列,并与乐曲库的歌曲进行特征值序列匹配,返回检索结果。通过编写程序并运行音频实例,实现了基于哼唱的音频检索实验,匹配率高,为今后哼唱检索在实际中的应用提供依据和保证。
参考文献
[1]潘复平,赵庆卫,颜永红.一个基于语音识别的音频检索系统的实现[J].声学技术增刊,2005,24:428~432.
[2]岁骏,欧智坚.一种高效的语音关键词检索系统[J].通信学报,2006,27(2):113~118.
[3]A.V.奥本海姆,R.W.谢弗.数字信号处理(董士嘉,杨耀增)[M].北京:科学出版社,1980,45~46.
[4]Reynolds DA,Rose RC.Robust.Text-independent Speaker Identification Using Gausian Mixture Speaker Models.IEEE Speech and Audio Processing,1995(1):72~83.
[5]吴春辉,黄胤科,钟宝荣.基于内容的音频检索技术[J].现代计算机(专业版),2006,4.
[6]L.A.Smith,R.J.McNab.I.H.Witten.Music Information Retrieval Using Audio Input.Proc AAAI Spring Symposium on Intelligent Integration and Use of Text, Image,Video,and Audio Corpora,Stanford,CA,1996:12~16
[7]R.J.McNab,L.A.Smith,I.H.Witten,C.L.Henderson,Cunningham S.J. Towards the Digital Music Library:Tune Retrieval from Acoustic Input.Proc Digital Libraries’96,1996:11~18.
[8]李国辉等,基于内容的音频检索与分类[J].计算机工程与应用,2002,(7):54~57.
石家瑞(1977—),男,天津人,高级工程师,现供职于天津广播电视台,研究方向:广播电视工程。
作者简介:
猜你喜欢
音乐生活(2024年1期)2024-03-13 08:07:58
乐府新声(2021年1期)2021-05-21 08:09:14
阅读(低年级)(2020年10期)2020-01-07 14:02:49
成都信息工程大学学报(2019年1期)2019-05-20 09:14:16
作文小学中年级(2019年4期)2019-04-25 02:29:54
计算机应用(2018年8期)2018-10-16 03:14:18
学与玩(2017年5期)2017-02-16 07:06:28
读写算(上)(2016年9期)2016-02-27 08:44:58
小演奏家(2014年11期)2014-12-17 01:18:52
数据采集与处理(2014年2期)2014-07-25 04:28:08
