
基于复杂网络及神经网络挖掘用户兴趣的方法
2016-02-23 12:12张兴兰
计算机技术与发展 2016年12期
张兴兰,刘 炀
(北京工业大学 计算机学院,北京 100124)
基于复杂网络及神经网络挖掘用户兴趣的方法
张兴兰,刘 炀
(北京工业大学 计算机学院,北京 100124)
按照用户的兴趣提供个性化服务是提高企业商业价值最有效的方案。针对目前从用户行为中挖掘用户兴趣方法的不足,提出一种依据用户使用软件的时间序列构建复杂网络及依据神经网络聚类挖掘用户兴趣软件的方法。在计算用户对于软件的兴趣度时,综合考虑用户使用软件的时长以及复杂网络中相邻节点的贡献度,包括节点的度、节点介数、聚集系数来判断节点的重要性,挖掘用户对于软件的兴趣度,形成软件兴趣社区。再利用神经网络算法对用户兴趣社区中的软件进行聚类,形成用户的兴趣软件集。实验结果表明,该方法能够较准确地挖掘用户感兴趣的软件集,并且在精确率和召回率上较其他方法有一定的提高。
用户行为;兴趣挖掘;复杂网络;word2vec
0 引 言
近年来,机器学习领域吸引了越来越多的关注和研究。随着信息科技的进步、人类行为学的发展,国内外的研究学者已经将用户行为分析挖掘的理论进行了实践研究,并逐步转入商业应用的阶段,取得了良好成效。大量的研究表明,根据用户行为日志挖掘用户兴趣具有一定的研究意义和应用价值。其中,Ford等[1]采用AprioriAll序列规则挖掘算法对用户访问站点的日志进行研究分析,获取用户的访问兴趣,并根据用户的兴趣设置广告投放,提高了网站的商业价值,但是AprioriAll算法只适用于挖掘用户感兴趣的关联序列,不适用于挖掘用户兴趣的排列顺序。李建廷等[2]提出了基于用户浏览动作分析用户兴趣度的计算方法,充分考虑了用户访问次数、访问动作、访问速度三种访问模式下的用户兴趣度的计算方式,并利用BP神经网络将这三种模式下的用户兴趣度进行融合,取得了良好的实验效果。这对用神经网络算法研究用户兴趣度的融合以及聚类提供了帮助,但是BP神经网络对于网络的初始权重十分敏感,不同的初始化值往往会造成不同的训练结果,这很容易造成偏差。王微微等[3]提出了一种基于用户行为日志挖掘用户兴趣的模型,结合用户的浏览内容和行为模式建立用户兴趣向量,再根据期望最大化的计算方法实现用户聚类,建立最终的用户兴趣模型。该模型虽然可以识别用户的购买兴趣,却没有充分考虑用户行为之间的顺序,即行为的时间序列关系。王梓等[4]提出了一种基于复合关键词向量空间的方法,最大限度地将用户感兴趣的关键词建立关联关系,但其选用的关键词是基于产品属性的,其方法不具有普遍适用性。
复杂网络技术是大数据处理技术的一种,是从复杂性科学角度出发,探索隐藏在大数据中真正的数据价值。复杂网络主要是依靠一切事务都具有相互作用的表现(例如WWW中网页之间的链接关系、文章之间的引用关系和超市中啤酒尿布的关联关系),利用网络的视角建立数据模型,挖掘数据规则,并通过复杂网络的小世界效应和无标度特性计算网络中节点的重要性,形成网络节点的重要性序列。聚类是数据挖掘中的一个重要组成部分,是通过度量样本间的相似性,发现隐藏在底层的关联性数据的又一种常见方法。
为了从用户使用软件的行为日志中获取用户感兴趣的软件,应用复杂网络中的理论知识以及神经网络聚类的方法,先形成用户的兴趣软件集,然后再应用神经网络算法对兴趣软件集中的软件进行聚类,计算用户的兴趣软件集。
1 用户行为日志预处理
现实世界中数据大体上都是不完整、不一致的脏数据,无法直接将数据应用到系统统计中,或者应用效果差强人意。文中的用户行为日志亦是如此,在用户行为日志的采集、打包、发送的过程中,可能会发生结构异常的现象甚至是数据丢失的情况。为了提高数据质量,需要对数据进行预处理。文中行为日志的预处理主要是清洗噪声数据,包括两方面的工作:
(1)删除异常行为:在用户行为日志中,存在某些行为数据结构异常,如数据中没有用户的ID或者没有软件名称,此类数据不具有分析价值,在清洗过程中进行删除。
(2)补全缺失行为:在用户行为日志中,某些用户行为日志的数据并不完善甚至是行为不匹配,如只有软件打开的行为没有软件关闭的行为,或者没有用户的开关机行为却存在软件使用的行为。因此首先需要对缺失行为进行补全,行为的缺失类型主要包括无头无尾型、有头无尾型、无头有尾型。
无头无尾的缺失存在于没有用户开关机行为却存在该用户软件使用行为的数据中。对于此类数据,将该用户的开机行为用该用户最早的软件使用行为补全,关机行为用该用户当日最后一个软件关闭行为补全,将所有行为确定为在同一个开关机会话中发生的。有头无尾、无头有尾的缺失存在于连续收集到用户两次开机的行为而没有关机行为的数据中。这种缺失类型使用补中间值的方法,用两头数据的中间值进行补全,误差较小。若两头无数据时,使用相关的整数值进行补全。噪声数据的处理流程如图1所示。

图1 噪声数据的处理流程
2 构建复杂网络模型
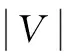
