
SPSS中判别分析的使用
2016-03-23 02:56瞿健菊
文教资料 2015年34期
关键词:语言学
瞿健菊


摘 要: 判别分析是多元统计分析中最常用的方法之一。该文结合一个语言学实验的例子对SPSS判别分析的操作步骤和输出结果作了详细的介绍,并对判别分析的不同方法在SPSS中的使用进行了区分。
关键词: SPSS 判别分析 语言学
1.引言
判别分析是多元统计分析中判别样本所属类型的一种常用方法。它的研究对象是训练样本,也就是说原始数据的具体分类是事先已知的,然后根据原始数据求出判别函数将待判样本的数据代入判别函数中判断其类型。[1]常用的判别分析方法主要有:距离判别法、Fisher判别法和Bayes判别法。然而,在SPSS操作中只能实现Bayes判别法与Fisher判别法两种,并且这两种方法的操作是合在一起进行的,所以使用起来需要特别注意。[2]下文将结合一个语言学实验的例子对SPSS判别分析的步骤和输出结果作详细解释和说明。
2.语言学实验
2.1实验背景
Fletcher和Peters(1984)研究发现,可以用语法和词汇两个维度来刻画语言受损儿童在语言表达方面的特征。被试分为两组,一组是20个正常儿童(LN),另一组是用标准化测试尺度在年龄和智力活动方面跟LN组相比而诊断为语言受损的9个儿童(LI)。在标准条件下收集他们的自发的语言数据(LN组的年龄均值为60.86个月,LI组的年龄均值为62.33个月)。围绕65个语法与词汇范畴——大部分引自Crystal、Fletcher和Garman(1976),每组儿童提供的样本都包括200个话语的得分。其中一个语法变量是根据无标记动词形式——既无后缀又无助动词修饰的实义动词词干——的个数来评分的。另外一个词汇范畴是动词词型,即一个儿童在样本中使用不同的实义动词的个数。[3]
2.2数据录入
本文使用的SPSS为20.0版本。首先建立一个数据文件linguistics.sav,将Fletcher和Peters所提供的每个被试的数据录入进去。数据文件的变量视图和数据视图分别如图1和图2所示。在变量视图中,定义变量Y(分类)的值标签,-1为语言受损,1为正常。在数据视图中,共29行数据,分别为29个被试儿童在x1和x2这两个变量上的得分及所属类别。
图1 变量视图
2.3判别分析步骤
①单击“分析”→“分类”→“判别分析”,从对话框左侧的变量列表中选中进行判别分析的变量“无标记动词形式[x1]”和“动词词型[x2]”进入“自变量”框,作为判别分析的基础数据变量。从对话框左侧的变量列表选中“分类[Y]”进入“分组变量”框,并单击“定义范围”按钮,在“定义范围”对话框中,定义判别原始数据的类别数,在最小值处输入-1,在最大值处输入1。分析方法按默认的“一起输入自变量”。
②打开“统计量”对话框,在“描述性”中,选择“单变量ANOVA”和“BoxsM”。在“函数系数”中选择“Fisher”(注:此为Bayes选项)和“未标准化”(注:此为Fisher选项)。
此外,“均值”可以输出各类中各自变量的均值和标准差。“矩阵”选项组可选择自变量的系数矩阵。
③打开“分类”对话框,在“先验概率”(注:此为Bayes选项)中,按默认选择“所有组相等”。在“使用协方差矩阵”中,按默认选择“在组内”。在“输出”(注:此为Bayes选项)中,选择“摘要表”和“不考虑该个案时的分类”。在“图”(注:此为Fisher选项)中,选择“合并组”、“分组”和“区域图”。
此外,“个案结果”可以输出每个观测量包括判别分数实际类预测类(根据判别函数求得的分类结果)和后验概率等。
④打开“保存”对话框,选择“预测组成员”、“判别得分”和“组成员概率”。
全部选择完成后,单击“判别分析”对话框中的“确认”按钮。
2.4判别分析结果
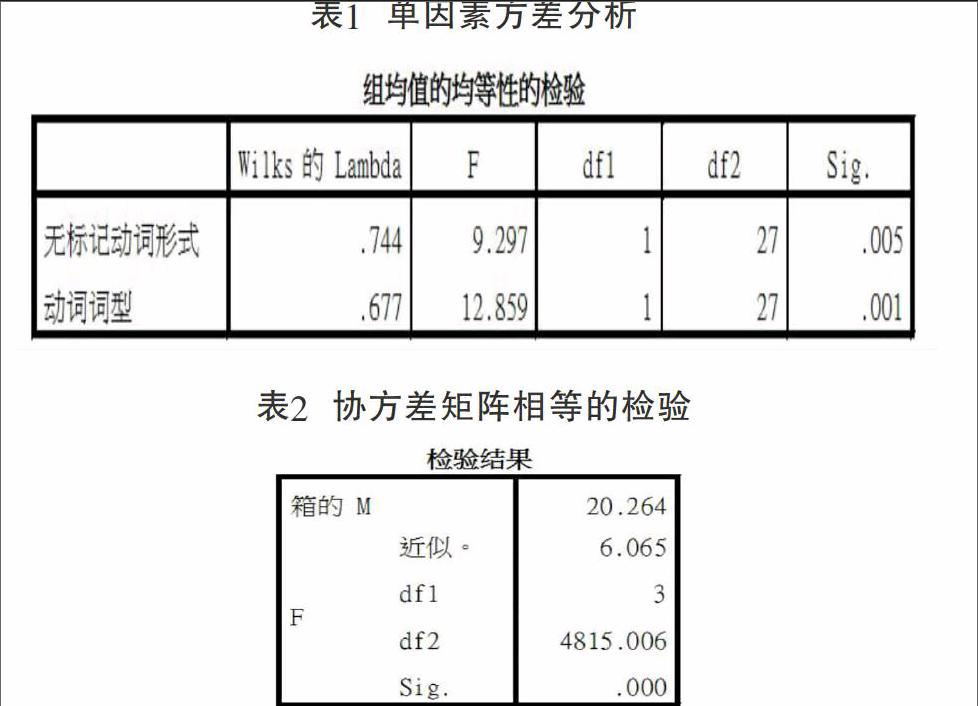
①适用条件检验。在“统计量”对话框中,选择“单变量ANOVA”和“BoxsM”,可分别得到下面的表1和表2。表1中的Sig值表示这两个变量均值在各组间都是有差异的,因此这两个变量对类间的判别都是有作用的。表2中的Sig值表示组间协方差齐这一假设是被拒绝的。不过,协方差齐的这一要求在实际应用中往往是被忽视的。[4]
