
基于随机森林模型的干旱预测研究
2016-03-22 06:54陈元芳余胜男河海大学水文水资源学院南京210098
中国农村水利水电 2016年11期
吴 晶,陈元芳,余胜男(河海大学水文水资源学院,南京 210098)
全球气候变化异常,人类活动影响,导致发生干旱的频率逐年增加,影响范围还在不断扩大。进行干旱预测,能够及时采取有效防灾措施,减少干旱对农业,工业,生态等社会各行各业的影响。如何更加准确的对干旱进行预测,具有重大的现实意义。干旱预测主要有基于物理成因的方法和基于统计理论的方法。因气候变化、水文机制等影响干旱发生的因素十分复杂,传统的基于物理成因的方法只是建立在线性平稳、多变量模型等随机模拟技术基础上,存在局限性,对具有非线性特征的气象要素或天气现象的预报有其明显的不足之处。为了描述预测干旱气候的这种非线性,神经网络(Artificial Neural Network ANN)、灰色系统模型(Grey System、GM)、支持向量机(Support Vector Machine,SVM)等智能方法被运用到干旱预测之中。但是,ANN虽有较强的非线性拟合能力,但其固有的弱点是在运行过程中初始权值、网络结构以及学习参数,动量因子难以确定,容易出现过拟合的问题,影响网络的泛化能力[1]。灰色GM(1,1)模型虽然有输入数据量小、原理简单、计算量适中、预测精度较高等优点,但是GM(1,1)一般只适用于短期干旱预测,当预测时间尺度较长时间时,预报准确度低[2]。李晓辉[3]利用灰色预测模型与人工神经网络相结合提高降水量的预测精度,但仍然仅适用于短期干旱预测,且输入的训练样本的大小以及训练筛选模式对预测结果影响较大。樊高峰[4]利用支持向量机的方法来预报干旱,SVM虽然避免了维数过高和过拟合等问题,但其内部参数和核函数比较难优选的,并且在分类预测中,还需对样本数据及影响因子进行标准化或归一化的预处理,而只能将结果分为两类,一定程度上不能满足当前对干旱预测的要求。
随机森林模型(Random Forest)是一种基于CART(Classifition and Regression Tree)分类决策树的组合分类模型。RF模型可以处理非线性问题,且不需对数据进行预处理,通过对大量分类树的汇总提高了模型的预测精度,是取代ANN、GM等传统机器学习方法的新模型,在各行各业得到越来越多的应用,并且已在在水文上应用得到较好效果,赵铜铁钢[5]利用随机森林模型对长江枯水期进行径流预报。
随机森林可以对影响影子进行分类,同时对各个影响因子的重要性进行评分,并将评分作为筛选重要因子的依据,采用简单多数投票法进行投票表决决定其最终分类。本文期望通过建立随机森林模型来对干旱进行分类预测。应用1962-2012年淮河流域21个代表站的数据,进行气象干旱分析,选用气象干旱指标:标准化降雨指数(SPI)分析干旱等级。并初步优选出372个因子作为因子筛选集,利用RF模型挑选出前30个重要性因子,进而进行RF干旱模型的检验及预报。
1 研究内容
1.1 研究区域概况
淮河流域(30.55′~36.20′N,111.55′~121.20′E)是我国东部最重要河流之一,位于黄河长江之间,发源于河南南阳桐柏山,整体自西向东流至江苏扬州三江营入长江, 流域全长1 000 km,面积为27万km2。淮河流域地处我国南北气候过渡带,天气系统异常复杂,变化多样,降雨时空分布极不均匀,灾害性天气(干旱、洪灾等)发生的频率高,尤其是冬春少雨易发干旱。淮河流域包括江苏、山东、安徽、河南、湖北五省40个地(市),181个县(市),总人口为1.65亿人,居各大江大河流域人口密度之首。若流域内区域发生干旱,其影响范围及损失将非常巨大。为提前采取相应措施应对旱灾,对干旱性天气进行合理准确的预测显得尤为重要,为此,本文利用1962-2012年淮河流域内21个代表站的降水以及相关气象要素的观测资料,结合随机森林模型预测淮河流域干旱情况。
1.2 干旱分类指标选取
干旱为某地理范围内降水,径流等自然水源在一定时期持续少于正常水平,导致河流、湖泊等水量亏缺的自然现象。干旱涉及气象、水文、农业和社会经济等学科,本质为水的短缺,其中影响干旱最重要的因子为降雨量。其中与降水量联系最紧密的为气象干旱,气象干旱也是四类干旱中最重要的。根据联系的重要性等因素选用基于气象的干旱评判指标评判干旱。气象干旱指标选用标准化降雨指数(SPI)。SPI以(小于或等于)某降雨值的累积频率对应的标准正态分布相同累计频率的分为点为该降雨量的标准化降雨值指数。其计算公式如下:
(1)

