
基于Web条件下数据挖掘算法与数据仓库的接口设计与实现
2016-03-07 11:39魏革
电脑知识与技术 2015年35期
魏革

摘要:随着社会经济的快速发展,数据仓库和数据挖掘研究行业的发展也越来越快。现阶段,这方面的研究热点,也已经集中在对于数据库的分析技术方面,比如对数据仓库数据挖掘等方面。该文首先对数据仓库系统做了概述;而后,对数据挖掘进行了描述;最后,对基于Web的数据挖掘算法与数据仓库接口的设计与应用做了详细的概述。
关键词:数据挖掘;接口;算法;数据仓库
中图分类号:TP311 文献标识码:A 文章编号:1009-3044(2015)35-0003-02
随着科学技术的发展,基于Web的数据挖掘系统已经逐步实行了与计算机技术和数据挖掘技术的融合,可以利用浏览器对企业所存放的数据进行科学有效的分析,对企业当中的一些决策可以起到决定性的作用。但是,在数据挖掘系统中,需要在Web环境下对企业中的仓库数据进行挖掘并且输出结果。因此,需要在Web条件下,对数据挖掘算法和数据管理系统进行接口设计,以便于企业对数据进行更加方便的管理,以利于企业的发展。
1 数据仓库系统
现阶段,有许许多多的各种数据源,比如管理系统、文件系统等含有WEB数据的数据源,这些数据源在质量、种类上也有很多不同的特点和特性,这些因素是直接导致数据来源不统一的主要原因,造成了数据集成极大的不方便性。在数据模式的设计、数据的清晰、数据的转换以及导入更新等方面,也都存在着很大程度的难点。在数据清理方面,必须要准确地发现重复的数据并且判断出是否需要删除。在这个过程当中,数据源是多种多样的,也存在着很多的重复数据。与此同时,每个数据源的质量和录入的方式也是不同的。因此,就需要在数据录入的时候,将重复的数据一一找出并且进行删除处理,保证数据的可靠性。在这个过程当中,就需要用到一些高效的办法来对数据进行有效判断,对数据的层次以及语义进行判别认知。通常情况下,数据源当中的数据可以分为关系数据库、XML半结构化数据等,这些数据在访问方式、数据模式等方面都是不相同的。在数据装入数据库的时候,在保证数据不丢失的情况下,还要保证原本数据模式语义的一致性。我们就需要将数据转换成一种方便转换的统一形式,再把数据装入数据仓库中[1]。
2 数据挖掘
数据挖掘,可以称之为数据库中的知识发现,即从大量的数据当中筛查挖掘出有用的信息。数据挖掘的用途主要是用来从指定数据挖掘任务当中找出模式类型,数据的挖掘可以分为描述和预测两类。数据挖掘具有自动预测趋势以及行为、关联分析、聚类、概念描述以及偏差检测这五个功能[2]。
3 基于Web的数据挖掘算法和数据仓库接口的设计和应用
3.1 接口设计
基于Web的数据挖掘算法,是在挖掘算法集成大B/S机构的数据挖掘系统之后形成的一种数据挖掘算法。数据挖掘算法一般可以利用C/C++、Java以及Delphi等多种计算机语言来编写,每一种算法都可以实现各自的挖掘功能。在系统当中,算法需要在C#开发的NET平台下运行,但并不是所有算法都可以被C#调用。因此,就需要将系统当中的算法编译成独立的组件,多个组件就组成了一个算法库。用户在进行操作的时候,就可以根据用户需求从算法库当中选择相对应的算法组件。算法的输入数据可以分为两种来源,分别是ODBC/ADO获取到的数据库当中的数据和文件当中的数据。算法的输出方式也可以有两种。在基于Web的数据挖掘系统当中,挖掘数据来自于数据仓库,而算法是需要与数据仓库进行接口操作,才能实现挖掘功能的。
在图1的算法当中,算法库的输入接口有两个,分别是与Web服务器连接的输入接口和数据挖掘库的接口。在此算法当中,Web服务器可以调用指定的挖掘算法组件,调用的方式是通过接口向算法库传递。在算法库中,可以通过与数据挖掘库的接口处来向算法库传递输入的数据,此时的算法用ODBC/ADC和数据挖掘库进行连接,对数据库进行操作的时候则是利用SQL语句。其中的数据挖掘库则是在浏览器端的用户字段上来对数据仓库当中的数据进行有效的筛查选择。在算法库接收到输入的数据之后,需要进行相关的运行计算,最终的结果会返回到Web的服务器当中,之后通过浏览器再传递到用户的网页当中,再根据用户的选择来进行储存或者删除。
运用此种算法的优点是能够直接对数据库进行操作,操作更加方便快捷,可以实时获得相对应的数据,在整个操作的过程中不需要缓冲,这样就可以在最大程度上加快相应的速度,对较小的开销进行连续执行,达到改善性能的效果;并且接口的形式简单,数据库当中的数据更新是由数据库进行直接控制的;与此同时,Web的负荷也是相对较小的,系统的稳定性可以在很大程度上得到改善。但是,采用此种方式的算法对内存的要求也是相对较高的,当其中的数据过多的时候,就会影响内存的响应速度;并且对算法的设计要求也会相应的提高,对于数据格式的设计要依赖于数据库,如果在算法成熟的情况下,就需要重新对算法进行设计。