(1)
weight(vi,vj)=Ti*strength(vi,vj)
(2)
其中,strength(vi,vj)(i,j为整数且0≤i
3 节点重要性统计特性
在该方法的用户行为日志中,用户使用软件的时长在一定程度上能够反映软件的重要性,只需要将复杂网络中节点的重要性进行修正即可。根据传播动力学的知识衡量网络中节点的重要性,将网络中的节点作为传播源,通过计算目标节点的传播范围来衡量节点在传播过程中的影响力以及号召力。在一个网络中,节点删除前后网络图联通性的变化能够充分说明该节点是否有足够的能力破坏网络,体现节点的重要性。所以综合考虑复杂网络特性[6]、实用性以及行为数据本身的概率特性,选取节点聚集系数[7]、节点介数[8]和节点度数[9]作为评价节点重要性[10]的指标特性。
3.1 节点聚集系数
节点Vi的聚集系数是与该节点相邻的节点之间的连接数和它们之间所有可能存在的连接数的比值,表示所有相邻节点形成一个小团簇的紧密程度。节点的聚集系数为:
(3)
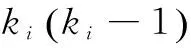
3.2 节点介数
节点Vi的介数是任意两个节点的最短路径中经过节点Vi的路径数与最短路径的总数形成的比值,反映该节点在网络中的影响力,计算公式为:
(4)
其中,nd(ij)表示Vi和Vj间最短路径的数目;nd(ijk)表示Vi和Vj经过Vk的最短路径的数目。
3.3 节点度数
节点的度数表示与该节点相连接的边的个数,度的大小直接反映了该节点对于复杂网络中其他节点的影响力,计算公式为:
(5)

(6)
gi=clu(vi)+bet(vi)+gre(vi)
(7)
其中,gi表示复杂网络G中节点vi的重要性系数的综合值;clu(vi)表示节点vi的聚集系数;bet(vi)表示节点vi的介数;gre(vi)表示节点vi的度;Ti表示节点vi的使用时长;β表示指标调参(经过实验,β取0.6效果较好)。
综上所述,式(7)是综合软件的时长特性和节点在复杂网络中的重要性的综合性指标,是多个判定指标标准化处理后再合并的结果,成为评判软件重要性的综合指标。
4 神经网络聚类
CBOW和Skip-gram模型是基于问答模式计算词向量的,一个问题出现某种答案的现象,也能够表示成一个问题与某种答案构成共现关系的现象。该方法使用word2vec工具[11-13]融合CBOW模型和Skip-gram模型,将软件看成词项,基于前期工作中网络拓扑结构中的共现关系、日志中软件的使用顺序构成的序列上下文形式,计算各个软件的词向量,然后根据向量余弦距离计算软件相似性,在该方法中取距离最近的软件形成聚类。其中,余弦距离公式为:
(8)
5 实验分析
为了验证该方法对用户兴趣软件的挖掘效果,收集了1 000名测试用户在15天之内(2015年8月5日-2015年8月19日)使用电脑软件的行为日志,并人工采集用户选定的兴趣软件与最终的实验结果进行比对。采用精确度P、召回率R、F1值对结果进行评测,其中精确度表明算法挖掘的准确性,召回率表明算法挖掘的覆盖性,F1值是对精确度和召回率两个指标的综合评估率的说明,计算公式为:
(9)
(10)
(11)
其中,Nminingright表示算法挖掘出用户兴趣中正确兴趣的数量;Nmining表示算法挖掘用户兴趣的总数;Nsample表示用户标注的兴趣总数。
将该方法与基于关键词提取用户兴趣模型的算法[14](TextRank)进行比对,结果表明该方法在精确度、召回率、F1值上都有所提高。算法平均值结果对比如表1所示。
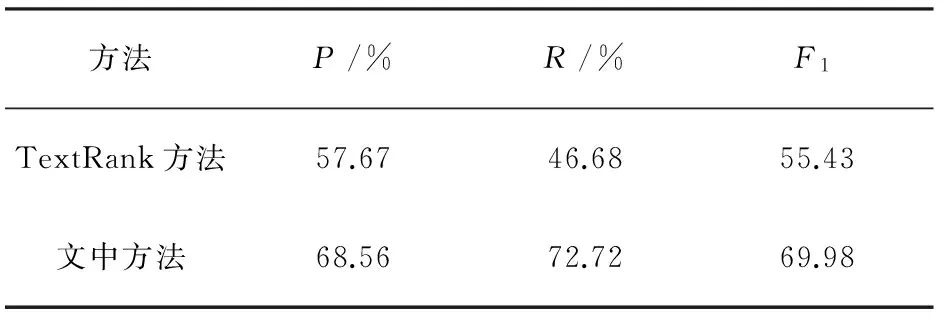
表1 算法平均值结果对比
6 结束语
文中利用复杂网络对用户使用电脑软件的行为日志进行分析建模,并依据复杂网络节点的统计特性计算软件对于用户的重要性,获取用户感兴趣的软件,再利用神经网络聚类对获取的用户兴趣软件进行聚类,形成最终的用户兴趣软件集。文中是复杂网络建模与神经网络聚类相结合获取用户兴趣的方法,与其他算法相比,在准确率和召回率上都有一定程度的提高。但是在计算用户兴趣软件时,是根据用户使用软件的时间序列信息形成的软件词向量,并依据向量的距离形成聚类,没有考虑软件类型之间的联系,而软件的类型往往也是判断软件相似性的一方面,这是文中方法的不足之处。同时如何根据软件使用的时间序列信息以及软件的类型形成软件聚类,也将是下一步的研究工作。
[1]GaolFL.Exploringthepatternofhabitsofusersusingweblogsquentialpattern[C]//2010secondinternationalconferenceonadvancesincomputing,control,andtelecommunicationtechnologies.[s.l.]:IEEEComputerSociety,2010:161-163.