因SPI假定所有地点的旱涝情况发生概率相同,无法区分干旱频发地区。本文分别对21个站进行干旱分类,这样能够独立分析每一个站真实的干旱情况。为防止时间步长较长的指标应用于降水相对较少的地区时,以月为分析尺度。
基于SPI的定义以及分析实际的情况确定SPI的阈值将干旱分成三类。频率小于30.9%的降雨所对应的SPI值定义为干旱的阈值,降雨出现频率高于30%所对应的SPI值定为湿涝的阈值,介于两阈值之间的SPI值所对应的月份即为正常月份。如表1为淮河流域21个站基于SPI的干旱分类情况。

表1 淮河流域21个站基于SPI的干旱程度等级划分Tab.1 Result of drought classification based on SPI with 21 stations of Huaihe basin
以3月王家坝为例列举出基于SPI分类干旱等级的年份分类情况表(表2)。

表2 淮河流域王家坝站3月干旱等级划分结果表Tab.2 Result of March month drought classification on Wangjiaba staion
2 研究方法
随机森林(RF)[6]是由Leo Breiman于2001年提出来的一种统计学习理论。随机森林与其他机器学习的算法相比预报精度高,且运算快捷,它集成了Bagging和随机选择特征分裂两种方法的特点;具有很好的泛化性能,对异常噪声具有很好的鲁棒性,在不同领域已取得较好的应用。随机森林包括随机森林回归与随机森林分类。
随机森林分类(Random Forest for Class,RFC)[7,8]是一个多决策分类器,具有由诸多CART分类模型{h(X,θk),k=1,2,…}(基本结构)组成的组合分类模型[9](图1),其中参数集{θk}是独立同分布的随机向量,输入自变量 的最终分类结果是由每个决策树分类模型进行投票来选择的最优的分类结果(定义y为输出结果)。

图1 Bootstrap重抽样过程图Fig.1 Schematic diagram of bootstrap resampling
RFC的基本思想:首先,利用Bootstrapping抽样从原始训练集(x,y)抽取k个样本,且每个样本的基本容量都与原始训练集容量一样,流程详见图1;再对k个样本分别建立k个决策树模型({h1(x),h2(x),…,hk(x)}),得到k种分类结果,最后,根据k种分类结果采用简单多数投票法对每个记录进行投票表决决定其最终分类,详见图2。由此看来,RF模型使用Bagging方法(随机采样选用自举法-Bootstrapping)形成新的训练集,随机选择特征进行分裂,使得随机森林能较好地容忍噪声,并且能降低单棵树之间的相关性;单棵树不剪枝能得到低的偏差,保证了分类树的分类效能。用Bagging方法生成训练集,原始样本集中接近37%的样本不会出现在训练集中,这些数据称为袋外(Out-Of-Bag,OOB)数据,可用OOB数据来估计决策树的泛化误差。对于每一棵决策树,可以得到对应的一个OOB误差估计,将随机森林中所有决策树的OOB误差估计取平均值,即可得到随机森林的泛化误差估计。Breiman通过实验已经证明,OOB误差是无偏估计,并且相对于交叉验证,OOB估计是高效的,且其结果近似于交叉验证的结果。所以,本研究模型性能的评估方法采用的是以OOB估计作为泛化误差估计的方法[10]。

