
网络安全设备联动系统中小文件存储优化方法研究
2016-03-07 11:44程晓荣李玉进李紫君刘雨晨
电脑知识与技术 2015年35期
关键词:网络安全
程晓荣 李玉进 李紫君 刘雨晨
摘要:网络系统在运行过程中会产生大量日志,采用Java编程技术将各安全设备日志转换为XML文件。在对日志文件存储过程中,现有的存储系统硬件成本高,扩展能力差,数据并行访问效率低,难以满足网络安全设备联动系统的需求。因此,该文采用基于HDFS的云存储系统对日志文件进行存储。为了提高基于HDFS的云存储系统中小文件存储效率,该文设计了云存储系统中小文件存储的优化方案,主要在小文件合并和小文件检索方面做了优化。该方案结合网络安全设备联动系统中日志文件的特点,首先是根据不同设备的文件进行分类,然后根据小文件在合并后的大文件中的偏移量进行检索。最后采用3组文件集合对优化方案进行了测试,实验结果表明,在不影响存储系统运行状况的基础上,该方案提高了小文件的存储效率和读取效率。
关键词:网络安全;小文件;Hadoop;存储优化
中图分类号:TP393 文献标识码:A 文章编号:1009-3044(2015)35-0010-02
1 引言
网络系统在运行过程中会产生大量的系统日志、应用日志、安全日志和网络日志,这些日志包含着关于网络运行、安全及状态的数据。随着采集日志的大规模增长,现有的存储系统硬件成本高,扩展能力差,数据并行访问效率低,难以满足网络安全设备联动系统的需求。因此,提供一种更高性能、更低成本、更好可靠性的易于管理的存储平台,才能够帮助该系统用尽可能低的成本应对日益增长的数据存储需求。
HDFS采用主从式架构设计模式(master/slave),一个名称节点(NameNode)和若干数据节点(DataNode)构成HDFS集群[1]。HDFS的这种单名称节点的设计极大地简化了文件系统的结构,然而也因此引发了HDFS的小文件存储效率低的问题。HDFS设计之初的目的是存储大量的大文件,所以需要采用分块策略先将每个文件分块,保存机制是每个文件都占用一个或多个块。因为HDFS中的每个目录和文件的元数据信息都存放在名称节点的内存中,如果系统中存在大量的小文件(指那些比HDFS数据块(默认为64MB)小得多的文件),则无疑会降低整个存储系统的存储效率和存储能力。然而,在网路安全设备联动系统[2]存在着大量的小文件。大量的小文件存在于云存储系统中无疑会降低整个系统的I/O性能。针对这一问题,本文提出云存储中小文件的合并处理方法,以提高小文件的存储效率,提高整个系统的I/O性能。
2 整体方案优化设计
文件的优化方案主要包括4个部分:数据预存储节点的功能设计,小文件合并方案,小文件索引结构的设计以及小文件合并过程的整体设计。
2.1数据预存储节点功能设计
数据预存储节点是在HDFS架构的基础上新增的节点,它位于客户端与名称节点和数据节点之间,主要实现对存储的文件进行预处理,根据文件大小,判断是否属于小文件,对于小文件主要完成存储前的合并,生成索引以及小文件检索时的文件分离等功能。增加数据预存储节点之后,在数据存储的过程中,数据的流向由从客户端直接到数据节点变成了由客户端先到预存储节点再到数据节点。
2.2小文件合并算法设计
当客户端写入小文件时,首先根据小文件的类型对数据预存储节点进行分组。然后分别将每个分组中的小文件合并成大文件,此时,生成相关小文件索引信息及元数据信息。最后将合并后的文件和相关的元数据,按照原HDFS写入文件的方式一同上传至HDFS中,其中第二类元数据信息由数据预存储节点进行存储,第一类元数据信息由名称节点进行存储,数据节点存储合并成的大文件[3]
