
徐州医学院图书馆自建麻醉学特色数据库关键技术
2016-03-22 05:40:34
中华医学图书情报杂志 2016年5期
特色数据库是指针对用户的信息需求,对某一学科或某一专题有价值的信息进行收集、分析、评价、处理、储存,并按照一定标准和规范将特色资源数字化,以满足用户个性化需求的信息资源库。医学院校图书馆必须根据本院的学科优势、专业特点等因素,选择特色专题并结合本馆的相关应用实际进行特色数据库的建设,使所建的特色数据库既有较高的学术价值,又具有良好应用前景[1]。
1 建设麻醉学特色数据库的背景及意义
徐州医学院(以下简称“我校”) 图书馆目前馆藏100余万册,其中麻醉学等方面的图书有1 500多种,还购买了中国知网数据库、万方数据库、维普期刊资源整合平台等中文数据库和Web of Science、Springer Link、PubMed等外文数据库,但是这些资源较为分散,载体形式各样,没有形成具有专业特点的特色馆藏。
麻醉学专业是我校的优势学科,在全国名列前茅。1986年我校创办了中国第一个麻醉学本科专业,建成了国内同行中规模最大、实力最强的麻醉学国家重点实验室,开创了具有中国特色的麻醉学创新人才教育体系,积累了大量的麻醉学教学实践资源。现任麻醉学院院长曹君利教授是“长江学者”,我校的麻醉学教学团队是“国家级优秀教学团队”。
建立麻醉学特色数据库,集中收集、加工,形成内容丰富的、高质量的特色化资源,为读者提供一站式高质量的麻醉学信息资源服务,有利于提高我校的地区影响力。
2 我校自建麻醉学特色数据库的流程
特色库的建设流程包括平台的搭建、数据源选取、信息采集与加工、信息发布与更新等环节。图书馆将与麻醉学相关的书籍、论文、专题讲座、教学课件等各类资源进行数字化处理后,按照统一的标准和规则,结合麻醉学专业特点和用户个性化需求,对各类信息资源进行有机整合,形成麻醉学特色数据库[2]。我校之前的硕士论文库和随书光盘库采用的是畅想之星公司的特色数据库平台。为了兼容我校之前的数字资源建设成果,麻醉学特色数据库也采用此平台进行建设。
我校的麻醉特色数据库数据来源主要包括图书馆纸质资源、数字资源、麻醉学院资源和网络资源。纸质资源的选取主要依据图书馆收藏的麻醉学相关方面的1 500多种图书,100多种专业期刊,报纸;数字资源的选取按照麻醉学专业学科分类体系逐步进行筛选,根据其内容质量、参考价值和使用频率等因素进行选取[3];麻醉学院资源的选取主要来自其广泛收集的高质量的麻醉学教学课件、讲座视频和学生获奖作品;网络资源的选取主要是登陆“中华麻醉在线”、“围术期患者之家”等国内外麻醉学权威网站和北大第一医院吴新民教授、华西医院刘进教授、协和医院黄宇光教授等麻醉学权威人士的个人主页、博客等,收集文章观点、讲座视频和会议视频等麻醉相关优质资源。
将符合条件的麻醉学相关图书、报刊、论文、标准规范等各类纸质文档数字化,按统一的标准生成PDF文档[4],利用虚拟打印机将搜集到的各种电子文档(WORD、PPT、 TXT等)按统一的标准转换成PDF文档,讲座等视频和音频资源采用Format Factory等软件按统一的标准转换为基于Windows Media的流媒体文件[5]。同时,还对数字对象进行分类、标引,把各种类型的数字对象加工成可供浏览和检索的数字资源。
