
基于大数据的时间序列异常点检测研究
2016-02-24 03:45程艳云张守超
计算机技术与发展 2016年5期
程艳云,张守超,杨 杨
(南京邮电大学 自动化学院,江苏 南京 210023)
基于大数据的时间序列异常点检测研究
程艳云,张守超,杨 杨
(南京邮电大学 自动化学院,江苏 南京 210023)
针对传统时间序列异常点检测方法在处理大量数据时检测精度与效率低下的缺陷,文中提出一种基于大数据技术的全新时间序列异常点检测方法。首先介绍了传统时间序列异常点检测方法并分析了其缺陷。其次介绍了基于大数据方法的理论推导,包括特征提取、奇异点检测及异常点判别,具体为采用大数据方法将海量序列分解为周期分量、趋势分量、随机误差分量及突发分量四个不同分量,对不同分量进行特征提取并根据特征提取结果进行奇异点检测,并在此基础上利用序列特点判别奇异点是否为异常点。最后通过实验分析对比验证大数据方法的可行性与效率。实验结果表明,基于大数据方法的时间序列异常点检测相比于传统的方法具有更高的检测精度与更快的检测速率。
异常点检测;时间序列;大数据;特征提取
0 引 言
所谓异常点,即数据集中与数据的一般行为或对象不一致的数据对象,异常点一般也称作离群点[1]。数据的不确定性是产生异常点的主要原因,数据的不确定性可分为存在的不确定性和值的不确定性两类[2]。简而言之,就是数据测量和收集误差、自然变异、数据不确定性等原因导致异常点的出现。异常数据往往包含着很重要的信息,对实验结果与分析起到了重要作用,一方面不应该将异常数据简单地作为错误数据来处理,另一方面应当寻找有效的方法去检测并挖掘这些异常点所隐含的意义。
时间序列是由记录值和记录时间组成的元素的有序集合[3]。时间序列的分析主要包括趋势分量、季节性分量、突发分量以及随机误差分量,而趋势分量与随机误差分量是时间序列中异常点检测的重要研究方向。文中将在分析时间序列特性的基础上,比较传统时间序列异常点检测方法的各自优缺点,结合大数据算法,研究如何采用大数据方法来对时间序列进行异常点的检测与分析,从而提高检测的效率与精度,为下一步的数据处理提供帮助。
1 传统时间序列异常点检测
为了减少异常点对实验结果的干扰,需要对异常点进行检测并处理。异常数据的挖掘主要使用偏差检测,包括聚类法、序列异常法、最近邻居法、多位数据分析法等[4-5]。通过偏差检测可以在一定程度上发现异常点,但是也存在部分缺陷,比如导致两种不良的后果:(1)掩盖现象,即未能识别出某些真正的离群点;(2)淹没现象,即将正常点误判为离群点[6]。
时间序列的一个最重要特征就是具有时间属性,序列值之间必须按照时间先后顺序进行严格的排序。针对这一特性,产生了很多种时间序列异常点检测方法,主要分为以下几大类:
(1)统计学方法[7-9]。
