
数据分析和数据挖掘在影视频艺人评估分析中的应用研究
2016-03-07 03:28:43丁皖莹殷复莲
中国传媒科技 2016年12期
■文/丁皖莹 王 格 殷复莲
数据分析和数据挖掘在影视频艺人评估分析中的应用研究
■文/丁皖莹 王 格 殷复莲
当今中国娱乐圈发展蓬勃,随着新晋艺人的数量不断增加,人们对艺人的要求也越来越高。针对当今娱乐市场缺乏对单个艺人整体客观评价的问题,本文采用了数据挖掘和文本分析的方法,从各大网络平台的用户数据中提炼出了明星粉丝的兴趣特征,并利用微博平台的评论信息综合分析出了几十个贴切艺人形象的关键词。最终得到了艺人整体形象和其粉丝兴趣特征的关键词,并以图表和词云的形式展现出来,给人以直观的印象,较好地反映了真实的情况。
艺人形象;粉丝兴趣;词云分析
引言
艺人作为娱乐化时代的核心参与者,他们的一举一动往往都会对整个社会产生巨大的影响,在专业领域,制作方需要不断挖掘能力出众的艺人参与作品,在商业领域,对艺人市场号召力的需求更是源源不断,从商家代言到慈善活动,都离不开明星的影响力。另外,艺人的粉丝也构成了其社会影响力的一个主要部分。所以一个客观、公正、全面的艺人社会形象和对其粉丝特征的深入分析就显得尤为重要。
在分析艺人形象时实验采用了对微博的文本分析方法,与传统篇章结构的长文本相比,微博短文本受到字数的限制,呈现特征稀疏、内容短小、表述直接等特点,这使得以往有效的情感分析方法,面向微博短文本,其效果难以保证[1]。近年来,多种统计理论和机器学习方法被用来进行文本的情感自动分类,掀起了文本情感分类研究和应用的热潮。情感分析又称为意见挖掘或者观点挖掘,是指从主观性文本中识别、抽取相关的倾向性信息的过程,属于文本分类的范畴。情感分析相关的研究方法主要可以分为三类:基于情感词典和规则的方法;基于机器学习的方法;基于语义分析的方法。文本分析方法可应用于各行各业。如在分析网络舆情信息中,可用文本分析技术对网络舆情进行描述,并对其关联性进行分析。还可以对网络舆情的产生原因进行分析,预测和推论舆情变化趋势和走向。另外,文本分析技术在专利信息的分析中也有重要应用。通过对专利说明书、专利公报中的专利信息进行分类、加工、整合可以使这些信息转化为具有总揽全局及预测功能的竞争情报[12]。在心理学研究当中,文本分析也成为了重要手段之一。Web 2.0时代的到来,使互联网成为大众普遍交流观点、抒发情感的平台,同时也积累下了关于人类心理和行为的海量文本信息。通过文本分析技术,拓宽了包括心理学在内的社会科学研究范畴,突破以往传统社会科学研究在分析民众心理时采用的随机取样进行问卷或电话调查的方法,可以得到更为精确的结果[13]。
本文重点将数据挖掘理论和文本分析应用到建立艺人形象词云和粉丝兴趣特征分析中来,以单个艺人为单位,通过对微博、贴吧的数据进行分析,最后以词云和图表的方式来客观展现中国艺人的整体形象和其粉丝兴趣的整体情况。
1.影视频艺人评估分析方案
实验中艺人形象评价体系的建立主要依赖于网民的评论,原始数据的来源主要来自于艺人的微博评论、百度百科、豆瓣和贴吧。而贴吧中粉丝的个人信息比微博要更好获取,所以实验最终选择了在贴吧上抓取粉丝的兴趣标签。在抓取到数据后,数据经过了分词和词频统计等数据挖掘工序,最终生成了较为直观的可视化效果。
为了全面地评估艺人形象,实验将艺人形象主要分为两个方面:私生活和专业领域。通过抓取私生活和专业领域两方面关于某艺人形象的相关语料,做分词和词频统计,最后用加权的方式得到一个完整的艺人形象词频信息,从而画出词云图。
在粉丝兴趣特征及地域分析这块,为了更好地把握各明星粉丝的群体特征,实验利用从豆瓣小组和百度贴吧提取的粉丝信息进行了分析。贴吧粉丝的数据来源是贴吧成员关注的所有贴吧名称,而从豆瓣抓取的则是豆瓣兴趣小组的粉丝地区名称。对粉丝的分析分成两个部分,其中一个部分是对明星粉丝地区分布的展示,这一部分以柱状图的形式展现,另外一个部分则是对贴吧粉丝的兴趣进行了分类,并依据分类兴趣的频次进行了可视化处理,最终依据人数的多少生成气泡图。整个方案流程图如图1。

