
基于局部稀疏重构度量学习的软件缺陷预测
2016-02-27 02:00:31荆晓远朱阳平董西伟
计算机技术与发展 2016年11期
王 晴,荆晓远,,朱阳平,吴 飞,董西伟,程 立
(1.南京邮电大学 计算机学院,江苏 南京 210003;2.武汉大学 计算机学院 软件工程国家重点实验室,湖北 武汉 430072;3.南京邮电大学 自动化学院,江苏 南京 210003)
基于局部稀疏重构度量学习的软件缺陷预测
王 晴1,荆晓远1,2,朱阳平3,吴 飞3,董西伟1,程 立2
(1.南京邮电大学 计算机学院,江苏 南京 210003;2.武汉大学 计算机学院 软件工程国家重点实验室,湖北 武汉 430072;3.南京邮电大学 自动化学院,江苏 南京 210003)
随着计算机技术的不断发展,如何准确地预测出软件中潜在的缺陷显得至关重要。近年来,研究者们尝试把一些机器学习方法应用到软件缺陷预测领域中,但是这些方法在分类过程中大多使用了传统的欧氏距离。距离度量学习方法通过挖掘训练样本集的特征信息和标记信息,学习得到有效的距离度量,让样本在基于度量矩阵的新特征空间中具有更好的鉴别可分性。将距离度量学习方法引入到软件缺陷预测中,同时融入了局部稀疏重构信息,提出一种新的软件缺陷预测方法,即局部稀疏重构度量学习方法(LSRML)。该方法学习得到的距离度量具有很好的鉴别性,并有效地解决了噪声敏感问题。在软件工程NASA数据库上的实验结果表明,提出的方法具有较好的缺陷预测效果。
度量学习;软件缺陷预测;稀疏表示;局部信息;鉴别性
0 引 言
随着软件在各个领域中的开发规模不断增长,由于软件故障导致巨大损失的事件频有发生,因此如何准确地预测出软件中是否存在潜在缺陷的问题变得十分重要[1-3]。软件缺陷预测(Software Defect Prediction,SDP)技术可以根据软件的基本属性,以及软件模块中的历史缺陷数据等信息,来预测开发的软件模块中是否存在缺陷。它对于提高软件质量、缩短开发周期和控制软件开发成本方面有着重要的意义。
目前,软件缺陷预测技术主要分为动态缺陷预测技术和静态缺陷预测技术两种。动态缺陷预测技术是基于缺陷产生的时间,对软件在生命周期或某些阶段的时间关系的缺陷分布进行预测的技术;静态缺陷预测技术是利用软件中已经存在的缺陷以及能够度量缺陷的度量元,结合一些机器学习模型,预测软件中潜在的缺陷[4-5]。文中主要研究静态缺陷预测技术。
静态缺陷预测方法的关键在于如何充分挖掘已有的缺陷数据,构造出更为精确有效的预测模型。目前,已有研究者将传统的机器学习方法成功地应用在软件缺陷预测领域,例如,压缩C4.5模型(Compressed C4.5,CC4.5)[6]、朴素贝叶斯模型(Naïve Bayes,NB)[7]、支持向量机模型(Support Vector Machine,SVM)[8]、神经网络模型(Neural Networks,NN)[9-10]等。近年来,一些较新的机器学习方法,如稀疏表示、字典学习等,已经被成功运用到软件缺陷预测中。代价敏感字典学习(Cost-sensitive Discriminative Dictionary Learning,CDDL)[11]融合了字典学习和代价敏感技术,解决了缺陷预测中的类不平衡和错误分类代价问题。协同表示分类模型(Collaborative representation classification based SDP,CSDP)[12]使用协同表示技术代替了稀疏表示应用在缺陷预测中,有效降低了计算复杂度,提高了分类器的性能。