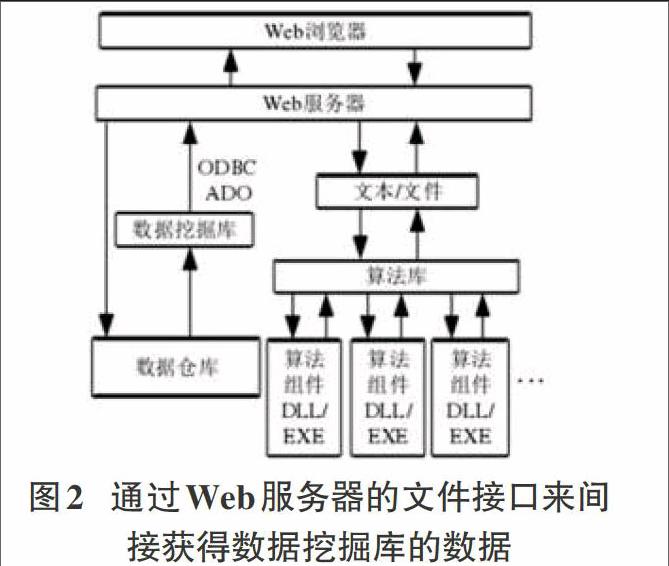
接获得数据挖掘库的数据
在图2的算法中,Web服务器上的文本或者其他格式的文件是此种算法的输入接口。其中Web的服务器会与数据仓库相连,需要根据用户选择的调用数量来对仓库当中的数据进行挖掘操作,之后就可以反馈到Web服务器中。Web服务器向算法库传递的挖掘指令、输入数据流以及输入的参数是利用两者之间的文本或者文件接口来进行的。算法库的输出接口也是通过Web服务器上的文本或者文件来进行的。在算法运行之后,会将计算结果输出到文本或者文件当中,然后再将数据传递到用户的Web浏览器的界面上,最后就会根据用户的选择来对数据进项储存或者删除。
采用此种算法,不管数据库运行速度快慢,数据的提取速度是相当快的,从计算机的硬盘当中对数据的提取通常会比从数据库当中检索的数据要快。即使数据过多,也不会影响运行的速度,系统会将数据以文本或者文件的形式存储在服务器的硬盘上,方便操作。与此同时,输入也相对来说较为简单,对于数据的筛选问题是不用考虑的,只需要根据用户的选择来进行动态选择。但是采用此种方式,在很大程度上也增加了服务器内存的操作次数,读取数据时需要对内存进行多次操作,并且每增加一种算法,就需要为算法开发出独立的输入与输出的格式,适用于每种不同的算法的输出输入需要。
3.2 实现应用
1)如果采用直接对数据挖掘库进行操作算法的模式来对数据库进行操作,此时的算法在集成进入系统的时候就需要以动态链接库的形式进入,而算法当中的DLL文件则需要对接口的入口函数与算法的运算函数进行调用,在对数据库进行操作的时候,语句可以用分配环境句柄、分配链接句柄、链接数据源、分配语句句柄、对数据库进行操作并且选择数据、断开链接以及最后的释放ODBC环境[3]。
2)如果采用通过Web服务器的文件接口来间接获得数据挖掘库的数据的算法来进行操作,就不能对数据库进行直接操作,需要通过服务器端的文件接口来对输入的数据进行获取最后输出结果到文件上。系统当中的算法如果要进入集成的系统当中,就需要以动态链接库的形式来进行集成,在算法中的DLL文件就需要对输入、输出的名称以及服务器上的物理地址进行精确的定义。算法还可以对文件的形式集成进行有效的执行,在Web服务器与文件接口进行连接的时候,需要首先对ADO库的文件进行引入并且定义,而后,利用SQLConnection对象进行数据仓库的连接,充分建立好连接。在连接过程当中,需要利用Command进行SQL命令的执行,将挖掘数据用文件流的语句形式导入到算法的输入文件当中去,用户可以对其结果进行选择。最后,就需要关闭连接,释放对象了[4]。
4 结语
综上所述,运用基于Web的数据挖掘系统,可以很好地将算法和仓库数据进行有效的连接,最大限度地解决了算法与数据仓库的集成问题。算法是利用接口的技术在计算机的环境之下进行企业的仓库数据管理,运用此种方式,可以对企业在管理决策上进行行之有效的管理,为企业的系统增添更多的新算法,保障了系统的延伸扩展性,增强对数据的挖掘性,提高企业的管理经营效益,推动企业经济发展。
参考文献:
[1] 王庆福.谈数据仓库与数据挖掘教学研究[J].中国科教创新导刊,2012(28):179.
[3] 刘新颖,王丽亚.基于Web的数据挖掘算法与数据仓库的接口设计[J].计算机工程,2006(21):88-90.
[3] 阮梦黎.基于半结构化分割的Web热点数据挖掘算法[J].科技通报,2015(4):115-117.
[4] 张艳格,高丽燕.一种基于云计算的海量web数据挖掘算法[J].中国电子商务,2012(18):64-65.
猜你喜欢
大众投资指南(2021年35期)2021-02-16
自然资源信息化(2019年4期)2019-03-29
电力与能源(2017年6期)2017-05-14
电子制作(2016年15期)2017-01-15
山东工业技术(2016年23期)2016-12-23
中文信息(2016年10期)2016-12-12
中国市场(2016年32期)2016-12-06
山东工业技术(2016年15期)2016-12-01
科技视界(2016年3期)2016-02-26
信息通信技术(2015年6期)2015-12-26