主要包括基于统计的异常点检测算法、基于密度的方法、基于距离的异常点的检测算法等等,然而这类方法需要在多维空间中寻找异常点,并不适用于一维的时间序列,并且在使用统计学方法前必须得知道数据的分布模型,这就涉及到模型参数的问题,但是这些信息一般事先是不知道的。
(2)机器学习方法[10-12]。
机器学习方法主要可以划分为两大类:一是人工神经网络,二是支持向量机。两类方法也是各有优缺点:人工神经网络在处理小规模问题上具有很好的应用效果,但是对于大规模的问题,人工神经网络的构造将会非常复杂,因此不能很好地往大规模问题上扩展;相对于人工神经网络,支持向量机不仅具有相同的处理能力,而且在计算效率上也有很大的提高,但是支持向量机在理论方面或者在建立模型方面都相对比较复杂,因此在实际应用中存在一定的难度。
(3)其他方法[13-16]。
除了上述提及的两大类方法,还包括基于空间的方法、基于小波的方法、基于AR模型的方法等等。基于小波的方法虽然在查询性能上有所改进,但是对短期的异常模式无法检测;而基于AR模型的方法需要知道时间序列模型。
虽然时间序列异常点检测研究领域出现了很多算法,但是这些算法还不够成熟,尤其面对日益增加的数据量,传统的时间序列异常点检测方法在效率与精度上都达不到预期要求,所以必须采用新的方法来进行处理。
2 基于大数据的异常点检测算法
由于时间序列具有结构简单的特点,传统时间序列异常点检测方法面临的主要问题在于时间序列特征难以提取,而且面对海量数据时,传统方法在处理能力上已显得力不从心。为了解决这两大问题,文中在时间序列基本特点的基础上,结合全新的大数据处理算法,提出一种新的时间序列异常点检测方法。通过分析隐藏在海量数据背后的特征,提取新的时间序列特征进行分析,从而提高预测效率与精度,改进预测速率,克服传统方法的缺陷。
时间序列由周期分量、趋势分量、突发分量及随机误差分量四个分量组成[17],每个分量均具有不同的特征。文中将先对四个分量进行特征提取并根据特征提取结果进行奇异点检测,然后结合四个分量共同特点进行异常点检测,提高检测精度与速率。图1为基于大数据方法的异常点检测方法流程图。

图1 基于大数据的时间序列异常点检测流程图
1)周期分量特征提取。
时间序列中周期分量的特征提取主要为时间序列周期的确定,一般的周期确定方法有傅里叶变换、小波变换、差分计算等[18]。文中将根据时间序列周期特点,结合大数据处理方法,采用一种全新的方法来确定周期L。首先根据式(1)对时间序列X{x1,x2,…,xM}(xi范围为V1-V2)进行差分计算得到矩阵A(其中m>30*48,n>50),如下所示:
(1)
对矩阵A的每一行进行线性拟合,参数分别记为(a1,a2,…,am-1),(b1,b2,…,bm-1),将A的每一行下标分别代入对应的Y=aN+b中得到对应的A',如式(2)所示。