尽管现有的软件缺陷预测方法融入了一些机器学习算法的优点,但是预测效果仍有较大的提升空间。现有相关方法在训练模型阶段或预测阶段中,往往使用欧氏距离来度量样本之间的距离。然而,欧氏距离并不能很好地突显样本之间的鉴别信息。因此文中引入距离度量学习方法(Distance Metric Learning),并融入了局部加权和稀疏重构技术,提出了一种新的软件缺陷预测方法,即基于局部稀疏重构的度量学习方法(Local Sparse Reconstruction based Metric Learning, LSRML)。该方法既可以学习鉴别性很好地距离度量矩阵,又融入了稀疏表示中对噪声鲁棒的优点。文中在NASA数据库[13]上的实验结果验证了所提方法的有效性。
1 大间隔最近邻算法
这一节简要介绍距离度量学习中的代表方法,即大间隔最近邻算法(Large Margin Nearest Neighbor,LMNN)[14]。该算法的目标是学习一个距离度量矩阵M,使目标样本与训练集中的近邻同类样本尽量靠近,同时与近邻异类样本尽量远离。
(1)
其中,M为半正定矩阵。
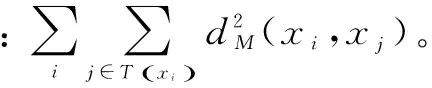
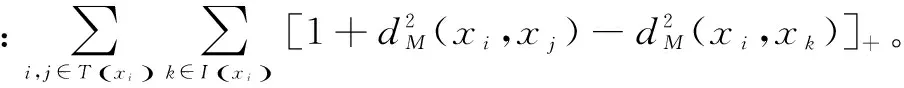
结合上述两个惩罚项得到如下损失函数(lossfunction):
(2)
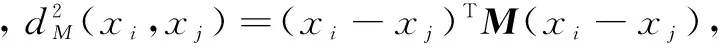
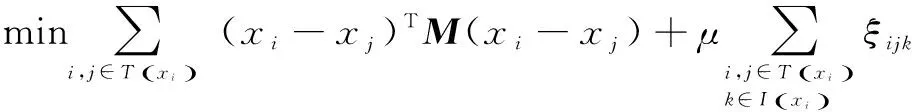
s.t.(xi-xk)TM(xi-xk)-(xi-xj)TM(xi-
xj)≥1-ξijk,ξijk≥0,M≥0
(3)
2 基于局部稀疏重构的度量学习方法(LS-RML)

(4)
其中,‖α‖1用来强制稀疏约束;σ用来平衡重构误差和重构系数的稀疏性。


为了增强距离度量矩阵M的鉴别性,设计了类内稀疏重构项和类间稀疏重构项。对于每个训练样本xi,i=1,2,…,N,把剩余的训练样本划分为两个样本集A和B。其中,A=[ai1,ai2,…,aiN1]表示和xi标记一致的样本;B=[bi1,bi2,…,biN2]表示和xi标记不一致的样本。类内稀疏重构项和类间稀疏重构项分别表示为:
(5)
(6)
其中,β表示样本集A对xi的稀疏表示系数;γ表示样本集B对xi的稀疏表示系数。
为了突出样本近邻信息在稀疏表示时的重要性,在式(5)和式(6)的基础上,让与xi同类的近邻样本所对应的稀疏系数更大,与xi异类的近邻样本所对应的稀疏系数更小,即:
(7)
(8)

其中,r1>r2。
可以看出,在距离相同的情况下,同类近邻样本对应的权重更小,放在最小化的目标函数中,求得的表示系数就越大,这样近邻样本在稀疏表示时就更加重要。