图2 随机森林分类模型结构图Fig.2 Schematic diagram of random forest structure
3 实例分析
3.1 RF预报模型的步骤
本研究以前期12个月的降雨和国家气象中心发布的74项水文-气象特征量作为预报因子,分别对淮河流域21个代表站的各月的干旱情况进行研究及预报。选用 1962-2012年,共 51 组经过三性审查的样本数据(来自水文年鉴)。以王家坝站的3月干旱情况预报为例,干旱预报步骤如下:
(1)预报因子初步选取:为提高模型筛选影响因子的能力和预报的精度,解释变量的选择应注重因子与预报对象之间的物理相关程度或天气学上的相关关系。充分考虑因子影响区域大气的时空状态变化及其特征的紧密程度、气象干旱成因机理并结合相关文献[5,11],从74项水文-气象特征量初步筛选出与形成气象干旱有关的30个因子(表3)。
(2)预报因子的筛定。为减少在重要性因子评价时加入的噪声对随机森林的预测准确率的影响,运用Incnodepurity指数评判因子的重要性,该值通过计算所有树的变量分割的节点不纯性减少值来比较因子的重要性,该值越大表示该因子在RF预测中的重要性越大。根据这个原则可以得出在建立的随机森林非线性关系中重要性排在前30的因子。
以次年3月-本年2月份的逐月降雨量和选取的30个水文-气象特征量逐月观测值共计372个水文-气象特征量作为备选解释变量,因子排列顺序为前期12个月的降水量序号排至12和按月排列12个月的筛选出的30项大气环流特征量,序号排至372。以王家坝站每年3月份的干旱等级作为目标变量,将所有观测样本作为训练样本集,构建基于随机森林模型对解释变量进行重要性评价。对解释变量依据其重要性进行降序排列,选取前30个变量作为最终预报因子。影响因子重要性指数见图3,各月干旱预测的预报因子筛定结果如表4所示。

表3 随机森林模型初步筛选的影响因子表Tab.3 Result of preliminary screening influence factors of random forest model
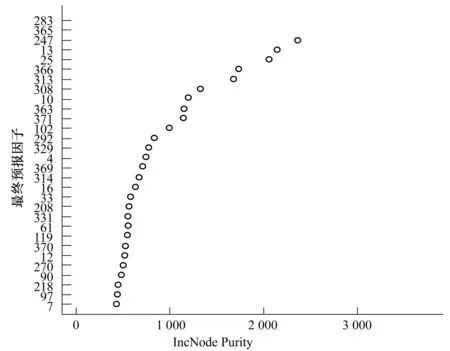
图3 随机森林对影响干旱分类等级的因子的重要性排序Fig.3 Ranking variable importance that associated with drought classification by random forest
(3)预报模型构建:应用基于 R 语言随机森林程序包( http:∥cran. r-project.org/) 进行干旱预报研究。以步骤(2)选取的30个预报因子作为解释变量,以1962-2012年王家坝站的3月份干旱分类作为目标变量。以1962-2006为模型训练期和2007-2012为模型检验期,以训练期样本构建预报模型对检验期样本进行预报,并对检验期干旱预报结果进行精度评价。在本次分析中,模型参数M为子预报模型的数量,参数N为回归树的节点中划分待选的变量的数目,根据文献[5]一般M取值越大越好,N取值一般为总的解释变量数目的1/3。本次RF模型筛选预报因子阶段,M取3 000,N取124,预报阶段,M取3 000,N取10。