采用最小二乘法(见式(3))计算A与A'每行最小误差,其中首次出现最小误差的行数即为周期L。

(2)
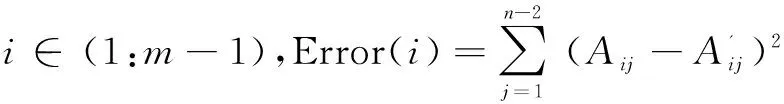

(3)
2)趋势分量特征提取。
周期分量特征的正确提取是进行趋势分量特征提取的前提条件。通过周期分量特征提取得到周期L,将时间序列X以周期L进行划分得到矩阵B,其中xM为时间序列X最后一个数据,xM之后数据均为空值NA。
(4)
矩阵B具有两个方向的特征坐标,同一行内所有点代表处于同一周期的所有时间点的集合,同一列内的所有点代表处于不同周期同一位置的点的集合。将矩阵B的每一列依次取出,得到共计L个时间序列{x1,xL+1,…,xN*L+1},{x2,xL+2,…,xN*L+2},…,{xi,xL+i,…,xM},{xi+1,xL+i+1,…,NA},…,{xL,x2L,…,NA},分别记做L1~LL。其中,每个Li序列均有N个数据(xM所在列之后序列最后一位数值均为NA)。
图2展示了时间序列X及经过趋势分量提取之后的序列X'。图(a)中,X坐标表示时间点,Y坐标表示序列值大小;图(b)中,X坐标表示不同周期,Y坐标表示单周期长度,Z坐标表示序列值大小。
对所有序列Li分别进行如下操作:
(1)如果序列中存在NA,则将NA剔除,序列长度变为N-1;
(2)对处理后的Li进行聚类分析[19],离群点划入奇异点E。
对于序列Li内的所有点,其本质为序列X内所有周期内相同位置的点的集合,排除突发分量和随机误差影响,理论上具有相同的分布特性。若序列Li趋势分量为固定值,则Li内所有点处于同一条水平直线上,该直线之外的所有点则均认为是奇异点;若序列Li趋势分量按照一定的规律分布,则不按照该规律分布的点视为奇异点;若序列Li趋势分量为随机分布,则需要先找出随机分布范围[min,max],在该范围之外的点均为奇异点。

(a)周期特征提取前时间序列X

(b)趋势分量提取后序列X
3)随机误差分量Rt特征提取。
传统方法一般认为时间序列随机误差分布函数服从正态分布,其均值为0,方差则根据实际情况确定。而在文中方法中,将根据时间序列的实际情况来确定随机误差分量的分布函数,具体方法如下所示:
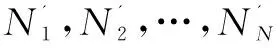
(5)
根据所有的Rt(i),可以得到序列X的随机误差分布模型,记为Xe~Fe(r)。
(6)
根据随机误差分布模型,即可得到序列X的随机误差分布范围,为下一步的判别奇异点是否为异常点做好准备工作。
4)突发分量Bt特征提取。
突发分量特征提取是判别奇异点是否为异常点的前提,分别对N1~NN-1行做如下操作:
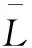
(7)
(8)
(3)如果Sum(i)>Sum(i)',则序列Ni内数据均为突发点,否则序列Ni内数据不为突发点。