对麻醉学特色数据库录入的数字资源由专人负责进行审核、校对,对不符合要求的数字资源给出意见并反馈到加工环节,审核通过的数字资源按照规定统一进行发布[6-14]。我们利用Coreseek 技术实现了麻醉学特色数据库的全文检索服务[15],针对本科生、研究生、教师、医生等不同的用户群提供全文检索、分类导航、栏目导航等功能,方便用户查找相关数字资源 。
3 自建麻醉学特色数据库的关键技术
3.1 利用开源ETL工具——Kettle处理原图书系统中的MARC数据
图书馆纸质资源数字化是一个浩大而繁琐的工程。汇文系统中有麻醉学相关的纸质资源的MARC数据,图书馆纸质资源数字化、采集、加工的过程中要维护好相关著录和标引信息。为了提高特色数据库的建设效率,减少重复性操作,我馆引入ETL工具,按照特色数据库的相关数据标准进行MARC数据转换,应用于新建的麻醉学特色数据库中。
由于商业化的ETL工具(Informatica、Datastage等)费用昂贵,我们采用了ETL工具中的Kettle来处理MARC数据转换。Kettle是一款开源免费的ETL工具,数据抽取高效稳定,完全能满足我们建库过程中转换数据的技术要求。Kettle有transformation和job两种脚本文件,transformation负责完成数据的提取与转换,job负责完成整个处理流程的相关控制。
我们首先把筛选出的纸质资源的MARC数据导出到文本文件marc.txt,然后利用华云马克数据转换工具将MARC数据转换为EXCEL文件marc.xls。转换后的EXCEL格式的MARC数据主要包括书目名称、作者、ISBN号、价格、出版地、出版社、出版时间、分类号、分类名、提要、页数、附件等信息。将这些信息按照特色数据库的数据标准智能导入麻醉学特色数据库中,可以极大减少图书馆纸质资源数字化的工作量,加快建设进程。畅想之星特色数据库的后台表结构如下图1所示。
最后利用Kettle建立transformation,将marc.xls的数据转换为符合特色数据库标准的数据,保存到特色数据库中,以备在纸质资源加工时直接引用,减少重复操作,提高工作效率。由于麻醉学特色数据库建设是一个长期的不断完善的过程,所以我们对MARC数据的处理并不是一次简单的数据转化,而是建立一种机制,只需将要添加转化的MARC数据放到指定位置的marc.xls中,系统自动完成相关的数据转化处理。transformation的建立步骤如图2所示。
第一,transformation中建立EXCEL输入控件,提取指定位置的marc.xls里的MARC数据;第二,选取“插入/更新”控件将MARC数据按照特色数据库的标准将数据更新到特色数据库中时,需要设置好该控件的数据库连接、目标模式和目标表等相关信息,然后以书名、作者、出版社、出版时间和ISBN号的组合条件为主键进行数据的添加或更新处理,将要处理的字段与麻醉特色数据库的目标表的字段进行映射,建立对应关系。第三,汇文系统中MARC数据难免有数据不全或不符合标准的数据,需要给“插入/更新”控件建立错误处理,以确保数据处理过程中完成符合标准MARC数据的处理,输出不符合标准的MARC数据的错误信息,以便查找和修正相关信息。