表4 基于RF模型3月王家坝站的预报因子Tab.4 Prediction factors based on RF of March month at Wang jiaba station
3.2 RF模型训练与预报结果
以1962-2006年为模型训练期的3月份王家坝站的基于RF干旱预测模型构建的OOB误差见表5。
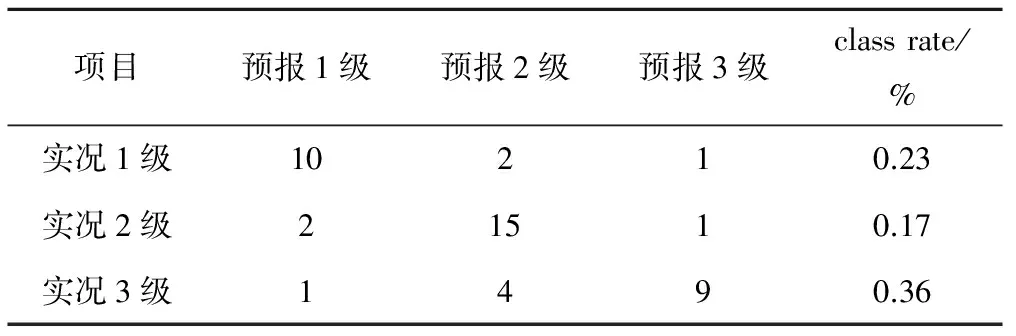
表5 模型训练期OOB预测误差表 Tab.5 The error of OOB at training period of RF model
由表5可以看出,划分的3个等级中,实况1级有13年,实况2级有18年,实况3级有14年,运用OOB数据进行预报,预报结果中有13年是1级,21年是2级,11年是3级,OOB预测的误差1级是0.23,2级是0.17,3级是0.36。检测期模型的平均OOB误差为25%,效果较好。随机森林预测2级(正常)的效果最好,其样本容量最大,且未被选取的RF干旱预测模型的预报因子可能对其干旱分类等级影响甚微。随机森林预测实况3级(干旱)的效果最差,可能与其样本容量和影响干旱分类等级的因子未被RF模型选用预报有关。
参考气候预报业务评分标准[9],按3级进行Ts评分(Ts=总得分/总预报次数),见TS评分表6。
根据建立的RF模型,对2007-2012年的干旱类别进行预报,预报结果见表7。

表6 3级TS评分表 %Tab.6 Ts score standard of 3 level
由表7可知,6年的独立预报样本,报对3年,报差一级为3年(实况为湿涝或干旱,预报为正常),结合表6的评分标准,可以求得建立的王家坝站3月份的随机森林模型平均预报准确率为75%。根据以上预测流程分析淮河流域21个站的干旱情况并得出预报结果。每个站的各月的干旱等级预报准确率、各站年均预报准确率以及12个月的月平均预报准确率如表8所示。

表7 2007-2012年王家坝站3月份干旱等级预报情况Tab.7 Class forecast result of drought from 2007 to 2012 in Wang jiaba station