根据上面定义的局部加权类内稀疏重构项和类间稀疏重构项,并借鉴LMNN中最大间隔的思想,则LSRML的目标函数定义为:
M≥0
(9)
式(9)可以使用交替优化(AlternatingOptimization)的方式来求解。目标函数中总共有三个未知参数M,β和γ,先固定M,求解β和γ;然后固定β和γ,求解M。
首先,初始化距离度量矩阵M为欧氏距离度量矩阵,即M=Id×d。此时目标函数转化为:
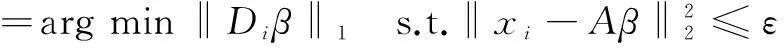
(10)
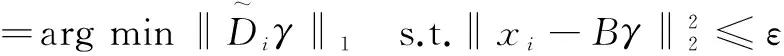
(11)
其中,容错误差ε>0。
式(10)、(11)为标准的l1范数的最小化问题,这和稀疏表示中的目标函数类似,可以采用文献[15-16]中的优化算法求解。
得到β和γ后,目标函数(式(9))可以简化为求解矩阵M的函数:
M≥0
(12)
这是一个典型的半正定规划问题,可以通过一个标准的半正定规划工具包进行求解。文中使用了cvx工具包。
由于M是半正定矩阵,可以将M写成M=WWT,这里W是一个线性转换:d→d。其中,xi通过学习到W不断更新:xi=WTxi,同时通过求解式(10)~(12)不断更新β,γ和M。综上所述,LSRML算法流程可以总结为:
输出:距离度量矩阵M。
步骤1:初始化矩阵M:M=Id×d。
步骤2:令r=1,2,…,循环
(1)根据式(10)和式(11)计算β和γ。
(2)根据式(12)求解得到矩阵M。
(3)分解M=WWT。
(4)更新训练样本xi=WTxi。
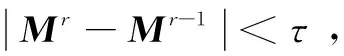
步骤3:输出度量矩阵M=Mr。
3 实 验
本节首先介绍实验所用的数据库,以及缺陷预测的评价指标,然后报告并分析文中LSRML和对比方法的实验结果。
3.1 数据库介绍
实验选用了NASA MDP数据库[13]的5个工程,每个工程代表着美国宇航局(NASA)的软件系统或者子系统,它们包含不同的静态代码度量和相应的缺陷标记数据。这些数据库通过一个bug跟踪系统记录每个模块的缺陷数。NASA MDP数据库的静态代码度量指标包括软件代码量、可读性、复杂度等等。这些分别由代码行数、操作数以及McCabe等度量计算得到。表1汇总了NASA MDP中5个工程的详细信息。
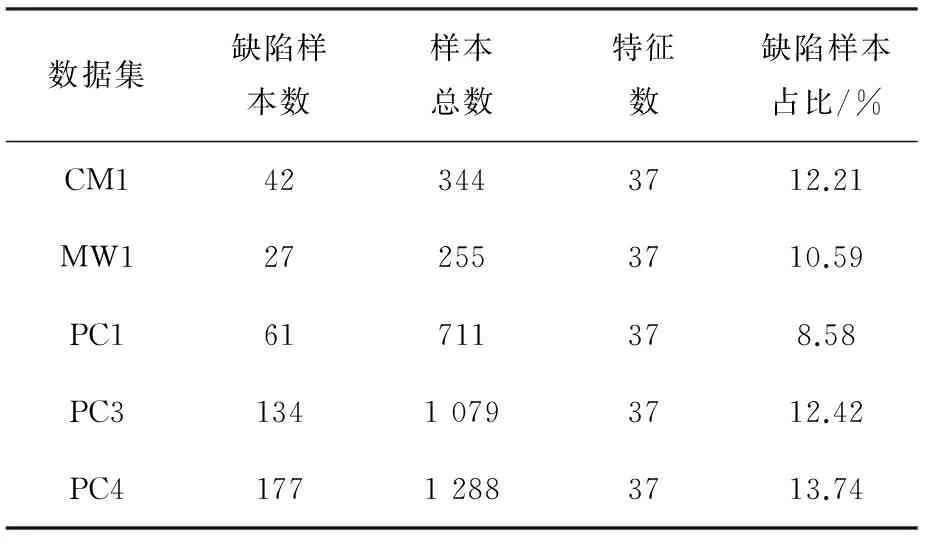
表1 NASA数据集
3.2 性能评价指标
在实验中,使用四种指标来评估方法的缺陷预测效果,即召回率(Recall,Pd)、FalsePositiveRate(Pf)、F-measure和AreaUnderrocCurve(AUC)。
假设A代表有缺陷样本被预测为有缺陷的数量,B代表有缺陷样本被预测为无缺陷的数量,C代表无缺陷样本被预测为有缺陷的数量,D代表无缺陷样本被预测为无缺陷的数量,如表2所示。
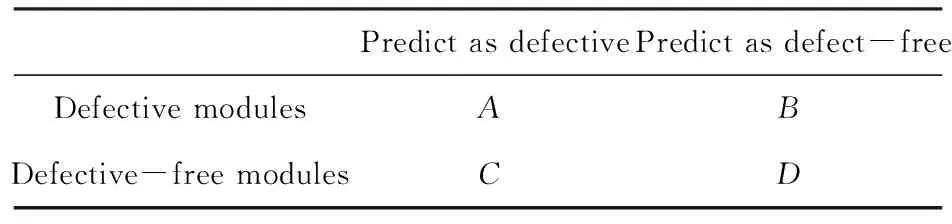
表2 四种预测结果
则以上四种指标定义为:Pd=A/(A+B);Pf=C/(C+D);F-measure=2*recall* precision/ (recall + precision),其中precision=A/(A+C);AUC为ROC曲线下面积。