当客户端需要读取某个小文件时,从名称节点获取小文件所在大文件的元数据信息,然后从数据预存储节点获取第二类元数据信息,从数据节点获取小文件所在的大文件,并在接口中将大文件解档为若干小文件,并将这些小文件缓存在客户端。
为了便于算法描述,对算法里的符号进行定义:File[type][MD5][key]——缓冲区中待合并的文件;type——日志文件的类型(1:主机日志;2:sort日志;3:防火墙日志;4:交换机日志);MD5——文件的MD5值;fi——要合并的第i个文件;xj——合并第j类文件个数。
分组合并算法描述如下:
(1)初始化,定义一个三维数组File[type][MD5][key],type初始化为1,key值初始化为文件的大小;
(2)读入缓冲区的所有文件大小,更新数组File[type][MD5][key],根据文件的类型更新数组的type值,初始化i=1;
(3)采用冒泡排序,分别将数组File[i][MD5][key]从大到小进行排序。首先判断File[i][MD5][key]的大小,如果所有文件的总大小大于64M,开始进行合并,否则退出程序,i++,等待下次分组合并调度;
(4)从最大的文件fi开始分组。如果放入文件fi后,此类文件的总大小小于64M,则存放下一个文件,从数组中把文件fi的记录删除,循环这个过程,直到所有的File[i][MD5][key]文件都合并到一起;
(5)计算每类文件合并后的大小,文件大小达到63M的调用HDFS命令将文件上传到HDFS上,大小小于63M的文件,再从缓冲区中查找文件进行装入,返回(2);
(6)上传成功;
主要是考虑到用户的访问效率,算法中采用将同类日志文件进行分组,无论从写入小文件,还是从读取小文件方面,都能大大提高HDFS的性能:首先减轻了名称节点的负担,在读取小文件方面,不用连接数据节点读取,减少文件读写的I/O操作,节约大量数据传输时间,极大地节省了网络通信开销,降低了HDFS的访问压力,提高客户端访问文件的速率和性能。
当用户删除数据时,把合并后的文件取回数据预存储节点,进行分解,删除指定文件,再与缓存区中已有的文件进行合并。
用户查询文件时,需要对HDFS索引进行查询,同时也需要查询缓冲区里面的文件。
2.3小文件索引结构的设计
在小文件合并之后,仅仅根据名称节点中存储的元数据信息不能检索到小文件,为了提高检索效率,需要为所有小文件构建相应的索引,使用户能够通过索引快速的检索到小文件。小文件索引信息是在小文件合并成大文件之后生成的,保存在数据预存储节点中,通过此类元数据信息,再结合名称节点中的第一类元数据信息,才能正确找到小文件的存储位置。所以小文件的索引信息对于后期的小文件检索极其重要,其中要包含小文件的一些重要信息:File_name类型为String,表示小文件名称;File_size类型为int,表示小文件大小;File_type类型为int,表示小文件类型;Merge_file_nam类型为string,表示小文件合并成大文件后的名称;File_offset类型为int,当前小文件在合并文件中的偏移量;time类型为long,表示文件的写入时间;If_use类型为bool,表示文件是否存在。
2.4小文件合并过程的整体设计
大致流程如下:
当需要写入文件时,首先将数据传输到数据预存储节点,判断文件大小,如果文件大小超过了HDFS数据块的大小,则直接存入数据节点,并将元数据信息写入到名称节点;如果需要写入的文件属于小文件,则先判断小文件的类型,然后根据2.2中设计的小文件合并算法将小文件合并,生成索引信息,在这个合并的过程中,不断地将正在合并的小文件索引信息插入到小文件索引信息列表中,当合并文件块达到合适的大小时,客户端将写文件请求发送到名称节点将合并后的文件存储到相应的数据节点中。
3 实验验证
实验需要搭建Hadoop集群,集群中包括4个节点:一台NameNode,二台DataNode,以及客户端用来提交数据的NameNode。 使用VMware 7.0 来模拟 Linux 环境[4,5台机器上模拟海量小文件的存储和访问操作。本文随机选取了10000个xml日志数据文件,文件大小分布情况为:200kB占1%,300kB占2%,400kB占10%,500kB占20%,600kB占30%,700kB占20%,800kB占10%,900kB占4%,1000kB占3%,可见文件大小集中在400kb到1000kb之间。
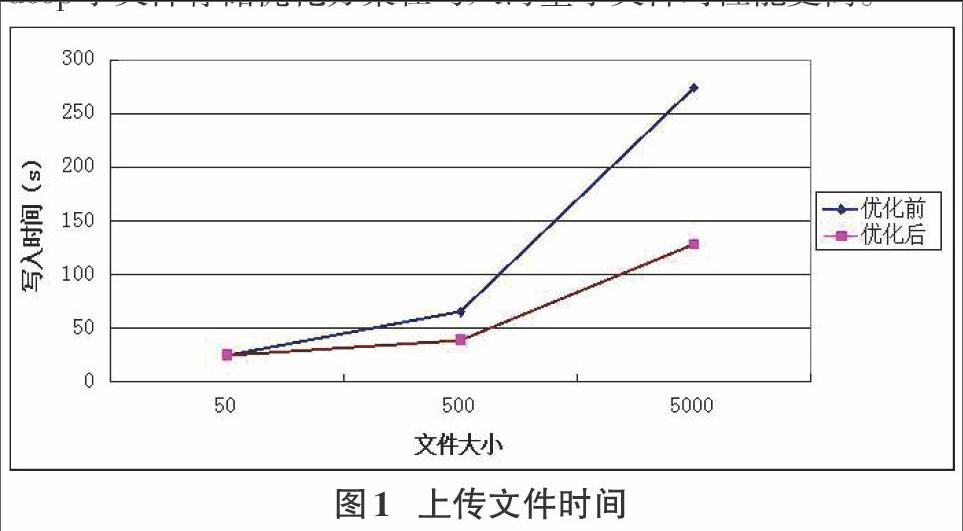
为了直观的反应优化方案在处理小文件和大文件时的系统性能,本文在测试数据中分别选取了100、1000、10000组数据,按照以上测试和执行程序步骤,对文件写入时间进行测试,测试结果如图1所示。实验结果表明,随着文件数量的增多,写入文件所用时间增长趋势的变化缓慢,说明本文设计的Hadoop小文件存储优化方案在写入海量小文件时性能更高。
4 结论
本文首先对网络安全设备联动系统的数据转化为XML文档,然后对文件的特点及文件大小的分布进行了分析。针对HDFS对小文件存储效率低的问题,对小文件存储方案进行了优化,设计了小文件分组合并的算法。最后搭建了Hadoop集群环境,对改进的方案进行测试,实验结果表明,本文设计的Hadoop小文件存储优化方案在写入文件所用时间增长趋势的变化缓慢,说明本方案在写入海量小文件时具有很高的性能,在不影响存储系统运行状况的基础上,该方案提高了小文件的存储效率和读取效率。
参考文献:
[1] 廖彬,于炯,张陶,杨兴耀.基于分布式文件系统HDFS的节能算法[J].计算机学报,2013(05):1047-1064.
[2] 傅颖勋,罗圣美,舒继武.安全云存储系统与关键技术综述[J].计算机研究与发展,2013,50(1):136-145
[3] D L Tennenhouse,J M Smith,W D Sincoskie,et al.A Survey of Active Networks Research[J].IEEE Communications Magazine,1997,35(l):80-86.
[4] 许春玲,张广泉.分布式文件系统HadoopHDFS与传统文件系统LinuxFS的比较与分析[J].苏州大学学报(工科版),2010,04:5-9+19.
[5] 崔杰,李陶深,兰红星.基于Hadoop的海量数据存储平台设计与开发[J].计算机研究与发展,2012(S1):12-18.
猜你喜欢
工会博览(2023年27期)2023-10-24
中国生殖健康(2019年10期)2019-01-07
信息安全研究(2018年12期)2018-12-29
小学生必读(中年级版)(2018年4期)2018-07-05
声屏世界(2015年7期)2015-02-28
警察技术(2014年3期)2014-02-27