突发分量特征Bt提取之后,判别奇异点E是否属于Bt或者Rt范围内,若是,则该奇异点不是异常点,若否,则该奇异点为异常点。方法总体步骤如下所示:
fori=1:m
计算A得到周期L
end
then
计算得到B(N*L)
fori=1:L
对B的每列进行趋势分量提取;
分析得到奇异点E:{e1,e2,…,en};
end
提取突发分量特征Bt;
then
提取随机误差分量特征Rt;
forE
if(ei属于Bt或者在Rt范围内)
ei为非异常点
else
ei为异常点
end
3 实验与结果
在通信网络中,各项核心性能指标(KPI)均以时间序列形式表示。以单一小区为例,单一KPI一年数据量长度为48*365。文中将以通讯网络中时间序列为例,分析并比较传统时间序列异常点检测方法与基于大数据的时间序列异常点检测方法各自的优缺点。
任取某一小区某一KPI(RRC设置成功率)半年数据为例,取m=400,n=100进行差分处理得到矩阵A(400*100),并对矩阵A的每一行进行线性拟合并采用最小二乘法计算误差得到Error矩阵,取矩阵Error首次出现最小值行数记为周期L,得到最优参数L=48,按照L=48得到矩阵B。对矩阵B以周期为单位画作图(按行)和以相同时间点作图(按列),见图3。
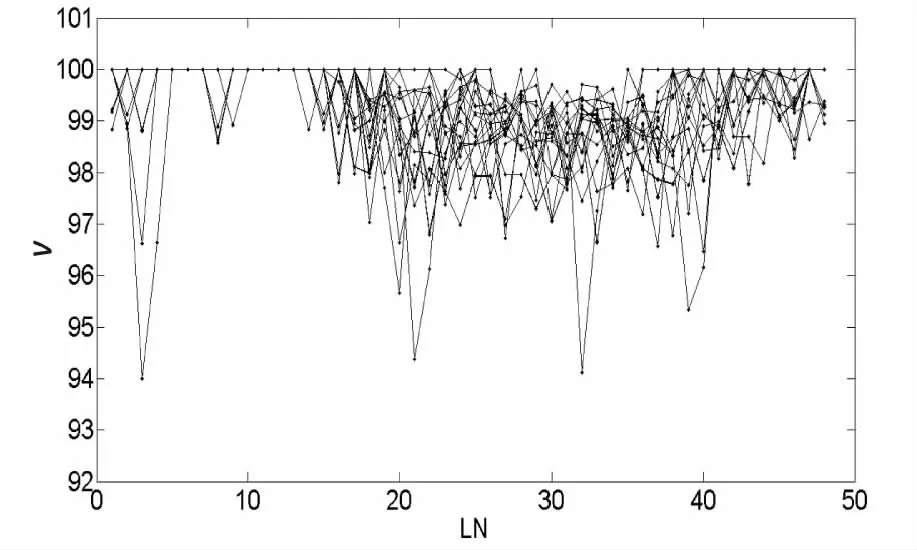
(a)L-V维度矩阵B
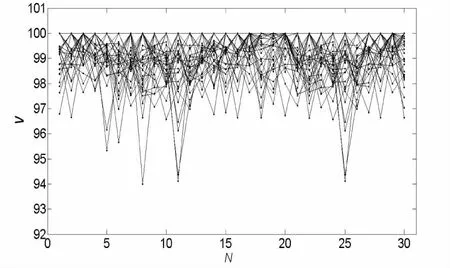
(b)N-V维度矩阵B
提取矩阵B的每一列得到不同的时间子序列Li,对于所有的序列Li,判别其趋势分量特征。若趋势分量为固定值,采用聚类或线性拟合进行奇异点确定[20];若趋势分量为规律分布,根据规律进行奇异点确定;若趋势分量为随机分布,根据分布函数进行奇异点确定。
图4分别展示了矩阵B的三种不同趋势分量分布奇异点确定方法。

(a)趋势分量为零
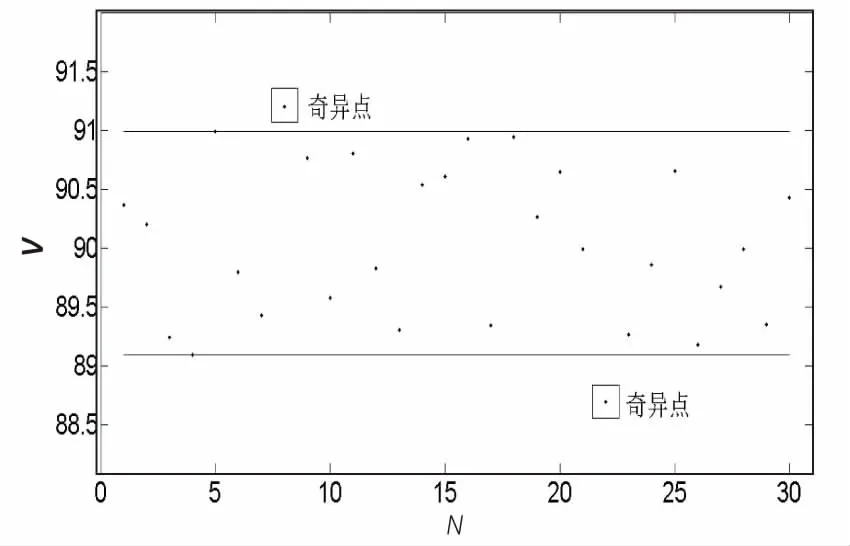
(b)趋势分量随机分布
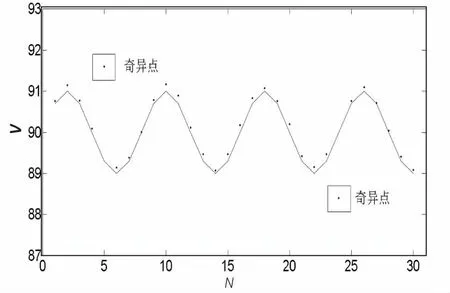
(c)趋势分量规律分布
如图(a)中所示,对于序列Ni内所有点理论均为固定值,即所有点的集合为一条直线,直线之外归为奇异点;图(b)中所有点为随机分布,找出分布的上下区间,取上区间的前5%和下区间的后5%的点记为奇异点;图(c)中,表示趋势分量呈一定的周期分布,在此周期之外的点为奇异点。
奇异点E提取过后,进行随机误差分量特征提取,按照大数据算法公式,可以得到整体分布函数为:
统计每个周期的分布函数,通过计算可以得到随机误差分布函数为:
Xe~Fe(x)=
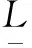