这四种评价指标值都在0~1之间,一个好的缺陷预测模型应该会有较高的Pd,F-measure和AUC值,以及较小的Pf值。而且F-measure和AUC是综合性评价指标,更加重要。
3.3 实验结果与分析
文中选取了几种代表性的缺陷预测方法作为对比方法,包括CC4.5[6]、NB[7]、SVM[8]和CBNN[10](cost-sensitive boosting neural networks)。此外,由于提出的LSRML方法融入了距离度量学习,所以也选取LMNN[14]作为对比方法之一。实验结果见表3。
分析表3可知,文中提出的LSRML在各个数据库上的缺陷预测效果普遍好于对比方法,尤其是F-measure和AUC评价指标。对于基于传统机器学习方法的CC4.5、SVM、NB和CBNN,LSRML优势较明显,说明了使用距离度量学习得到的度量矩阵M要优于传统的欧氏距离,距离度量学习技术在软件缺陷预测领域是有效的;对于代表性的距离度量学习方法LMNN,LSRML方法的优势说明局部稀疏重构项在缺陷预测时的有效性。
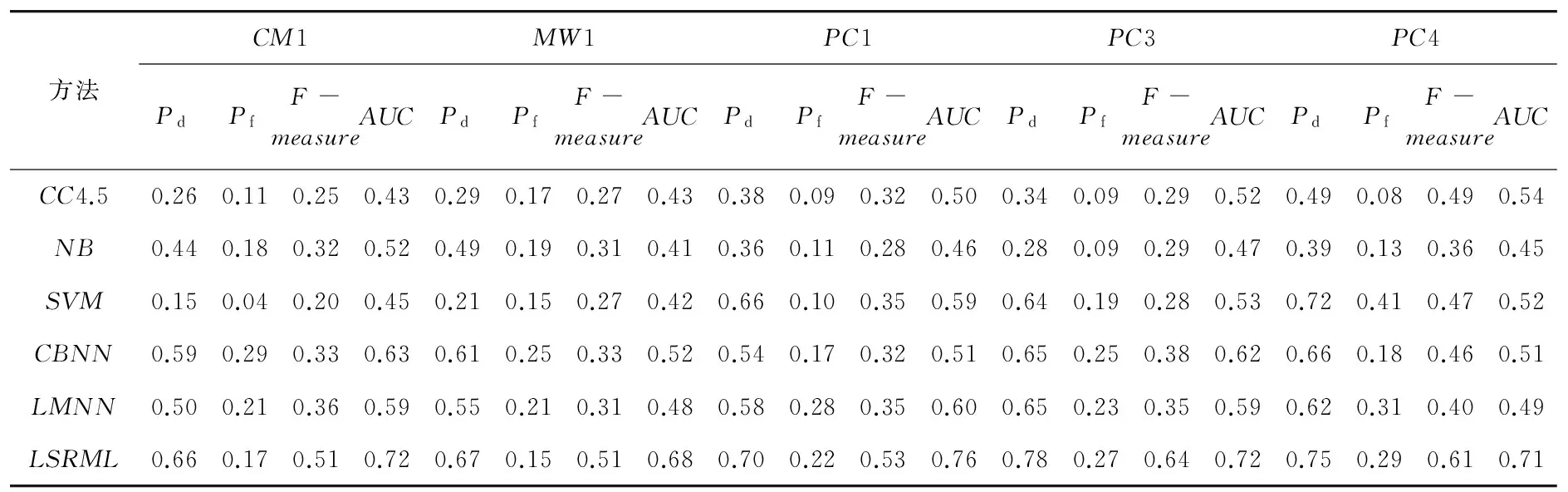
表3 所有方法在NASA MDP数据库上的实验结果
4 结束语
文中首次将距离度量学习方法引入到软件缺陷预测中,并且融入了稀疏重构项和样本的局部近邻信息,提出一种新的软件缺陷预测方法,即LSRML。该方法学习得到的距离度量具有很好的鉴别性。NASA MDP上5工程的数据库表明,LSRML与现有的代表性缺陷预测方法相比,提高了缺陷预测的效果。
[1] 刘英博,王建民.面向缺陷分析的软件库挖掘方法综述[J].计算机科学,2007,34(9):1-4.
[2] 刘义颖,江建慧.基于软件失效链的软件错误行为分类研究[J].计算机技术与发展,2015,25(4):1-5.
[3] 李 娟,陈 斌.一种基于JM模型的软件安全性测试方法研究[J].计算机技术与发展,2012,22(9):246-249.
[4] Catal C,Diri B.A systematic review of software fault prediction studies[J].Expert Systems with Applications,2009,36:7346-7354.
[5] Hall T,Beecham S,Bowes D,et al.A systematic literature review on fault prediction performance in software engineering[J]. IEEE Transactions on Software Engineering,2011,38(6):1276-1304.
[6] Wang J,Shen B J,Chen Y T.Compressed C4.5 models for software defect prediction[C]//2012 12th international conference on quality software.[s.l.]:IEEE,2012:13-16.