图1 方案体系示意图
2.中国艺人形象词云分析
2.1 形象词云分析方法
首先,私生活是艺人在专业领域之外的一个“真实”的展示,包括媒介展示出来的明星的业余才艺、日常生活、身世、性格,关于社会公共事件的观点和行动等。虽然我们并不能将艺人通过社交媒体展示出来的“真实”等同于个人真实,但是这种“媒介真实”仍然有研究价值,在这方面,实验借助一些网络平台作为数据来源,尽可能多地采集关于艺人形象的词语。私生活这个部分主要基于微博平台,因为微博上的数据量足够大,且这是一个艺人们发送自己私生活的主要途径之一。微博数据分为三部分:微博个人信息标签、微博内容和粉丝评论。从微博的个人信息标签能获取到艺人本身对于自身形象的一个概括,搜集到的词语大多都与该艺人形象十分贴切,所以将个人信息标签词的词频均乘以10。微博内容是抓取近一年某艺人关于自己日常生活的微博内容,并做分词和统计词频。因为微博内容中关于形象的词语较少,所以由此统计出来的词频均乘以0.5。最后一块是粉丝评论,抓取的是之前所找的微博内容下的粉丝评论,每条微博抓500条粉丝评论,使得评论尽可能避免谈及作品或一些通告活动。最后将统计出的词频乘以0.8。
专业是指该艺人所从事专业里所展现出来的形象。如演员就包括他的平面媒体形象、影视作品角色形象和一些与作品相关的宣传活动中所呈现出的造型等。歌手就包括其演唱歌曲风格和演唱时的形象等。描述一个艺人专业形象的词语主要通过粉丝以及一些专业人士对其作品的评价来获得。本文选取的三个来源是百度百科、微博和豆瓣。百度百科上一般会有对一个艺人的整体专业形象的介绍,该介绍来自于各大媒体杂志,具有较高的可信度和权威度,但又由于篇幅较短,所以由百度百科得到的词频均乘以5。有关艺人作品的数据抓取,本文以评论数较多、最新、作品种类作为标准筛选出三个作品进行抓取。微博作品相关评价是抽取每个作品200条评论作为语料来源,由于评论人群的不确定,所以权威性和真实性也有所下降,所以该词频均乘以0.8。最后一项是豆瓣作品评价,豆瓣作为国内大型社区网站之一,里面对于电影电视剧等影视作品的评价更加公正、客观,更能搜集到关于艺人专业形象的相关语料。从之前选好的三部作品的短评区各抓取200条评论,最终得到的词频乘以1.5。将这六个词频矩阵放到一起重新排序即得到该艺人的形象词频,从而画出词云图。
2.2 形象词云案例分析
杨幂的艺人形象词频中前20个词为: “演技”“演员”“第一”“电视剧”“时代”“进步”“好看”“电影”“美女”“时尚” “女孩”“北京”“表演”“影视”“独特”“豪气”“兢兢业业”“可爱”“灵气”“美貌”。最终为了更好地让人一目了然该明星的形象词云,实验选取了富有艺人特征的头像图作为词云形状。

图2 杨幂形象词云
通过以上词云图我们可以清晰看到杨幂日常形象多以美女、可爱、气质为主,在专业度方面,她作为一个演员,主要在电视荧幕上出现,并具有普遍认可和接受的演技和被大家称赞的认真态度等。
赵丽颖的高频词和杨幂的差别不大,这应该可以看作是女演员形象的共性,如“可爱”“偶像”“公主”等。

图3 赵丽颖形象词云
3.中国艺人粉丝特征分析
3.1 粉丝特征分析方法
抓取数据使用的是乐思数据采集软件,抓取了百度贴吧粉丝关注的贴吧名,大约10000条数据,经过计算词频及去重后剩余大约3000条数据。将所得词频数据通过在线可视化网站直接生成词云,同时将数据输入兴趣匹配的程序,得到各个兴趣分类的数量。兴趣匹配的程序使用python语言写成,利用的是基于词典的匹配,而词典是利用乐思从贴吧中抓取相应分类数据而生成的。
对采集到的数据进行预处理时,由于通过爬虫程序抓取的各类贴吧名的数量有限,从而生成的分类词典内容不够丰富,某些贴吧名未能涵盖进去。故对原始数据进行一个预处理是有必要的,本实验对原始数据进行同类词语匹配,从而简化合并了一些重复的数据,使得分类更精确。同类词的构词法有一个重要的特征,即意义相同或相近的语词大多包含有相同的字,如“微微一笑很倾城”和“微微一笑很倾城电视剧”。
为了计算词语的相似度,实验设计了一个基于单字在词语中出现频率的算法。令词语A中单字的个数为a,词语B中的单字个数为b,利用python检测得A与B中相同字的个数为n,两词的相似度为P(a,b),相似度计算公式如下:

规定P(a,b)>60%时两个词语为同类词语,并将长度大的词语替换为两者中长度小的词语。
在对数据进行了去重处理后,便可用语言进行词频的计算,并删除词频小于等于3的词语,最后利用python和已有的词典对词语进行分类。
3.2 粉丝特征案例分析
3.2.1 粉丝地区分布
明星粉丝的地区来源于豆瓣,实验抓取了800个粉丝的地区信息,并去重,将最后得到的数据利用excel图表的形式呈现出来,以杨洋和赵丽颖的粉丝地区分布为例,图表如下。
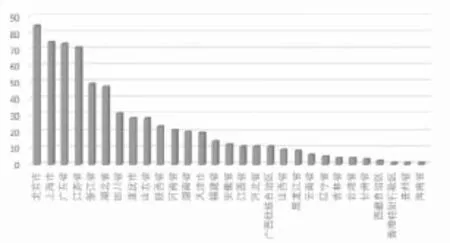
图4 杨洋粉丝地区分布图