图1 畅想之星特色数据库后台表结构

图2 Kettle transformation建立设置
3.2 利用Coreseek + Python + Sql Server实现麻醉学特色数据库的全文检索服务
全文检索有数据库内置的全文检索(Oracle,Mysql,SQL Server,等)和专业的开源全文检索引擎(Sphinx,Lucene等)两种模式。数据库内置的全文检索只需将需要全文检索的相关字段建立全文索引,改变查询条件即可实现全文检索功能,但不支持中文分词、智能关联排序。Lucene是用Java语言开发的,性能相对较低,对硬件要求高,所以我们利用C++开发的高性能Sphinx全文检索引擎进行开发,设计了麻醉学特色数据库全文检索系统,为用户提供一站式智能检索服务[16]。Coreseek全文检索引擎是在Sphinx 基础之上开发的,增强了中文分词、中文编码等中文支持,并根据中文的相关特点对搜索结果的排序进行了优化。Coreseek全文检索引擎构成及功能见表1。

表1 Coreseek全文检索引擎构成及功能
Sphinx主要支持MySQL 数据库、PostgreSQL 数据库。因为Python目前具备操作所有类型数据库的能力,Coreseek为了扩展,增加了Python数据源功能[16]。
本数据库利用Coreseek 全文检索引擎和Python数据源程序接口,实现一个无限扩展Coreseek/Sphinx的数据获取功能。以Sql Server数据库为主,可兼容多种类型数据库的分布式全文检索引擎,向使用者提供更加快速、精确并具有良好数据兼容性的全文检索服务,为以后整合管理自建数据库和商业数据库等相关数字资源铺平了道路。系统架构见图3。
由于麻醉学特色数据库平台是畅想之星,后台为SQL SERVER数据库,所以要安装pymssql扩展包,然后利用Python的数据源功能操作SQL SERVER数据库[6]。
麻醉学特色数据库客户端是采用PHP语言实现的,调用Sphinx API中的方法并构造SphinxClient对象实现全文检索。守护进程searched负责接受查询请求,对接收到的检索内容利用LibMMSeg工具进行分词,然后在服务器上的全文索引文件中进行检索,并把检索结果通过API返回给特色数据库客户端。

图3 麻醉学特色数据库全文索引系统模型
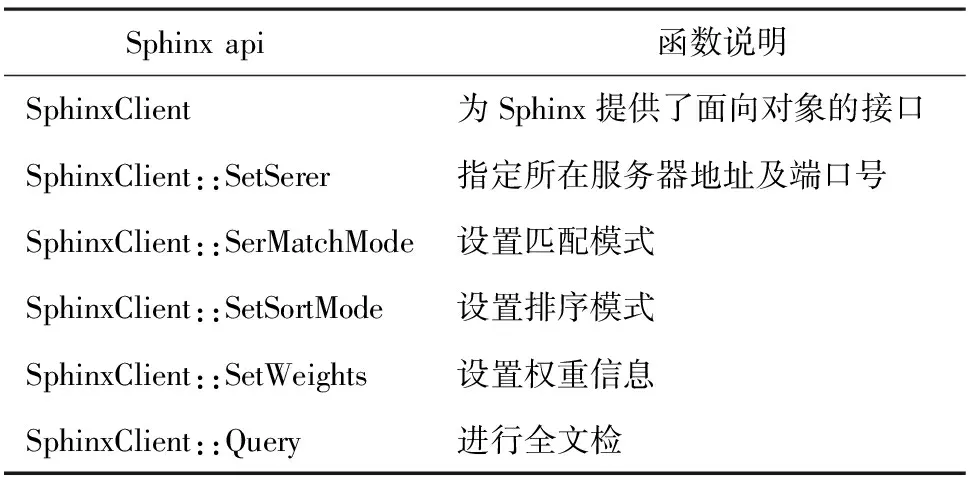
Sphinx api 函数说明SphinxClient为Sphinx提供了面向对象的接口SphinxClient::SetSerer指定所在服务器地址及端口号SphinxClient::SerMatchMode设置匹配模式SphinxClient::SetSortMode设置排序模式SphinxClient::SetWeights设置权重信息SphinxClient::Query进行全文检
示例代码如下:

4 总结与展望
本文论述了我校图书馆自建麻醉学特色数据库的整体流程,并详细分析了利用Kettle实现MARC数据共享,提高建库效率和利用Coreseek等技术实现麻醉学特色数据库的全文检索,为读者提供最佳的检索服务。经过测试,本文建设的麻醉学特色数据库全文检索引擎在2GB-4GB 的文本建立的索引上搜索,平均0.1秒内获得结果,相比Sql server自带的全文检索引擎,速度提升近10倍,检索质量也明显提高。其对Python 数据源的支持使我们的麻醉学特色数据库可以兼容不同类型的异构数据库,提高麻醉学特色数据库的扩展性,有利于以后与硕博士论文库、中国知网、万方等数据库进行资源整合,从而进一步促进我校麻醉学专业的建设与发展[17-20]。
猜你喜欢
——以川北医学院为例
中国卫生产业(2022年23期)2022-03-13 21:52:14
卫生职业教育(2019年18期)2019-09-18 08:58:56
中国生殖健康(2019年2期)2019-01-03 09:58:27
首都医科大学学报(2017年3期)2017-06-24 11:38:39
现代计算机(2016年27期)2016-10-29 01:52:32
新高考(英语进阶)(2016年12期)2016-02-28 21:58:00
文学教育(2016年27期)2016-02-28 02:35:24
Coco薇(2016年1期)2016-01-11 03:00:59
东莞理工学院学报(2014年3期)2014-07-12 13:21:36
阜阳职业技术学院学报(2013年3期)2013-04-29 13:40:50