②基本输出结果。表3给出了判别函数的特征根以及判别指数。本实验中只有一个判别函数,所以只有一个特征值。表4中的Sig值表示差异达到显著水平,即这个投影函数能将两组儿童区分开。从表5中,可以看出判别函数主要与“动词词型”这个自变量相关。由于本实验只有一个判别函数和两个自变量,那么可以推测在区分正常儿童和语言受损儿童上,“动词词型”这个变量在判别分析中起了主要作用。表6是各组的判别函数的重心。注意此处使用的是非标准化典型判别式函数。
③三种判别式。判别分析默认会给出表7的判别函数,其中的判别函数使用的是标化变量。如果在“统计量”对话框中,选择“未标准化”,可以得到表8的判别函数;选择“Fisher”,可以得到表9的判别函数。注意此处“Fisher”复选框对应的实际上是Bayes判别。
标准化典型判别式为:
F(X)=-0.684×Z无标记动词形式+0.785×Z动词词型(变量前加Z表示标化后的数值)
未标准化典型判别式为:
F(X)=-2.046–0.060×无标记动词形式+0.190×动词词型
Bayes判别式为:
语言受损=-13.760+0.285×无标记动词形式+0.897×动词词型
正常=-17.050+0.167×无标记动词形式+1.271×动词词型
④图表。由于本实验只有一个判别函数,所以没有产生区域图和合并图,只有如图3和图4所示的分组直方图,从直方图中可以大致看出各组中样本的分布情况。
图3 分组直方图(语言受损)
图4 分组直方图(正常)
⑤分类结果。在“分类”对话框中,选择了“摘要表”可以得到表10中的上半部分,是采用回代法得到的判别信息,由表可见有96.6%的正确率,其中语言受损有1例错判。在“分类”对话框中,选择了“不考虑该个案时的分类”可以得到表10中的下半部分,是采用交叉验证法得到的判别信息,本实验中正确率为86.2%,其中语言受损有1例错判,正常有3例错判。
⑥保存结果。运行判别分析后回到数据文件的数据视图,如图5所示,生成了新的变量。在“保存”对话框,选择“预测组成员”,产生“Dis_1”变量,显示的是各样本按Bayes判别所属的类别;选择“判别得分”得到“Dis1_1”列,是样本在Fisher投影函数下投影的坐标;选择“组成员概率”得到“Dis1_2”和“Disc2_2”,为样本分别属于第1类与第2类的后验概率大小。根据表10所示,语言受损有1例错判。在图5中可以看出,语言受损儿童中错判的是第3例,因为其第2类的后验概率0.90727大于第1类的后验概率0.09273,因此判别为第2类。此外,“Dis1_1”的值还可以结合表6的类中心坐标使用距离判别法进行类别判别。
3.结语
综上所述,SPSS只能完成Bayes判别与Fisher判别,无法直接完成距离判别。SPSS判别分析是以Bayes判别为主,主要菜单与选项都是针对Bayes判别分析设置,并且最终保存的判别结果也是以Bayes判别为依据;Fisher判别操作仅给出投影表达式、各类投影中心坐标及投影分界图,最终判别结果需要自己根据各类投影中心坐标或投影分界图去做判别。[5]此外,由于判别分析有着比较严格的前提条件,比如自变量和因变量间的关系要符合线性假定等等。当自变量和因变量间的联系为比较复杂的非线性函数,甚至无法给出显式表达时,这些基本的判别法就不适用了。而SPSS在“分析”菜单中,还提供了“树”和“神经网络”,这些方法均为非参数方法,因此没有太多的适用条件限制,应用范围更广,也更适合对各种复杂联系进行分析判断。
参考文献:
[1]任志娟.SPSS中判别分析方法的正确使用[J].统计与决策,2006(2):157.
[2]陈希镇,曹慧珍.判别分析和SPSS的使用[J].科学技术与工程,2008,8(13):3567-3571.
[3][英]Woods,A.等著.语言研究中的统计方法[M].陈小荷等译.北京:北京语言文化大学出版社,2000:275-280.
[4]张文彤.SPSS统计分析高级教程[M].北京:高等教育出版社,2004:261-277.
[5]陈敏琼.利用SPSS进行判别分析的几个问题的说明[J].现代计算机(专业版),2015(2):34-39.
猜你喜欢
天津外国语大学学报(2021年1期)2021-03-29
江西社会科学(2018年8期)2018-08-29
海外华文教育(2016年1期)2017-01-20
新疆大学学报(哲学社会科学版)(2015年6期)2015-10-12
当代外语研究(2010年3期)2010-03-20
当代修辞学(2010年1期)2010-01-23