图5 赵丽颖粉丝地区分布图
可以看出北京市、广东省、江苏省等地区的粉丝数量众多,究其根源,与发达地区人口数量众多也有非常大的关系。
3.2.2 粉丝兴趣特征
这次实验首先利用了从百度贴吧中爬取的3000个粉丝兴趣标签计算词频并生成兴趣词云如下:

图6 杨洋粉丝兴趣词云

图7 赵丽颖粉丝兴趣词云
随后实验将已有的兴趣标签去掉出现频次为1或2的部分后利用Python进行分类,分类结果如下:

表一 杨洋粉丝兴趣分布

图8 杨洋粉丝兴趣分类图示

表二 赵丽颖粉丝兴趣分布

图9 赵丽颖粉丝兴趣分类图示
由上面的数据可以看出关注明星的粉丝对于明星和电视剧相关的内容最为感兴趣,这也是较为符合人们对于粉丝群体的直观印象的,说明收集的数据很好地反映了粉丝群体的实际情况。
4.总结
艺人的商业价值主要体现在其关注热度以及其个人的形象塑造,积极的形象往往比负面的形象更能吸引粉丝的追捧。而粉丝购买相关明星产品,观看明星出演的影视剧均创造了大量的消费。研究粉丝的群体特征,例如兴趣爱好、地区分布方便企业制定有客户群体针对性的项目,这样便可以使利润最大化。而在寻求明星代言时,明星的个人形象关乎到公司产品给消费者的形象,于是艺人的商业价值很大一部分都依赖于其平时所树立的公众形象。
此次试验结果取得了较为精确的结果,给人以多方面直观的印象,但如何增加分析的角度,提高分析方法的精度是我们下一步要做的。
[1]林江豪.一种基于朴素贝叶斯的微博情感分类[J].计算机工程与科学,2012,34(9):160-165.
[2] Kamps J, Marx M, Mokken R J. Using WordNet to measure semantic orientations of adjectives[C]. Proceedings of the 4th International Conference on Language Resources and Evaluation. 2004, IV: 1115- 1118.
[3] 朱嫣岚,闵锦,周雅倩.基于HowNet的词汇语义倾向计算[J].中文信息学报,2006,20(1):14-20.
[4] 卢玲,王越,杨武.一种基于朴素贝叶斯的中文评论情感分类方法研究[J]. 山东大学学报(工学版),2013,43(6):7-11
[5]孙丽华,张积东,李静梅.一种改进的KNN方法及其在文本分类中的应用[J].应用科技,2002,29(2):25-27.[6]VALENTINI G, DIETTERICH T G. Bias-variance analysis of support vector machines for the development of SVM-based ensemble methods[J]. The Journal of Machine Learning Research, 2004, 5: 725-775.
[7] Kim S M, Hovy E. Extracting opinions, opinion holders, and topics expressed in online news media text[C].Proceedings of the ACL Workshop on Sentiment and Subjectivity in Text, 2006:1-8.
[8]徐军,丁宇新,王晓龙.使用机器学习方法进行新闻的情感自动分类[J].中文信息学报,2007,21(6):95-100.
[9]Perter D, Turney, Michael L. Unsupervised learning of semantic oriental on from a hundred-billion-word corpus[R].National Research Council of Canada. 2002 : 359-364.
[10] Mullen T, Collier N. Sentiment analysis using support vector machines with diverse information sources[C].Proceedings of the Conference on Empirical Methods in Natural Language Processing. 2004:412-418.
[11]徐海龙. 明星形象的价值再探讨与进化阶段划分[J]. 现代传播(中国传媒大学学报),2014(02):62-65.
[12]张群. 文本挖掘技术及其在专利信息分析中的应用[B] 1008-0821(2006) 03 -0209- 02.
[13]乐国安,董颖红,陈浩,赖凯声.在线文本情感分析技术及应用.
(作者单位:中国传媒大学)
J94
A
1671-0134(2016)12-077-04
10.19483/j.cnki.11-4653/n.2016.12.031
猜你喜欢
园林科技(2021年3期)2022-01-19 03:17:48
电脑知识与技术(2021年13期)2021-07-19 22:11:53
学生天地(2018年32期)2018-11-07 12:19:32
海峡姐妹(2018年8期)2018-09-08 07:58:48
价值工程(2018年14期)2018-05-03 04:09:18
中国医药导报(2017年6期)2017-04-06 22:01:19
儿童故事画报·发现号趣味百科(2016年6期)2016-08-19 06:37:06
苏州杂志(2016年6期)2016-02-28 16:32:28
读者·校园版(2015年7期)2015-05-14 13:11:40
深圳大学学报(理工版)(2015年5期)2015-02-28 16:22:05