[7] Wang T,Li W H.Naïve Bayes software defect prediction model[C]//International conference on computational intelligence and software engineering.[s.l.]:IEEE,2010:1-4.
[8] Elish K,Elish M.Predicting defect-prone software modules using support vector machines[J].Journal Systems and Software,2008,81(5):649-660.
[9] Thwin M M T,Quah T S.Application of neural networks for software quality prediction using object-oriented metrics[J].Journal of Systems and Software,2005,76(2):147-156.
[10] Zheng J.Cost-sensitiveboosting neural networks for software defect prediction[J].Expert Systems with Applications,2010,37(6):4537-4543.
[11] Jing X Y,Ying S,Zhang Z W,et al.Dictionary learning based software defect prediction[C]//Proceedings of the 36th international conference on software engineering.[s.l.]:ACM,2014:414-423.
[12] Jing X Y,Zhang Z W,Ying S,et al.Software defect prediction based on collaborative representation classification[C]//Proceedings of the 36th international conference on software engineering.[s.l.]:ACM,2014:632-633.
[13] Menzies T,Greenwald J,Frank A.Data mining static code attributes to learn defect predictors[J].IEEE Transactions on Software Engineering,2007,33(1):2-13.
[14] Weinberger K Q,Saul L K.Distance metric learning for large margin nearest neighbor classification[J].Journal of Machine Learning Research,2009,10(1):207-244.
[15] Donoho D L,Tsaig Y.Fast solution ofl1-normminimizationproblemswhenthesolutionmaybesparse[J].IEEETransactionsonInformationTheory,2008,54(11):4789-4812.
[16]WrightJ,YangAY,GaneshA,etal.Robustfacerecognitionviasparserepresentation[J].IEEETransactionsonPatternAnalysisandMachineIntelligence,2009,31(2):210-227.
Software Defect Prediction of Metric Learning Based on Local Sparse Reconstruction
WANG Qing1,JING Xiao-yuan1,2,ZHU Yang-ping3,WU Fei3,DONG Xi-wei1,CHENG Li2
(1.College of Computer,Nanjing University of Posts and Telecommunications,Nanjing 210003,China;2.State Key Laboratory of Software Engineering,School of Computer,Wuhan University,Wuhan 430072,China;3.College of Automation,Nanjing University of Posts and Telecommunications,Nanjing 210003,China)
With the development of computer technology,how to predict the potential defects in software project preciously is an important topic.Recently,researchers have introduced some machine learning methods into the software defect prediction field.However,they usually utilize the traditional Euclidean metric in classification phase.Distance metric learning can learn an effective distance metric by exploiting the feature and label information of training sets,which makes the original samples hold better discriminability in the new feature space.The distance metric learning is introduced into the software defect prediction field,and a novel software defect prediction approach called Local Sparse Reconstruction based Metric Learning (LSRML) is proposed.It incorporates the local sparse reconstruction information into the distance metric learning scheme.The learned distance metric not only has favorable discriminability,but also effectively handles the noise problem.The experiment results on the NASA projects demonstrate the effectiveness of the proposed approach.
distancemetric learning;software defect prediction;sparse representation;local information;discriminability
2016-01-24
2016-05-11
时间:2016-10-24
国家自然科学基金资助项目(61272273)
王 晴(1993-),女,研究生,研究方向为软件工程、机器学习与数据挖掘;荆晓远,教授,博士生导师,研究方向为模式识别、图像与信号处理、信息安全、机器学习与数据挖掘。
http://www.cnki.net/kcms/detail/61.1450.TP.20161024.1114.050.html
TP181
A
1673-629X(2016)11-0054-04
10.3969/j.issn.1673-629X.2016.11.012
猜你喜欢
数学小灵通·3-4年级(2024年2期)2024-05-15 02:02:44
数学年刊A辑(中文版)(2022年4期)2022-02-16 08:18:02
摄影世界(2022年1期)2022-01-21 10:50:14
黑龙江工业学院学报(综合版)(2020年6期)2020-08-11 07:16:08
数学年刊A辑(中文版)(2019年3期)2019-10-08 07:34:38
知识经济·中国直销(2018年12期)2018-12-29 12:22:14
成都信息工程大学学报(2018年3期)2018-08-29 01:08:44
商周刊(2017年6期)2017-08-22 03:42:36
电子元器件与信息技术(2017年4期)2017-03-08 02:15:59
山东大学法律评论(2016年0期)2016-08-16 03:24:12