[2] 李建廷,郭 晔,汤志军.基于用户浏览行为分析的用户兴趣度计算[J].计算机工程与设计,2012,33(3):968-972.
[3] 王微微,夏秀峰,李晓明.一种基于用户行为的兴趣度模型[J].计算机工程与应用,2012,48(8):148-151.
[4] 王 梓,高金萍,陈 钊.基于复合关键词向量空间的林产品贸易网站用户兴趣模型[J].计算机工程与科学,2013,35(5):154-160.
[5]FerrerICR,SoléRV.Thesmallworldofhumanlanguage[J].ProceedingsoftheRoyalSocietyBBiologicalSciences,2001,268(1482):2261-2266.
[6] 陈彦萍,张冠男.基于复杂网络的软件方法重要性评估指标[J].计算机应用研究,2016,33(5):1395-1398.
[7] 张 睿.基于点聚集系数和边聚集系数的社区发现算法[D].昆明:云南大学,2013.
[8] 熊金石,李建华,沈 迪,等.基于边介数的信息系统网络节点重要性评估方法[J].科技导报,2013,31(14):53-55.
[9] 任卓明,邵 凤,刘建国,等.基于度与集聚系数的网络节点重要性度量方法研究[J].物理学报,2013(12):522-526.
[10] 刘 通.基于复杂网络的文本关键词提取算法研究[J].计算机应用研究,2016,33(2):365-369.
[11]MikolovT,SutskeverI,ChenK,etal.Distributedrepresentationsofwordsandphrasesandtheircompositionality[J].AdvancesinNeuralInformationProcessingSystems,2013,26:3111-3119.
[12]GoldbergY,LevyO.word2vecExplained:derivingMikolovetal.'snegative-samplingword-embeddingmethod[DB/OL].2014.arXivpreprintarXiv:1402.3722,2014.
[13]XinRong.Word2vecparameterlearningexplained[DB/OL].2014.arXivpreprintarXiv:1411.2738,2014.
[14] 段 准,刘功申.基于TextRank的用户模板构建方法[J].计算机技术与发展,2015,25(10):1-6.
Method of Mining User Interest Based on Complex Network and Neural Network
ZHANG Xing-lan,LIU Yang
(College of Computer Science,Beijing University of Technology,Beijing 100124,China)
Providing personalized service according to the user’s interest is the most effective solution to improve the commercial value.Aiming at the problem of mining user’s interest method from user behavior,a method of constructing complex network based on time series and neural network clustering is proposed,which is based on the user’s software.In the calculation of user interest in software,the using time and adjacent nodes are considered including node degree,betweenness and clustering coefficient to determine the node importance for mining user for the degree of interest for the software,forming of interest community.Then the neural network is used to cluster the software in the user interest community.The experiments show that this method can be more accurate than other methods to mine the user’s interest,and the accuracy rate and recall rate of the algorithm is improved.
user behavior;interest mining;complex network;word2vec
2016-02-04
2016-05-11
时间:2016-11-22
北京市教育科研项目(PXM2015_014204_500251)
张兴兰(1970-),女,教授,研究方向为密码协议形式化方法和可信计算;刘 炀(1990-),女,硕士研究生,研究方向为数据挖掘、信息安全。
http://www.cnki.net/kcms/detail/61.1450.TP.20161122.1227.004.html
TP31
A
1673-629X(2016)12-0022-04
10.3969/j.issn.1673-629X.2016.12.005
猜你喜欢
华人时刊(2021年13期)2021-11-27
心声歌刊(2020年4期)2020-09-07
电子制作(2019年19期)2019-11-23
铁道通信信号(2019年6期)2019-10-08
小学生(看图说画)(2017年6期)2017-11-06
雷达学报(2017年6期)2017-03-26
互联网天地(2016年1期)2016-05-04
重型机械(2016年1期)2016-03-01
大连工业大学学报(2015年4期)2015-12-11
海军航空大学学报(2015年4期)2015-02-27