突发分量特征提取结束之后,进行最后一步计算,判别奇异点是否为突发分量或者在随机误差范围内。
图5为基于大数据方法的异常点检测算法、基于距离的异常点的检测算法[21]、基于人工神经网络的异常点检测方法[22]、基于AR模型方法的异常点检测方法[23]结果对比图,其中虚线线条对应点即为异常点。
表1为上述四种方法对于不同数据量(短期:30*48个数据量;长期:12*30*48个数据量)的检测精度、检测效率、检测速率对比结果。

(a)基于大数据
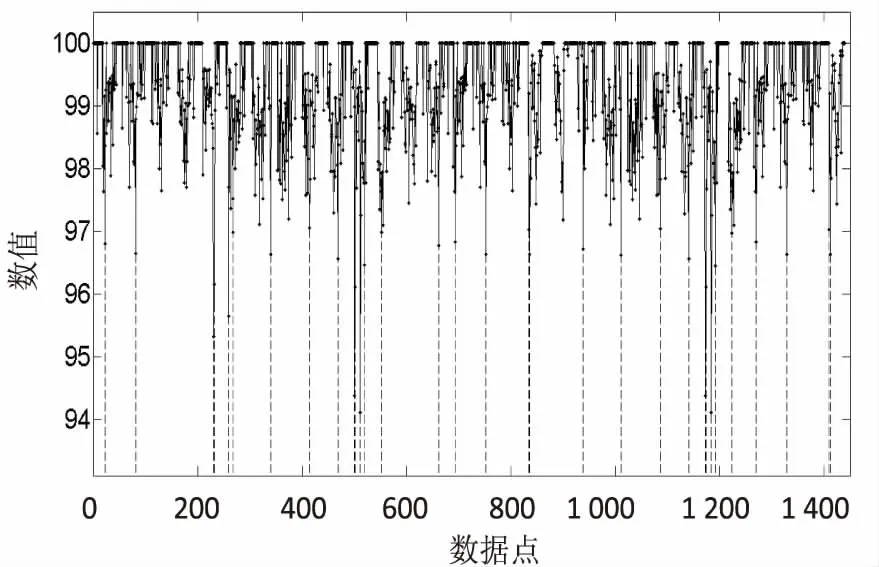
(b)基于距离

(c)基于人工神经网络

(d)基于AR模型
检测精度=正确的检测结果数/异常点总数值* 100%
检测效率=正确的检测结果数/检测结果数* 100%
检测速率=完成一次检测所需时间(s)
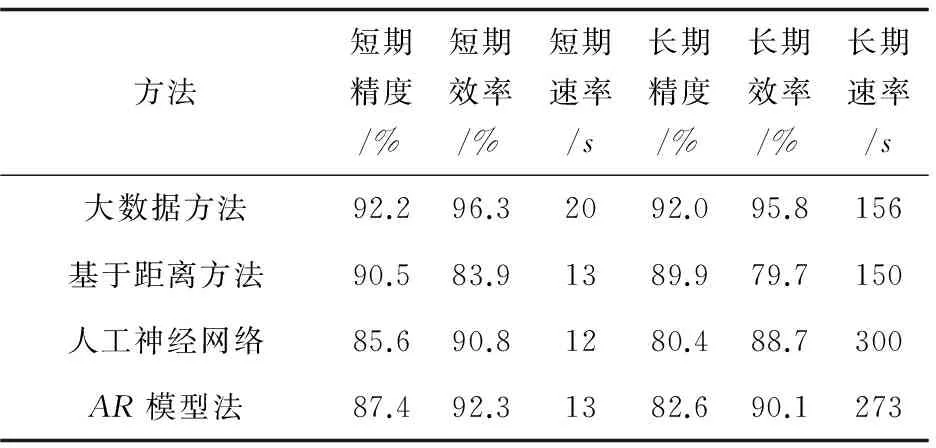
表1 短/长期检测精度、效率、速率结果对比
通过实验结果可以看出,基于大数据的时间序列异常点检测方法在短期异常点检测中与传统方法相比在检测精度、检测效率上有一定的改进,但在检测速率上稍微逊色一点;但是在面对大量的长期数据时,基于大数据的时间序列异常点检测方法在检测精度与检测效率上均比其他方法有很大的提高,在检测速率上相比于其他方法,基于大数据的方法具有更快的速率。
4 结束语
面对日益增长的数据量,文中采用大数据方法,基于时间序列特征提出了一种全新的时间序列异常点检测方法,并通过实验分析该方法的可行性与效率,达到了预期要求。同时作为刚刚兴起的大数据方法,还有许多需改进的地方,将来的工作需要对算法做进一步的改进,提高短期预测速率、长期预测精度与效率等。
[1] 曹忠虔.时间序列异常检测的研究[D].成都:电子科技大学,2012.
[2] 郭 春.基于数据挖掘的网络入侵检测关键技术研究[D].北京:北京邮电大学,2014.
[3]BoxGEP.时间序列分析——预测与控制[M].上海:机械工业出版社,2011.
[4] 杨金伟.基于距离和信息熵的不确定异常点检测研究[D].昆明:云南大学,2011.
[5] 刘良旭,乐嘉锦,乔少杰,等.基于轨迹点局部异常度的异常点检 测算法[J].计算机学报,2011,34(10):1966-1975.
[6] 刘丹丹,陈启军,森一之.线性回归模型的多离群点检测方法及节能应用[J].信息与控制,2013,42(6):765-771.
[7] 胡世杰,钱宇宁,严如强.基于概率密度空间划分的符号化时间序列分析及其在异常诊断中的应用[J].振动工程学报,2014,27(5):780-784.
[8] 苏卫星,朱云龙,胡琨元,等.基于模型的过程工业时间序列异常值检测方法[J].仪器仪表学报,2012,33(9):2080-2087.