表8 基于RF模型的淮河流域21站的每月的干旱等级预测结果表 %Tab.8 Drought prediction result of every month of 21stations at the huaihe river basin based on RF model
RF干旱预测模型预报淮河流域21站的12个月的平均预报准确率为73.0%。在预报结果中,预报准确率最高的为100%,分别是王家坝站6月份预报准确率,高良涧闸站6月份准确率,徐州站6月份准确率;最低的为50%,分别是灵璧站1月份准确率,石漫滩站1月份准确率;其中王家坝站的年平均预报准确率为77.1%,最高;灵璧站的年平均预报准确率为68.8%,最低;21个站的平均预报准确率最高月份为6月,其准确率为90.1%,最低月份1月,其准确率为60.3%。
经分析,对于准确率较高的站点和月份,RF模型筛选出影响因子对该地区干旱发生有及紧密的联系,因果相关性较大,模型可以较为准确的预测出干旱等级。准确率较低的月份和站点,其干旱成因机理受更多因素影响,如1月份的干旱等级更多的受冬季气温、ENSO等影响;可能还与基于SPI进行干旱分类在某区域和月份上适用性较差有关。
4 结 语
(1)秉承理论与实践相结合的思想,按SPI值将干旱等级划分成三类,以单站为分析单元,以一个月为分析尺度,对淮河流域21个站的干旱情况应用RF干旱预测模型预测,模型目标变量为基于SPI的模型样本的干旱分类等级,并且基于物理成因和统计特性初步选择了与干旱密切相关的预测因子集,再从中筛选出的重要性前30的因子作为最终预报的影响变量进行随机森林分类模型检验与预测。
(2)RF干旱预测模型的预测结果较好,总体的平均预报准确率为73.0%,高于气候系统的天气预报准确率65%。其中王家坝站的年平均预报准确率为77.1%,最高;灵璧站为68.8%,最低;各站平均预报准确率最高月份为6月,其准确率为90.1%,最低月份1月,其准确率为60.3%。经分析及验证,对于准确率较高的站点和月份, RF模型筛选出影响因子对该地区干旱发生有极其紧密的联系,因果相关性较大,模型可以较为准确的预测出干旱等级。反之对于准确率较低的站点和月份,其区域或月份的干旱程度与其他因素联系更为紧密,致使预测准确率降低。
(3)基于SPI的干旱分类的RF干旱预测模型的预报结果表明RF预测模型从物理成因等方面选择因子进而直接对干旱等级进行预测,得出相对较高的预测准确率,但此RF预报模型只是基于淮河流域21个站预报干旱较为准确,模型的适用条件还需进一步检验,可将此模型在不同区域进行试验,若能得出较高的预报准确率可以进行推广及应用。此外模型的分类依据只为气象干旱指标SPI,在今后分析,可以考虑将气象干旱、水文干旱、农业干旱等指标进行耦合,更加科学地将干旱从不同成因角度进行等级划分,使预报结果更具准确性和说服力。
□
[1] 汪春秀. 基于支持向量机的气象预报方法研究[D]. 南京:南京信息工程大学, 2011.
[2] 刘代勇,梁忠民,赵卫民,等.灰色系统理论在干旱预测中的应用研究 [J].水力发电,2012,38(2):10-12.
[3] 李晓辉,杨 勇,杨洪伟.基于 BP 神经网络与灰色模型的干旱预测方法研究[J].沈阳农业大学学报,2014,45(2):253-256.
[4] 樊高峰,张 勇,柳 苗,等.基于支持向量机的干旱预测研究[J].中国农业气象,2011,32(3):475-478.
[5] 赵铜铁钢,杨大文,蔡喜明. 基于随机森林模型的长江上游枯水期径流预报研究 [J]. 水力发电学报, 2012,31(3):18-24,38.
[6] 李欣海.随机森林模型在分类与回归分析中的应用[J].应用昆虫学报,2013,50(4):1 190-1 197.
[7] BREIMAN L. Random forests [J].Machine Learning, 2001,45(1):5-32.
[8] Gislason P O, Benediktsson J A, Sveinsson J R. Random forests for land cover classifiction [J].Pattern Recognition Letters, 2006,27(4):294-300.
[9] 方匡南,吴见彬,朱建平,等.随即森林方法研究综述[J].统计与信息论坛,2011,26(3):32-38.
[10] Hongyan Li, Miao Xie, Shan Jiang. Recognition method for mid-to long-term runoff forecasting factors based on global sensitivity analysis in the Nenjiang River Basin[J].Hydrological Processes,2012,26(18):2 827-2 837.
[11] 董 亮,陆桂华,吴志勇,等.基于大气环流因子的西南地区干旱预测模型及应用[J].水电能源科学,2014,32(8):5-8.
[12] 常 军, 路振广,李素萍,等. 基于SVM 方法的水文年型预报[J]. 人民黄河, 2009,31(4):29-30,33.
[13] 康 有,陈元芳,顾圣华,等.基于随机森林的区域水资源可持续利用评价[J].水电能源科学,2014,32(3):34-38.
猜你喜欢
家教世界(2022年28期)2022-10-25
治淮(2022年8期)2022-09-03
作文周刊·小学一年级版(2022年24期)2022-06-18
阜阳师范大学学报(社会科学版)(2021年4期)2021-12-07
内蒙古气象(2021年2期)2021-07-01
治淮(2019年5期)2019-06-12
领导决策信息(2018年46期)2018-04-20
百科探秘·航空航天(2017年11期)2017-12-20
治淮(2017年2期)2017-04-17