[9] 杨 越,胡汉平,熊 伟,等.一种基于超统计理论的非平稳时间序列异常点检测方法研究[J].计算机科学,2011,38(6):93-95.
[10] 王佳玮.决策支持中基于时间序列数据的异常点检测[D].合肥:中国科学技术大学,2014.
[11] 陈 敏.基于BP神经网络的混沌时间序列预测模型研究[D].长沙:中南大学,2007.
[12] 崔万照,朱长纯,保文星,等.基于模糊模型支持向量机的混沌时间序列预测[J].物理学报,2005,54(7):3009-3018.
[13] 庄雪鹏.基于小波的时间序列中异常点的检测[D].南京:南京大学,2013.
[14] 张建平,李 斌,刘学军,等.基于Hadoop的异常传感数据时间序列检测[J].传感技术学报,2014,27(12):1659-1665.
[15] 王 骏,钟富礼,王士同,等.基于移相加权球面单簇聚类的周期时间序列异常检测[J].自动化学报,2011,37(8):984-992.
[16] 张玉飞,董永贵.一种时间序列异常检测用参数化熵滤波器[J].机械工程学报,2011,47(22):13-18.
[17] 张 蕾.非线性时间序列的高阶统计特征提取和趋势分析[D].沈阳:沈阳航空航天大学,2012.
[18] 龚祝平.混沌时间序列的平均周期计算方法[J].系统工程,2010,28(12):111-113.
[19] 韩 娜.聚类算法在时间序列中的研究与应用[D].广州:广东工业大学,2011.
[20] 闫秋艳,夏士雄.一种无限长时间序列的分段线性拟合算法[J].电子学报,2010,38(2):443-448.
[21]RasheedF,AlhajjR.Aframeworkforperiodicoutlierpatterndetectionintime-seriessequences[J].IEEETransactionsonCybernetics,2014,44(5):569-582.
[22]Buzzi-FerrarisG,ManentiF.Outlierdetectioninlargedatasets[J].ComputersandChemicalEngineering,2010,35:388-390.
[23]LiST,ChengYC.AstochasticHMM-basedforecastingmodelforfuzzytimeseries[J].IEEETransactionsonCybernetics,2010,40(5):1255-1266.
Research on Time Series Outlier Detection Based on Big Data
CHENG Yan-yun,ZHANG Shou-chao,YANG Yang
(College of Automation,Nanjing University of Posts and Telecommunications,Nanjing 210023,China)
According to the detection accuracy and efficiency limitation of traditional time series outlier detection methods when dealing with a large amount of data,a new time series outlier detection method is put forward,which is based on the big data technology.Firstly,the traditional time series outlier detection methods are introduced,analysis of their defects.Secondly,it introduces the theoretical derivation of big data method in this paper,which can be divided into feature extraction,abnormal detection and outlier distinguish.The massive series is decomposed into four different components,including periodic component,trend component,random error component and burst component.Then the feature is extracted to four components and abnormal detection is made according to the result of extraction.On this basis it determines whether abnormal point is outlier by series characteristic.Finally,the feasibility and efficiency of big data approach is verified by experiment analysis and comparison.The results show that the big data method has higher precision and rate compared with traditional methods.
outlier detection;time series;big data;feature extraction
2015-07-06
2015-10-14
时间:2016-05-05
江苏省自然科学基金(BK20140877,BE2014803)
程艳云(1979-),女,副教授,硕士生导师,研究方向为自动控制原理、网络优化;张守超(1991-),男,硕士研究生,研究方向为大数据挖掘在通信网络中的应用。
http://www.cnki.net/kcms/detail/61.1450.TP.20160505.0817.046.html
TN915.07
A
1673-629X(2016)05-0139-06
10.3969/j.issn.1673-629X.2016.05.030
猜你喜欢
第一财经(2021年6期)2021-06-10
基层中医药(2021年12期)2021-06-05
智族GQ(2019年9期)2019-10-28
电子制作(2019年15期)2019-08-27
电子制作(2018年19期)2018-11-14
英美文学研究论丛(2018年1期)2018-08-16
Coco薇(2017年9期)2017-09-07
自动化学报(2017年11期)2017-04-04
纺织服装流行趋势展望(2016年2期)2016-05-04
汽车科技(2015年1期)2015-02-28
